机器学习
- 一、如何让自注意机制更有效?
- 1、local attention/truncated attention
- 二、non-autoregressive sequence generation非自回归序列生成
- 三、pointer network
一、如何让自注意机制更有效?
在自注意机制里面,我们输入一个序列,输出是另一个序列。输入序列之后我们可以得到一个query和一个key的向量序列,长度为分别都为N(跟输入序列长度相同)。那么在attention matrix里面,我们要做的就是把query和key进行点积,那这个运算的就是NN级别的。所以我们要想办法解决这个机制的运算量大的问题。虽然self attention运算量可能会很惊人,但是我们的self attention毕竟是我们的神经网络中的一个小小的一部分(可能有很多个self attention还有别的结构组成)。
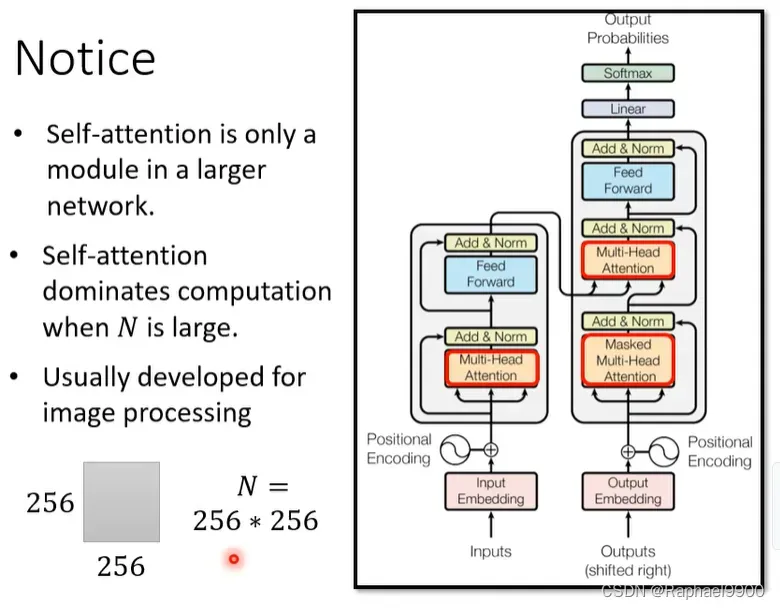
虽然self attention会对网络的计算量影响很大,但是也有可能被其他计算量更大的结构主导网络,那么我们优化self attention计算就没有什么显著的优化。那什么时候self attention主导网络的计算量呢?当self attention的N很大的时候,这样我们加快self attention 才会对神经网络有帮助。我们经常把self attention应用在图像识别的时候。我们的一个图片如果N是256256,那我们的运算就会非常大!
1、local attention/truncated attention
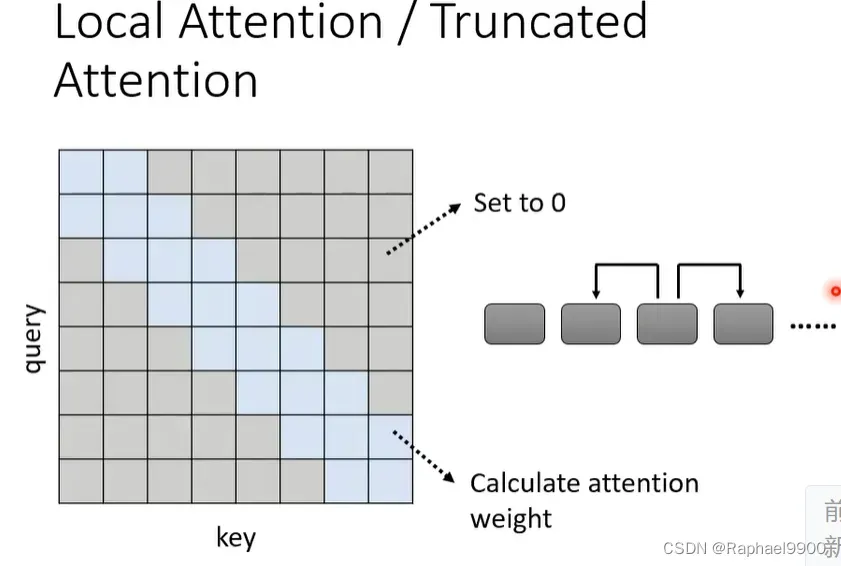
在self attention里面,我们最大的计算量就是要计算N*N的矩阵。那我们可以怎么优化呢?也许我们不需要计算这个矩阵所有位置的数值,我们可以用人类知识填充!有些问题不需要看整个attention,可以只看前后的邻居。在self attention如果我们只看邻居,那我们就能把很远的地方的值设为0.下图我们把灰色地方设为0,因为那些地方没有必要参与运算。而蓝色的就需要计算啦。整个方法就是local attention或者truncated attention。但是这个local attention明显有问题,我们在做attention的时候只能看到小范围的数值,那这个就跟CNN很像啦!local attention是可以加快我们的attention的方法,但是不一定能得到很好的结果。下面这个local attention是寻找前后的邻居。
2、stride attention
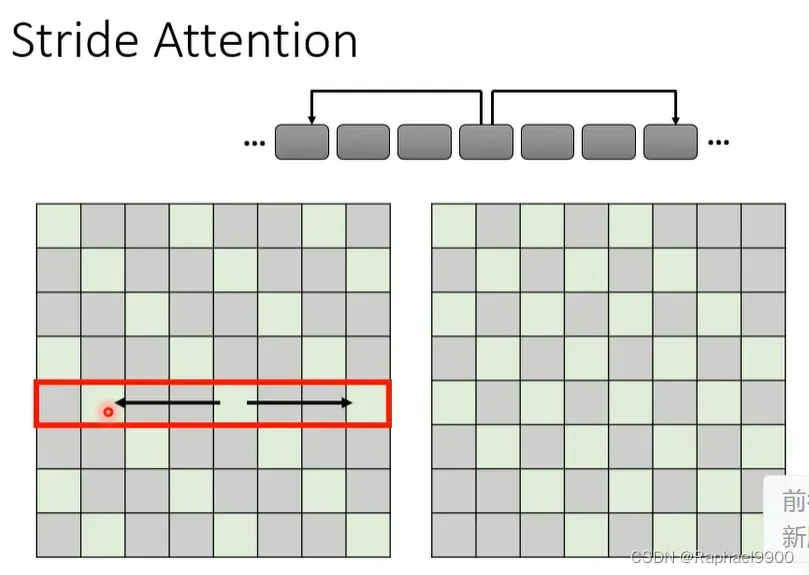
那么这个stride attention就是,取比较远的邻居!下图我们是空2格看的,或者是别的方式。
3、global attention
以上都是以某个位置为中心看左右的事情,如果我们关心整个sequence,那么我们可以用global attention。我们可以加入一个特殊token到原始的sequence里面。在这里,global attention会做两件事情:
(1)每个特殊的token都加入每一个token,收集全局信息。
(2)每个特殊的token都被其他所有的token加入,以用来获取全局信息。
怎么实现呢?第一种,我们可以把原来的sequence里面的某些向量选做special token。另外一种就是外加额外的token。如果要把外加token的矩阵attention matrix画出来,每一个cow行代表query,每一个column列代表key。下图中橘色两个横向的地方是有值的,都要计算attention,他们是特殊的token,要加入到所有的其他的key。那每一列的前两列也是有值的,他们也会加入到第一个和第二个位置。从下图可以看出来,每一个不是特殊token的query都要加入特殊token。而对于灰色的地方,他们没有值,互相之间就没有联系了!
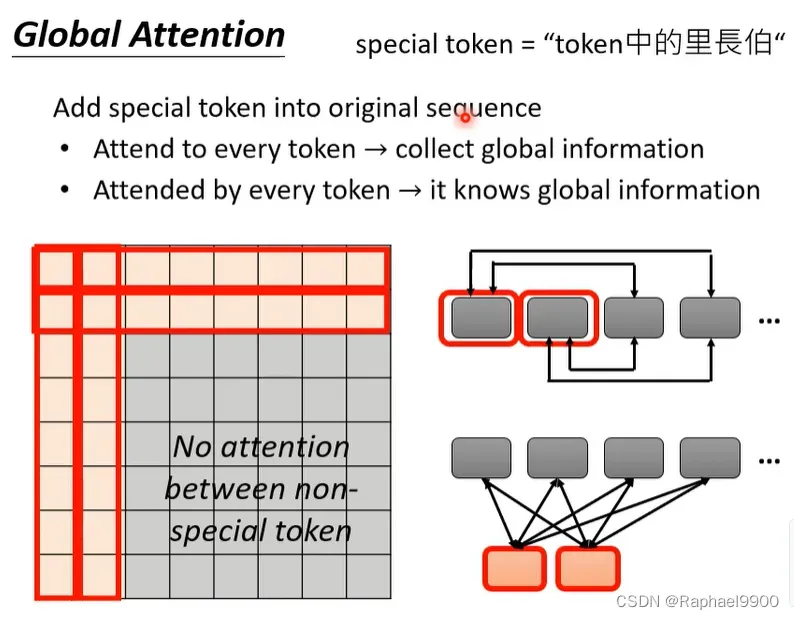
以上我们讲了三张不同的选择,那哪一个好呢?我们都选择!对于不同的heads我们选择不同的attention。
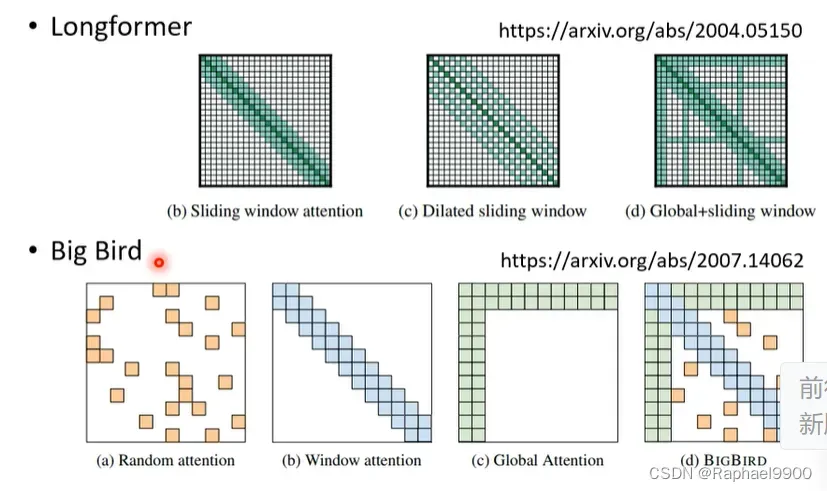
big bird加入了random attention。
4、data driving
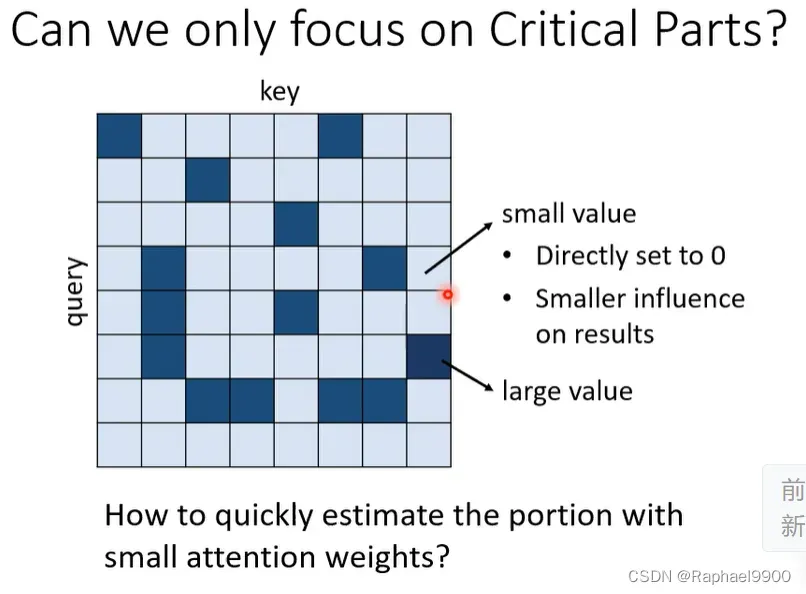
刚才我们说的方法是人为决定的,哪里有值,哪里为0.那我们能不借助人,而使用数据驱动的方式吗?在一个self-attention里面的矩阵里面,某些位置有很大的值,有些位置又有很小的值,那我们就把很小的值变为0,这个可能对我们的结果没有什么影响。那我们是否能估计矩阵哪里有大值,哪里有小值吗?
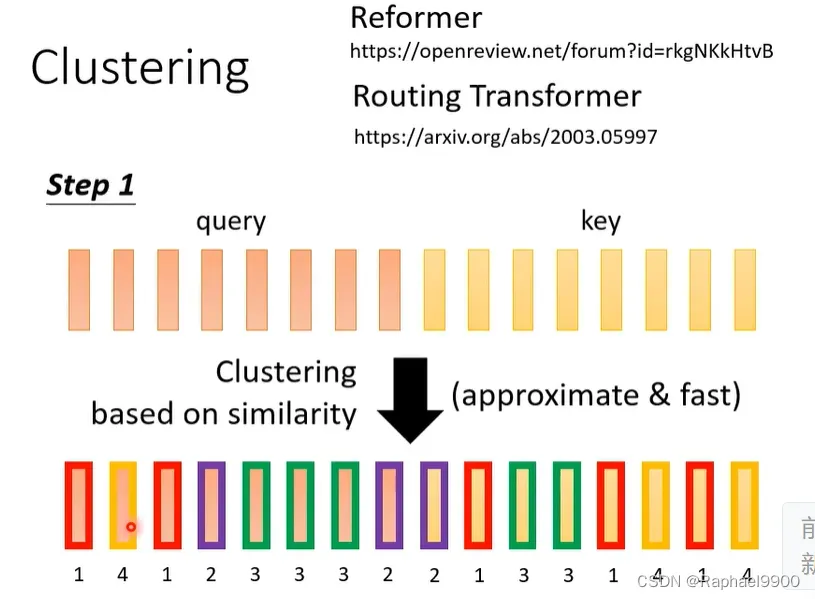
clustering
在reformer和routing transformer两篇文章里面,都用了一个方法——clustering。
步骤一:我们先把query和key取出来,然后根据query和key的相近程度做clustering。对于相近的数据就放在一起,对于比较远的数据就属于不同的cluster。下面我们有四个cluster,用不同的颜色来标出。这里可能有个问题,我们在做cluster的时候可能会出现运算量大的问题!其实事实上我们的cluster还是有很多快速的方法的。
对于query和key形成的attention matrix来说,只有当query和key的cluster是一样的时候,我们才计算他们的attention weight。对于不属于同一个cluster的两个query和key,就把他们设为0。这种方法可以加速我们的运算,这是一种基于数据来决定的!
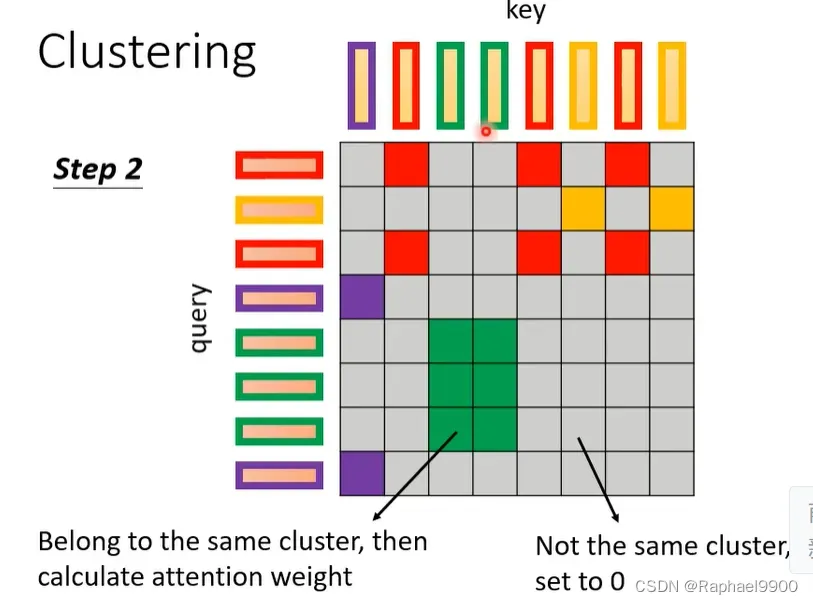
learnable patterns of sinkhorn sorting network
那有没有方法可以让我们再次改变上面的想法,让我们的矩阵是学习出来的呢?下面的方法就是由sinkhorn sorting network学习出来的。在sinkhorn sorting network里面,直接学习另外一个network来决定怎么输出这个矩阵。
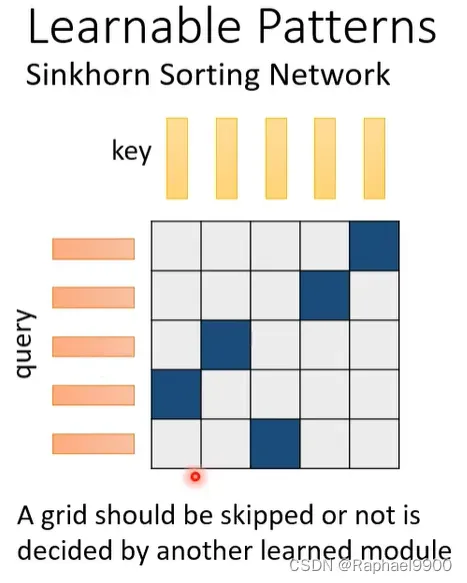
我们把输入的序列,经过一个NN之后产生另外一排向量序列,生成的矩阵就是NN的。我们要把这个生成的不是二进制的矩阵变成我们的attention matrix。这个过程是可以微分的,所以是可以在NN里面训练出来的。
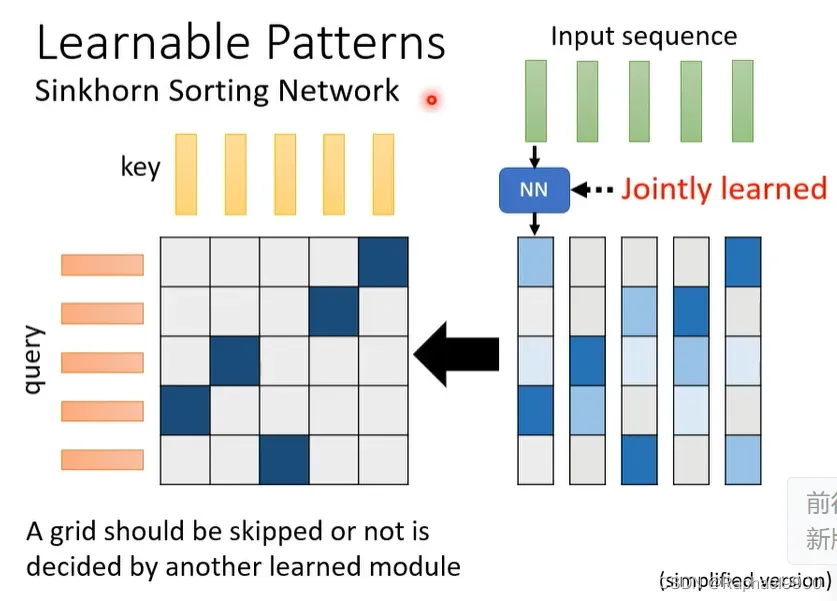
其实我们可以直接输出这个attention matrix,不用经过非二进制矩阵转换为二进制!
但是其实还有个问题,就是用另外一个网络生成矩阵真的比我们直接算attention matrix快吗?仔细想想,好像两个没有什么区别吧。事实上,在sinkhorn sorting network里面,有好几个输入的向量会共用一个经过NN产生的向量。也就是时候有向量复用啦!
又有另一个问题,我们真的需要一个NN的full attention matrix吗?在一片linformer的文章里面提到,在一个attention matrix里会有很多冗余的列,很多列都是重复的,这个矩阵是low rank的,很多列是依赖其他列的。那我们能不能去掉重复,产生小的attention matrix,加快attention的速度呢?
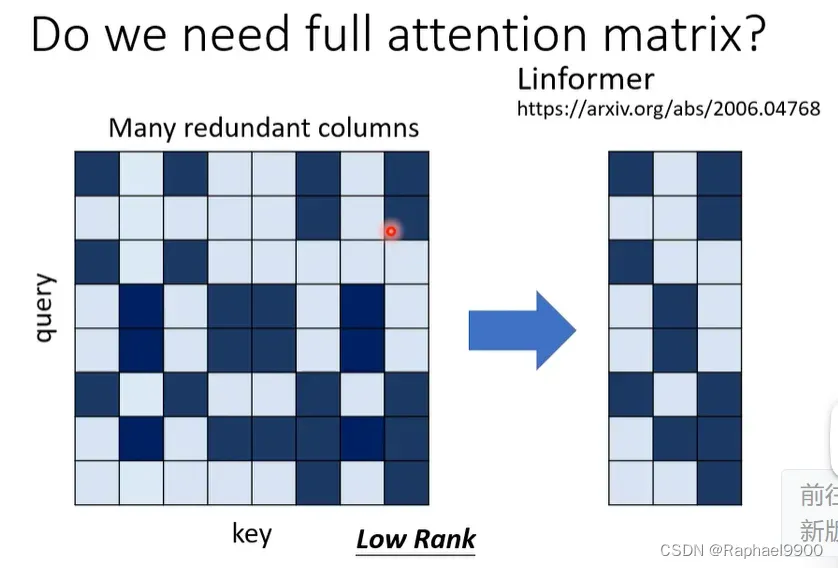
怎么做呢?我们有N个key,选择K个代表的key。然后与N各query产生一个矩阵,那我们怎么用这个长方形的矩阵产生self -attention layer 的输出呢?我们有N个value,也选择K个代表value。然后我们把这K个value和attention matrix做weight sum加权和,就得到输出。我们我们要选择代表key,而不选择代表value呢? 但是我们不能改变query呀!因为我们的输出长度可能就会变短了!如果不是输入一个序列输出一个label那就不要这样做了!
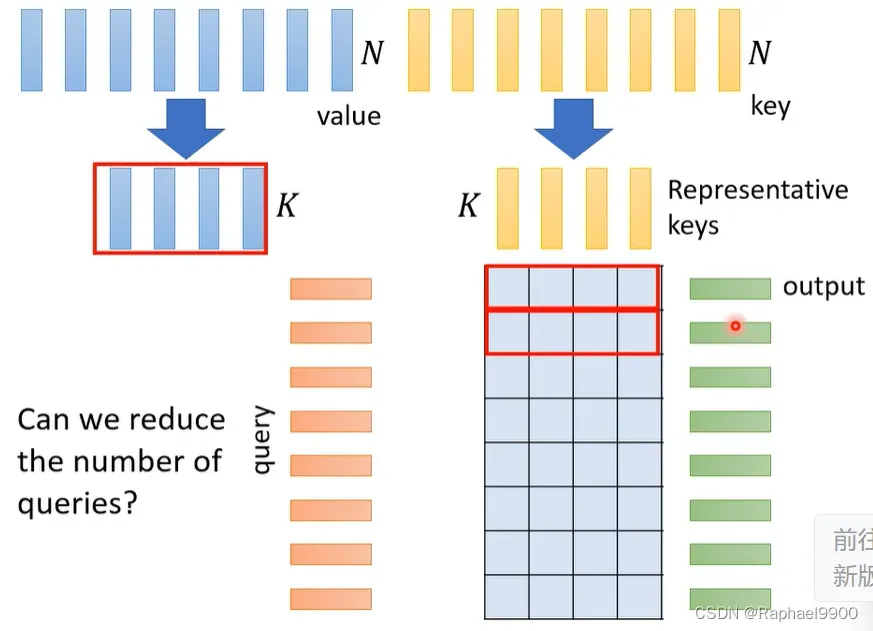
减少key的数量
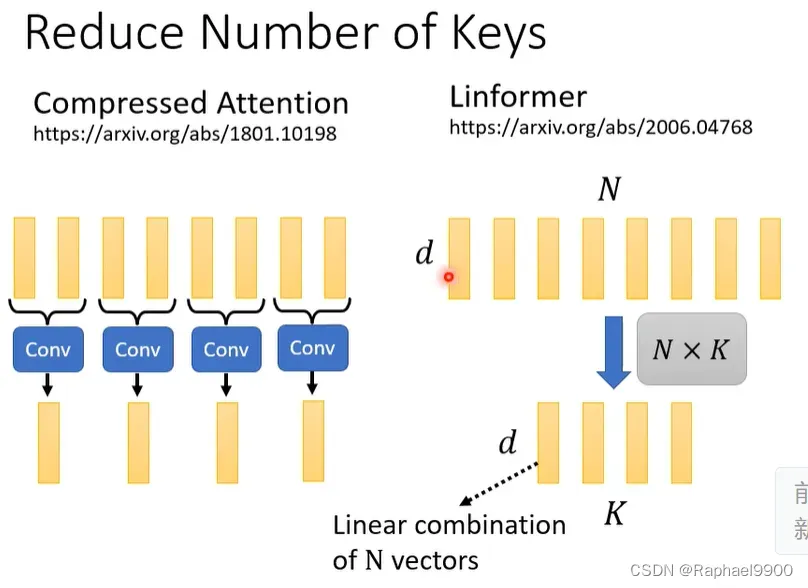
怎么选择代表性的key呢?在一个文章compressed attention里面提到,我们输入一个很长的key序列,我们用CNN来扫过,key序列的长度就变短了,那这个就是代表性的key。在另一个文章linformer里面提到,输入的key序列可以看成是dN的矩阵,我们可以把这个key序列乘上一个NK的矩阵,然后就得到了d*K的矩阵。那这个得到的新矩阵就是代表性key序列,这个方法其实是N个key序列的线性组合。
注意机制attention mechanism
回顾,其实attention的整个过程,其实就是矩阵相乘,那我们是否能进行优化呢?
我的输入是一个矩阵I,I乘上一个linear transformer Wq得到另外一个矩阵Q(dN)。然后再做以下的运算:
Q和K的维度d要一样,因为要做点积。但是V可以不为dN。有没有办法加速这个运算呢?
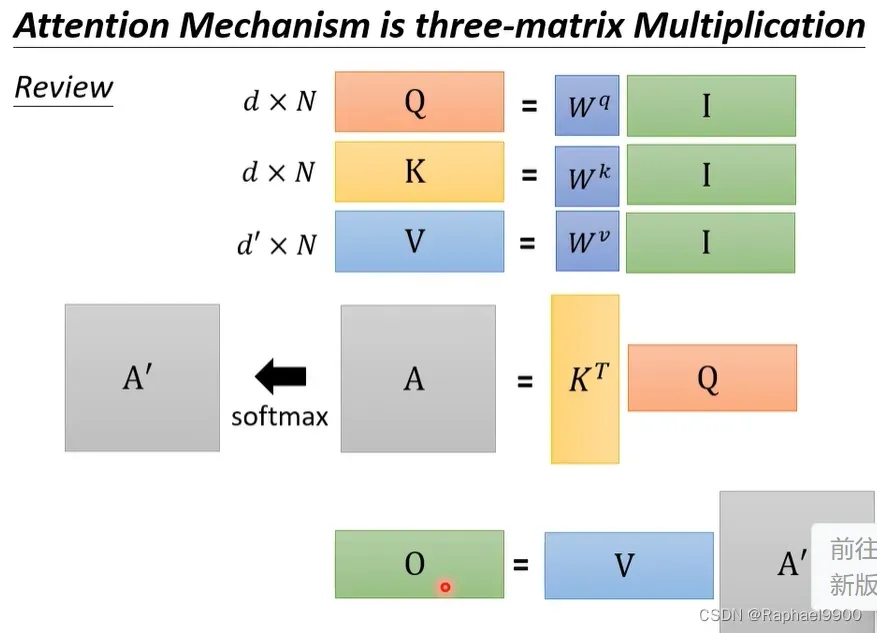
假设我们没有做softmax这个步骤,那A=A’,O=VKTQ。
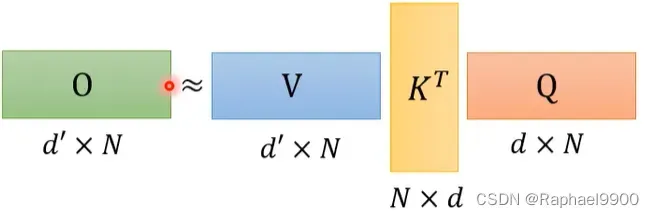
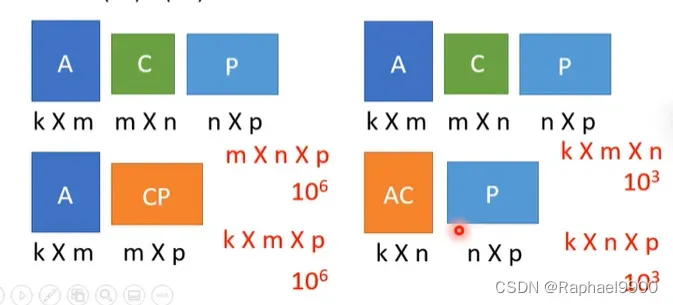
我们可以这样进行优化:是否V和K跟K和Q相乘的运算是差不多的呢?不是的。
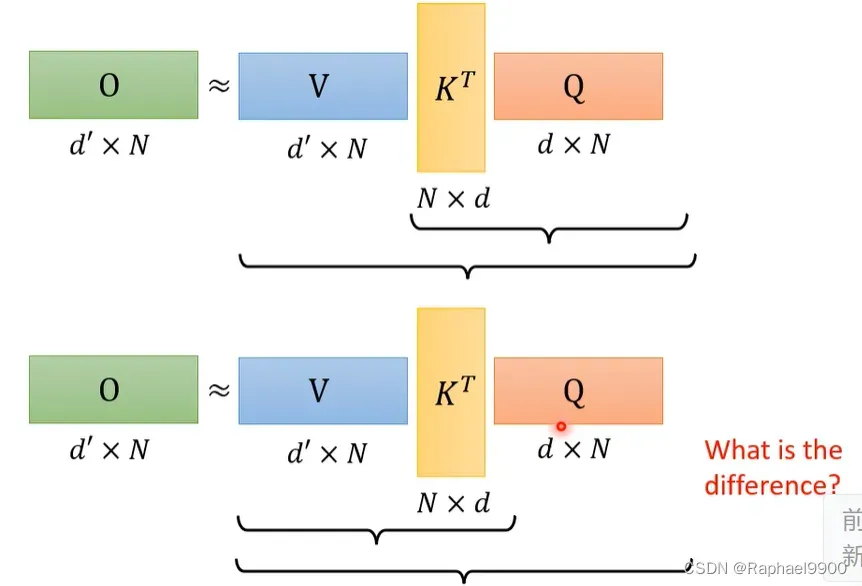
事实上,这两种情况的相乘结果是一样的,但是运算量是不一样的!
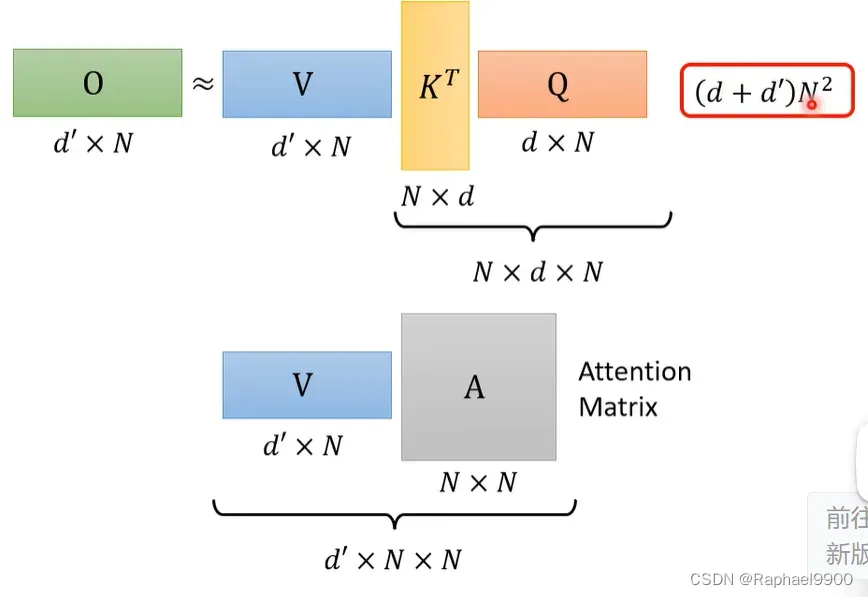
KT和Q相乘的乘法次数需要NdN次,得到A(attention matrix)。V*A的乘法次数是d‘’NN,那总的计算次数就是(d+d’)N^2.
但是我们交换了乘法顺序之后呢?乘法次数只要2dd’N!那上面的计算就会比下面的计算大很多呀。
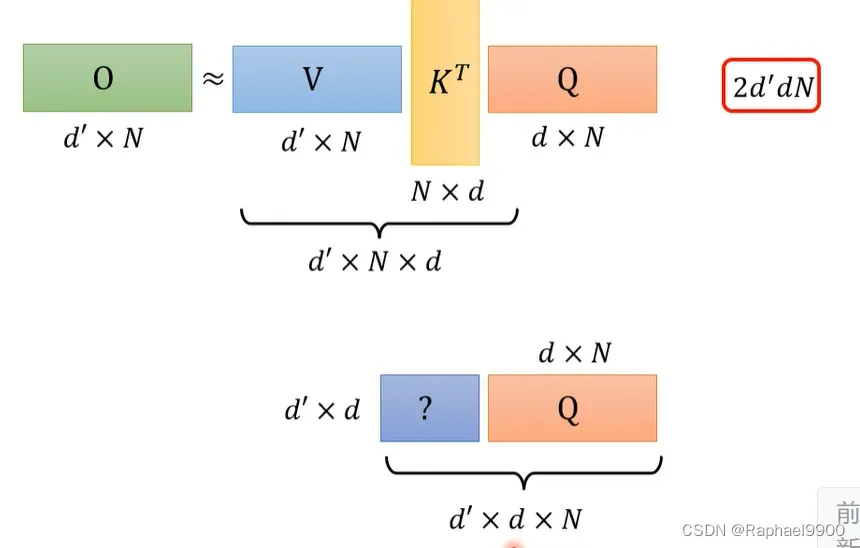
如果加上softmax呢?这个原来的计算过程
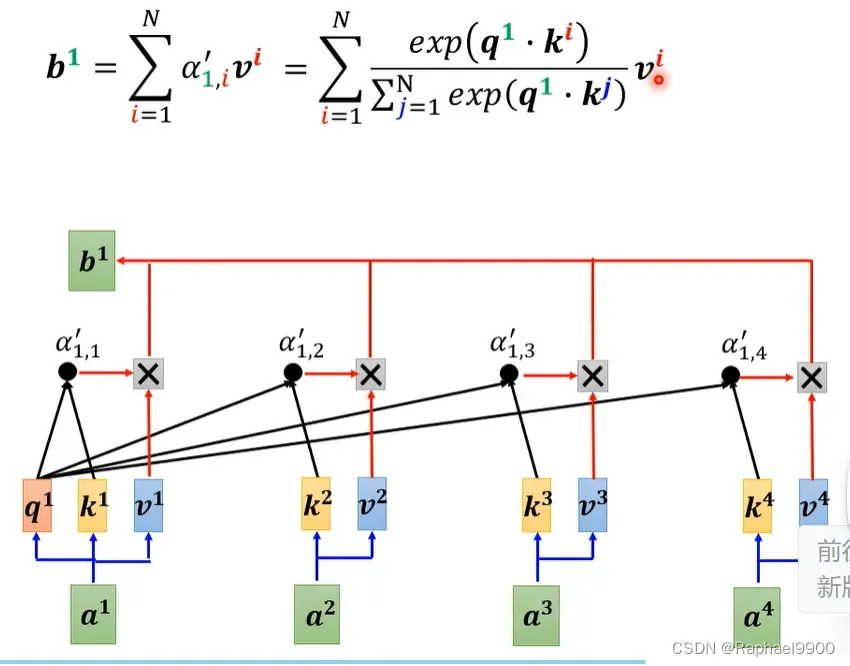
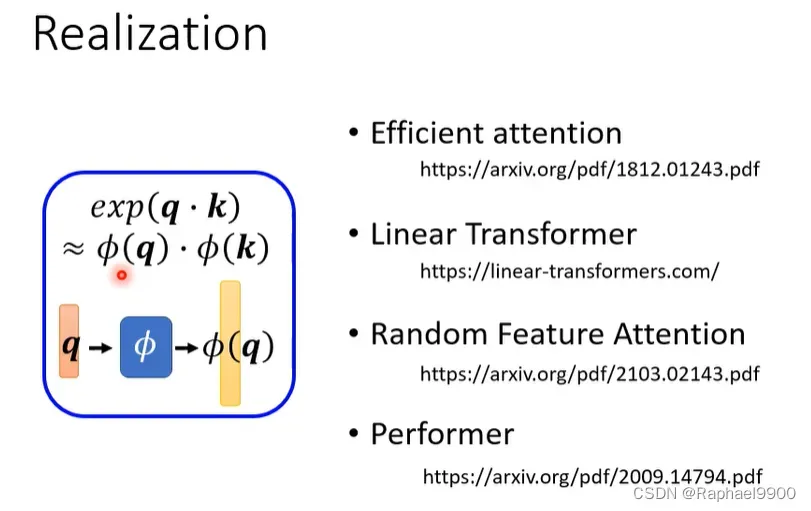
实际上这个过程是可以简化的!我们有φ的方法:把指数expornatial的矩阵运算变成φ的点积。
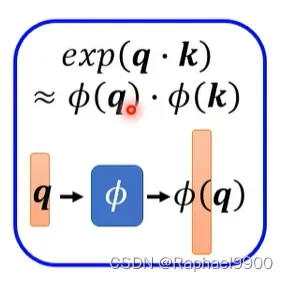
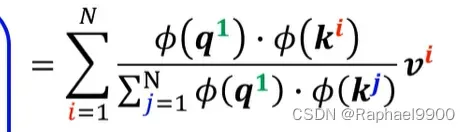
然后我们发现,在分母的地方没有出现i,那就能把i提到上面!
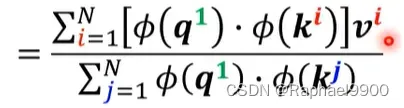
然后看分母,发现q跟j也没有关系,也可以提出来,只求k求和!
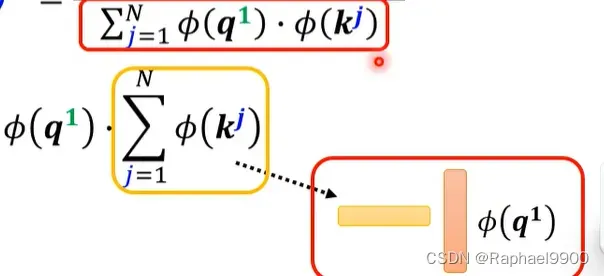
看分子,我们展开之后,把q相同的项相乘

