更新记录
- 小白不想学习原理的话 可以直接学习后三次更新哈 前面可以直接跳过
- 第一次更新 抓包抢座
- 2023-4-28日第二次更新(更新了指定时间抢座 加了时间戳)
- 2023-5-9日第三次更新(更新了延迟时间 测试成功案例)
- 2023-5-31日第四次更新(关于程序中url的抓取)
- 2023-6-1日第五次更新(关于评论区有同学出现的bug(远程已帮忙解决))
小白不想学习原理的话 可以直接学习后三次更新哈 前面可以直接跳过
第一次更新 抓包抢座
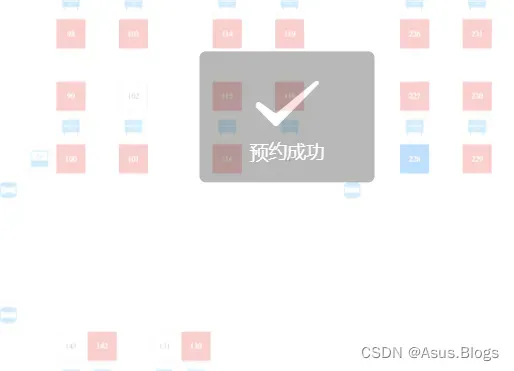
先来个效果图(利益相关先全码上了 )
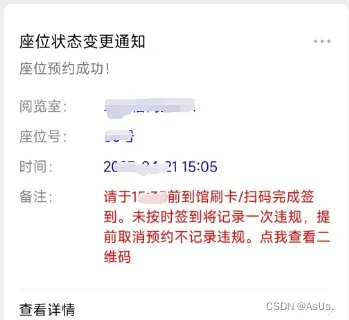
终于成功了!
以下废话可跳过
鉴于考研期间图书馆座位特别难抢,而且经常有人把垃圾留在我想去的那个座,于是就计划写个爬虫去实现正道的光 (我不是用科技抢座的, 我是要去保护那个桌子QAQ )
虽然大二写过py但是已经忘得差不多了,昨天凌晨还在看request,各种查博客,上午就想放弃了。但是有bug的程序我是受不了的,中午没来得及睡觉三点左右的时候肝出来了,最后发现是pc端微信获取到的cookie是错误的(也可能是我哪里没处理好),后来用手机连接fiddler拿到cookie才成功!
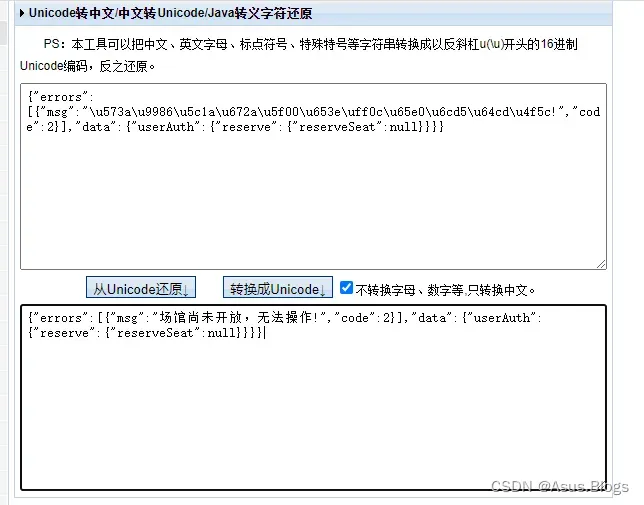
最后幸亏搜了一下乱码,竟然没看出来是unicode,太蠢了,转码出来结果也就出来咯

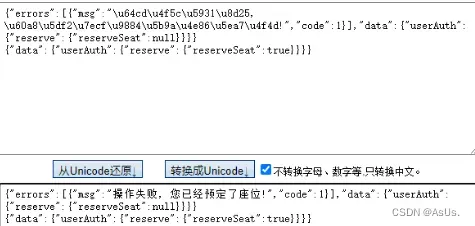
这个图是抢占成功后再去request返回的结果 没看出来是Unicode编码 还好灵机一动搜了一下 结果发现我已经占座成功了 打开手机看了下已经显示可以去签到了
因为我们学校前一阵已经把系统部署到学校服务器了,所以这里就不放地址了,简单讲下思路。
写在前面:
①代码很简单 就一个request请求 后面作者本人还会继续优化 先讲一下我的需求:
<1> 实现全自动抢座,每天开馆的时候定时开抢
<2> 速度比人快,达到馆开座到的效果 所以后期这里应该会优化 因为本博客只提交了一次request请求,也没有加时间戳什么的 这个很好实现 大家自由发挥
②过程中肯定避免不了多次请求 所以为了避免反爬封ip所以后期一定要加上代理池之类的(但是如果老师真想搞你 肯定会有你信息的 所以大家还是慢点冲吧)这个可与先不考虑,此程序不会导致这种情况
思路:
①运用了Python的request库去提交get/post请求 具体是用get还是post需要大家自己去抓包分析
②抓包软件我用的是Fiddler
③我们需要手机连接到Fiddler 然后手动去预约一次拿到post的参数 比如header data cookie等等 (第二次更新可以不用去抓手机PC端微信可以解决!)
