
博文为精选内容,完整ppt请留言索取
一周内更新完毕,敬请期待
2023年度视觉与学习青年学者研讨会 (Vision And Learning SEminar, VALSE)于6月10日至12日在无锡太湖国际博览中心召开,由中国人工智能学会、中国图象图形学学会主办,江南大学、无锡国家高新技术产业开发区管理委员会承办。共呈现了3 个大会主旨报告、4个大会特邀报告、12个年度进展报告 (APR)报告、4场讲习班 (Tutorial)、20场研讨会 (Workshop)。另外,还有186篇顶会顶刊论文墙报展示交流活动
文章目录
- 大会特邀报告 & 年度进展评述(APR)
- 1.特征编码与数字视网膜
- 2.下一代深度学习的思考与若干问题
- 3.计算机视觉–从孤立到系统性方法
- 4.基于NeRF的三维视觉年度进展报告
- 5.扩散概率模型的前沿进展
- 10.视觉自监督学习
- 11、遥感目标检测
- Tutorial1:从 Transformer 到 GPT
- Tutorial2:扩散模型
- Workshop 1: 大模型对 CV/PR 的挑战与机会
- Workshop 4:多模态认知计算
- Workshop 6: ChatGPT 与计算机视觉
- Workshop 7:机器人具身智能
- Workshop 10:目标检测与分割
- Workshop 12:多模态大模型与提示学习
- 1.预训练模型和语言增强的零样本视觉学习
- 2.知识增强的多模态预训练和提示学习
- 3.多模态交织-多模态融合新方法&新架构
- 4.基于 LLM 的多模态提示学习:框架、提示数据及评测标准
- 5.模态鸿沟与交互式提示学习
- Workshop 13:三维视觉技术前沿
- Workshop 14:视觉内容生成
- 1.多模态通用生成模型的基本框架与最新进展
- 2.知识蒸馏场景下的样本生成
- 3.跨模态生成视角下的抽象视觉理解
- 4.面向艺术肖像画的媒体艺术生成与评估
- 5.From Paint by Example to Generalized Image Editing
- Workshop 15:自监督视觉表征学习
- Workshop 17:视觉知识和多重知识表达
- Workshop 19:优秀学生论坛
- 总结
Valse 2023 于2023年6月9日在无锡 太湖博览中心召开
大会特邀报告 & 年度进展评述(APR)
1.特征编码与数字视网膜
报告人:北大 高文
从认知心理基础,到特征编码方式、数字视网膜

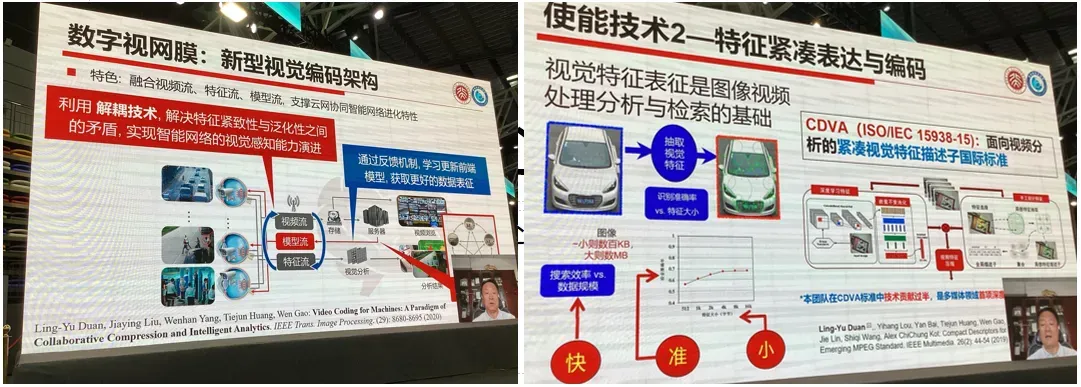
最后还讲了模型压缩、终端部署、大模型等内容

以及鹏程-大圣的视觉模型

2.下一代深度学习的思考与若干问题
焦李成 西安电子科技大学
本报告着重和大家一起探讨深度学习基础理论相关的研究。首先,回顾了深度学习的思想起源与发展历程。紧接着,讨论了对深度学习再认识与再思考,从而引出应突破的基础理论。然后,从类脑启发、物理启发和进化启发等三个方面讨论了深度学习的表征、学习与优化理论。最后,给出了对下一代深度学习的一些思考。

优化理论:
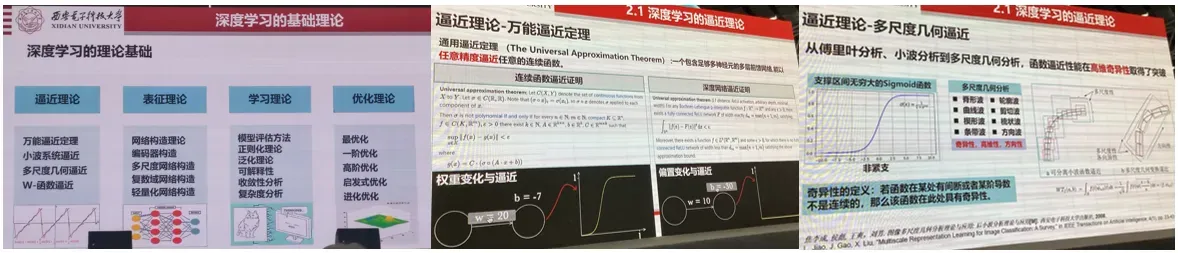
表征理论和学习理论:

其他学科的交叉影响:
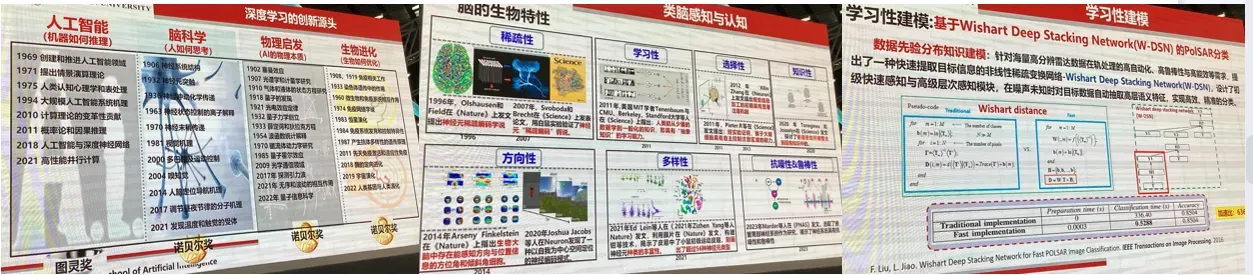
起源与启示

当然还有电磁学、统计热力学、光学、能量模型和量子智能等,需要完整PPT请私信。

后面还有元学习、神经网络搜索的综述NAS。最后是总结思考:

3.计算机视觉–从孤立到系统性方法
陈熙霖 中国科学院计算技术研究所
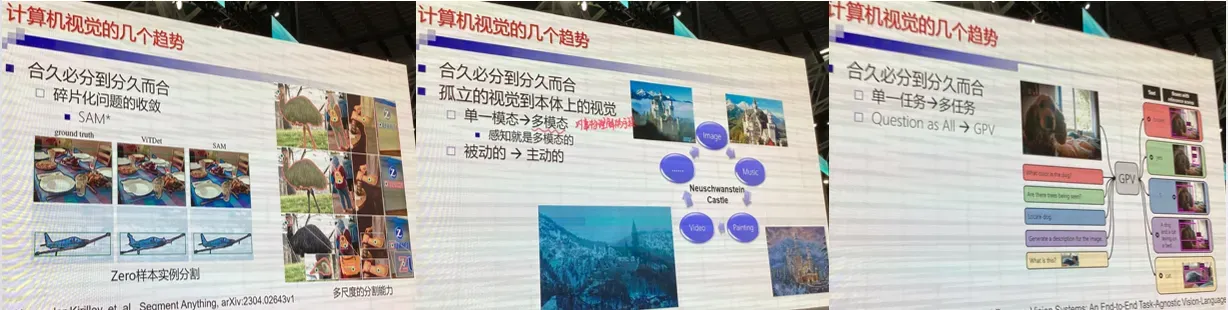
在 AI 领域,很长时间以来的研究范式是以孤立算法为核心的单点研究,同时,现实世界中广泛存在着样本分布不均、任务多样性等问题。对以往的孤立研究范式而言,这些问题显然是难以克服的困难,因此需要从系统化的角度探索融合多模态信息,构建从感到探、从被动到主动的系统性学习体系。本报告将介绍我们近期在这方面的一些思考和尝试,探索从系统性的角度实现连续积累和学习的路径。
CV发展史

计算机视觉的几个趋势:
模型背后的逻辑:
1.模型是什么?(不是算法复杂度)
模型 =算法复杂程度 X 养成数据
养成数据的规模与维数灾难
2.模型成熟度 M=算力/模型复杂程度
思考级–例:2000年以前的NN,非常原始的结果,少数人能够认识到
研究级–例:2010年前后的NN,成为学术界的重要手段研究级
产业级–例:今天的大模型产业级
个人用户级
大模型是希望还是终结?
一、IBM 360的启示计算机体系结构
大模型催生AI体系结构:1大模型成为组件(直接拿来用);2.关注更加宏观的智能,分久而合
二、AI体系结构
1.AI基本能力间的界面; 2.AGI的结构支撑; 3.超越传统AI话题的研究领域 ;4.超越单一智能催生综合智能体
Take home messages:

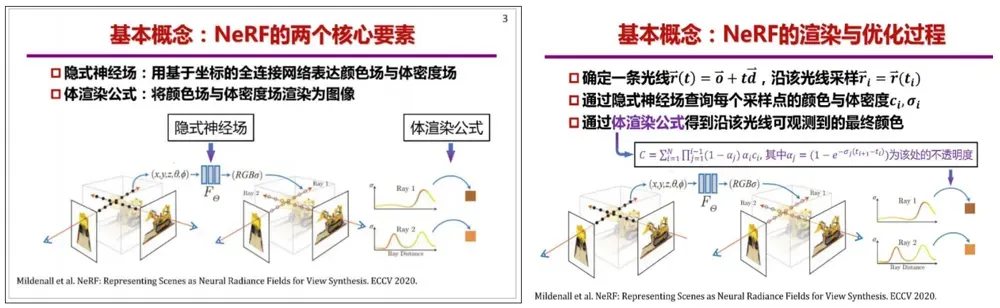
4.基于NeRF的三维视觉年度进展报告
刘烨斌 清华大学
神经辐射场(NeRF)是一种以隐式场和体渲染为基础的三维表征,以其端到端可
微、高质量视点生成等特性得到广泛关注。自 NeRF 被提出以来,学者对其隐式场本身或体渲染过程进行了诸多改进,以实现加速推理和训练、几何与表观解藕、材质和光照编辑乃至稀疏视点下的动静态和多尺度场景建模。与此同时,通过结合多元表征和生成式模型,NeRF 在三维视觉领域的应用层出不穷。本报告将回顾过去一年神经辐射场的重要研究成果,涵盖其表征基础的优化及代表性应用研究,重点将围绕 NeRF 现存的两大挑战,包括在轻量化采集条件下的高质量三维重建与渲染,以及将 NeRF 拓展到时空动态场景的高效四维表征来进行探讨与展望。首先是基本原理:
重要性:

几个大的研究方向:

四大常见场景建模:

还有几个具身应用的场景建模:

5.扩散概率模型的前沿进展
朱军 清华大学
AIGC 发展迅速,扩散概率模型是 AIGC 的关键技术之一,在文图生成、3D
生成等方面取得显著进展。该报告介绍扩散概率模型的若干进展,包括扩散概率模型的基础理论和高效算法、大规模多模态扩散模型以及 3D 生成等内容。首先是原理:

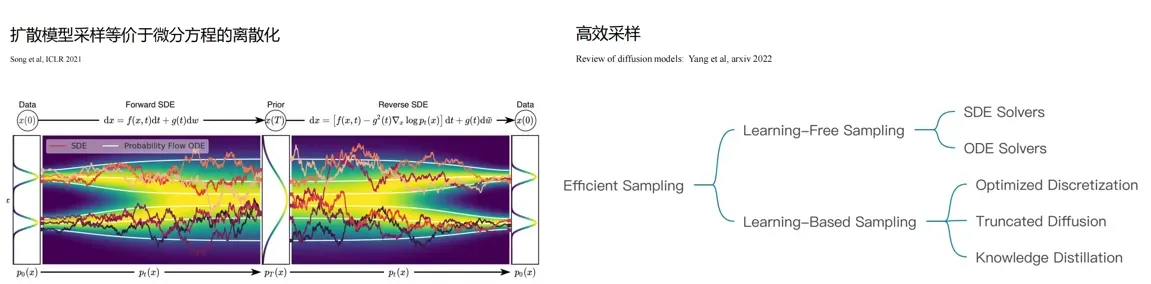
对比了SDE和ODE两种不同的微分方程:
ODE(Ordinary Differential Equation,常微分方程)描述的是确定性变量随时间的变化关系,它是由形如 dt/dy =f(y) 的微分方程组成,其中 y 是一个确定性的变量,f 是它的导数关系。ODE的解是一个确定的函数,对于给定的初始值,其解是唯一的。
SDE(Stochastic Differential Equation,随机微分方程)描述的是随机变量随时间的变化关系,它是由形如 dXt =μdt+σdWt 的微分方程组成,其中 μ 和 σ 是确定性的常数,W t 是随机过程(通常是布朗运动)。SDE的解也是一个随机过程,它将初始值的不确定性引入到了解中,因此,给定相同的初始值和参数,SDE的解通常不是唯一的。ODE在描述确定性系统中扮演着更为关键的角色,而SDE则更适用于描述随机性系统中的行为。