可以看出来,括号里的式子可以看出是一个向量v的权重和。那有几个v向量呢?由有几个q决定!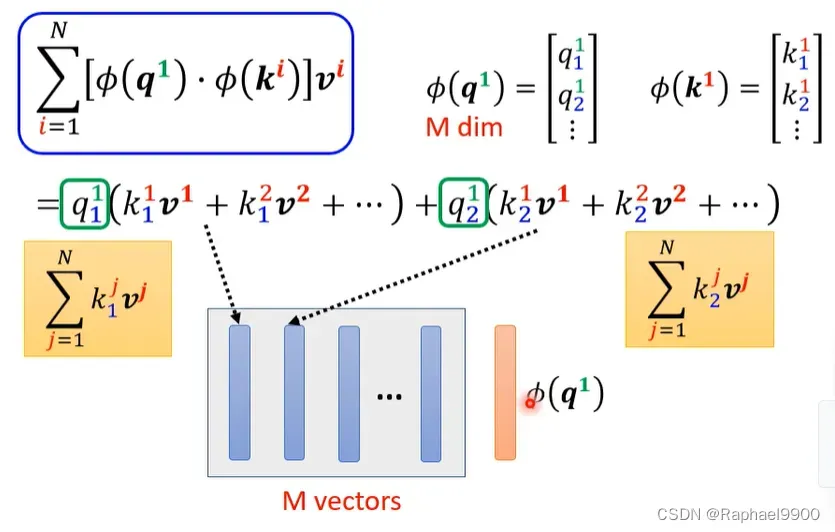
我们再来看看,事实上b跟只涉及q这个矩阵,而其他矩阵相乘只需要计算一次!
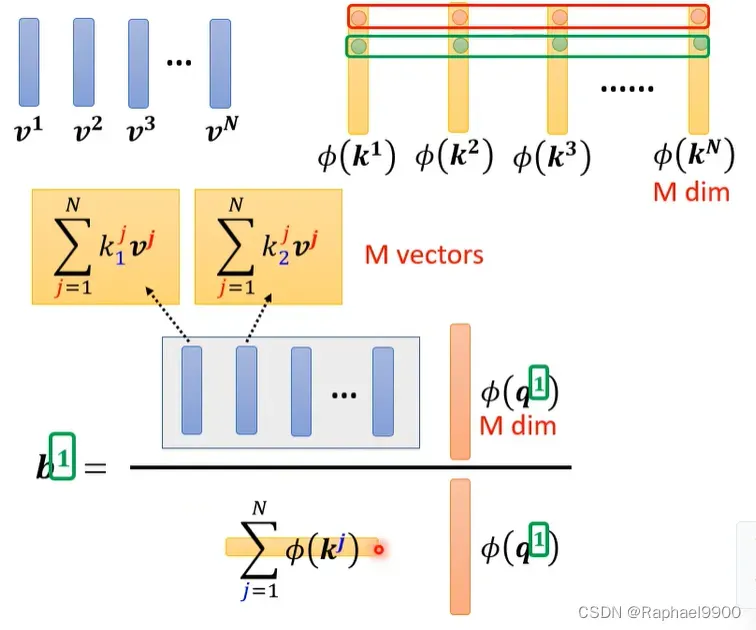
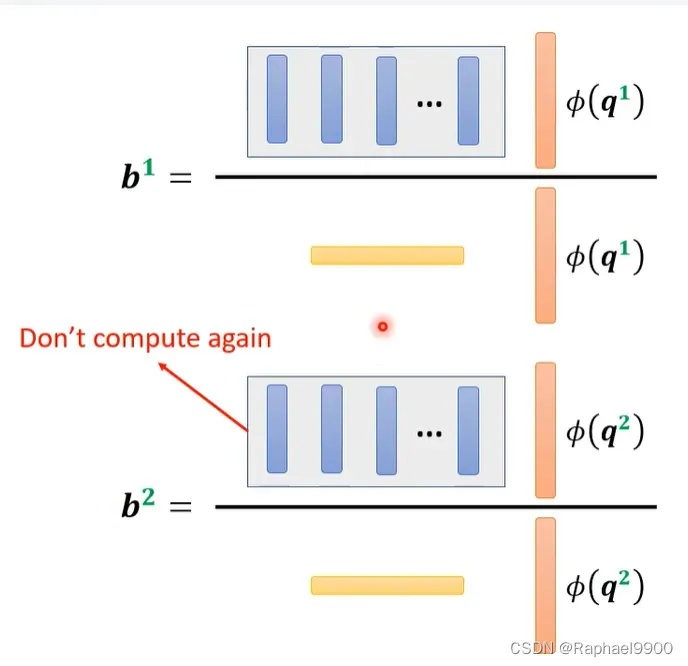
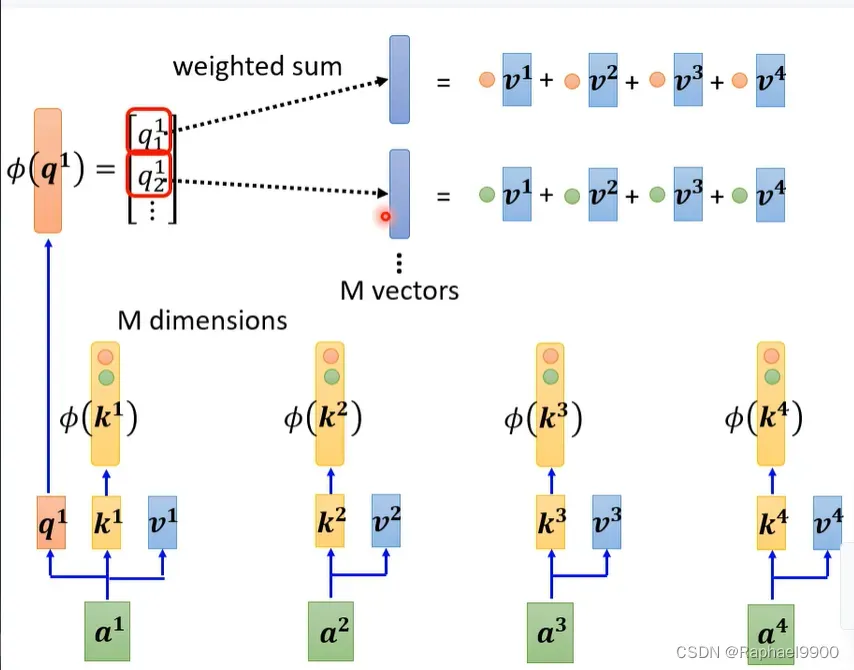
也就是说我们的每个输入只用分别计算q,而其他的不用重复计算啦!但是我们要选择适当的φ才能求得跟原来的网络相似的结果!
那怎么选择φ呢?以下有很多方法
synthesizer
我们真的必须要q和k去计算attention吗?不一定,可以用synthesizer。那我们的这个矩阵怎么出来呢,可以直接吧attention matrix作为网络参数的一部分,而不是求出来的,这样的performance也没有很大的区别。

