1、 前言
对于自动驾驶来说,单相机识别无法满足现有要求,也有过将多相机中的检测结果进行整合的工作,但这种操作显然不够“优雅”,于是更多的在Bird’s Eye View(BEV)视角下进行识别,如下图所示。

BEV的重点是如何高效的设计BEV特征,目前可以分为两种:自底向上和自顶向下。 自底向上可以理解为从”2d”出发,通过”LIFT”操作把图像提升到”3d”伪点云,然后在利用voxel pooling生成BEV特征。自顶向下可以理解为从”3d”出发,先生成含有3d信息的BEV query,然后再利用transformer将每张图片上的特征提取待BEV query上。 因此本文会按照两个部分来总结部分的BEV模型,同时会给出一些学习资料,便于后续学习。
欢迎进入BEV感知交流群,一起解决学习过程发现的问题,可以加v群:Rex1586662742或者q群:468713665。
BEV模型排行榜:https://www.nuscenes.org/object-detection?externalData=all&mapData=no&modalities=Camera
数据集下载地址:https://www.nuscenes.org/download
测试只需要下载页面最下方的 Full dataset(v1.0)里面的Mini数据集以及Map expansion里面的Map expansion(v1.3)
nusence 数据集解析:https://blog.csdn.net/qq_39025922/article/details/114889261
2、模型小结
该模块将小结一下在本地跑通过的模型,并对大部分模型进行了逐行代码的解析,为了更加全面的了解BEV模型,这个也是比不可少的过程。下面将主要分为四种类型:自低向上、自顶向下、多模态、解码。针对不同类型的模型提供相应的学习文章、视频,相信看完这些资料后,会对BEV模型有进一步的了解。