随后是 团队: @ THU TSAIL Group:一些 Diffusion Models进展,
Basic theory and algorithms:
1.Score estimate for energy-based LVMs (ICML2021)
2.High-order denoising score matching (ICML 2022
3.Analytic-DPM – optimal variance estimate (ICLR 2022 0utstanding paper.ICML 2022)
4.DPM-Solver – the fastest inference algorithm (NeurlPs Oral, 2022)
5.U_ViT backbone – more scalable (CVPR 2023)
Novel design of diffusion models for various tasks
1.Energy-guided DPM for lmage-2-lmage translation (NeurlPs,2022)
2.Equivariant energy-guided DPM for Molecular design (ICLR 2023)
3.Generative behavior modeling for Offline RL (ICLR 2023)
4.UniDiffuser for Multimodal inference (ICML 2023)
5.ProlificDreamer for Text-2-3D content (arXiv:2305.16213, 2023)
6.ControlVideo for one-shot Text-2-Video editing (arXiv:2305.17098, 2023)
重点介绍了以上最后三个工作:
1.多模态预测

2.ProlificDreamer: 高质量的Text-to-3D(改编自dreamFusion)
1.DreamCLIP,单个场景,直接梯度下降优化
2.DreamFusion,单个场景去拟合预训练的分布,方法是score distillation 3.samplingProlificDreamer,场景分布 (一堆场景) 去拟合预训练的分布,方法是variational scoredistillation
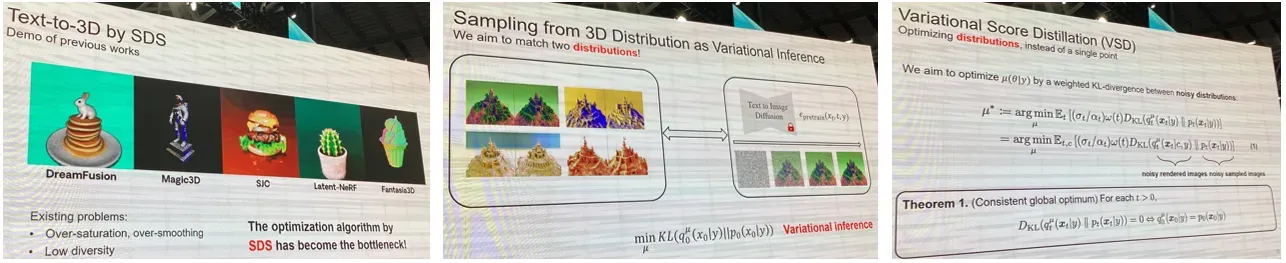
3. ControlVideo: One Shot Text-to-Video Editing

最后的总结:

10.视觉自监督学习
胡瀚 微软亚洲研究院
视觉自监督学习的主流范式在过去一年多的时间里经历了从对比学习方法到生
成式方法的迁移。以 BEiT/MAE/SwinV2(SimMIM) 为代表的生成式方法在预训练-微调范式下取得了优异的性能,更重要的是,它们被证明相比此前的方法具备更好的数据和模型可扩展性,也能很好的与多模态方法融合。本次 APR 概述过去一年视觉自监督学习方面的主要进展,包括预训练方法本身及其相关性质的研究。