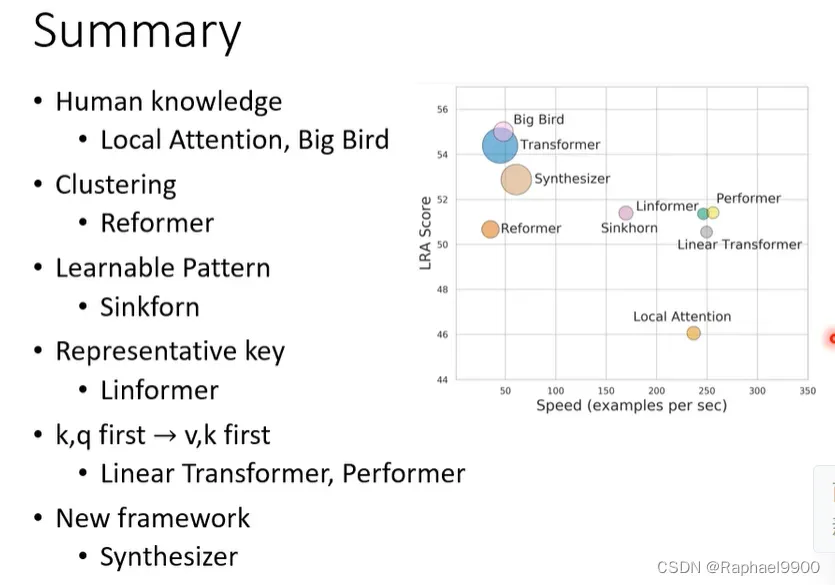
横轴是速度,纵轴是分数,圈圈大小是attention数目。
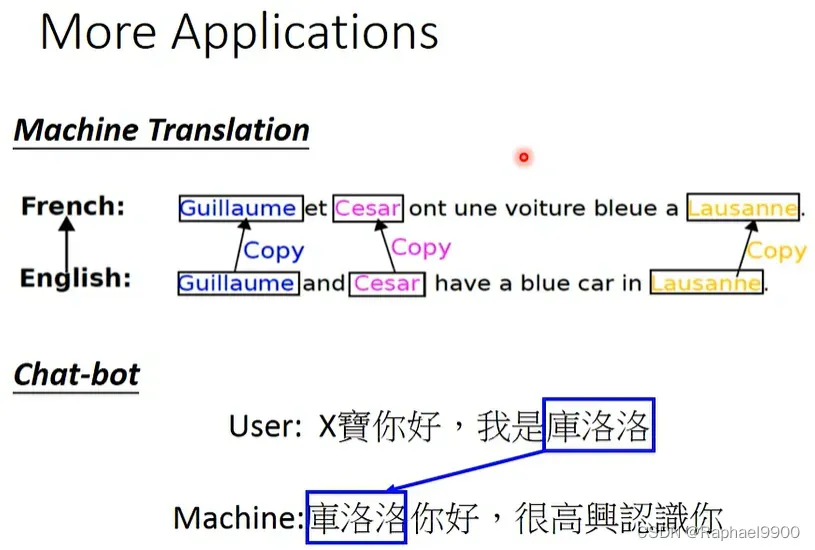
二、non-autoregressive sequence generation非自回归序列生成
conditional sequence generation条件序列生成
(1)输入语音序列(condition),输出中文序列(sequence modeling)。
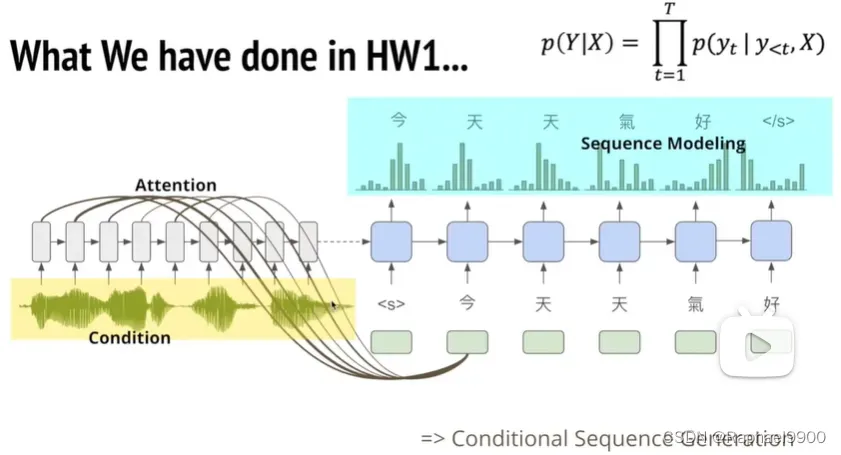
(2)输入一张图,输出这张图的内容,这是一个image caption generation。
(3)输入一段英文,输出中文意思,这是一个machine translation。