1.1、Lift-Splat-Shoot(LSS)
repo :https://github.com/nv-tlabs/lift-splat-shoot
paper:https://arxiv.org/pdf/2008.05711
学习链接:手撕BEV的开山之作:lift, splat, shoot(没完全shoot)
学习笔记:[BEV] 学习笔记之Lift, Splat, Shoot
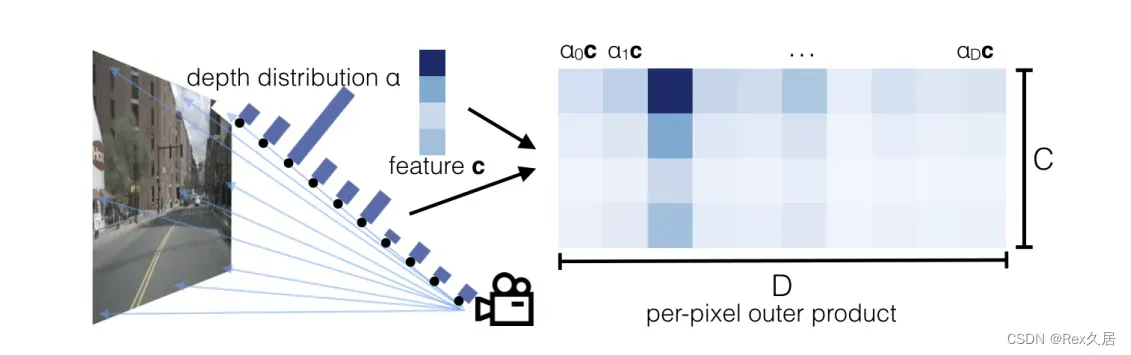
最为BEV模型的开山论文,论文中主要提出了Lift-splat操作,它可以显示的估计深度信息以及特征,然后再将视锥和深度特征通过voxel_pooling得到BEV特征,如下图所示。
1.2、BEVDet
repo :https://github.com/HuangJunJie2017/BEVDet
paper:https://arxiv.org/pdf/2211.17111
学习链接:BEVDet系列源码解读
学习笔记:[BEV] 学习笔记之BEVDet(原理+代码解析)
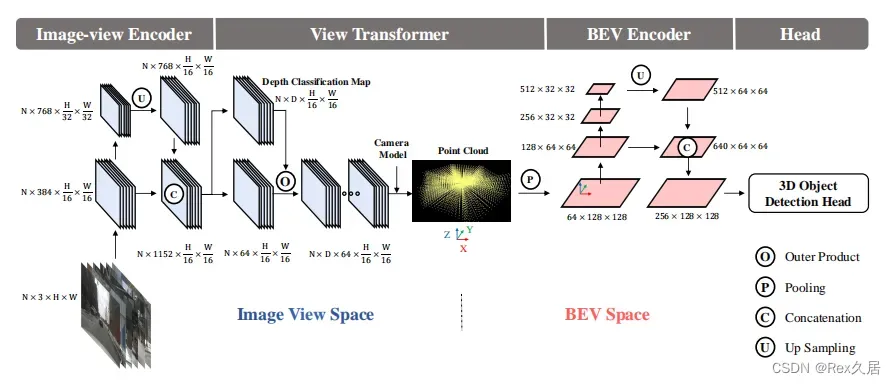
目前在nusences排行榜中暂时排名第一的模型,目前也来到了2.0版本,论文的主要工作是获得了显示的BEV特征,并进行了可视化。由于是显示的BEV特征,因此可以进行特征提取以及使用常见的检测头进行解码,BEVDet主要包括四个步骤:
- Image-view Encoder,环视图像特征提取,包括深度
- View Transformer,将图像特征转化为BEV特征
- BEV Encoder,BEV特征提取
- Head 解码
关键是其中的第二步,View Transformer将图像特征转化为BEV特征的过程,并使用cuda实现了高效的voxel_pooling_v2,在后处理中,也提出了scale-NMS,可以针对不同尺度的物体进行缩放,然后进行过滤。模型结构如下图所示:
1.2、BEVerse
repo :https://github.com/zhangyp15/BEVerse
paper:https://arxiv.org/pdf/2205.09743
学习文章:https://zhuanlan.zhihu.com/p/518147623
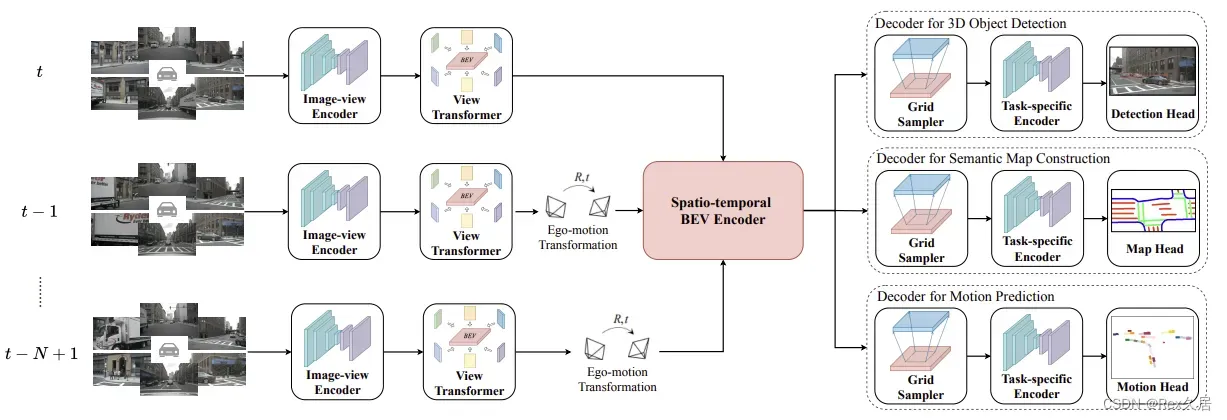
基于BEVDet,BEVerse会从N个时间戳获取周围M个摄像头的图片,并将相应的自运动和摄像头参数作为输入,使用SwinTransformer作为图片特征提取的主干网络,然后对每一帧的图片进lift操作,最后将每一帧得到的BEV特征利用soatio-temporal BEV Encoder模块得到最终的BEV特征。
1.3、BEVDepth
repo :https://github.com/Megvii-BaseDetection/BEVDepth
paper:https://arxiv.org/pdf/2206.10092
学习笔记:[BEV]学习笔记之BEVDepth(原理+代码)
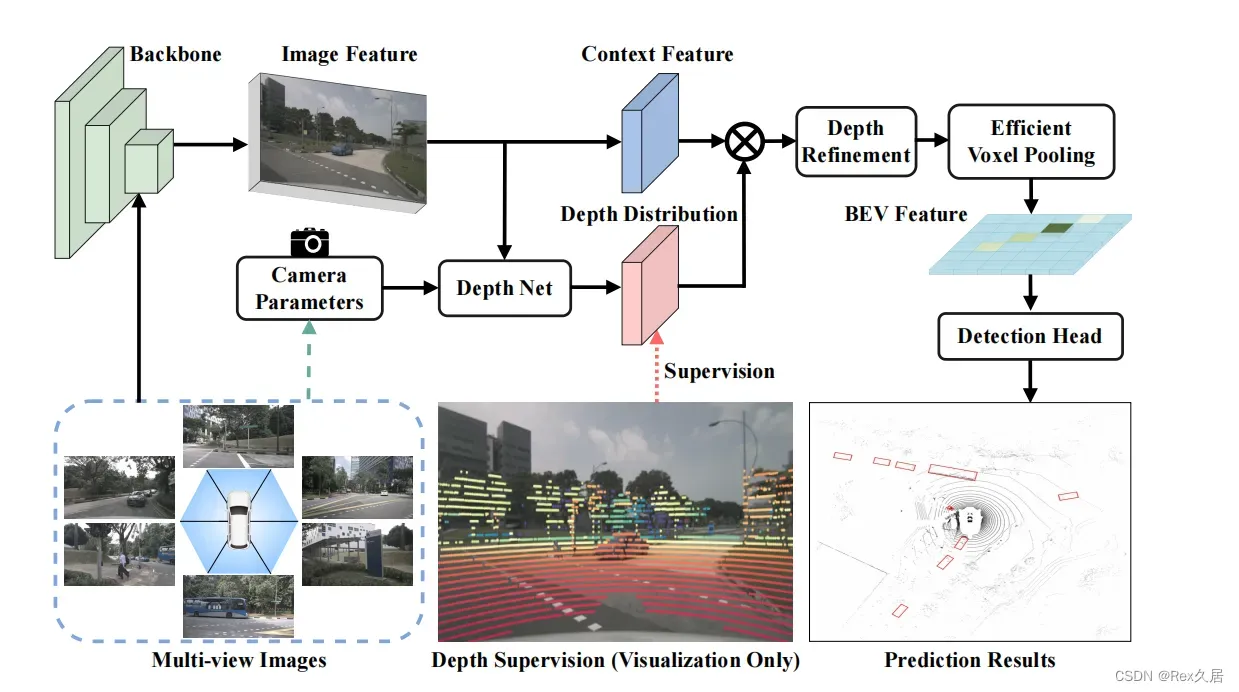
BEVDepth使用了时序建模,一定程度上借鉴了BEVFormer,其核心主要分为如下三点
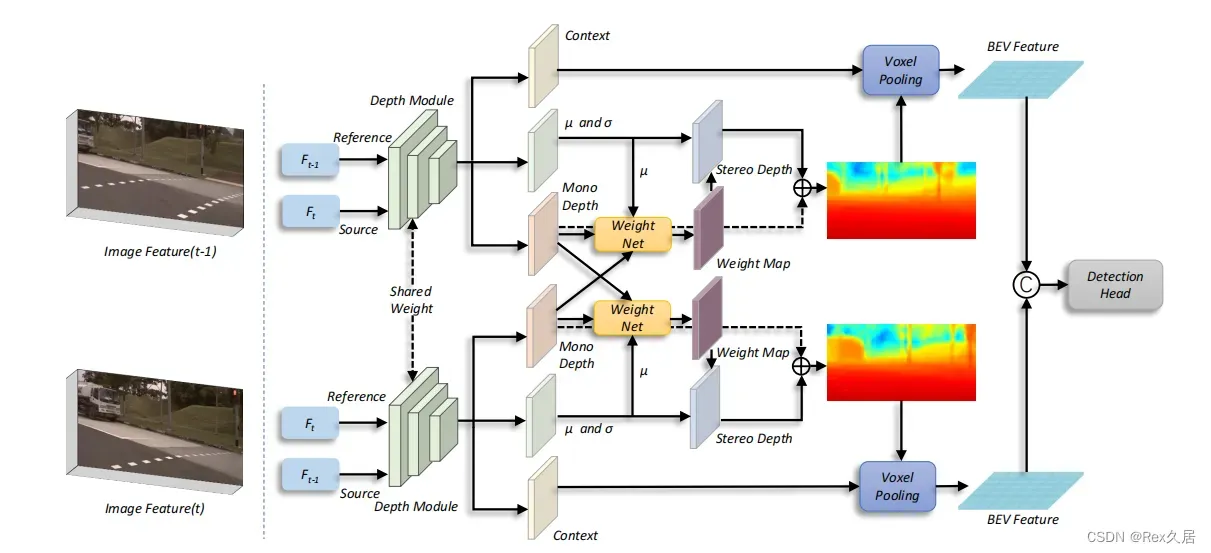
1、深度监督,在之前的论文中,都没有对预测的深度进行显示的监督,导致深度估计不够理想,而BEVDepth中利用Lidar的点云对LIFT中的深度进行监督,提搞了深度预测的准确性。
2、深度预测和特征预测分离,之前的工作是通过一个网络一次预测出depth以及context,而BEVDepth中是先通过图片特征得到context,然后再通过context获得depth.
