假如输入系统的图像是一页文本,那么识别时的第一件事情是判断页面上的 文本朝向,因为我们得到的这页文档往往都不是很完美的,很可能带有倾斜或者污渍,那么我们要做的第一件事就是进行 图像预处理,做角度矫正和去噪。
然后我们要对文档版面进行分析,每一行进行行分割,把每一行的文字切割下来,最后再对每一行文本进 行列分割,切割出每个字符,将该字符送入训练好的OCR识别模型进行 字符识别,得到结果。
但是模型识别结果往往是不太准确的,我们需要对其进行识别结果的矫正和优化,比如我们可以设计一个语法检测器,去检测字符的组合逻辑是否合理。比如,考虑单词Because,我们设计的识别模型把它识别为8ecause,那么我们就可以用语法检测器去纠正这种拼写错误,并用B代替8并完成 识别矫正。这样子,整个OCR流程就走完了。从大的模块总结而言,一套OCR流程可以分为:
版面分析 -> 预处理-> 行列切割 -> 字符识别 -> 后处理识别矫正
OCR技术的实现,总体上可以分为五步:预处理图片、切割字符、识别字符、恢复版面、后处理文字。
预处理图片和后处理文字是最难的部分。
切割字符,识别字符,恢复版面是字符识别的核心步骤。
1、预处理图片
(1)对于倾斜的文本,可以采用找到文本的最小面积矩形(minAreaRect),然后旋转这个矩形,将矩形摆正,实现角度矫正。
如果矩形区域内的文字又有倾斜,这时候考虑使用霍夫线变换(HoughLinesP),霍夫线变换就是在图上找直线,因为图中的若干点,可以构成一条直线,把这些直线画出来。
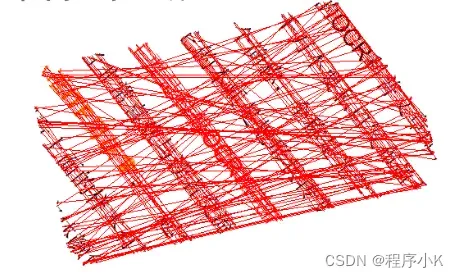
可以发现每一行的字都应该是在一条直线上的。
通过寻找直线法,进行矫正。
(2)对于扭曲的文本,拍照的时候出现这种问题比较多,比方说拍照的角度问题会导致文本的扭曲,空间上的扭曲,体现在视觉上就是近大远小。

处理步骤:
1、输入原图
2、灰度处理
3、二值化
4、膨胀操作
5、腐蚀操作,进行边缘瘦身
6、边缘检测
7、矩形框检测
8、把扭曲矩形矫正
9、矫正完成
对于一些识别的源数据情况比较好的,预处理可以忽略
2、切割字符
通过预处理后,图片变得规范以后,进行字符切割,把每个字符都切割出来。因为OCR最终识别是对单字符进行识别的(比方说识别you,其实是依次识别y,o,u),另外在切割字符的同时要对每个字符做好标记,用于后面的还原操作。根据字符之间的相对位置,进行还原。
切割字符的方法
(1)投影法
利用每个实体都是有影子的常识,字符也是有影子的,该方法可以用于行切分和列切分,注意一定要先切行,再切列。
切行:横着收集像素点,从左侧插入,右侧推出,把所有的黑点都堆到最右侧
![]()
切列:竖着切,在行切完的基础上,单独对每个切分块进行列投影
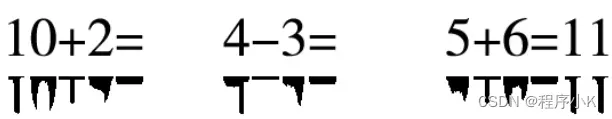
最后通过投影之间的间隙,我们就可以把每个字符切割开来。
为了方便OCR的识别,我们把切完的字符突变编程黑底白字,在RGB色值中,0代表黑色,255代表白色。
3、利用神经网络识别字符
学习的主要是各个字符的特征,虽然在32*32像素的图片上去学习特征,也可以学的非常的好。
我们只要构建好神经网络,然后把图片输入进行学习,机器自然就会学到各个字符的特征,这个过程相对来说是比较简单的。
4、文本后处理
还原::
识别出来了字符后,需要把字符还原,这一步至关重要。利用前面获得字符识别结果和字符的位置信息来进行还原。
我们根据字符的位置信息来判断字符是否是同一行,同一列。
例如判断两个字是否在同一行,可以看两个字在Y轴的重叠情况。如果重叠达到一定占比,那就可以认为这两组数据是处于同一行。也可以看两个文本在纵向的重叠率来判断他们是否属于同一列。
校正:
为了得到更加准确的文本内容,我们还需要对结果进行校正。可以借助于智能校正,结合语境来进行纠正。例如一些固定编码规则之类的。
5、总结
我认为OCR的重点就在于数据,数据量决定了识别率,对于同样的算法,数据量大的明显比数据量小的泛化性更强。数据量太小的时候,一旦出现了一些变动,可能就严重影响了识别率。这机器学习就像人一样,你只看过汉字,给你识别英文,你肯定不知道这个英文字符是什么。所以数据的多样性十分重要。
文章出处登录后可见!