我们在翻译的时候一般都用autoregressive model。如果是RNN,我们就是逐步输入和逐步输出的。
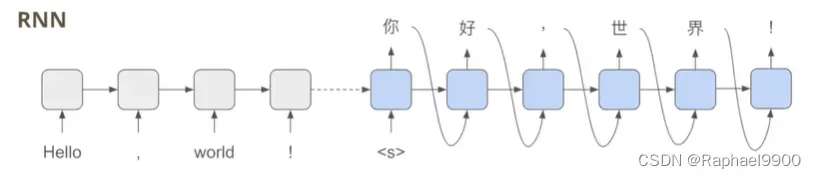
在transformer里面,虽然是吧输入一次性输入到encoder里面,但是decoder还是要逐步输出(依赖前一个输出)。
这样就会很浪费时间!
那我们能不能让他一次性输入和输出呢?non-autoregressive model。我们可以让encoder随意预测一个长度,encoder输入就是放在position embedding。
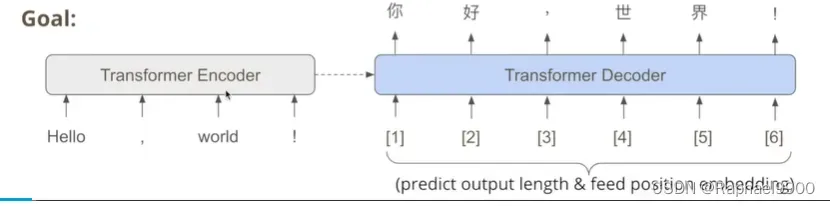
问题
在文字转图片的任务里面,模型学习到的是一个双头火车!这就很奇妙啦。

实际上,我们的输出相互之间没有什么依赖,我们希望输出第二个能看见第一个位置的值。另外,我们希望输出层中的每个神经元对应一个像素,而不是会出现两个一模一样的东西!
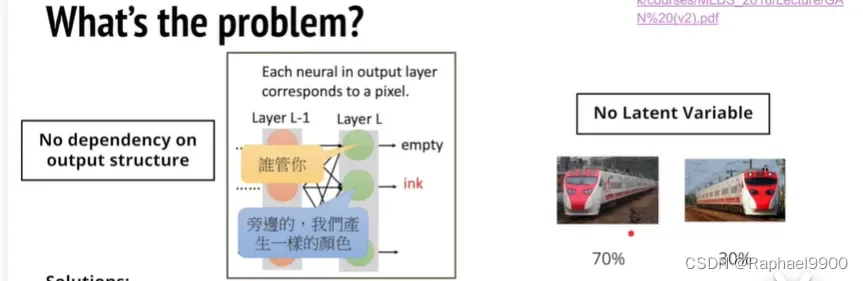
如果我们用GAN的方法就能实现这种依赖,GAN(autoregressive model之一)是能让generator输出结构的方法。在我们描述的时候,可能不知道需要显示左边还是右边的火车(no latent variable),这个模型内部可能自己预测很大可能是左边的火车,但是因为没有随机的机制,所以到了最后的一个隐藏层,我们得到的还是两个火车的叠加!为什么autoregressive model没有这个问题呢?因为autoregressive model会在每个时间点做一个sample的动作,他会挑选最大几率的一个,抛弃其他的。不管GAN还是conditional GAN,我们在输入的时候都要输入一个噪声(normal distribution z)到G,让模型事先决定生成的方向。所以这两个方法就会避开上面的问题。