3、由于振动或者其他原因,相机外参数可能会进行变化,因此,专门设计了两个网络来学习此时的相机参数信息,并将其作为注意力的形式作用与context以及depth.
1.4、BEVStereo
repo: https://github.com/Megvii-BaseDetection/BEVStereo
paper:https://arxiv.org/pdf/2209.10248
学习文章:https://zhuanlan.zhihu.com/p/569422924
在BEVDepth的基础上,进一步提出来多帧深度特征融合的方法,基于立体的多视图 ,应用时序立体技术,同时论文还提出了一种size-aware circle NMS 方法来提升性能。
1.5、小结
自低向上的过程大致可以分为1、环视特征提取以及”LIFT”,2、获取BEV特征,3、解码。其中各个模型的的不同点在于BEV特征的设计,深度特征预测以及高效voxel_pooling。
2、自顶向下
自顶向下的BEV模型基于DETR发展而来的,需要预先熟悉以下三篇文章有关于DETR的模型。
2.1 Detr/Deformable-DETR/Detr3d
DETR:
repo: https://github.com/facebookresearch/detr
paper:https://arxiv.org/pdf/2005.12872.pdf
DETR的成功源于transformer的成功,在这里推荐几个up主,他们将transformer讲解的十分详细了,如果不了解transformer的同学可以先进行学习。
transformer:tansformer讲解
vision transformer:vision transformer讲解
DETR:DETR论文讲解
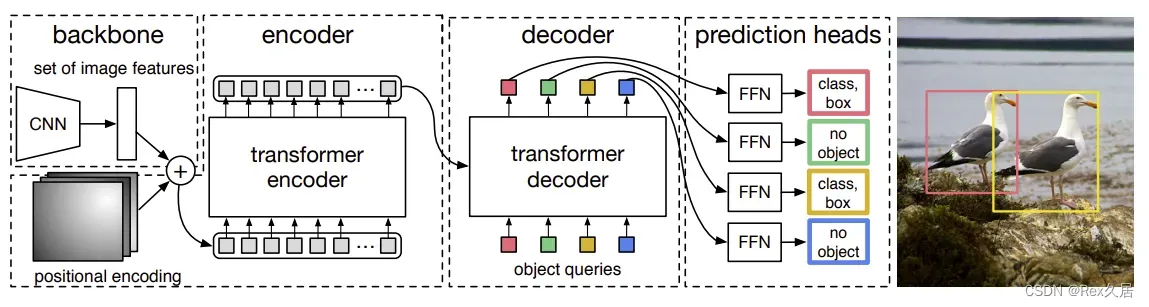
DETR是一个端到端的模型,解决了许多人为设置的因素。
