openprompt使用记录:分类,生成案例
从安装到使用
官方提供了两种安装方式,我们直接使用git即可。这议严格按照官方教程(参考资料1)来,顺序不能错,有些网上教程版本较旧,没有中间那句,会导致很多依赖库的缺失。同时,在使用的过程中,发现了一些接口与 hugggingface 的版本依赖有关。建议安装之前修改 rwquirements.txt,规定其版本,或者安装后手动降低版本。
transformers==4.20.1
安装过程就是pip install那些,清华大学镜像停止了anaconda支持,所以会中断很多次,解决方案可以看(参考资料2),但是其实就一直暴力重装就行。
git clone https://github.com/thunlp/OpenPrompt.git
cd OpenPrompt
pip install -r requirements.txt
python setup.py install
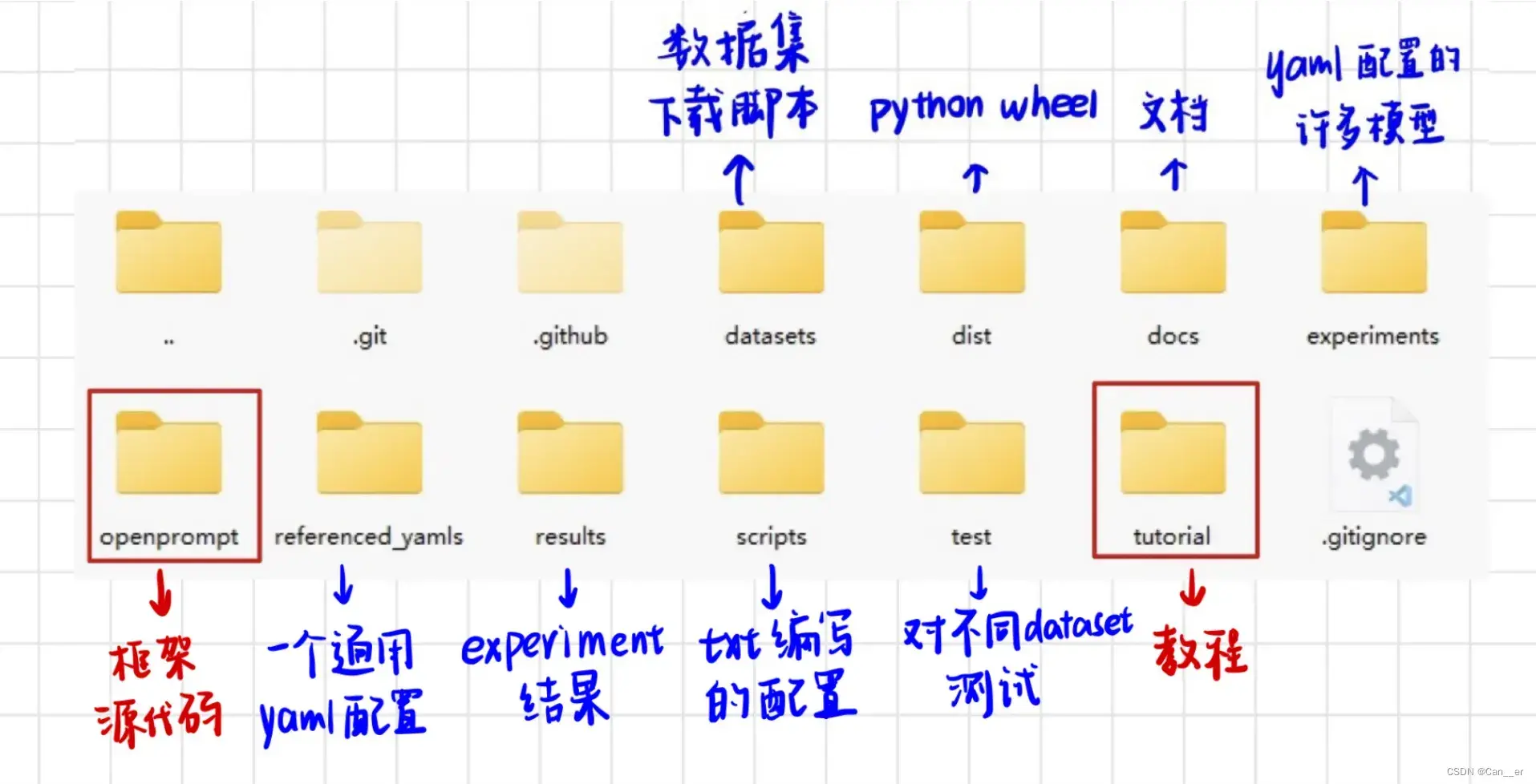
下载后在目录中新建文件夹可以看到整个项目结构,这里从实用性的角度出发,我们主要关注两个红色框框里的即可,主要就是通过跑tutorial里的程序,来逐渐熟悉这个框架。注意tutorial很多代码默认的方式是从磁盘读数据集,需要改一下,改成相对目录,或者利用datasets中下载脚本进行下载,否则会报错。
如果需要了解架构和组织原理,可以参考原论文(参考资料3,4,5)。
这里建议跑里面的实例程序和自己程序之前,先跑官方给的sample,参考资料1里的那个。直接在当前目录创建sample.py即可。这里跟着官方sample演示分类,生成各一个实例。
分类(参考资料6)
第一步:确定NLP任务
确定NLP任务也就是需要确定输出标签以及数据集。这里的输出标签指的是下游任务的输出,也就是y。本例只有两个类别,表示情感正向的positive,和情感负向的negative。
# 第一步:确定NLP任务(简单起见以情感分析作为例子)
import torch
from openprompt.data_utils import InputExample
# 1. 确定类别:也就是确定数据标签,本例只有两个类别,表示情感正向的positive,和情感负向的negative
classes = [
"negative",
"positive"
]
# 2.确定数据集:为了简单起见,这里只有两个例子text_a是数据的输入文本,一些其他数据集可能在一个例子中有多个输入句子
dataset = [
InputExample(
guid = 0,
text_a = "Albert Einstein was one of the greatest intellects of his time.",
),
InputExample(
guid = 1,
text_a = "The film was badly made.",
),
InputExample(
guid = 2,
text_a = "That is wonderful.",
),
]
第二步:确定预训练语言模型
这里加载的是一个训练好的bert语言模型,返回模型、分词器、模型参数、对应模型的包装器。这里需要提一点,因为我们直接只用预训练模型,所以上一步只有测试数据没有训练数据。否则需要加入 label = 作为标签。
# 第二步:定义预训练语言模型(PLMs)作为主干。
from openprompt.plms import load_plm
plm, tokenizer, model_config, WrapperClass = load_plm("bert", "bert-base-cased") # 这里选择的预训练语言模型是bert
第三步:定义模板