我们在翻译的时候,想要将英文输出为中文,比如说,输入hello,一般我们的输出会有很多种答复。那怎么确定输出哪一个呢?在autoregressive model里面会学习到,输入hello的时候,哈和你、罗和好的几率差不多大,那这样会不会组合错误呢?会!这种问题叫做multi-modality problem。这是本文主要解决的问题。
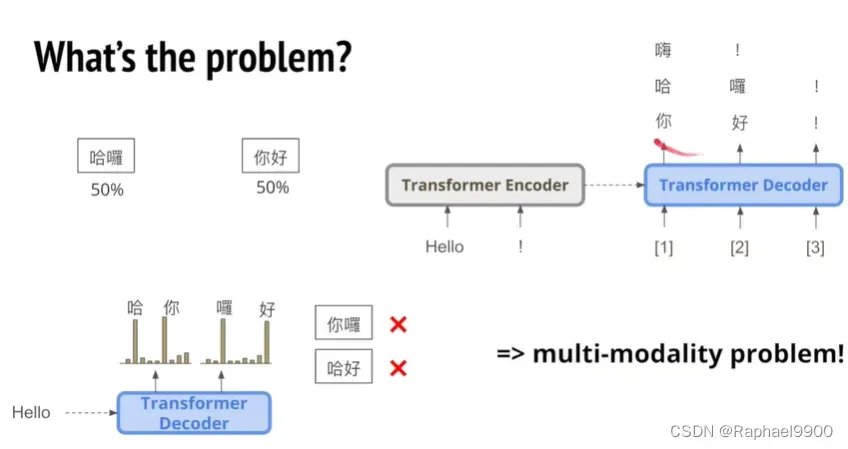
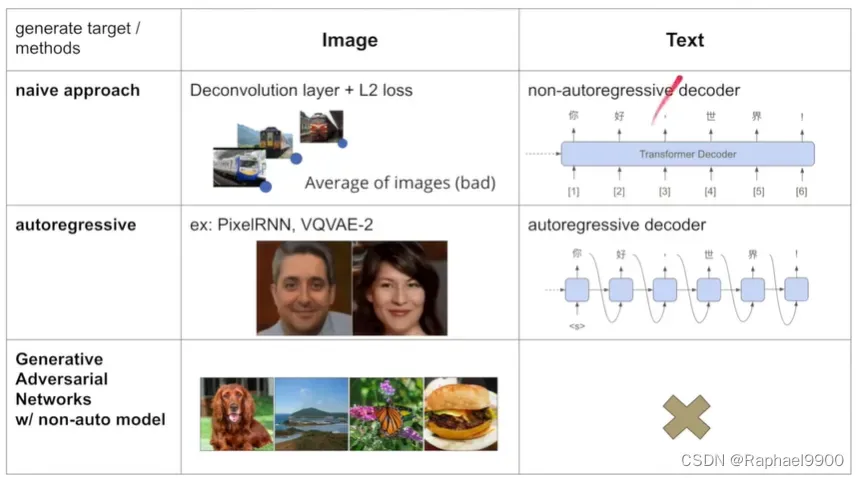
假如我们想要从一个模型里面生成一张图片,用最简单的方法,deconvolution layer +L2 loss,可能会生成模糊图片(生成的图片是很多图片的平均)。对应在文字上的就是,我们翻译的文字是各种可能的结果的叠加。如果我们用autoregressive model就能生成很好的图片,对应到文字上就是我们需要一个个输出文字。除此之外GAN也能生成很好的图片。在做GAN的时候,我们的结构可以用deconvolution layer +L2 loss,而不用autoregressive model,结果也很好。但是目前GAN没有用于文字。
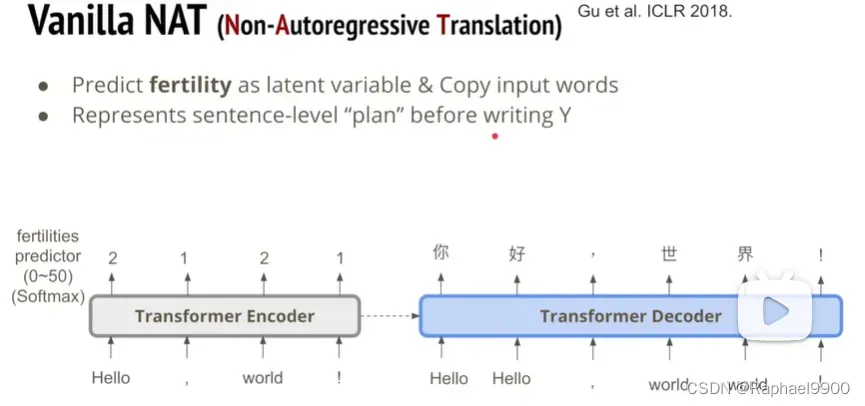
对于文字翻译来说,我们希望用第一种简单的方法来实现。在输入的地方,我们对于每个encoder的输入向量都预测一个数字,对应到decoder的输出的对应位置。在我们预测完成之后,就对输入进行复制到decoder的输入,那么最后我们预测的数字总和就是我们的输出的长度。这种其实代表了我们的decoder对翻译的事先规划。
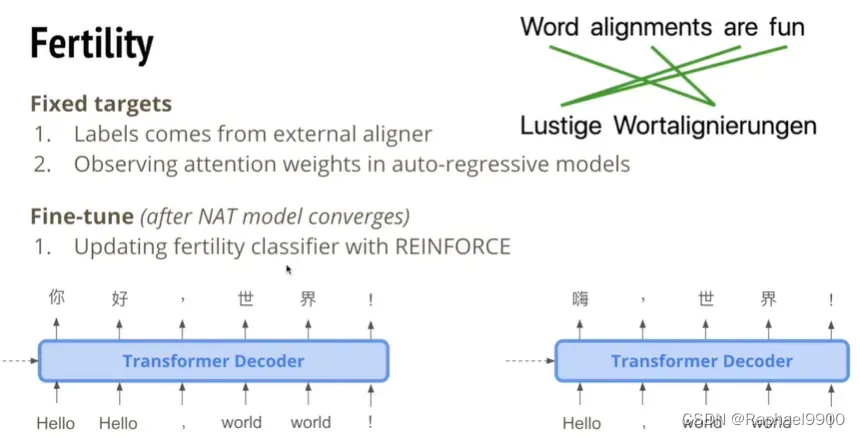
1、fertility
我们要怎么训练呢?可以用一个外部的工具,对于输入我们预测输出有几个字。也可以直接训练一个autoregressive model观察attention weight是怎么分布的。从外部工具得到我们想要的fine-tune,目标不一样。我们在模型收敛之后会做fine-tune,也就是用reinforce的loss加在fertility classifier上面。
2、sequence-level knowledge distillation
knowledge distillation
如果我们想要训练一个小模型,想要小模型的表现跟大模型一样好。那就把小模型当做学生,大模型 作为老师。小模型在训练的时候,把输入给大模型,让大模型预测出他预测的概率分布。然后让小模型直接学这个概率分布,那小模型就会学的比较好。这个是knowledge distillation在做的事情。
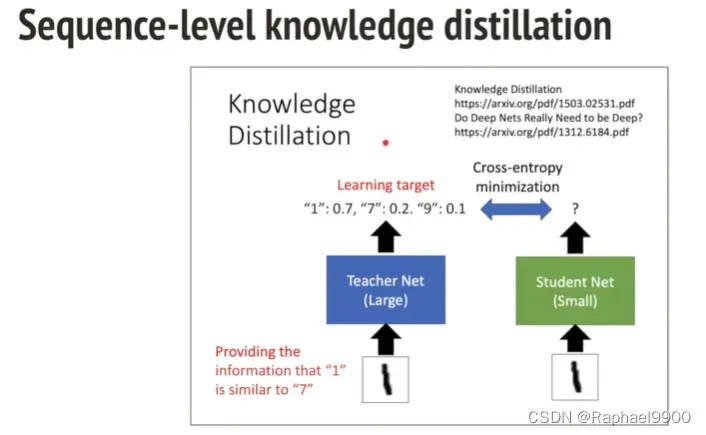
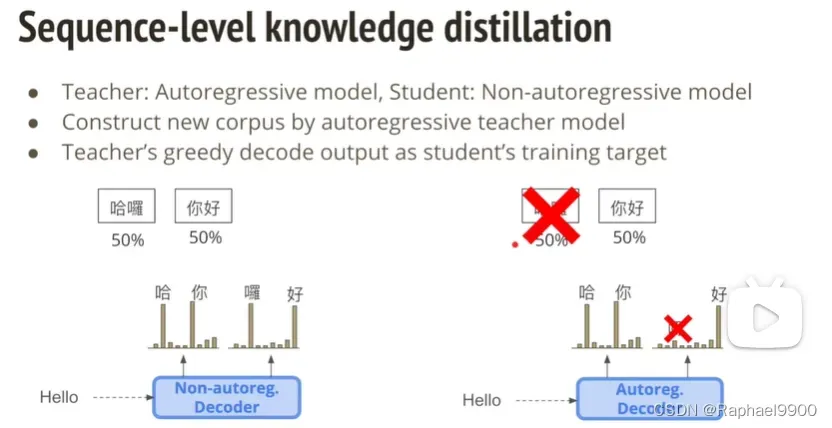
在sequence-level knowledge distillation里面,教师模型是autoregressive model,学生模型是non-autoregressive model。这里跟knowledge distillation不一样,学生模型不学习教师模型输出的概率分布。而是让教师模型把corpus里面的每一句话用greedy decode的方式预测,然后让学生模型把输出的这个结果作为正确答案训练。为什么用non-autoregressive model解决刚才的multi-modality问题呢?multi-modality problem相互之间没有依赖,错误记录很大。如果数据集事先给了autoregressive model做decode的话,那概率分布就会不一样,就避免了模型的错误!
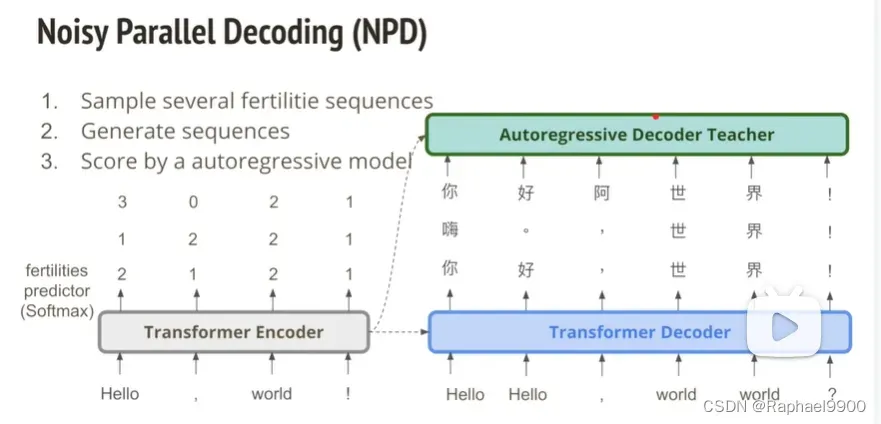
(3)noisy parallel decoding(NPD)
我们在训练好了non-autoregressive model之后,我们的decoder是可以sample不同的数字的(1221),那么就会输出不同的句子!然后这些句子交给教师打分(autoregressive model),选择最好的那个句子作为答案。这里我们涉及了autoregressive model,有没有可能运算就变慢了?
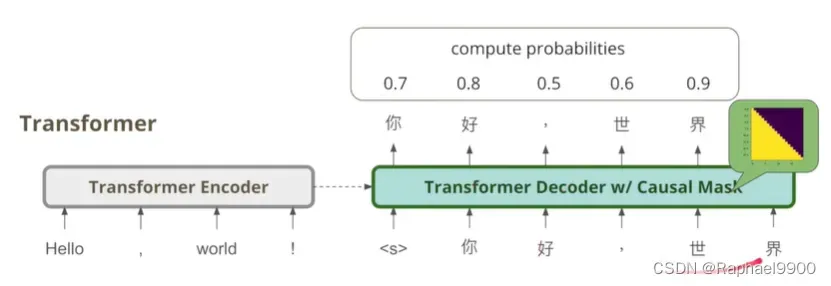
其实如果让autoregressive model去计算已经出现的句子的概率,只需要一个步骤就可以了!我们会用transformer decoder的方式,teacher focing,casual mask,让左边的输入不能涉及右边的输入。这个不怎么需要耗费时间。
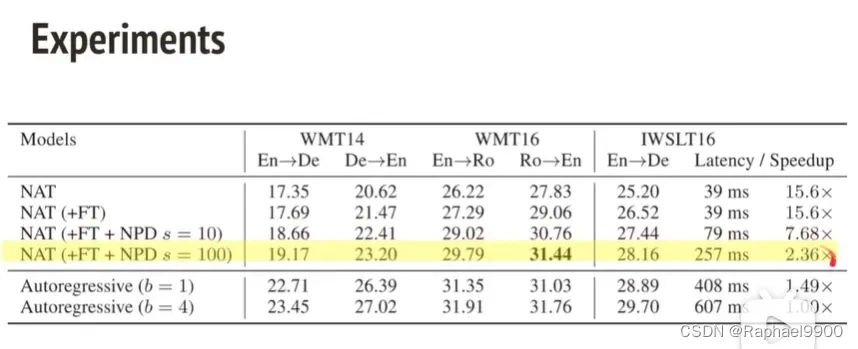
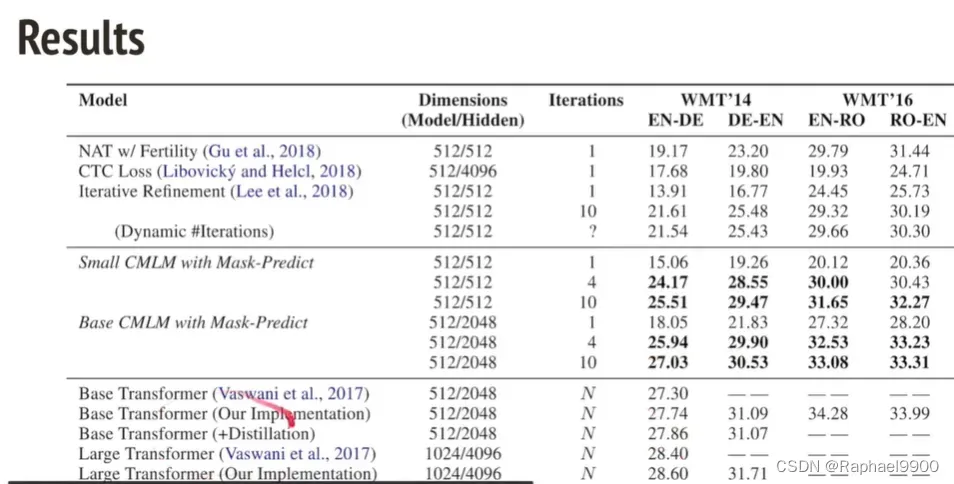
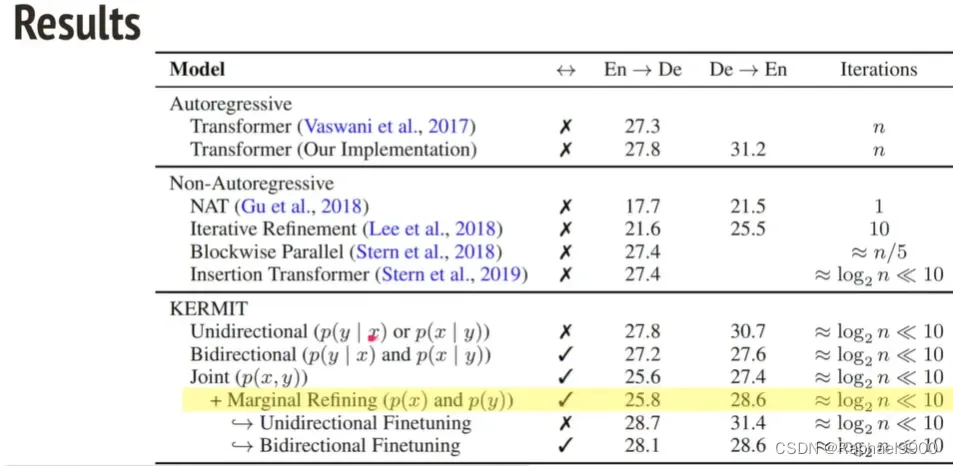
在实验中,第一列En->De的意思是performance,可以看到是递增的;最后一列是速度,基本上是递减的。