Deformable-DETR:
repo: https://github.com/fundamentalvision/Deformable-DETR
paper:https://arxiv.org/pdf/2010.04159
学习笔记:【BEV】学习笔记之 DeformableDETR(原理+代码解析)
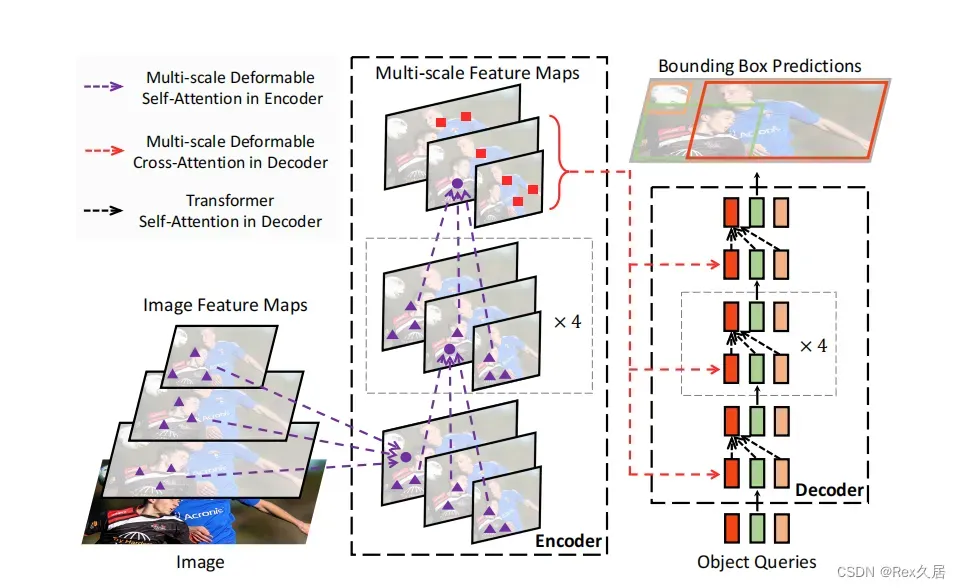
尽管DETR提供了一个十分简单的利用Transformer进行目标检测方法,但是也存在缺点:更长的收敛时间、小目标检测较差。
相较于DETR密集的注意力机制,Deformable-DETR每个参考点仅关注邻域的一组采样点,这些采样点的位置并非固定,而是可学习的(和可变形卷积一样),从而实现了一种稀疏的高效注意力机制。
DETR3d:
repo: https://github.com/WangYueFt/detr3d
paper:https://arxiv.org/pdf/2110.06922
学习文章:https://zhuanlan.zhihu.com/p/430198800
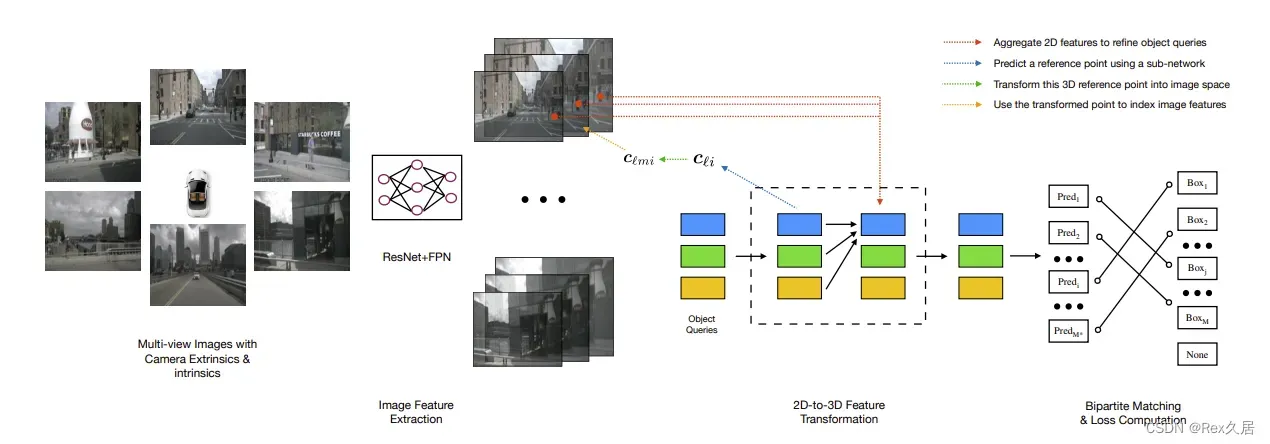
由于DETR的成功,DETR3D将DETR应用在环视图片的特征提取中。
2.2 PETR/PETRV2
PETR:
repo: https://github.com/megvii-research/PETR
paper:https://arxiv.org/pdf/2203.05625
学习文章:PETR
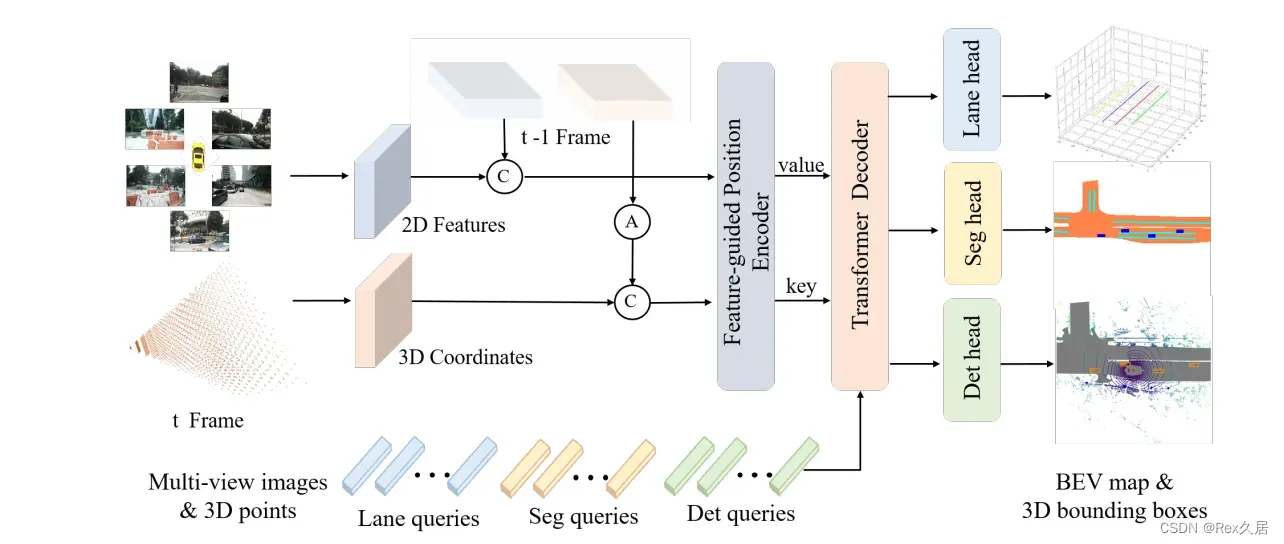
PETR是DETR3D的改进,通过Position Embedding将多视角相机的2D特征转化为3D感知特征。

PETRv2:
paper:https://arxiv.org/pdf/2206.01256