这一块对应就是模板工程中的问题了,模板可以从txt中读取构建,也可以直接像下面这样定义。本例采用的格式是 [x],It was [Z],x对应代码中的text_a,应填入输入语句。Z对于mask,是LM的预测结果。
# 第三步:定义模板。
from openprompt.prompts import ManualTemplate
promptTemplate = ManualTemplate(
text = '{"placeholder":"text_a"} It was {"mask"}',
tokenizer = tokenizer,
)
关于这里的key值,可能比较奇怪的一点是论文中提到的 meta 究竟是什么,为什么在具体使用的时候是用的placeholder呢?这里文档中也没有给出详细明确的解释,但是通过源码可以看出来,InputExample 类默认有三个可填充的参数,text_a,text_b和meta,前两者都是一个str,而后者是一个dict,解释为An optional dictionary to store arbitrary extra information for the example。所以,当我们的主要句子可以使用前两者表示的时候,是无需用meta 的。
第四步:答案映射
这一块对应的是答案工程,在这个例子中把消极类投射到单词bad,把积极类投射到单词good, wonderful, great。
# 第四步:定义Verbalizer是另一个重要的
# Verbalizer将原始标签投射到一组lable单词中。在这个例子中把消极类投射到单词bad,把积极类投射到单词good, wonderful, great
from openprompt.prompts import ManualVerbalizer
promptVerbalizer = ManualVerbalizer(
classes = classes,
label_words = {
"negative": ["bad"],
"positive": ["good", "wonderful", "great"],
},
tokenizer = tokenizer,
)
第五步:构造PromptModel
promptModel有三个对象,分别是:PLM, Prompt, Verbalizer,分别对应Prompt研究重点中的三个部分:如何选择语言模型(第二步),如何定义模板(第三步),如何把答案映射至标签(第四步)。
# 第五步:将它们合并到PromptModel中
# 给定任务,现在我们有一个PLM、一个模板和一个Verbalizer,我们将它们合并到PromptModel中。
# 请注意,尽管示例简单地组合了三个模块,但实际上可以在它们之间定义一些复杂的交互。
from openprompt import PromptForClassification
promptModel = PromptForClassification(
template = promptTemplate,
plm = plm,
verbalizer = promptVerbalizer,
)
第六步:构造PromptDataLoade
与数据加载和数据处理相关的内容,PromptDataLoader基本上是pytorch Dataloader的prompt版本,它还包括一个Tokenizer、一个Template和一个TokenizerWrapper,返回可迭代训练/测试的数据集。这里还可以定义如batch_size,max_seq_length等超参数。
# 第六步:定义DataLoader
from openprompt import PromptDataLoader
data_loader = PromptDataLoader(
dataset=dataset,