自监督学习年度进展 (2022-2023):
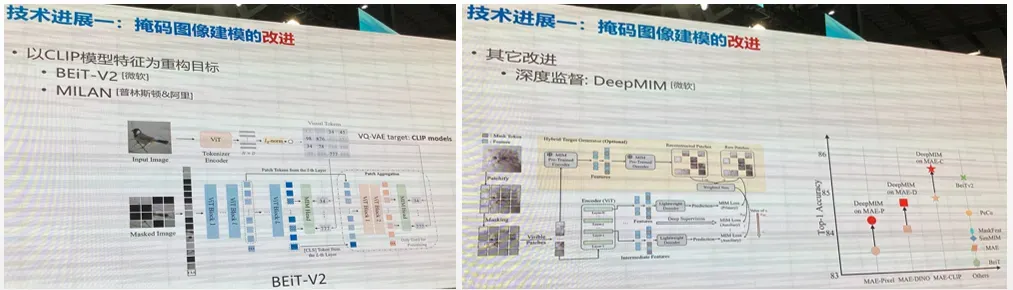
技术进展趋势一:掩码图像建模的改进
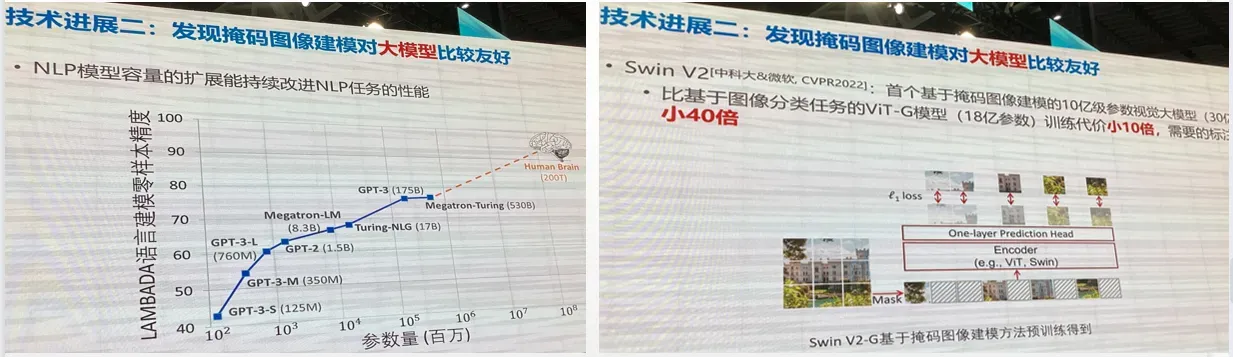
技术进展趋势二:发现掩码图像建模对 大模型 比较友好
技术进展趋势三:针对 小模型 的掩码图像建模训练
技术进展趋势四:挖掘掩码图像建模的好性质
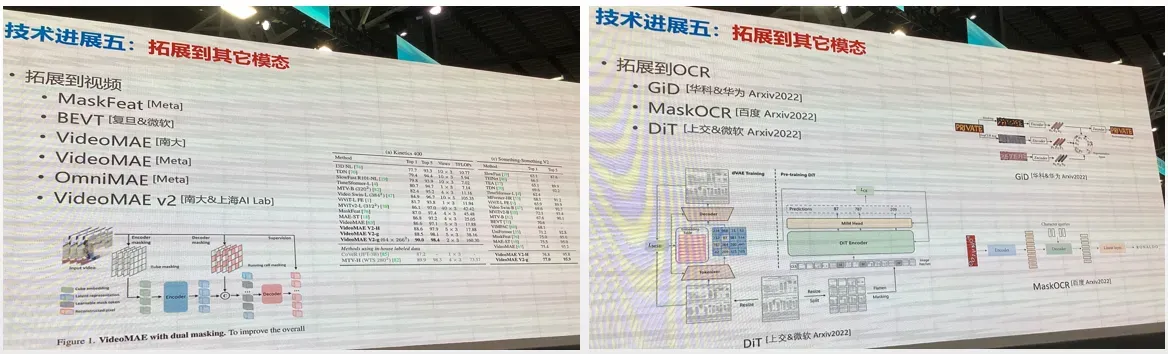
技术进展趋势五:拓展到其它模态
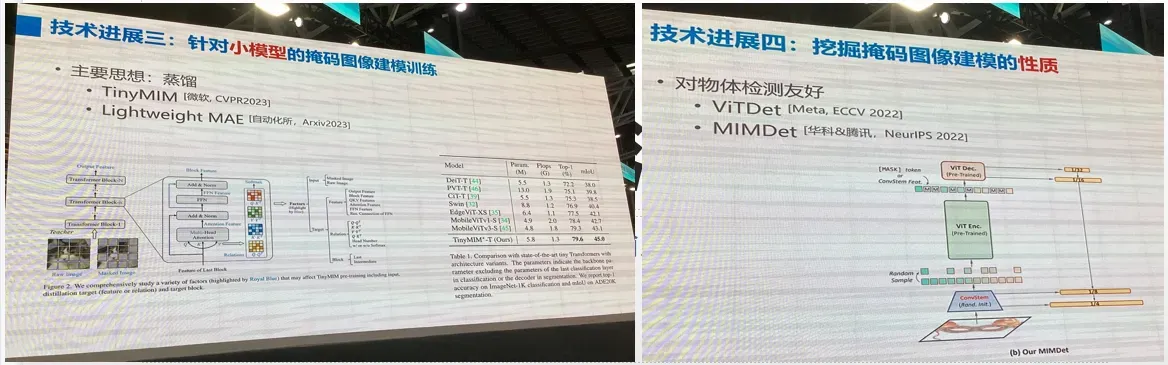
拓展到其他模态:
总结:
11、遥感目标检测
程 西北工业大学
本报告首先总结分析遥感目标检测面临的挑战,接下来重点概述近年来遥感目标检测的主要进展,主要包括有向目标检测、弱监督目标检测、小样本目标检测、目标型号识别、以及弱小目标检测等
几个挑战:
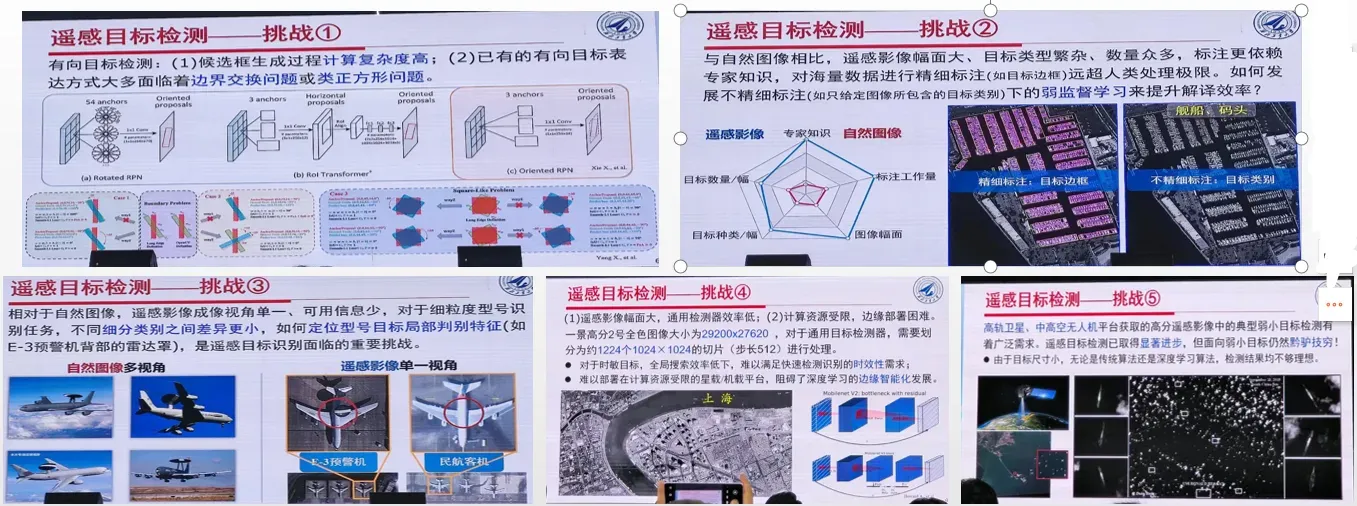
有向目标检测几种算法:


弱监督目标检测:

细粒度识别:

高效目标检测
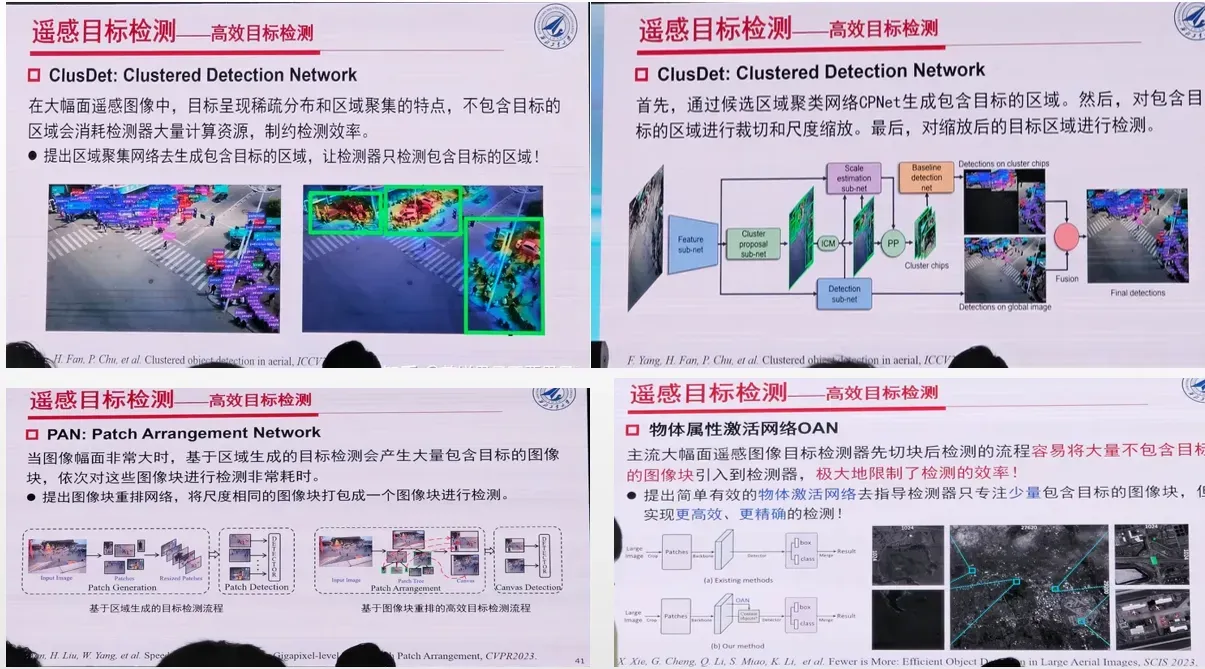
弱小目标检测:

博文为精选内容,完整ppt请留言索取:`
未来几天内将更新完毕
博文为精选内容,完整ppt请留言索取
Tutorial1:从 Transformer 到 GPT
Tutorial2:扩散模型
李崇轩 中国人民大学
摘要:扩散概率模型是一类新涌现的深度生成模型,这类方法逐步地对先验噪声分布去噪得以逼近数据分布。目前,扩散概率模型在数据合成质量、采样的多样性和数据密度估计等指标下取得了超越 VAE、GAN、FLOW 等经典深度生成模型的结果,也在诸多领先的视觉生成大模型中得到应用,有望成为未来通用生成式智能的重要组成部分。本次课程会介绍扩散概率模型的基本原理与代表性工作,介绍其在可控生成、多模态建模和三维场景建模等方面的前沿进展,并对扩散概率模型的下一步发展做简单的展望。
• 1.概览
• 2.扩散模型学习算法
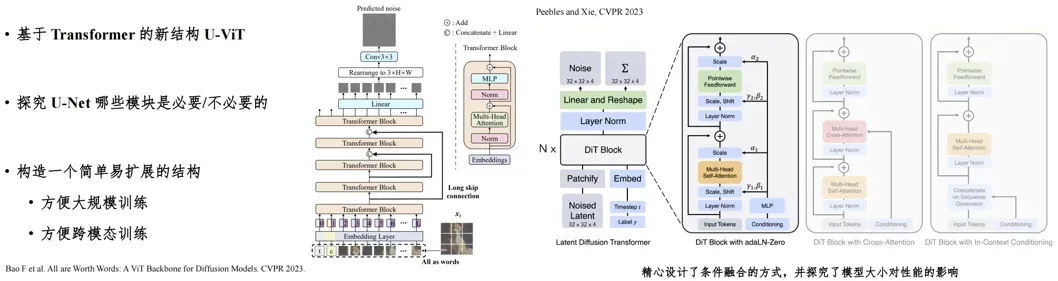
U-ViT 与DiT两种新结构:
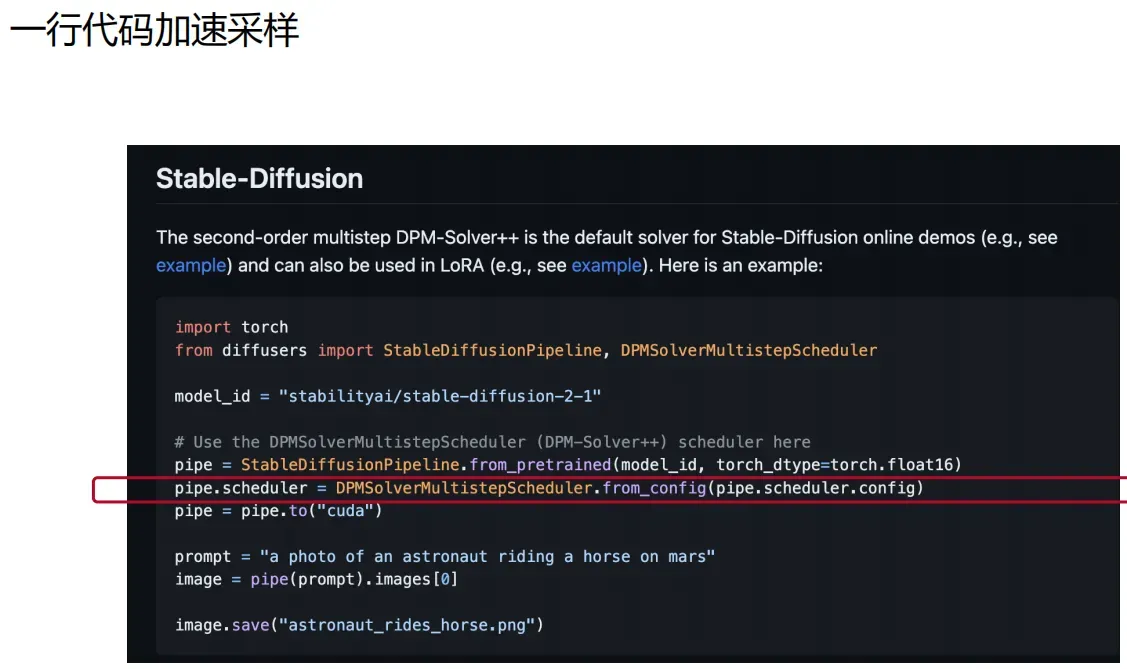
• 3.扩散模型采样算法