学习文章:PETRv2
PETRv2是在PETR的基础上改进了如下几个部分:
- 将3D PE扩展到时序版本,通过对生成的3D coordinates进行变换,实现了时序对齐
- PETR中3D PE的生成是data-independent的,PETRv2中引入了特征引导的位置编码器,使得3D PE的生成和输入数据相关,隐式地从特征中获取到深度等信息。
- PETRv2引入了一个简单高效的方案来支持BEV分割,受SOLQ5启发,DETR框架中一个query足以表征一块区域内的掩码,为此PETRv2中定义若干个分割查询向量实现高质量的BEV分割
3.3 BEVFormer / BEVFormerV2
BEVFormer
repo : https://github.com/fundamentalvision/BEVFormer
paper: https://arxiv.org/pdf/2203.17270
学习视频:手撕BEVFormer
学习文章:https://zhuanlan.zhihu.com/p/543335939
学习笔记:[BEV] 学习笔记之BEVFormer(一)、[BEV] 学习笔记之BEVFormer(二)
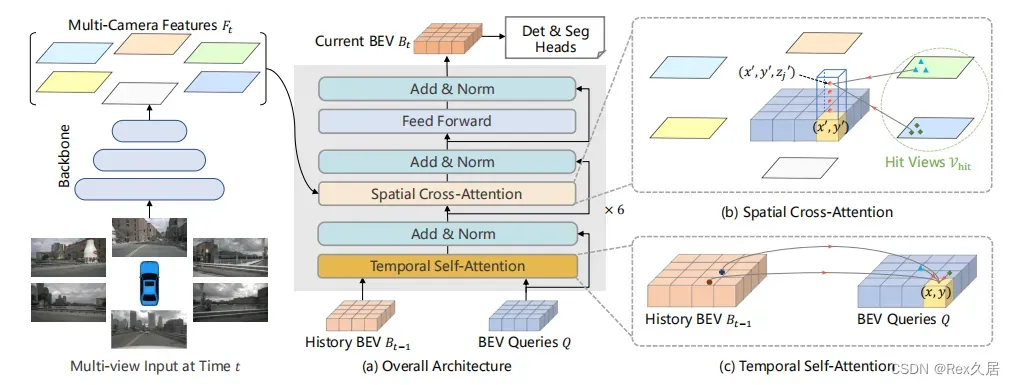
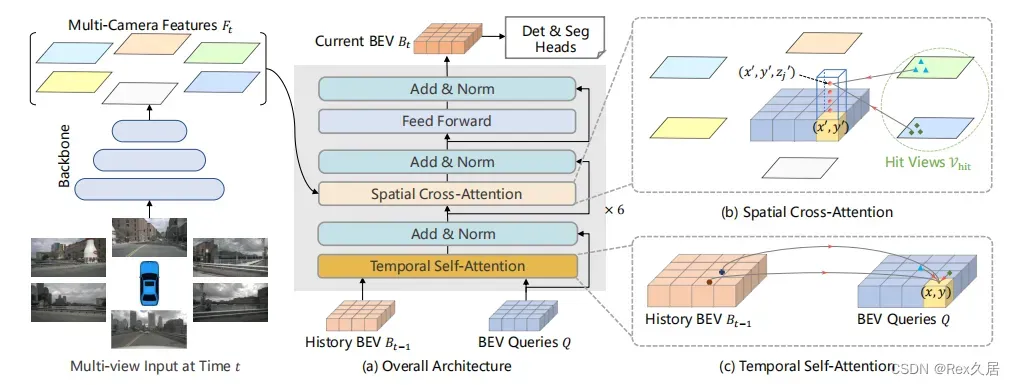
BEVFormer的可以分为如下几个步骤:
- 环视图片特征提取
- 利用Temporal Self-Attention 、Spatial Cross-Attention提取BEV特征
- 利用Deformable DETR 进行decoder
- 使用匈牙利算法定义正负样本
- Focal Loss + L1 Loss
BEVFormer核心是Encoder中的Temporal Self-Attention模块以及Spatial Cross-Attention模块。