tokenizer=tokenizer,
template=promptTemplate,
tokenizer_wrapper_class=WrapperClass,
)
第七步:预测
在上述过程中,没有用任何训练数据对Bert进行调整,就实现了零样本的情感分类。传入数据loader和model,使用类似基于Pytorch的其他机器学习一样完成训练和测试即可。
# 第七步:训练和预测:完成了!我们可以像Pytorch中的其他过程一样进行训练和推理。
# making zero-shot inference using pretrained MLM(masked language model) with prompt
promptModel.eval()
with torch.no_grad():
for batch in data_loader:
logits = promptModel(batch)
preds = torch.argmax(logits, dim=-1)
print(classes[preds])
# predictions would be 1, 0 for classes 'positive', 'negative'
经过了上面的项目,我们简单总结一下:在openprompt中,我们的工作就是将DataLoader处理为PromptDataLoader,Model处理为PromptModel,其余的训练,测试就均和pytorch接口融洽了。
下面梳理细节,看一下数据在其中究竟是如何流动并组合的。
首先是DataLoader,他需要的输入是key-value形式的data,template,tokenizer 和 tokenizer_wrapper_class(下图绿色框框标注),以及一些超参数。(参考资料7,8)
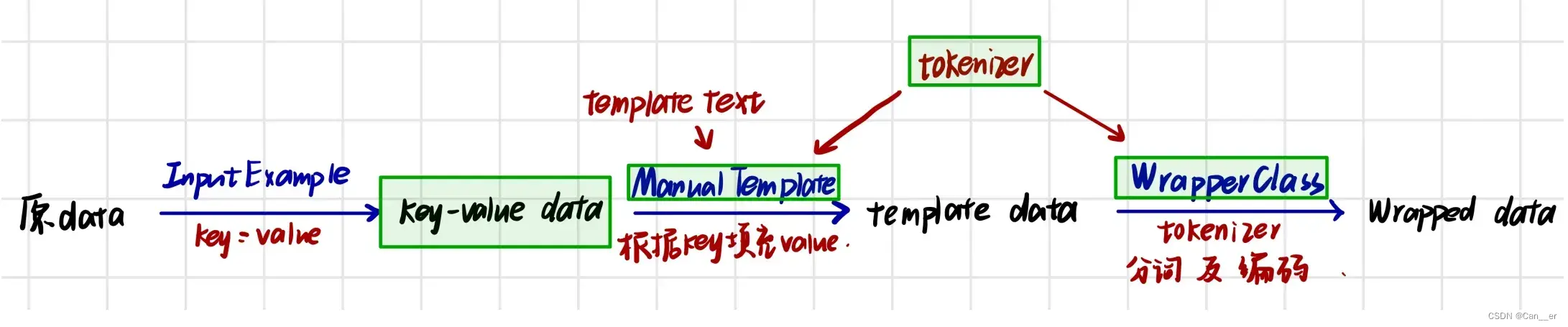
然后考虑PromptModel,他需要的输入是plm,template 和 verbalizer 以及一些超参数。不同于数据的每步处理,这里我们无需关注模型究竟是如何组织的,而更关注如何使用该模型。
生成
生成相比分类麻烦一些,主要是因为其运用了huggingface库函数中的一些接口(注意版本依赖)。这里我们需要先做一个工作:安装nltk的依赖(参考资料9),防止某些包找不到。
下面将通过一个简单的,但更接近实际应用的生成案例,带领大家对openprompt做更深入的了解。该案例使用的是webnlg数据集(参考资料10),由三元组(实体和它们之间的关系)以及自然语言文本形式的相应事实组成。这里我们加载数据集,并加载预训练模型t5。
import torch
from openprompt.data_utils.conditional_generation_dataset import WebNLGProcessor
dataset = {}
dataset['train'] = WebNLGProcessor().get_train_examples("./datasets/CondGen/webnlg_2017/")
dataset['test'] = WebNLGProcessor().get_test_examples("./datasets/CondGen/webnlg_2017/")
# load a pretrained model, its tokenizer, its config, and its TokenzerWrapper by one function
from openprompt.plms import load_plm
plm, tokenizer, model_config, WrapperClass = load_plm("t5", "t5-base")