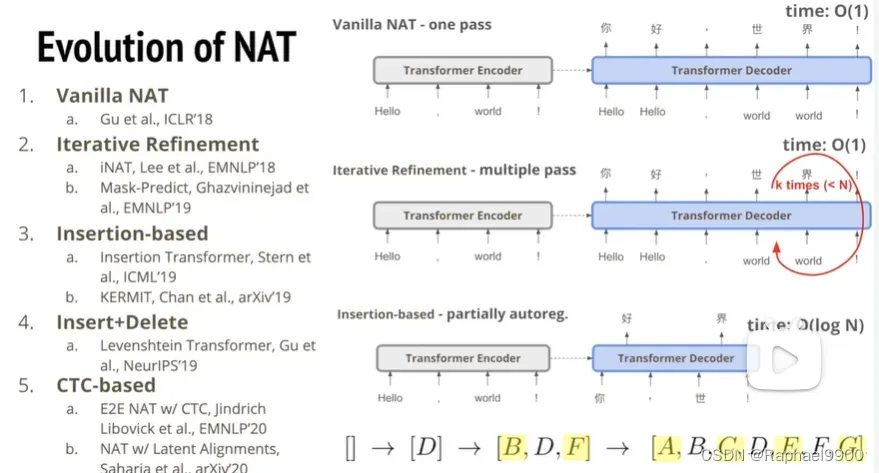
第一种方法是刚才说的,第二种iteration refinement是在生成了一句话的一部分之后作为输入到decoder里面,第三中insertion-based是:输入一个很差的句子到decoder里面,然后在中间进行补足,这种方法没有限制句子应该输出多少个字,所以可以由机器自己决定。第三种方法,比如说我们输入一个D,预测B和F,然后有三个字母之后又能预测ACEG。这种方法时间复杂度logN,但是这种方法如果在输出一个错字的时候就不能修改了。而第二种方法能对我的输出进行修正。所以就出现第四种方法,可以让第三种方法出现错误的时候删除错字。
方法
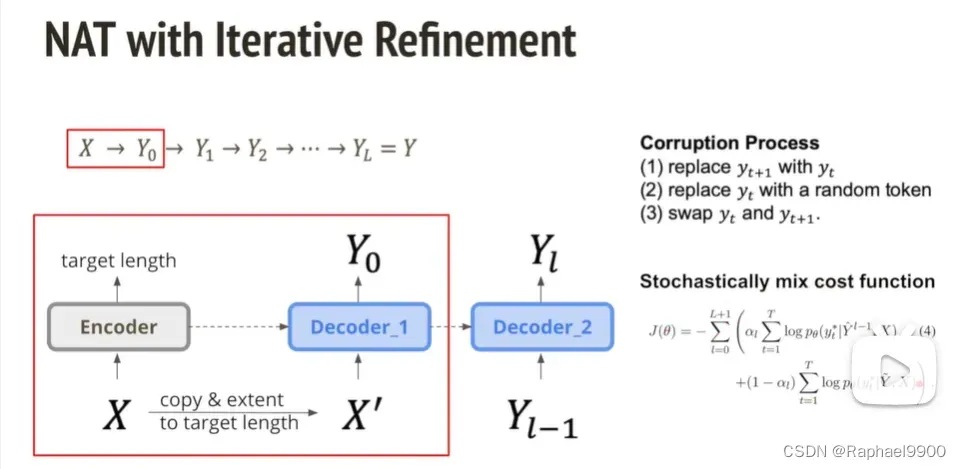
1、iterative refinement
我们输入一个X,输出Y0,然后可以不断对Y进行修正,最后得到最好的结果Y。decoder可以加入噪声(用yt+1替换yt,或者把yt替换成一个随机的token,或者交换yt和yt+1),模型如下:
Mask-Predict
decoder输入的某些vector用mask token替代
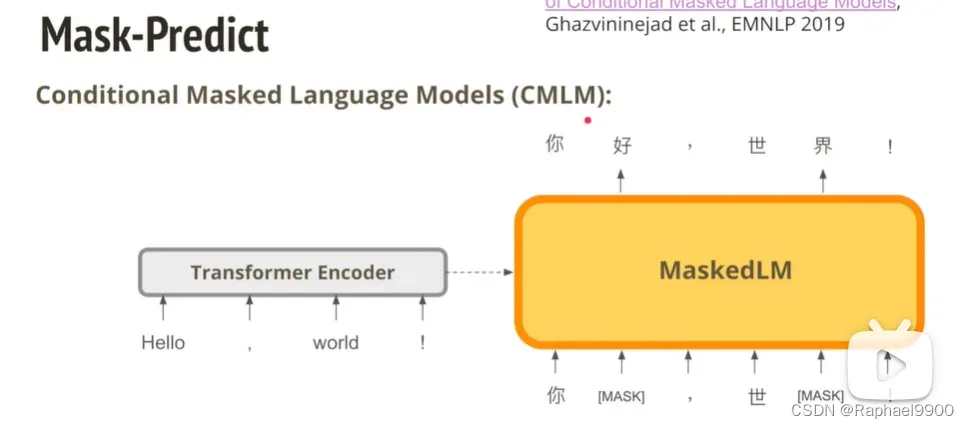
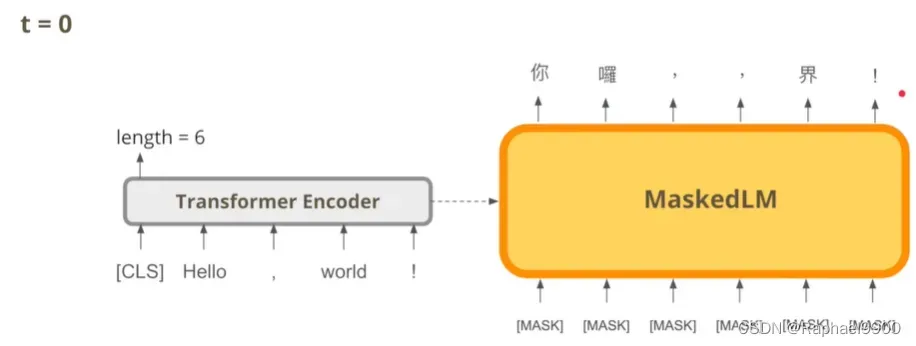
怎么做呢?我们先预测6,然后生成6个mask到decoder里面,得出第一版本的翻译结果(bad)。
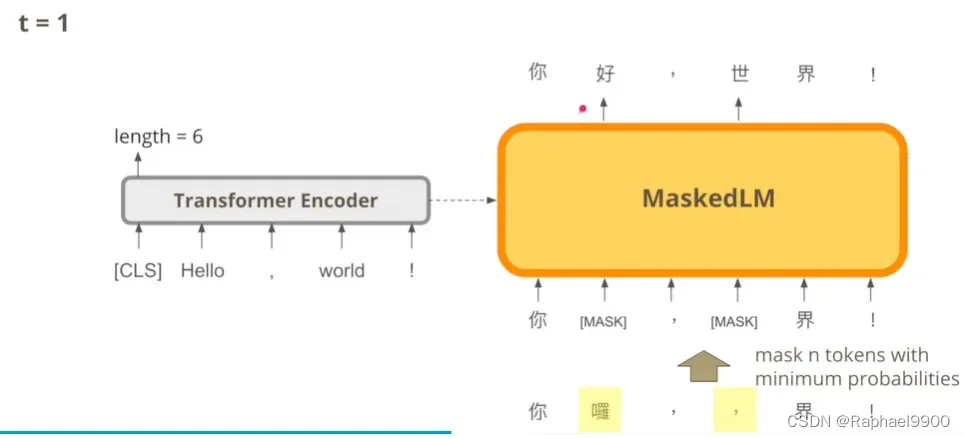
我们把第一个输出放到输入里面,判断刚才生成的字里面哪些概率比较低,把概率低的几个字换成mask token,然后再生成一次结果(better)。
这是每次要mask几个字的方程:刚开始mask的比较多

样例:黄色的字为几率低的,t=2的时候就能得到正确答案了!

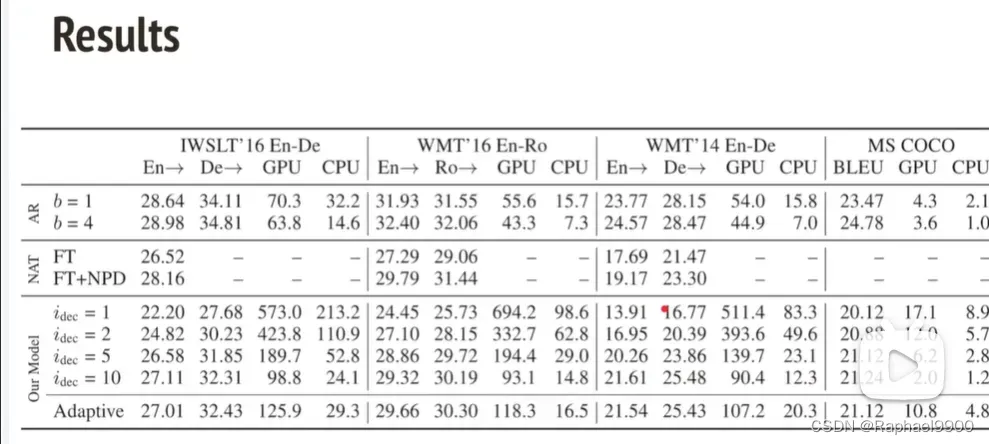
这个方法比前面的好很多!
2、iterative refinement
我们有生成到一半的不成型的句子,输入有几个输出就几个。我们把输出的相邻两个相邻相接,两个字中间就有一个recreation。
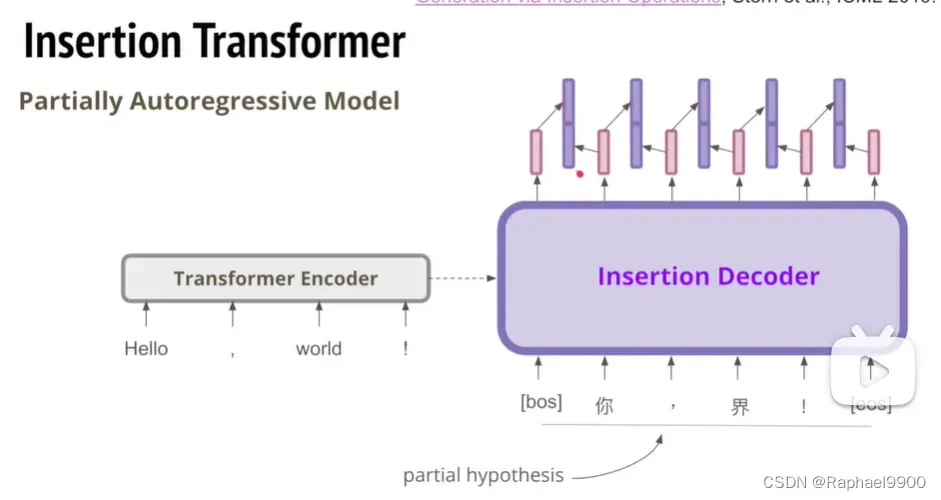
我们用recreation来预测要插入的字,如果没有要插入的字,就是end。如果预测了字,那就插入输入的句子里。
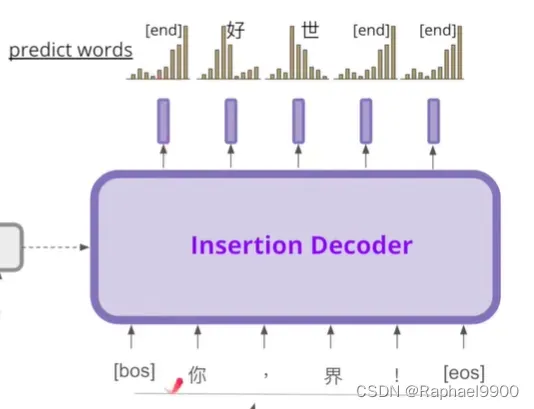
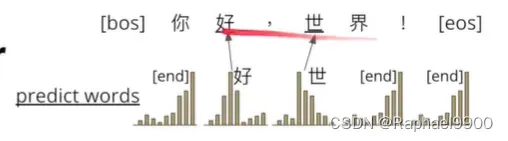
训练
加入我们的数据集里面有十个字,然后做shuffled打乱顺序。选择任意的数字,删除那些任意位置的字,然后把原来的句子还原。

如果删掉两个就算两个loss
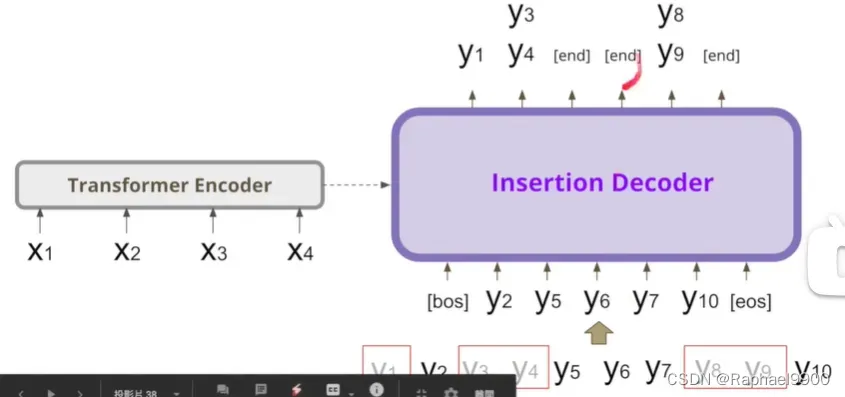
uniform policy的策略是进行loss的取平均,但是我们有个更好的方法——平衡二叉树策略。这个方法类似于下面这个字母的例子,得到中间的更容易算出两边的。所以我们会让中间的mask的权重大一点。


