最近大模型通用智能应用持续发酵,各大科技公司都陆续推出了基于通用大模型的智能应用产品,典型的如OpenAI的ChatGPT、微软的BingChat、百度的文心一言、360的智脑、阿里的通义千问等。当然最火的要属于ChatGPT了,从去年年底推出到现在已经有很多人体验了,并惊叹于如今的人工智能已经发展到无所不知、无所不能的程度了。
经过一段时间对ChatGPT的使用,我逐渐认同马占凯马老师《ChatGPT:人类新纪元》书中对“ChatGPT:人类新纪元”的提法。ChatGPT,如同人类历史上的单向门——火、文字、造纸、蒸汽机、电和计算机一样,ChatGPT的横空出世让大家看到了通用人工智能达到了崭新新的高度,标志着人类科技进步的又一重大里程碑,预示着我们正步入通用人工智能的新纪元。就像2007年乔布斯发布划时代的苹果智能手机iphone后,各种互联网移动应用蜂拥而至,大家再也离不开智能手机了,从此开始了移动互联的新纪元。
一、ChatGPT之初体验
对于一个码农,初接触ChatGPT时就想验证一下ChatGPT的编程功底,最近正好在研究用机器学习来识别心电图。如是问了一下ChatGPT如何用Python写一段心电图识别波形的代码。
看一下ChatGPT给我的答案:
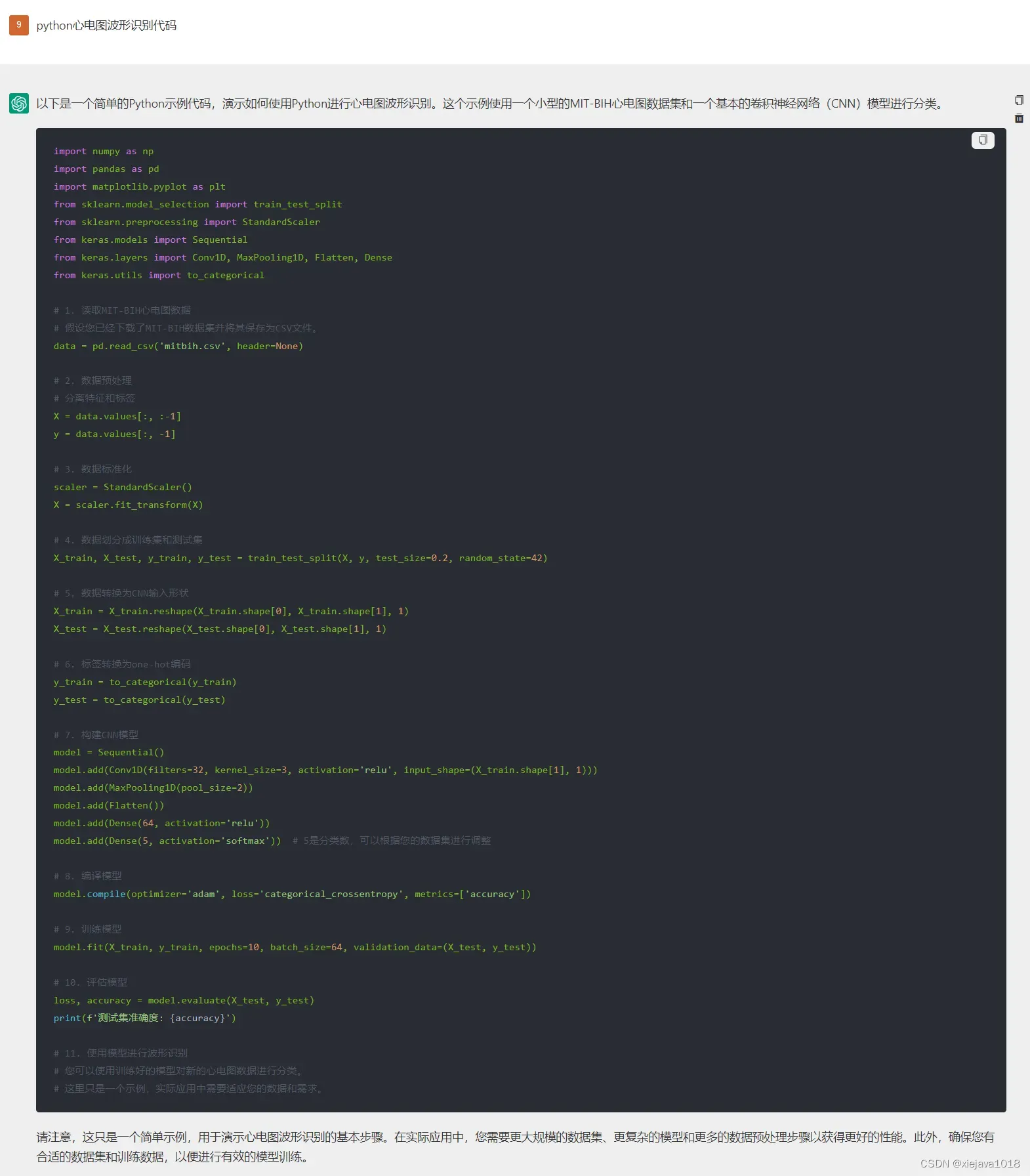
关键是这段代码稍作调整就可以运行起来。
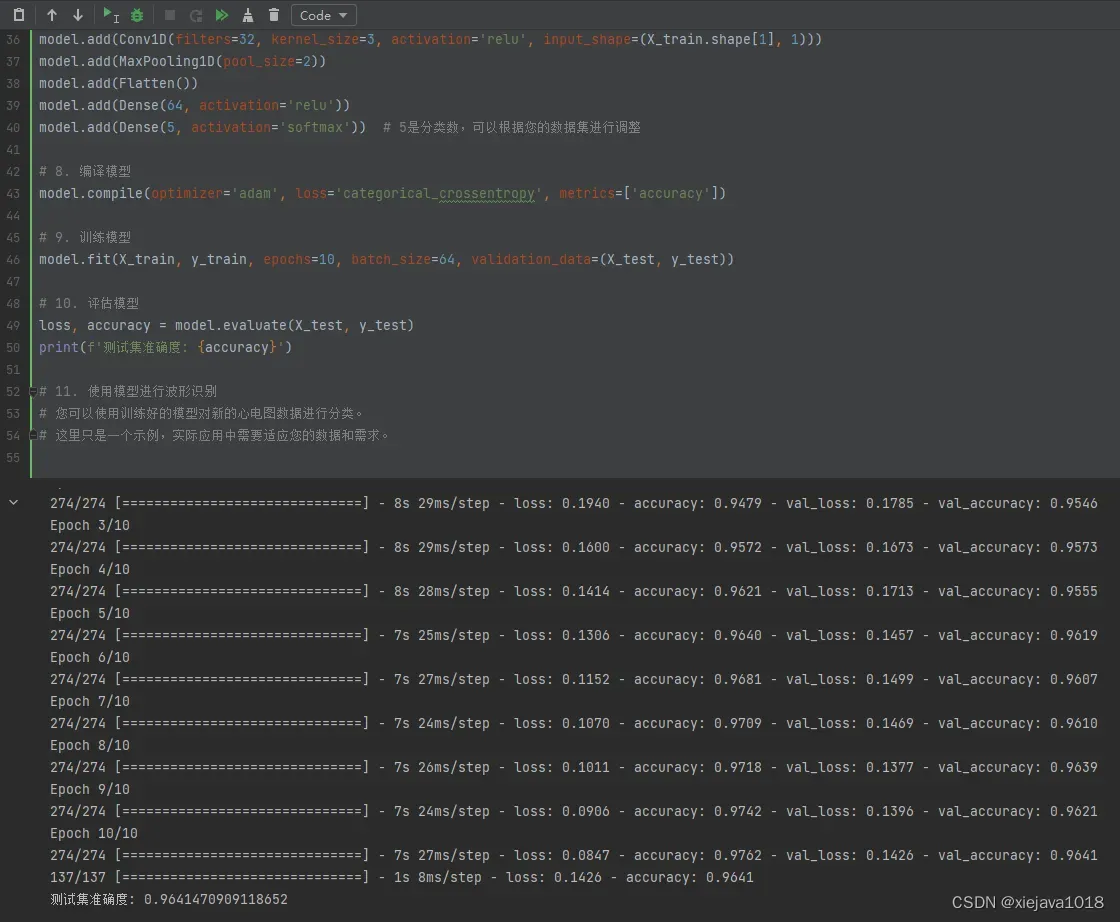
看上去效果还不错!