数据的具体组成为json格式,我们可以直接使用openprompt中提供的库函数 get_train_examples ,加载该数据集并进行InputExample的转化,最终得到的形式如下:

可以看到,我们要利用 text_a 中的信息去生成 tgt_text。很自然的可以定义模板如下(这里是否使用eos是无关紧要的):
from openprompt.prompts import ManualTemplate
mytemplate = ManualTemplate(tokenizer=tokenizer, text=' {"placeholder":"text_a"} {"special": "<eos>"} {"mask"} ')
然而,这里将介绍另外一种更适合 预训练模型+微调 范式的Template,这是支持T5和其他编码器 – 解码器模型的实现,只要它们的块允许注入,就可以在不接触代码库的情况下进行微调。不过需要注意一点是, However, it may fail to work when used in DataParallel model. Please use it using single gpu or model-parallel training.,不过在官方仓库中的issue中,给出了解决方案(参考资料11),在使用并行训练时候可以参考。
from openprompt.prompts.prefix_tuning_template import PrefixTuningTemplate
mytemplate = PrefixTuningTemplate(model=plm, tokenizer=tokenizer, text=' {"placeholder":"text_a"} {"special": "<eos>"} {"mask"} ', using_decoder_past_key_values=True)
下面进行DataLoader的包装,普通参数不再进行解释,只需要注意predict_eos_token,如果自己使用的数据集中,或者定义的模板最后不包含结束符,需要确保传递predict_eos_token=True,否则模型可能无法停止生成。
from openprompt import PromptDataLoader
train_dataloader = PromptDataLoader(dataset=dataset["train"], template=mytemplate, tokenizer=tokenizer,
tokenizer_wrapper_class=WrapperClass, max_seq_length=256, decoder_max_length=256,
batch_size=5,shuffle=True, teacher_forcing=True, predict_eos_token=True,
truncate_method="head")
test_dataloader = PromptDataLoader(dataset=dataset["test"], template=mytemplate, tokenizer=tokenizer,
tokenizer_wrapper_class=WrapperClass, max_seq_length=256, decoder_max_length=256,
batch_size=5,shuffle=False, teacher_forcing=False, predict_eos_token=True,
truncate_method="head")
最后定义模型,相比 PromptForClassification 而言,PromptForGeneration 多了生成相关的方法和 gen_config参数。