最后就是撸代码 去提交post请求
坑:
1.最好还是用抓手机的请求去获取cookie,我用pc端的微信去预约结果报语法错误? 也可能哪里没弄好 后来手机端cookie可以了也就没去再测试pc端的 大家自测吧 后期如果我测试了会补上 (第二次更新解决 PC端是可以的)
2.看好get/post请求 以及传送的data是json还是其他格式
3.暴力请求就要加代理池了 被封了就不好了。。。。
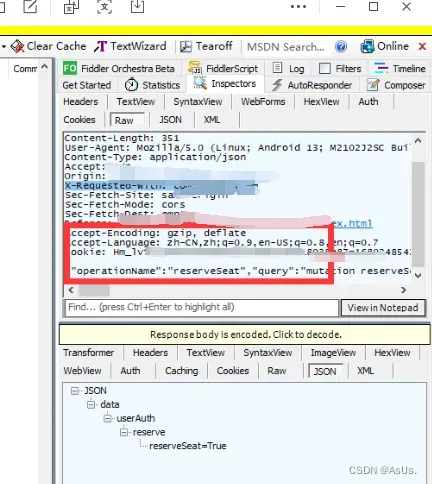
上代码(具体大家去根据自己情况抓包分析,每个系统都是不一样的 这里只讲了思路)
import json
import time
import requests
header = {
'Host': 'xxxx',
'Connection': 'keep-alive',
'Content-Length': '',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 NetType/WIFI MicroMessenger/7.0.20.1781(0x6700143B) WindowsWechat(0x6309001c) XWEB/6763',
'Content-Type': '',
'Accept': '*/*',
'X-Requested-With': '',
'Origin': '',
'Sec-Fetch-Site': '',
'Sec-Fetch-Mode': '',
'Sec-Fetch-Dest': '',
'Referer': '',
'Accept-Encoding': '',
'Accept-Language': 'zh-CN,zh',
'Cookie': 'xxxx'
}
url = 'xxxx'
data = \
{"operationName": "reserveSeat",
"query": "mutation reserveSeat($libId: Int!, $seatKey: String!, $captchaCode: String, $captcha: String!) {\n userAuth {\n reserve {\n reserveSeat(\n libId: $libId\n seatKey: $seatKey\n captchaCode: $captchaCode\n captcha: $captcha\n )\n }\n }\n}",
"variables": {"seatKey": "35,18", "libId": 525, "captchaCode": "", "captcha": ""}}
res = requests.post(url=url, headers=header, json=data)
tm = res.elapsed.total_seconds()# 获取请求时间
print(tm)
print(res.status_code)
print(res.text)
2023-4-28日第二次更新(更新了指定时间抢座 加了时间戳)
本次更新了 程序可以对指定时间精确到秒来进行抢座
经过测试 pc端微信进入公众号进行抓取获取到的cookie是有效的 这样就省去了再用手机端进行抓取的繁琐步骤 爽✌
# -----------------------------正题--------------------------------
struct_openTime = "2023-4-28 17:20:00"
openTime = time.strptime(struct_openTime, "%Y-%m-%d %H:%M:%S")
openTime = time.mktime(openTime)
request_cnt = 0
while True:
# nowTime = int(time.mktime(time.localtime()))
print(time.time(), openTime)
if time.time() >= openTime:
# print(nowTime, openTime,time.time())
print("------------------------------")
print(time.time(), openTime)
print("ok Try to grab seat!")