这可不是向搜素引擎一样搜出一堆的结果给出一堆的选项让我来选,而是真正的根据我的题意自己生成了一段可以执行的代码!这就有点牛逼了。
原来一直以为码农毕竟还是干技术活的,不会像那些从事简单重复劳动的活一样被AI所替代。但是看到ChatGPT给我的答案,又更进一步的加深了我的焦虑。本来就很卷的IT行业,还要和通用人工智能卷,估计用不了多久码农这个职业就会要消失了。
二、ChatGPT与搜索引擎
有人认为ChatGPT就是搜索引擎的升级版,输入一些信息机器就给你反馈一些经过精细过滤后的信息。ChatGPT与搜索引擎完全是两类不同的东西。差别就和智能手机与以前的功能手机一样大。
ChatGPT是通过海量的数据学习后,具备真正具有智能能力的,给出的内容是根据自身的学习自动生成的。也就是我们常说的生成式AI,是一种能够从其训练数据中学习并生成新的、类似的数据或模型的机器学习技术。这种方法不依赖于预先定义的规则或模式,而是通过自我学习和适应来改进其性能。
与传统的AI相比,生成式AI的主要区别在于其学习方式和能力。传统的AI通常依赖于专家知识或编程指令来执行特定的任务。例如,一个图像识别系统可能被训练成只识别特定的图像类型,如猫或狗。然而,一旦这个系统遇到它从未见过的图像,它就无法做出正确的判断。
相反,生成式AI可以通过自我学习和适应来提高其性能。即使它从未见过某种类型的数据,它也可以通过分析大量的类似数据来学习如何处理这种数据。例如,ChatGPT通过海量的数据学习可以自动生成给出符合题意的答案。
而搜索引擎甚至连传统的AI都算不上,只是通过大数据的搜索算法将符合搜索条件的信息查询后返回到你,你还要根据自己的判断去识别和删选有用的信息。尤其是有了竞价模型后,可能搜索引擎给你的数据排名前几的都是对你来说没有什么用的,只是出价高的几个。
三、机器学习与人类学习
机器学习其实是和人类学习是一样的。基本原理如下图所示:
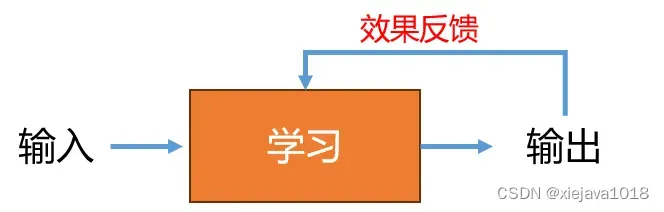
机器学习的输入是海量的数据,通过模型的训练从数据中学习,生成并输出新的数据,根据输出的效果的进行评估和反馈来调整模型参数使模型的学习效果达到最优。
人类学习也是一样的,平时我们努力大量的看书、看视频、看其他资料、与人交流,其实都是在获取信息,将信息输入至大脑后,大脑经过思考输出结果,结果是对世界的认知、对人生的看法、对专业知识的领悟、输出一篇论文、输出一次演讲等等。也是对自己输出的结果进行评估和反馈来强化学习效果。
比如:学生通过大量的阅读和做题作为输入来学习知识,通过考试来评估学习效果,根据考试评估的结果来调整自己的学习方法策略来取得更好的学习成绩。
我们也是一样的,要想提高自己的认知和能力,就要通过大量的阅读(输入)、思考(学习)、不断的反思(反馈评估)、不断的思考调整学习方法策略等(优化模型参数),最终提高自身的能力,可以有高水平的认知输出(输出)。
四、智能涌现与从量变到质变
“智能涌现” 是一个涵盖广泛领域的概念,它描述了在复杂系统中,智能行为或性能如何从简单组件或个体之间的互动中产生或 “涌现” 出来。在机器学习中,神经网络和深度学习模型可以通过大量的神经元之间的互连来实现智能任务。
在ChatGPT惊人的智能表现背后,就发生了智能涌现的现象。涌现现象是极为复杂的,因为复杂性科学就是复杂的,复杂是其基本特征。通俗的将就是当数据和模型参数达到一定的数量级后模型涌现出了新的完成任务的能力。
目前,在大模型的智能涌现方面,有三个结论。
第一,我们不知道什么时候会涌现某种新能力;
第二,我们不知道到一定规模时会涌现哪一种新的能力。
第三,我们唯一知道的是,只要数据量足够大,训练得足够深,一定会有涌现发生。
于是,我不禁又要拿出这张图:
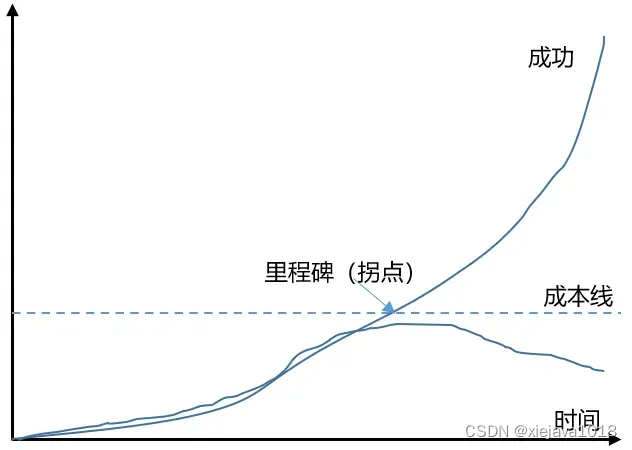
这张图可以理解为从量变到质变的过程。在人类学习的过程中,学任何东西,如:学习英语,只要输入足够多通过大量的听说读写(数据量足够大),投入的时间精力够多(训练得足够深),一定会有拐点(涌现)发生,一定会成功,就像顿悟后开了挂一样。
既然基于大模型的通用人工智能不可避免的来了,就让我们一起拥抱吧!
文章出处登录后可见!