# load the pipeline model PromptForGeneration.
from openprompt import PromptForGeneration
prompt_model = PromptForGeneration(plm=plm,template=mytemplate, freeze_plm=False, tokenizer=tokenizer, plm_eval_mode=False)
这里想详细介绍一下除去模板,分词和预训练模型三者之外的两个超参数,他们的开关与否往往影响着超参数的数量,以及,是否能正常的运行起来你的模型,也是在实验过程中如果不了解,经常犯的一个错误(参考资料12)。我查阅了源码,将其放在这里,进行区分。
if freeze_plm:
for param in self.plm.parameters():
param.requires_grad = False
if plm_eval_mode:
self.plm.eval()
for param in self.plm.parameters():
param.requires_grad = False
我们需要了解的是(参考资料13),pytorch中,对于model的eval方法主要是针对某些在train和predict两个阶段会有不同参数的层。比如Dropout层和BN层。使用 plm.eval() 使得这些层的参数固定不变,而对变量 torch.autograd.Variable(tensor,requires_grad=True or False) 进行参数设置,是指定的要不要更新这个参数,也就是要不要通过梯度(迭代)来更新。关于pytorch中计算梯度的具体信息,感兴趣可以看参考资料1,有很详尽的介绍。
回到这里,无论设置 freeze_plm 还是 plm_eval_mode 为True,都会导致使用 ManualTemplate 定义的模板无法训练,而 PrefixTuningTemplate 则不存在这种问题。
在我们定义好DataLoader和PromptModel后,可以仿照pytorch中的训练流程进行训练和测试即可。源码中还使用了如梯度裁剪,学习率decay和 warmup等技巧,这里为了突出重点,只给出训练代码:
for epoch in range(3):
prompt_model.train()
for step, inputs in enumerate(train_dataloader):
if use_cuda:
inputs = inputs.cuda()
global_step +=1
loss = prompt_model(inputs)
loss.backward()
tot_loss += loss.item()
optimizer.step()
optimizer.zero_grad()
if global_step %50 ==0:
print("Epoch {}, global_step {} average loss: {} lr: {}".format(epoch, global_step, (tot_loss-log_loss)/50, scheduler.get_last_lr()[0]), flush=True)
log_loss = tot_loss
模型训练好后,我们可以使用他来生成,并进行评估:
from openprompt.utils.metrics import generation_metric