• 4.大规模扩散模型
模型规模是大规模深度生成模型中联合概率分布表示的第三维度:
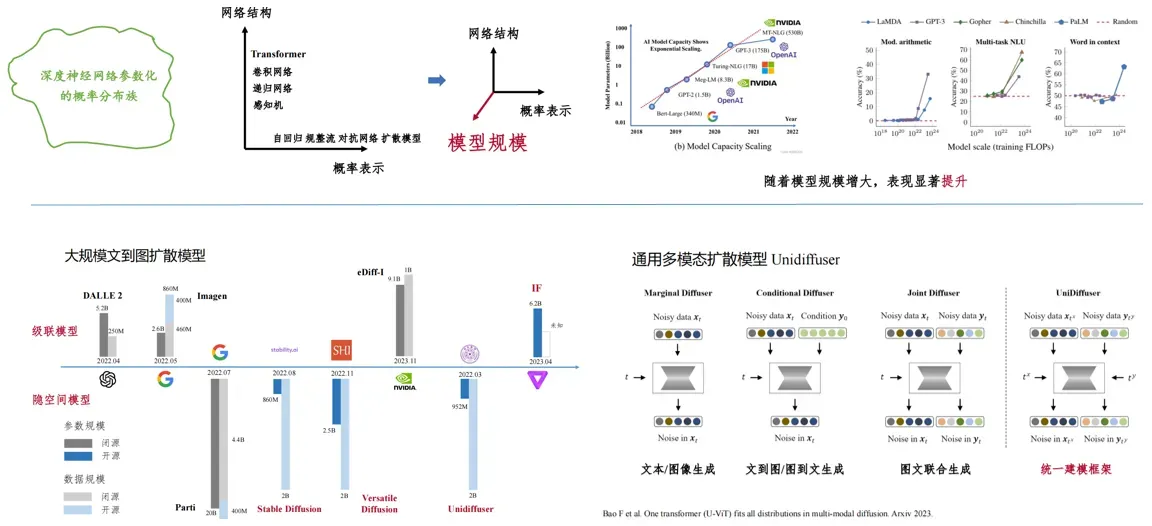
• 5.扩散模型与 AIGC
• 大规模预训练模型的特点
• 开放域、强泛化
• 文本作为主要交互接口
• 下游AIGC的需求与挑战
• 数据少(利用开放域、强泛化的特点,少样本解决下游任务)
• 个性化/可控制(加入额外条件控制)
下游任务
•个性化图像生成
• 图像可控生成与编辑
• 视频可控生成与编辑
• 三维场景生成
• 6.展望
整个PPT达一百多页,需要请留言
Workshop 1: 大模型对 CV/PR 的挑战与机会
Workshop 4:多模态认知计算
Workshop 6: ChatGPT 与计算机视觉
Workshop 7:机器人具身智能

1. 视觉导航:从模拟到现实
报告摘要:视觉导航是指具身智能体通过视觉实时感知环境,进行路径规划找到给定目标,这是具身交互任务中的一个重要步骤,是智能系统应用在现实世界中的一项重要能力,具有广泛应用潜力。受限于在现实场景中存在的训练数据不足、交互性不强、难以评测对比等问题,视觉导航等具身智能任务主要在模拟器环境下开展研究。本报告将首先介绍基于模拟器的视觉导航技术研究现状和进展,包括类别级/实例级物体导航、单物体/多物体导航等技术;其次将探讨视觉导航从模拟环境到现实环境的迁移与实施,介绍真实环境下视
觉导航开展情况并给出演示。
2. 具身三维视觉 PIE 方案
报告摘要:该讲座介绍讲者具身三维视觉 PIE 方案。P(Perception)介绍讲者全感知与交互感知工作。I(Imagination),介绍讲者的物理世界概念驱动仿真推理框架。E(Execution)介绍讲座通用元操作技能设想与工作(重点介绍:通用柔性物体操作与通用抓取工作)。
3. 3D 视觉引导的机器人自主操作
报告摘要:机器人自主操作能力不但是衡量机器人智能化水平的关键指标之一,对提高机器人在智能制造、家庭服务、医疗健康等领域的作业适应范围也具有重要意义。其中机器人感知和认知能力实现机器人自主操作的关键,而视觉特别是 3D 立体视觉和机器学习是机器人感知和认知的重要手段。虽然近年来涌现出许多令人兴奋的进展,但机器人感知和认知中的一些核心问题仍然没有得到很好解决,导致机器人还无法完成很多人类看似简单的工作,例如机器人视觉识别能力不足、自主操作泛化能力较弱等。报告结合机器人学国家重点实验室的背景和特点,主要阐述针对机器人感知和认知中的视觉识别和在线学习问题所开展的探索性研究。
4. 视频人体动作的细粒度分析与理解
报告摘要:视频是人们观察和记录世界、进行内容分享和信息交互的重要载体,分析视频中人体动作对理解现实世界、服务人类社会具有重大意义,其作为基础性关键技术在智能体育、智能安防、智能媒体、智能家居等领域具有广阔的应用前景。本报告首先介绍视频人体动作分析与理解的难点问题和方法;重点介绍视频体育运动定量评价与数据分析等问题,构建了首个细粒度竞技体育视频数据集 FineDiving,提出了基于过程感知的细粒度人体动作解析等方法,解决竞技体育运动定量评价的可回溯性问题;介绍视频人体动作意图难理解、人工标注不可靠等问题,提出了基于知识增强的意外动作定位等方法,突破现有模型稳定预测、泛化的局限性,提升了模型推理行为目标、认知他人计划的能力。
5. 人形机器人多模态应用
报告摘要:人形机器人的多模态应用是指在实际应用中结合多种感知和交互方式,以提高机器人的适应性和功能。这些模态包括视觉、听觉、触觉、运动和语言等,人形机器人需要具备高度的自主性来完成不同的任务,近年来的研究和实践表明语言大模型和多模态感知是实现这一目标的关键技术之一。 报告结合人形机器人背景和特点,主要阐述针对人形机器人自主操作的初步探索, 应用语言大模型与多模态感知,人形机器人实现人机自然语音交互,任务分解,路经规划,定位导航,动作和步态控制,物体检测,物体识别,灵巧操作,触觉传感与机械臂控制自主作业。为了人形机器人的高度适应性,以便在不同的环境和场景中完成任务,我们将来的工作会在机器人感知, 认知和决策中的一些核心问题, 如多语言多任务语音交互技术,增强机器人视觉识别能力,自主操作泛化能力,精确的物体操控和操作技术,运动控制技术,情感识别技术和情感表达技术在人形机器人上进行进一步探索。这些多模态应用使得人形机器人在日常生活、医疗、教育、娱乐, 工厂,物流等领域都有着广泛的应用前景,可以为人类带来更加便利和高效的服务。
6. 速度与“机”情——智能巡检机器人在列车运维中的应用
报告摘要:中国目前有数千组动车和城轨列车,每年承载着几十亿人次的出行。为保证公
共交通的安全与便捷,轨道交通的运维工作变得至关重要。列车运维场景具有环境结构化
弱、通道狭窄、地面情况复杂、巡检采集精度要求高等特点。为此,格灵深瞳研发了新一
代的智能巡检机器人,结合了自主导航、在线感知、手眼协同、虚拟示教等技术。使得机
器人可以适应列车检修的复杂场景,做到快速部署,稳定运行。同时,搭配结合了深度学
习与立体视觉的 Deep3D 算法引擎,解决列车故障诊断碎片化程度高,收敛速度慢等问题。
本次报告将介绍列车运维面临的场景挑战,以及格灵深瞳利用以立体视觉技术为中心的解
决方案。同时,也将针对列车的缺陷检测问题的难点做出分享。
PPT较多,需要请留言
Workshop 10:目标检测与分割
Workshop 12:多模态大模型与提示学习
1.预训练模型和语言增强的零样本视觉学习
左旺孟 哈尔滨工业大学
近年来,随着 CLIP、Stable Diffusion 等多模态预训练模型的出现,如何在各种下游任务中充分利用预训练大模型进行微调和提示学习,已成为近年来计算机和多模态学习的研究热点问题和重要发展趋势。针对上述挑战性问题,本报告主要包括三个方面:(1) 以 3D 点云分类为例,探讨如何将图像-语言预训练模型拓展至其他视觉模态如 3D 点云;(2) 以物体检测为例,探讨如何基于多模态预训练生成模型实现更复杂视觉任务的零样本学习。(3) 以多标签分类为例,探讨如何将语言数据作为视觉监督信息,进一步增强零样本视觉学习性能;通过上述分析介绍,期望更多种类的预训练模型(如:CLIP、Stable Diffusion)可以更为广泛地应用于各种视觉模态(如:图像、点云)和复杂视觉任务(如:分类、检测、分割、生成),推动多模态预训练模型在下游任务中的研究与实际应用
内容:
1.语言增强的零样本多标签图像分类
文本作为图像
2.其他模式零样本分类的扩展
CLIP2Point:CLIP用于3D点云分类
3.扩展到其他零样本任务
ImaginaryNet:目标检测的图像合成
Ref-D:零样本参考图像分割
常见大模型:BERT / T5、ChatGPT、GPT-4、LLaMA