grab_time = time.localtime(time.time())
ts = time.strftime("%Y-%m-%d %H:%M:%S", grab_time)
print('当前时间是: ' + ts)
request_cnt += 1
res = requests.post(url=url, headers=header, json=data3)
tm = res.elapsed.total_seconds()
print(tm)
print(res.status_code)
print(res.text)
# break
if str(res.text).count("true"):
print("恭喜你!抢座成功!程序即将结束......")
break
else:
time.sleep(0.2)
print("------------------------------\n\n")
if request_cnt >= 5: # 防止请求过多 被老师XX 所以这里我只敢 “最多” 请求5次
break # 另一个作用是避免图书馆服务器有延迟 加上上面的sleep 延迟时间可以控制在 5*0.2s = 1s 内 而且避免了过多的请求(程序1秒内发送的请求是很可怕的数量)
print("程序结束成功!")
这个图是刚开始测试截的图 后面完整程序没截图 不过程序是可以用的 图后期补上吧 如果有时间
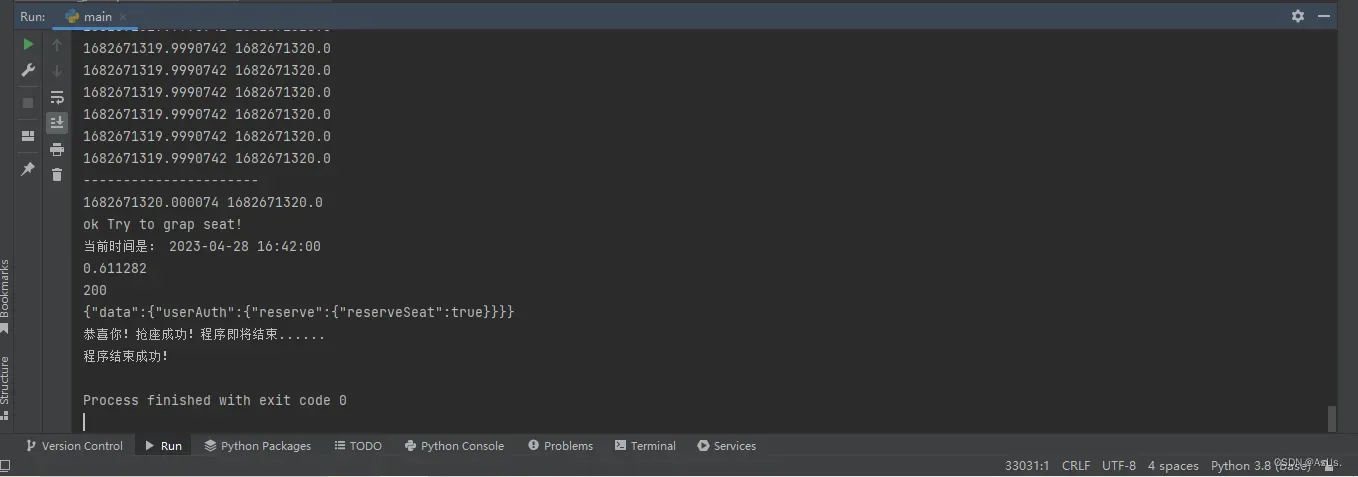
2023-5-9日第三次更新(更新了延迟时间 测试成功案例)
这次就说一下实战中遇见的问题和如何解决的
写好程序去实战的时候发现 我们学校服务器是有延迟的 之前设置的 sleep(0.2) * 5 = 1s是达不到要求的,所我就修改成了sleep(0.3) * 10 = 3s 来进行抓取,结果很丝滑,大家实战的时候可以按自己学校服务器放缩。另外今天也测试了一下人工手速和程序抢,结果基本被程序秒杀…
坑:
①注意cookie时效性,cookie会在一定时间内失效,需要自己去重新获取,这个我不知道多久失效一次(大约30分钟失效的样子),所以我每次抢座都会获取最新的cookie,好像发现计网有一块是讲这个的,等复习到再来更新一波吧…
②服务器延迟,大家多测试几次就行了,或者时间打长点,轻点c也是没问题的。
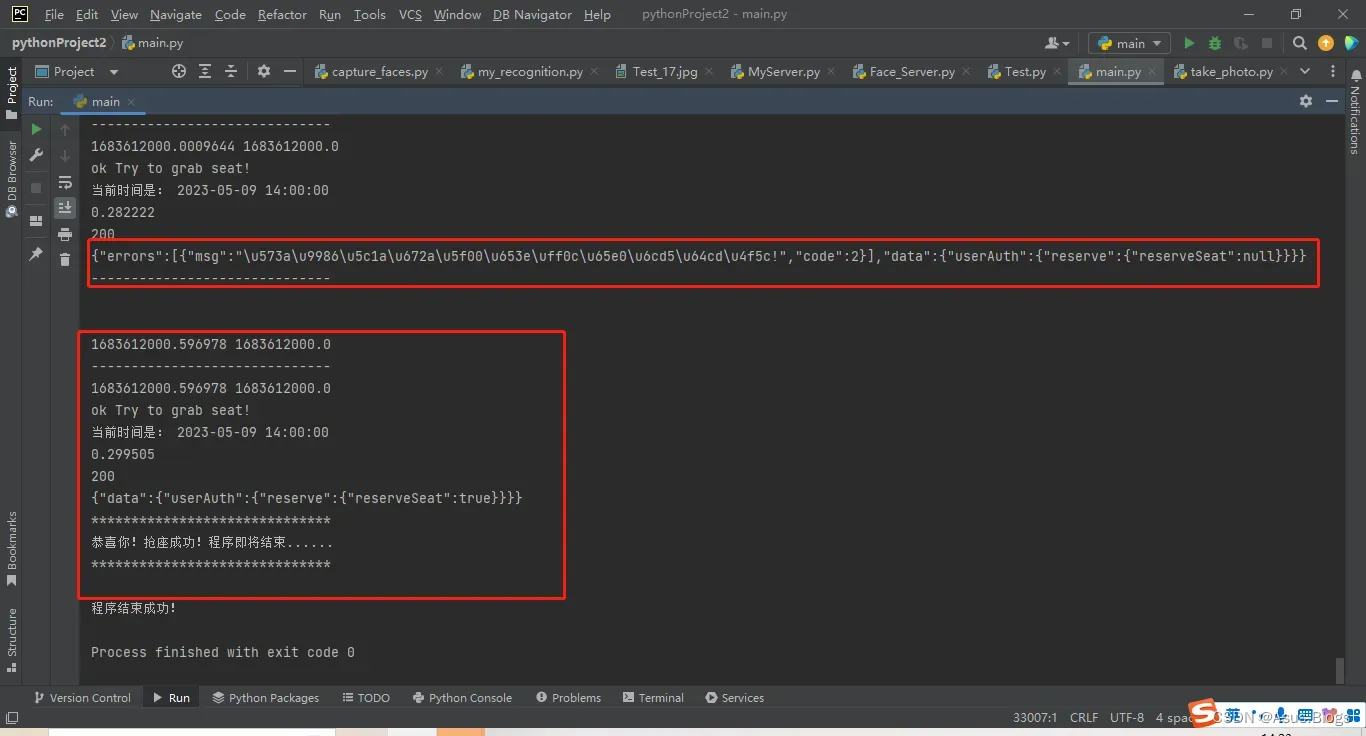
这里因为有延迟所以失败了一次,不过我设置的是请求10次,只要成功就会break掉程序,所以接下来的一次成功啦。到此也就结束了!
完整代码:
import json
import time
import requests
header = {
'Host': '',
'Connection': 'keep-alive',
'Content-Length': '353',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 NetType/WIFI MicroMessenger/7.0.20.1781(0x6700143B) WindowsWechat(0x6309001c) XWEB/6763',
'Content-Type': 'application/json',
'Accept': '*/*',
'X-Requested-With': 'com.tencent.mm',
'Origin': '',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': '',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh',