# Define evaluate function
def evaluate(prompt_model, dataloader):
generated_sentence = []
groundtruth_sentence = []
prompt_model.eval()
for step, inputs in enumerate(dataloader):
if use_cuda:
inputs = inputs.cuda()
_, output_sentence = prompt_model.generate(inputs, **generation_arguments)
generated_sentence.extend(output_sentence)
groundtruth_sentence.extend(inputs['tgt_text'])
score = generation_metric(generated_sentence, groundtruth_sentence, "sentence_bleu")
print("test_score", score, flush=True)
return generated_sentence
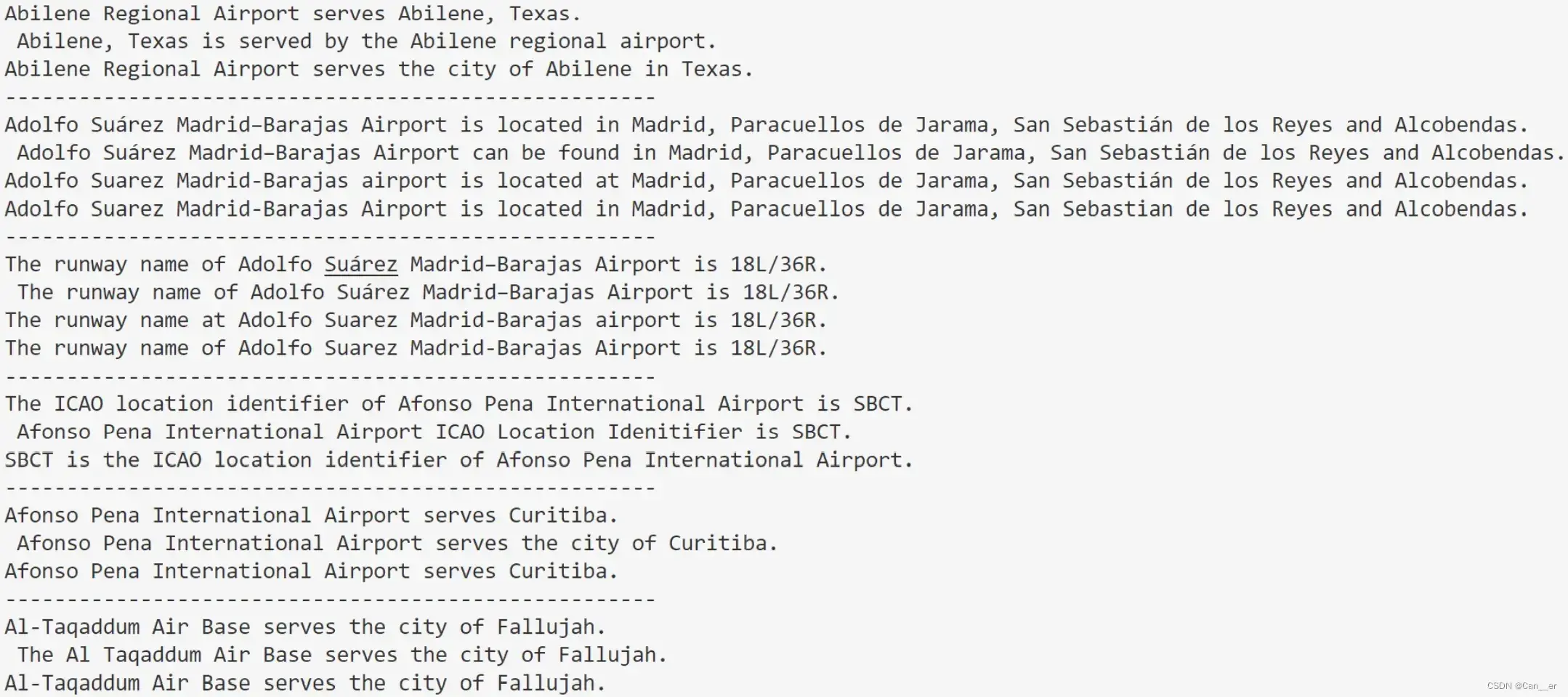
可以简单看一下生成效果,每句话的第一行为生成的,后面为多个标准答案。
参考资料
- GitHub – thunlp/OpenPrompt: An Open-Source Framework for Prompt-Learning.
- 解决pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool_禅心001的博客-CSDN博客
- [2111.01998] OpenPrompt: An Open-source Framework for Prompt-learning (arxiv.org)
- OpenPrompt阅读笔记 – 知乎 (zhihu.com)
- OpenPrompt原论文阅读 – 知乎 (zhihu.com)
- 【踩坑记录】OpenPrompt工具包如何使用?_vector<>的博客-CSDN博客
- openprompt结合源码讲解:如何加载自己的数据集 – 知乎 (zhihu.com)
- openprompt结合源码讲解:建立dataloader – 知乎 (zhihu.com)
- NLTK:Resource punkt not found. Please use the NLTK Downloader to obtain the resource_PleaseBrave的博客-CSDN博客
- |带代码的论文 (paperswithcode.com)
- 使用多个GPU训练出现如下错误 · Issue #152 · thunlp/OpenPrompt (github.com)
- 关于PrefixTuningTemplate更改后报错的问题 · Issue #198 · thunlp/OpenPrompt (github.com)
- pytorch中的model.eval()与volatile=True与requires_grad=False_两只蜡笔的小新的博客-CSDN博客
- PyTorch 的 Autograd_AlanBupt的博客-CSDN博客
文章出处登录后可见!