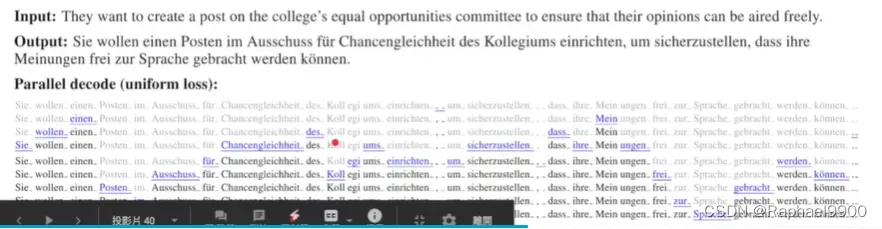

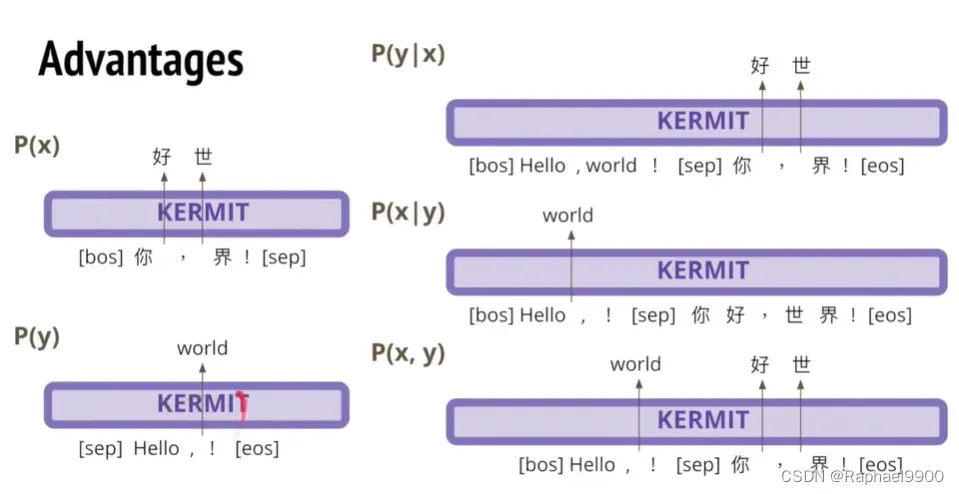
KERMIT
混合encoder和decoder

这种模型可以中英混合翻译
同时训练五个任务有什么好处呢?从下面看好像刚开始没有变好,还变糟糕了。但是训练了多个任务之后,performance突然变好。
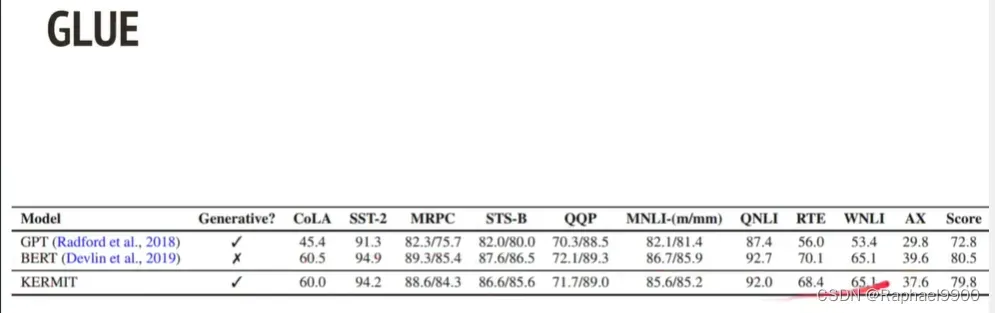
KERMIT还可以做下面的zero-shot clonzeQA
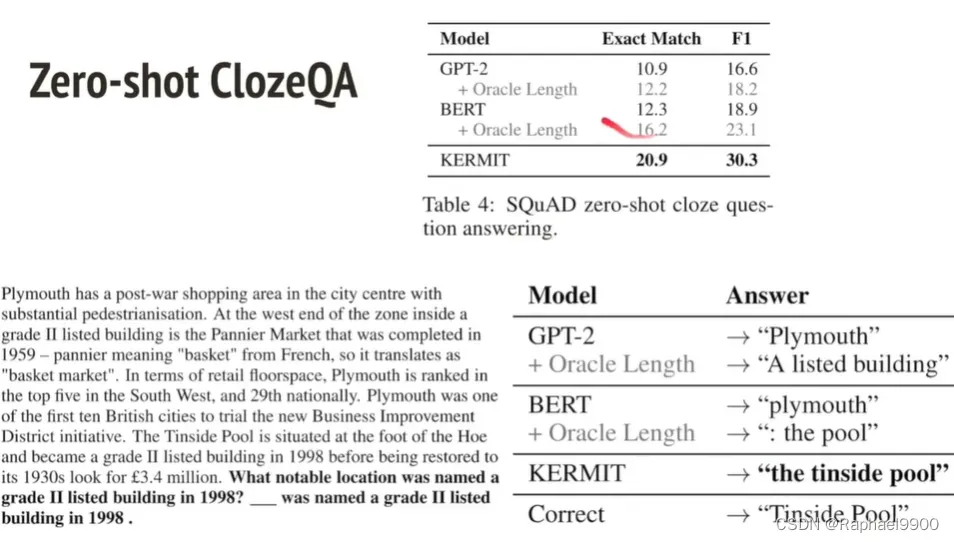

3、insertion +delete=>levenshtein transformer
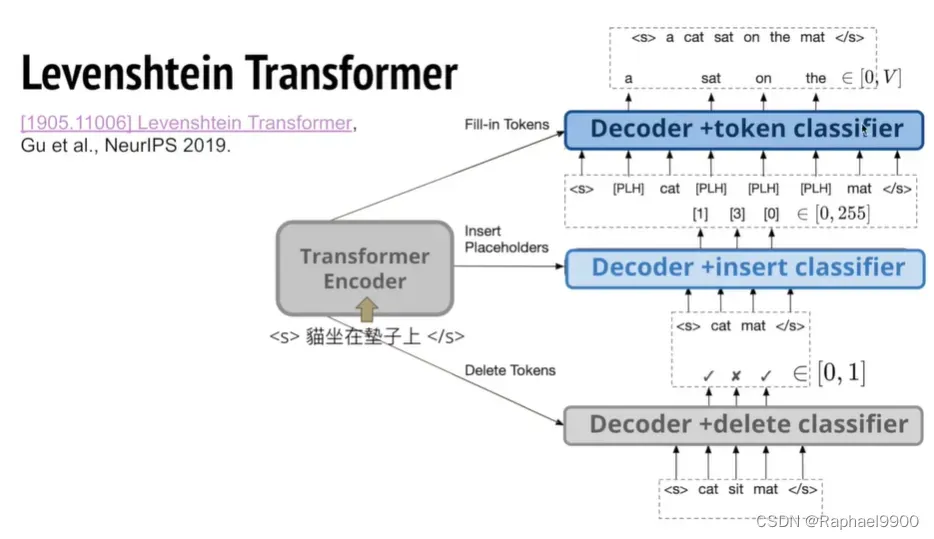
levenshtein distance algorithm

这是一个用法,不过更好的处理是先删除后加入。
imitation learning
我们有两种句子:需要被删除字的句子和需要加入字的句子。看见这个错误的句子,算法产生一个00100000,交给delete classifier去学习。看见一个需要加入的句子,算法就产生0200,交给insert classifier学习。还有在包含占位符place holder(PLH)的句子里面,,我们也能算出需要加入什么字,然后交给token classifier学习。这样就能训练出levenshtein transformer。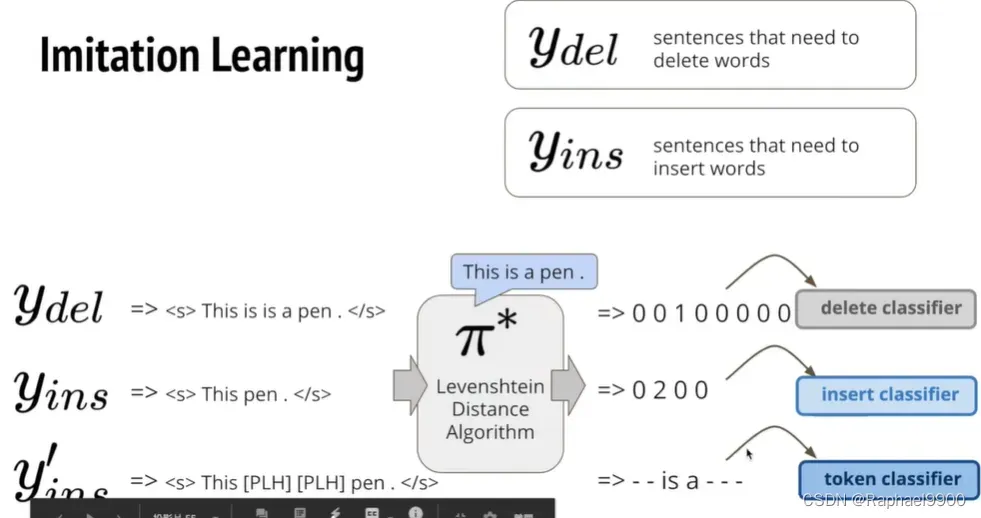

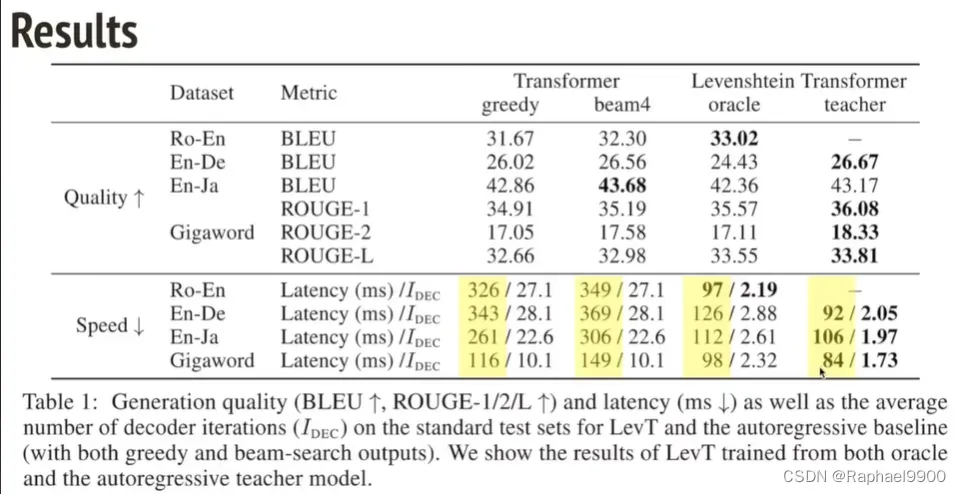
有效!
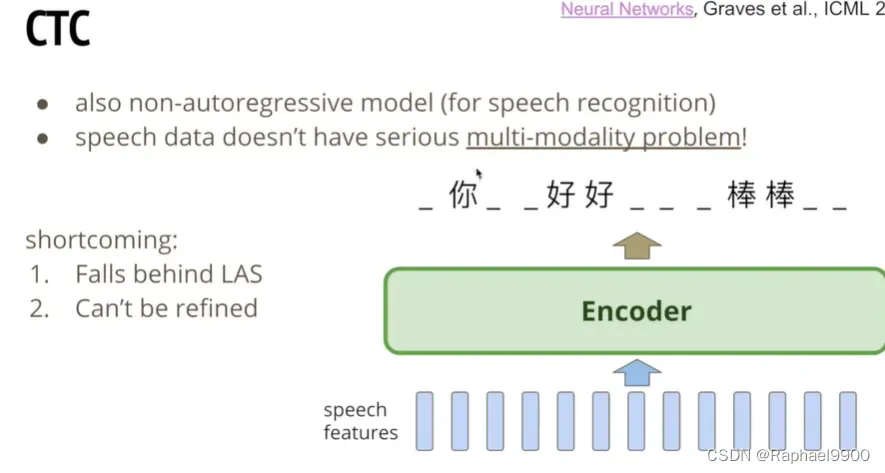
4、CTC
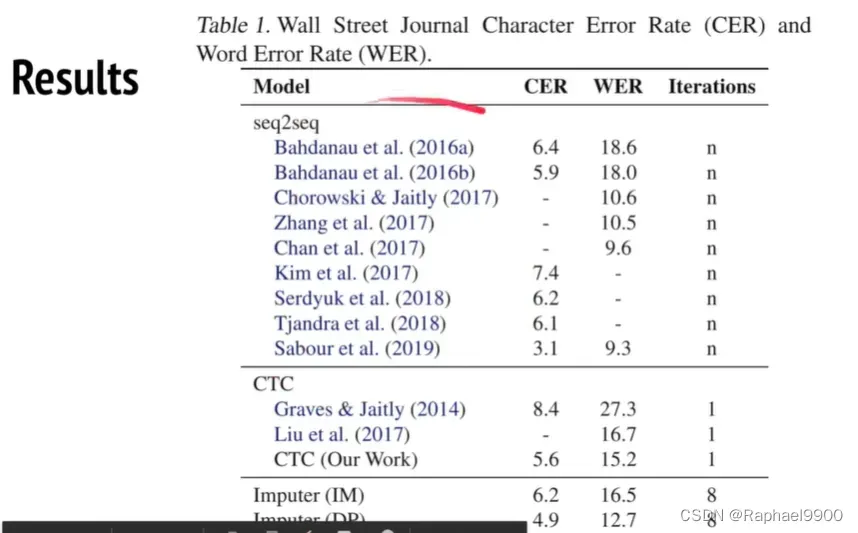
输出可以去掉空格,去掉重复,得到一个句子。CTC经常用于语音识别。我们很少遇到上面出现很多结果的问题,因为一段语音是有正确答案的!缺点:LAS更优;不能做refined,结果文字不能做decoder的输入,也就是输出不能修正。
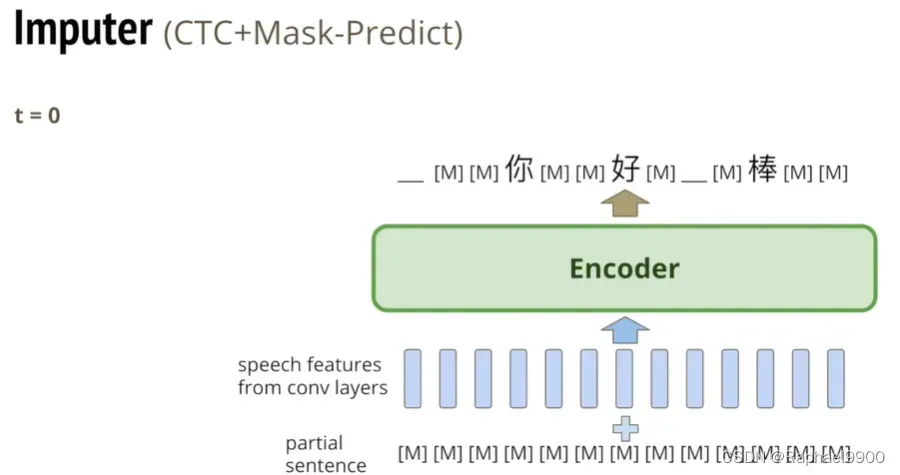
改良:inputer(CTC+mask-predict)
在输入的地方同时加入token sequence,在t=0的时候,token sequence全是mask sequence。
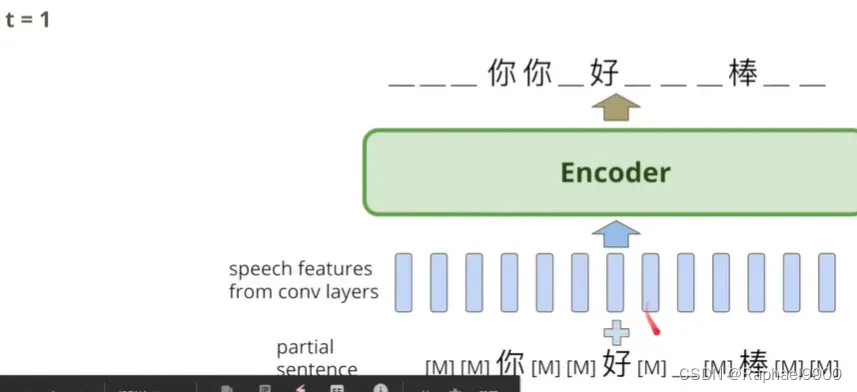
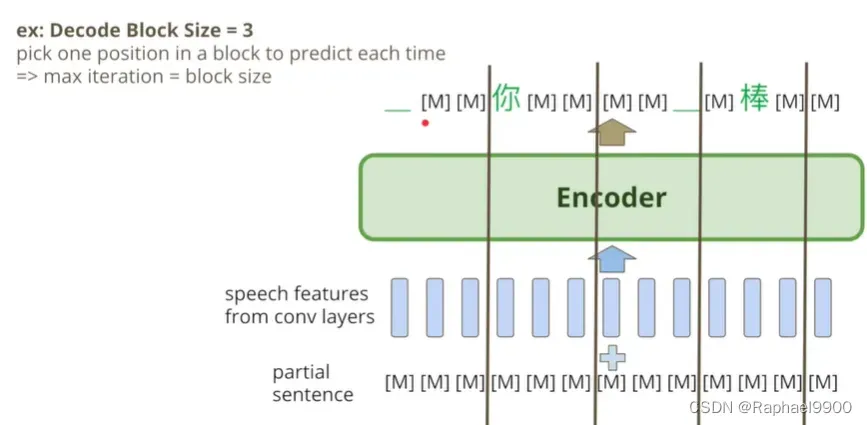
我们限制在每个时间点都把token换成字,block size=3,那三步之内一定可以decoder一个完整的句子!
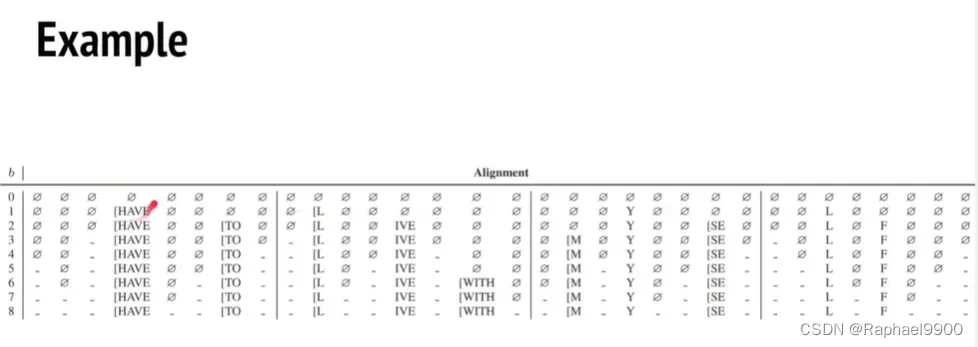
明显改善错误率。
这个imputer也可以放在文字翻译里面:把每个feature分裂成多个feature,类似于语音信号。
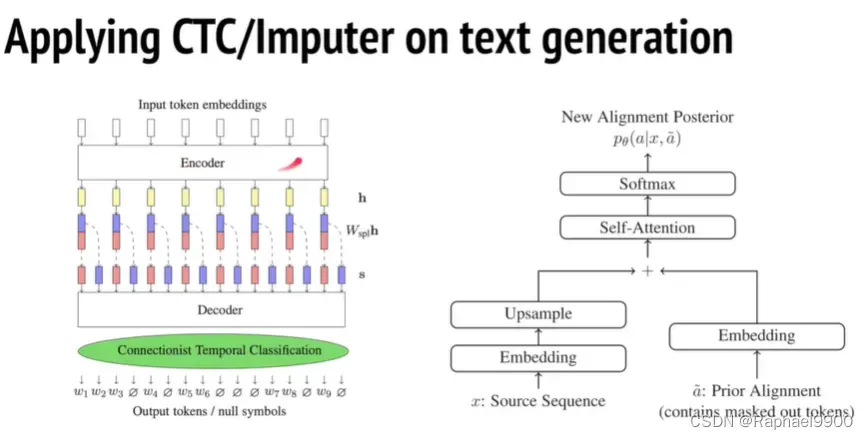
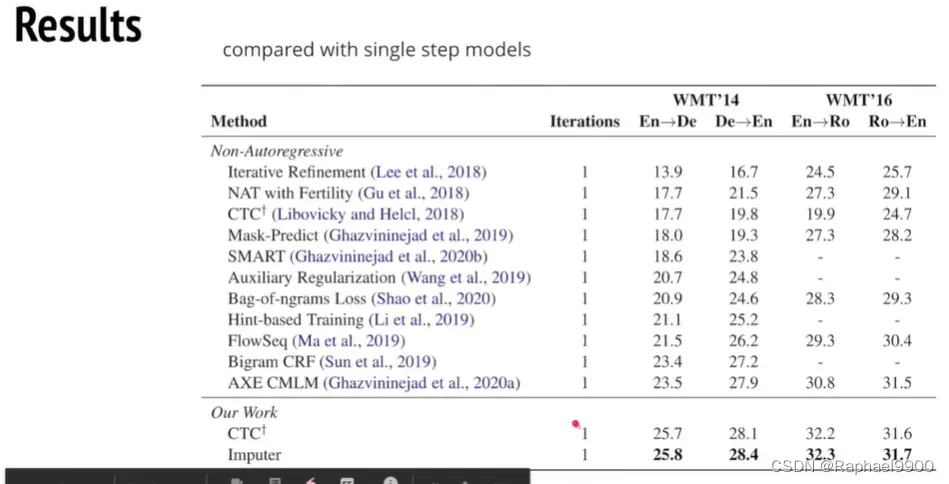
CTC居然能胜过之前的所有的模型!
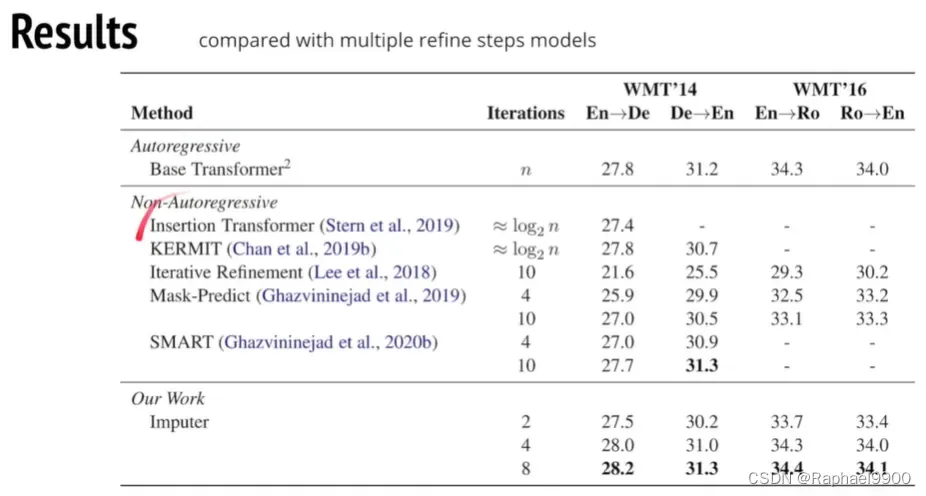
这个方法很强!
下面是三种语言互相翻译:
AT的方法好像不是很能翻译出,在一句话更多是同种语言为多。NAT会分辨出一句话三种语言的区别。