'Cookie': ''
}
url = ''
# 2楼 60号
data3 = \
{"operationName": "reserveSeat",
"query": "mutation reserveSeat($libId: Int!, $seatKey: String!, $captchaCode: String, $captcha: String!) {\n userAuth {\n reserve {\n reserveSeat(\n libId: $libId\n seatKey: $seatKey\n captchaCode: $captchaCode\n captcha: $captcha\n )\n }\n }\n}",
"variables": {"seatKey": "35,18", "libId": 525, "captchaCode": "", "captcha": ""}}
# 6楼 233号
data = {"operationName": "reserveSeat",
"query": "mutation reserveSeat($libId: Int!, $seatKey: String!, $captchaCode: String, $captcha: String!) {\n userAuth {\n reserve {\n reserveSeat(\n libId: $libId\n seatKey: $seatKey\n captchaCode: $captchaCode\n captcha: $captcha\n )\n }\n }\n}",
"variables": {"seatKey": "24,55", "libId": 20060, "captchaCode": "", "captcha": ""}}
# -----------------------------测试--------------------------------
# res = requests.post(url=lib_url2, headers=header, json=data3)
# tm = res.elapsed.total_seconds()
# print(tm)
# print(res.status_code)
# print(res.text)
# -----------------------------正题--------------------------------
struct_openTime = "2023-5-9 14:00:00"
openTime = time.strptime(struct_openTime, "%Y-%m-%d %H:%M:%S")
openTime = time.mktime(openTime)
request_cnt = 0
while True:
# nowTime = int(time.mktime(time.localtime()))
print(time.time(), openTime)
if time.time() >= openTime:
# print(nowTime, openTime,time.time())
print("------------------------------")
print(time.time(), openTime)
print("ok Try to grab seat!")