BEVFormerv2
paper: https://arxiv.org/abs/2211.10439
学习文章:https://www.zhihu.com/question/568349586/answer/2770772116
基于BEVFormer,引入透视空间监督来简化BEV检测器的优化方案,并且采用了未来帧来生成BEV特征,因此BEVFormerv2主要由五个组件组成:图像主干、透视3D检测头、空间编码器、改进的时间编码器和BEV检测头。由于目前BEVFormerv2的代码暂未开源,无法在本地进行测试。
3、多模态
纯视觉3d检测的效果目前还有待提高,为了更好的将BEV模型应用在自动驾驶中,多模态的是目前精度最高的做法。
3.1 bevfusion-mit
repo : https://github.com/mit-han-lab/bevfusion
paper: https://arxiv.org/pdf/2205.13542
学习文章:BEVFusion
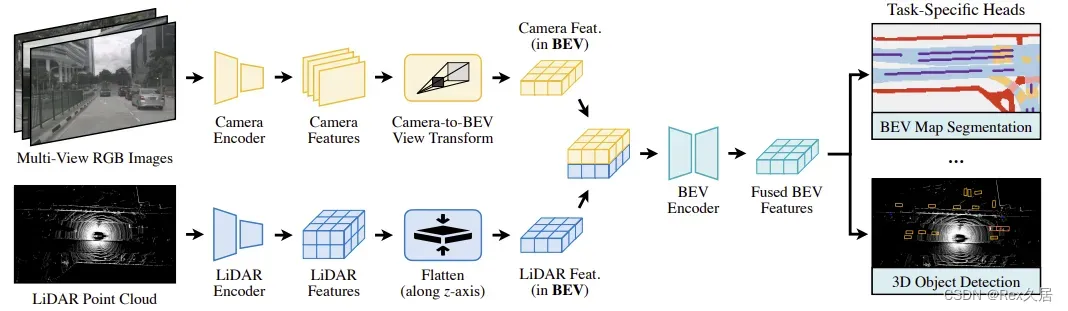
BEVFusion提出了多任务多传感器的框架,通过针对不同的传感器,设计不同的特征提取网络,最后得到统一的BEV特征,最后可以支持多种下游任务。BEVFusion的整体结构还是很明显的,在查看源代码的时候也比较清晰。其中通过环视图片提取BEV特征的方式也是通过LSS的方法产生的,点云模型部分需要熟悉稀疏卷积。
3.2 bevfusion -ADLab
repo :https://github.com/ADLab-AutoDrive/BEVFusion
paper:https://arxiv.org/pdf/2205.13790
北大&阿里提出了BEVFusion,与mit的BEVFusion同名,两者的网络框架也很类似。
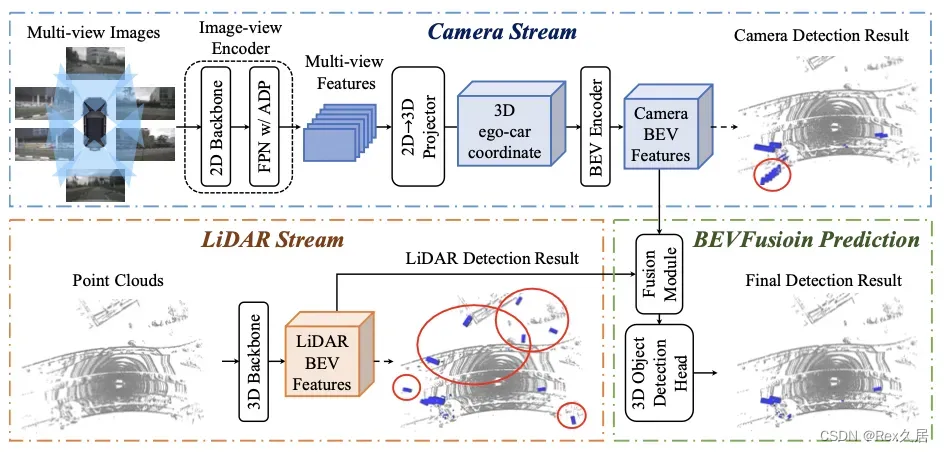