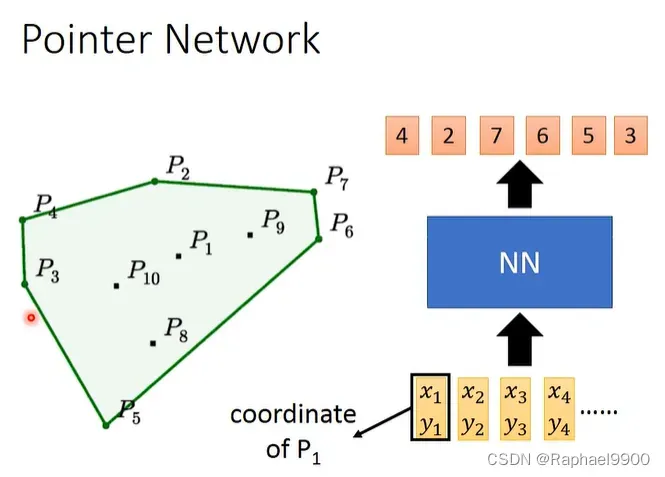
三、pointer network
问题的原始描述是有一堆的点,要找出最外围的点,使得这些点连起来,能够包围所有的点。
我们用NN来解决:输入一大堆数据,经过NN之后,得到一组数据,这些数据就是这些外围点的下标。
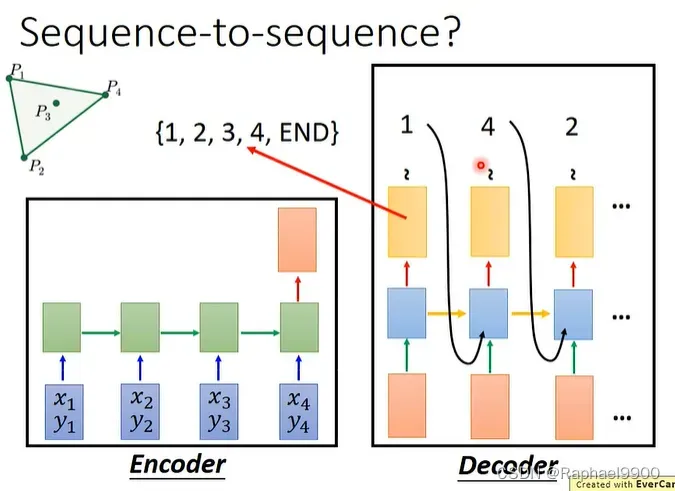
好像可以用seq2seq解决!如果就用这种直接训练,好像跑不起来。因为我们在输出的时候选择限制了,如下图,限制输出{1,2,3,4,end},那当我扩大了数据了?就选不了别的数字啦!
我们可以做下面的调整:加入x0和y0代表end。采用之前的attention-based model,这有个key z0,与每个输入的h产生attention weight
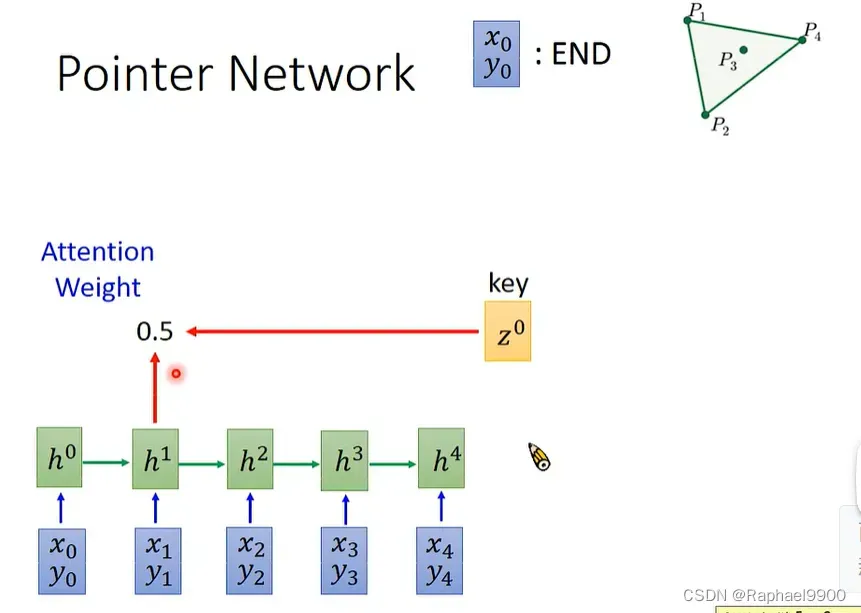
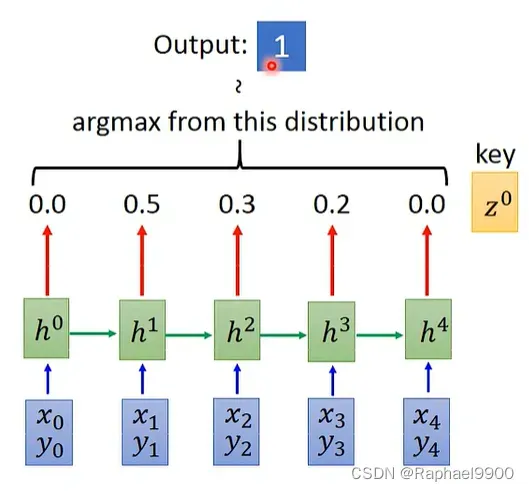
我们把z和h计算得到的结果作为distribution,然后做argmax,输出最大的值的上标!输入有什么,decoder输出就可以选择什么。
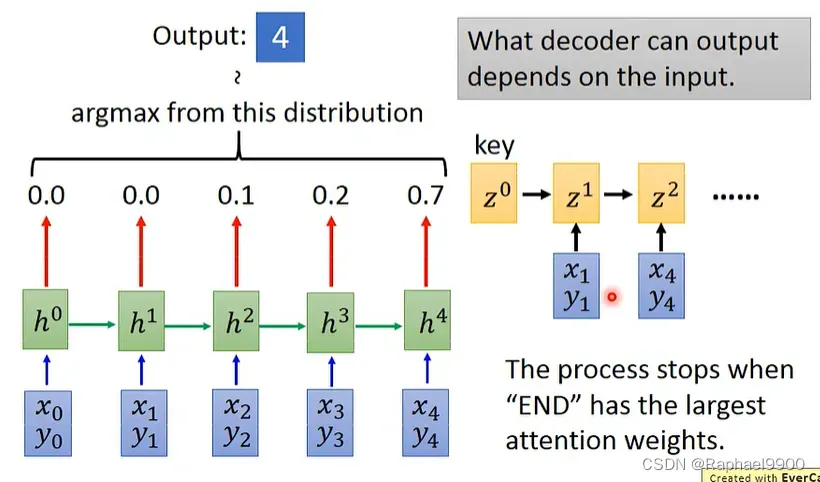
一直输出,知道end是作为最大的输出!
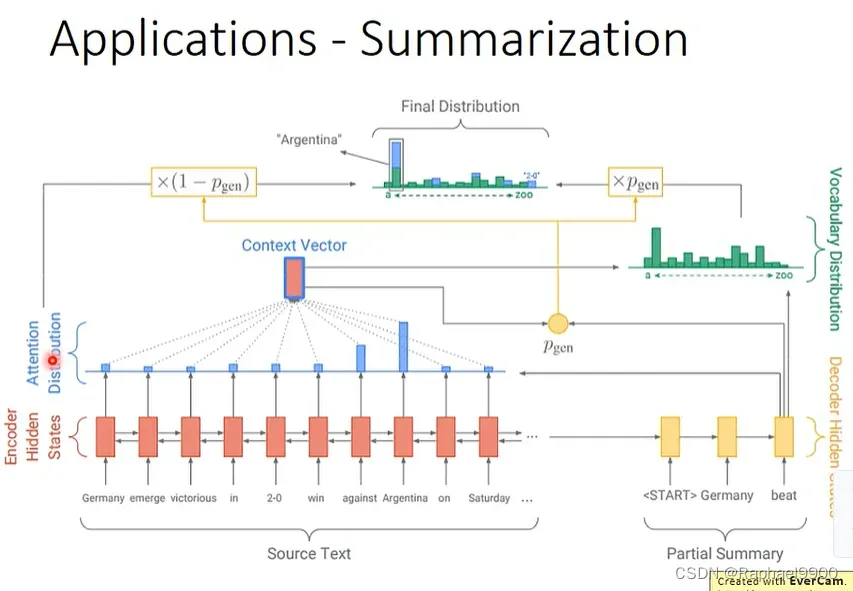
这种方法可以用来做总结summarization
文章出处登录后可见!