grab_time = time.localtime(time.time())
ts = time.strftime("%Y-%m-%d %H:%M:%S", grab_time)
print('当前时间是: ' + ts)
request_cnt += 1
res = requests.post(url=url, headers=header, json=data) # 此处data3 是2楼 60
tm = res.elapsed.total_seconds()
print(tm)
print(res.status_code)
print(res.text)
# break
if str(res.text).count("true"):
print("******************************")
print("恭喜你!抢座成功!程序即将结束......")
print("******************************\n")
break
else:
time.sleep(0.3)
print("------------------------------\n\n")
if request_cnt >= 10: # 防止请求过多 被老师XX 所以这里我只敢 “最多” 请求10次
break # 另一个作用是避免图书馆服务器有延迟 加上上面的sleep 延迟时间可以控制在 10*0.3s = 3s 内 而且避免了过多的请求(程序1秒内发送的请求是很可怕的数量)
print("程序结束成功!")
2023-5-31日第四次更新(关于程序中url的抓取)
首先打开我们的Fiddler和PC端微信 并在微信中打开图书馆公众号进行模拟选座
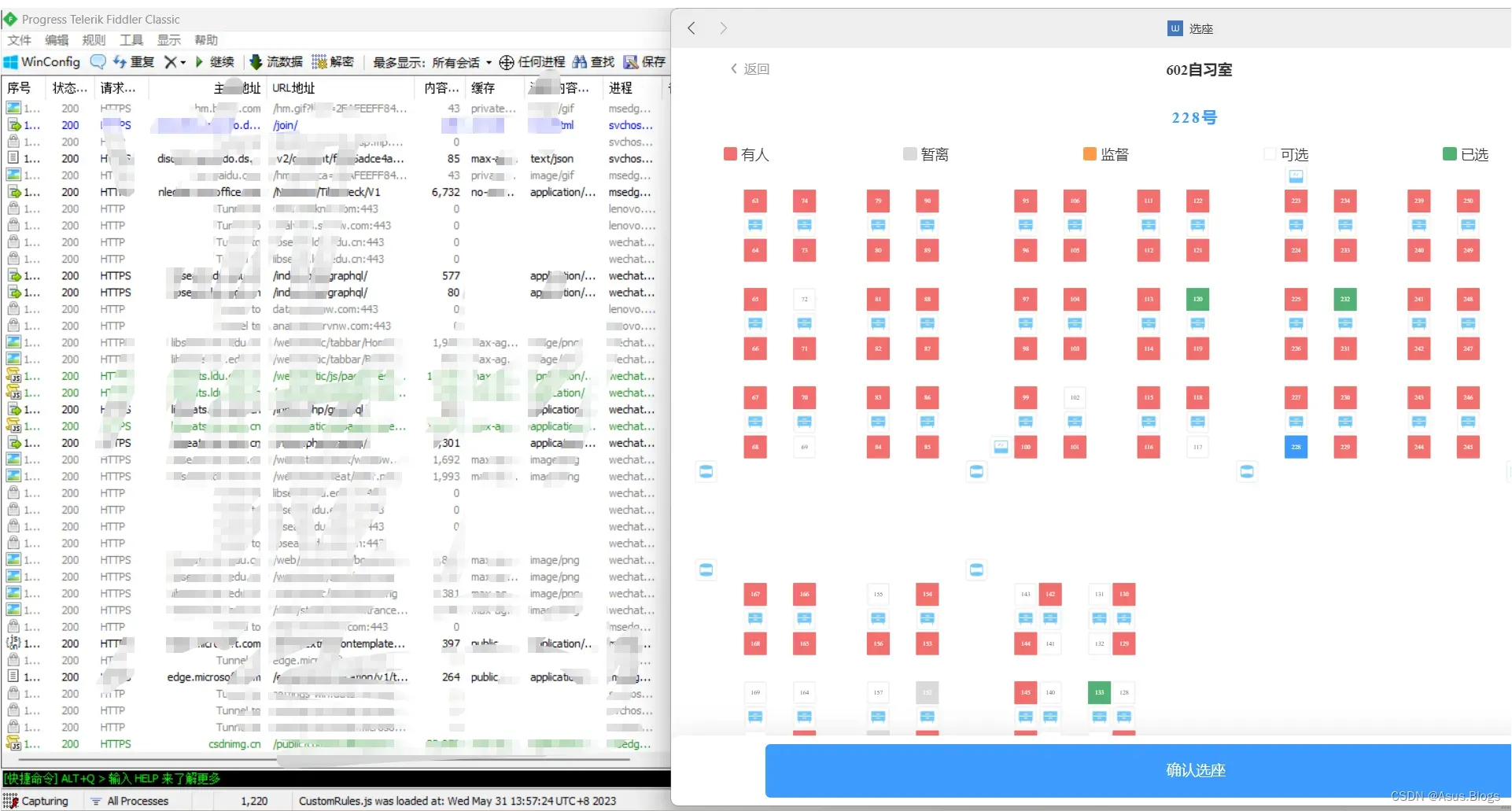
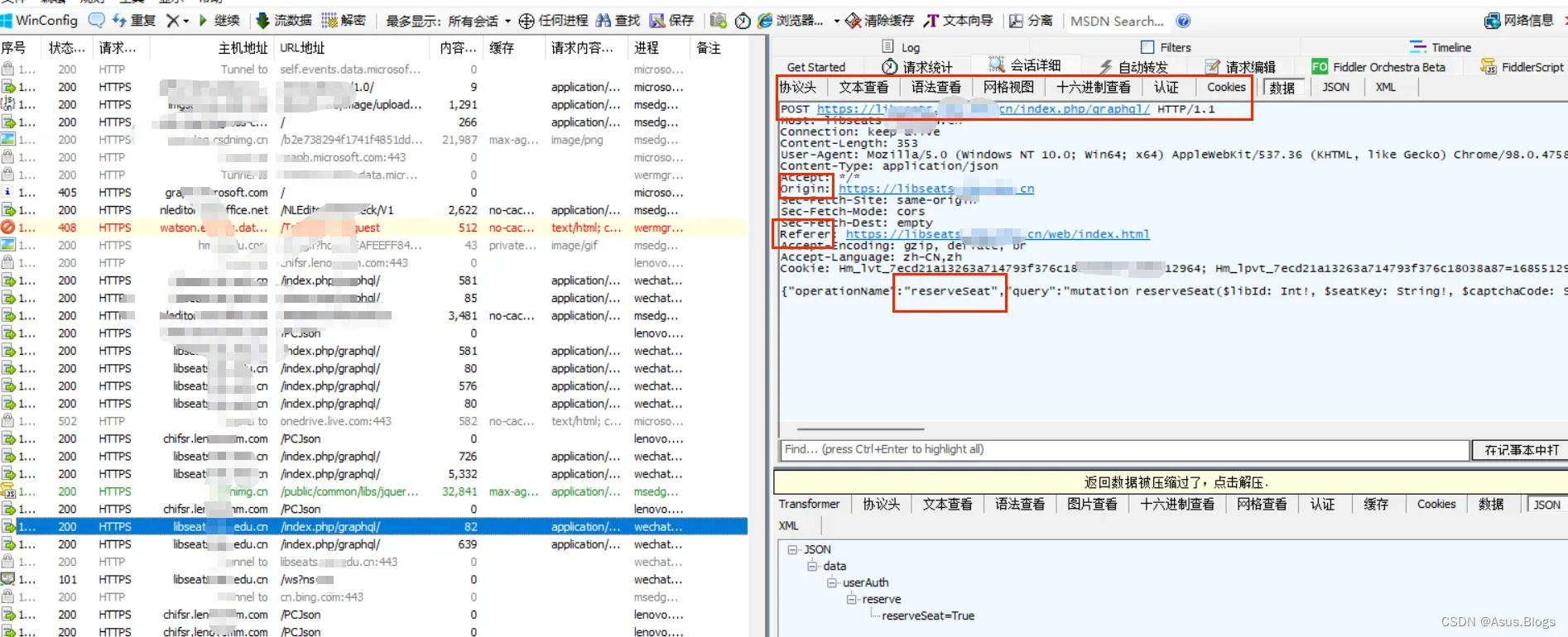
在Fiddler中就可以看到我们发出的选座请求以及各种header参数,而url就是POST后面那个冒蓝光的那个。
2023-6-1日第五次更新(关于评论区有同学出现的bug(远程已帮忙解决))
有同学在使用过程中返回了各种错误,在这里做一波更新
关于Access Denied 或者 其他

这个问题多半是cookie失效 或者 cookie填写不正确,大家在选cookie的时候可能出现各种格式的cookie,可能有很多参数行,我们只需要在fiddler中找到模拟请求的那个Http请求里的cookie就行了,注意 如果cookie有多个参数需要用分号隔开,不过在Raw里面fiddler已经给分好了,可以拿来直接用就行啦。