4、解码模型
上文中提到的模型解码部分一般分为两种,基于centerpoint和基于DETR。
4.1、CenterNet/CenterPoint
CenterNet:
repo :https://github.com/xingyizhou/CenterNet
paper:https://arxiv.org/pdf/1904.07850
学习文章:centerpoint
CenterNet是一个anchor free的模型,整个模型可以分为4个部分
- 主干网络:提取图片特征
- 上采样:利用特征图进行反卷积,得到一个高分辨率的输出。
- Center Head 热力图预测、中心点预测、宽高预测
- 预测结果的解码
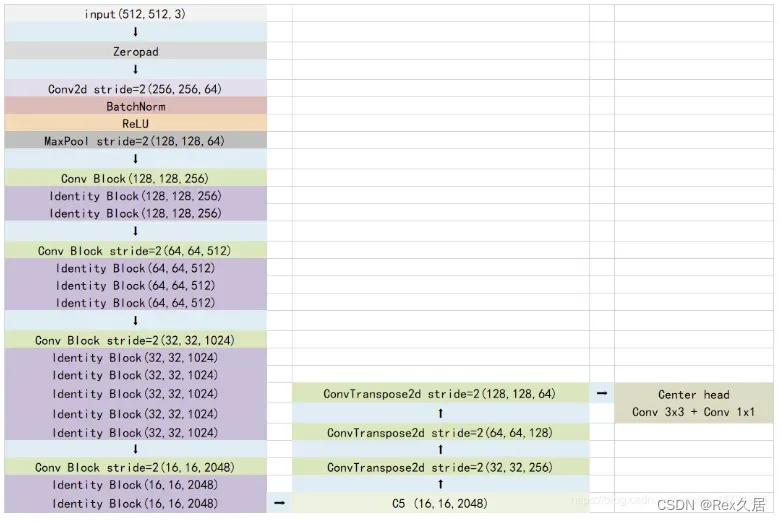
CenterPoint:
repo :https://github.com/tianweiy/CenterPoint
paper:https://arxiv.org/pdf/2006.11275.pdfcenterpoint
学习文章:CenterPoint
CenterPoint是将CenterNet的方法拓展到3d检测中。
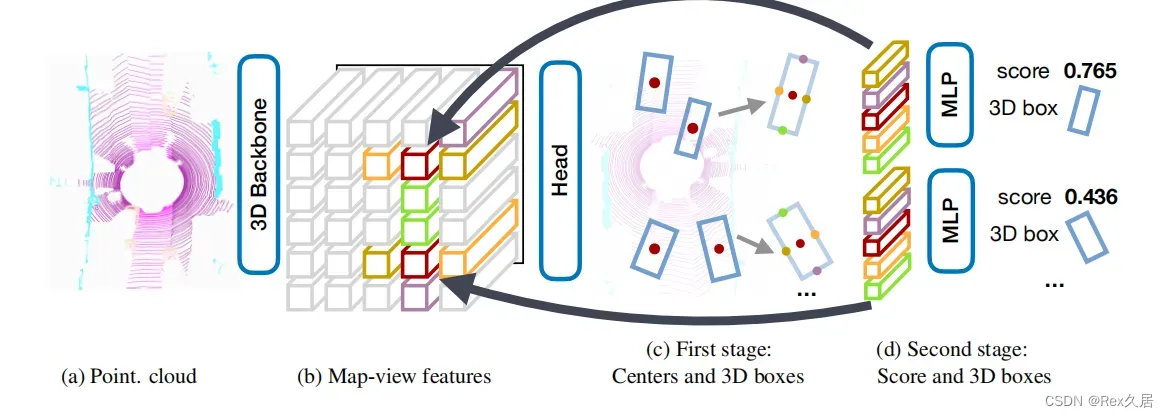
4.2、DETR
在DETR的decoder中,人为的设计了100个Object queries,用于一次性预测出图片中的100个物体,然后利用两个FFN来预测object query 的类别以及bbox,以达到无序NMS的操作。
5、总结
通过对多种BEV模型的学习,现在已经对BEV的由来、发展有了初步的了解。BEV未来的发展应该与transformer的发展紧密结合,相信在以后BEV模型还有为进一步的突破,尤其是纯视觉的BEV模型。同时也期待能够学习到更多的BEV模型的部署教程,从中学习到更多知识,共勉。
文章出处登录后可见!