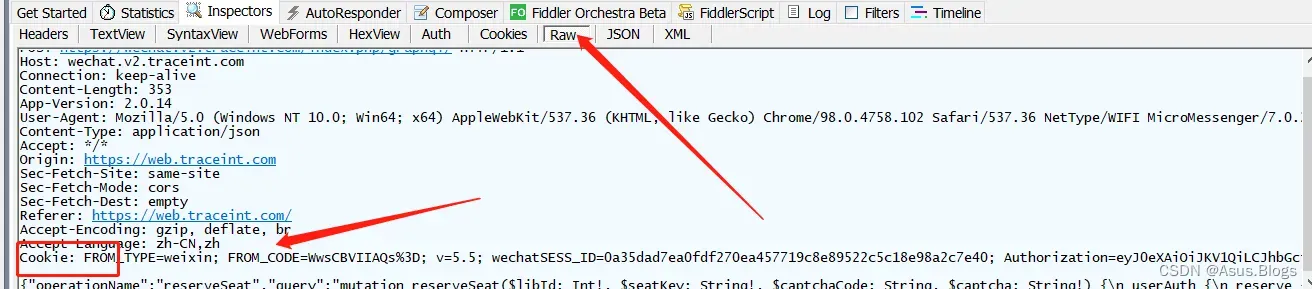
以上是第一次获取cookie的过程,因为要拿到header中的其他参数,所以我们需要手动模拟一次,在以后使用过程中,我们只需要抓取登录页面的cookie就可以了,不需要每次再手动选座获取了
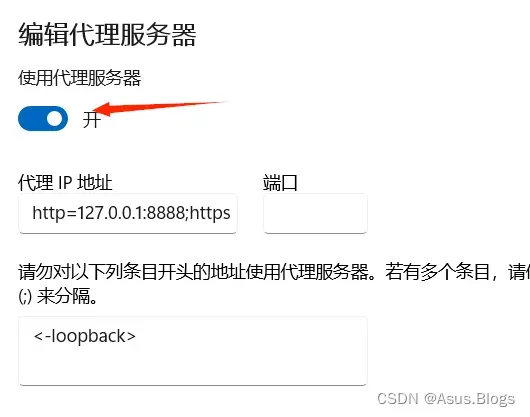
最后填个坑:在fiddler运行过程中会自动开启代理


把下面这个关掉再去运行程序,或者拿到cookie之后把fiddler关掉去运行程序,如果开着这个代理的话程序是运行不了的
第二点是如果开着fiddler不正常关机的话会导致下次开机网页打不开,解决办法是重新打开fiddler再关掉就能解决了。本质是如果开着fiddler关机 ,此时的代理服务器会保存,也就是保存为下图的代理IP地址,从而导致网页打不开
写在最后 本次更新后估计很少再对程序优化了,虽然没有达到全自动抢座(是指由程序自动获取cookie 然后定时提交登录)甚至基本的UI界面都没有。毕竟考研年没太多时间精力再去优化了,因为手动抓取cookie也就几秒的时间,而且本程序初衷也是为了避免自己喜欢的座位被抢掉,现在通过半自动已经达到目的了,另外也总不能天天有人给你抢座吧,所以大家平时还是在手机上选座提交就行啦。
综上,祝好!
文章出处登录后可见!