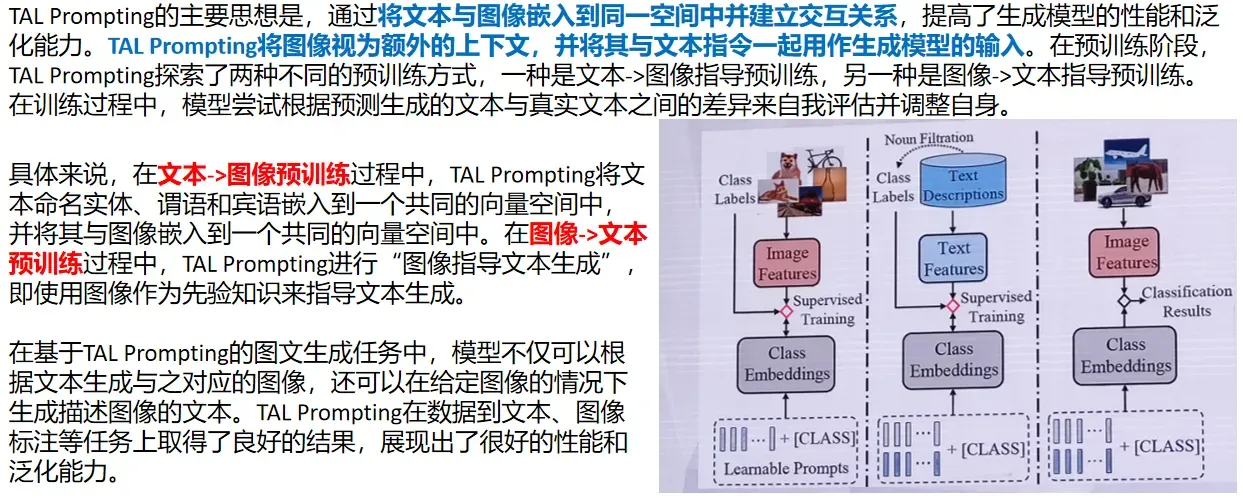
TAL Prompting图文预训练框架:
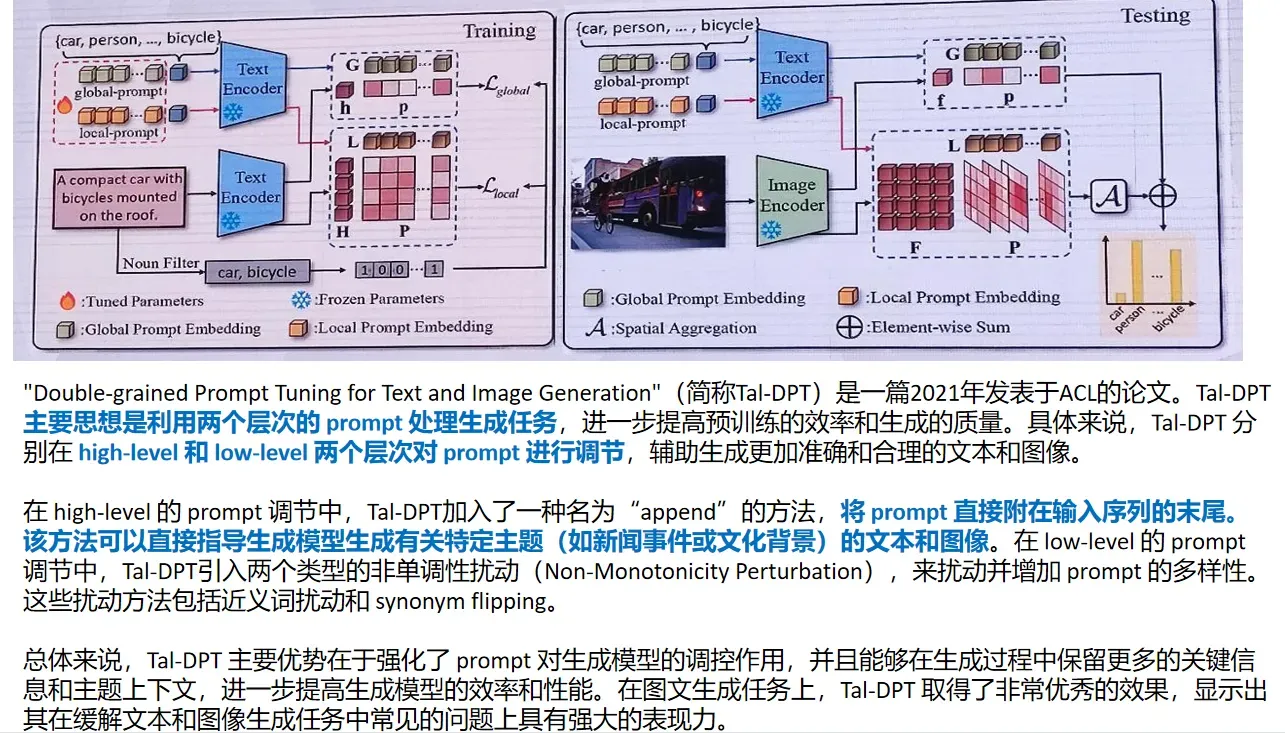
点云与深度图:投影间接利用大模型的方法:

随后介绍了ImageBIND 与ImaginaryNet:
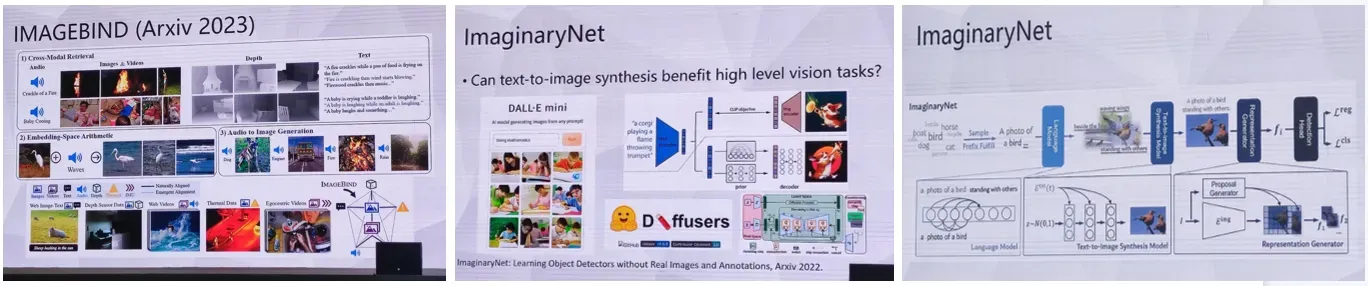
“lmaginaryNet: Learning Object Detectors without Real lmages and Annotations” 中科院自动化研究, Arxiv 2022 :一种新的基于生成模型的无监督学习方法,用于训练物体检测模型,解决缺乏真实图像和标注的情况下的物体检测问题:使用一个基于生成模型的无监督训练方法,通过像素级别的生成来构建一些虚拟图像监督,从而探索是否可以在没有任何真实图像或标注的情况下实现高效的物体检测。
两个主要部分:一个像素生成网络,用于生成虚拟图片,并且该图片中存在着虚拟目标。这些目标在该图片中的坐标和区域是随机生成的,不存在真实标注。另一个是物体检测器,该检测器通过对虚拟图像上执行目标检测任务进行训练。对于物体检测器,像素生成器生成的虚拟图片和它们的目标位置作为训练数据,训练检测网络,Detector 生成目标检测边界框,并在无监督情况下进行训练。
创新点:不需要真实图像和标注信息,利用 ImaginaryNet 的生成模型来生成虚拟图片和目标,让生成的图片以及虚拟的目标视为监督信号,实现了物体检测器的无监督训练。我们可以从虚拟图片和虚拟目标中训练算法,不需要真实图片和标注,并通过生成器不断地产生更多的虚拟图片和虚拟目标,以进行更加高效的训练。
数据集上实验表明,缺乏大量真实图像和GT的情况下,该方法也可以实现物体检测任务,并达到了良好的性能表现。
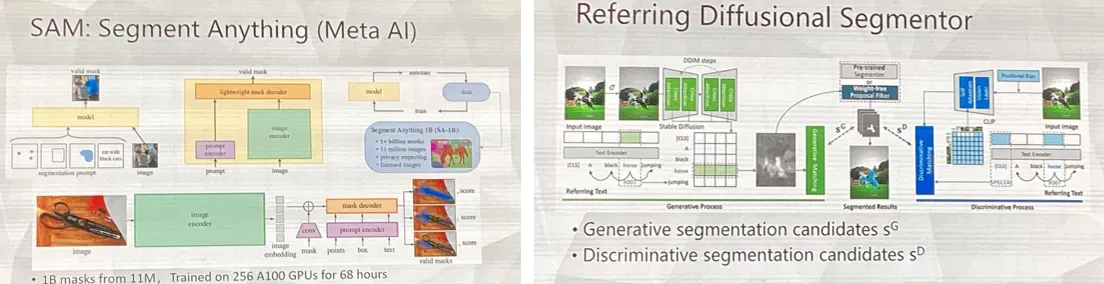
通用分割模型SAM,以及利用SAM辅助Referring Diffusional Segmentor,用于交互式图像分割。它将分割过程分为生成过程 (generative process) 和判别过程 (discriminative process) 两部分。在生成过程中,该算法通过引导模式,将用户提供的引导信息 (如关键词、指针、轮廓等) 结合图像的特征,使用随机游走模型生成初始分割结果。进入判别过程后,该算法使用一个深度判别网络来对经过随机游走生成的分割结果进行学习和优化,并提高分割的准确性。在具体实现中,该算法通过将判别网络训练技巧与对抗训练相结合,从而使分割结果更加稳健和准确。
2.知识增强的多模态预训练和提示学习
余宙-杭电子科技大
从海量数据中预训练得到的多模态模型在各种多模态任务上均取得令人惊叹的效果。如何在现有的“数据驱动”框架基础上进一步引入“知识指导”,从而进一步提升模型的表达能力和泛化能力是当前研究的热点和难点。在本报告中,我们介绍了两种融合知识的多模态学习框架:
1.ROSITA:利用多模态数据内部隐含的模态内和模态间关联知识,实现内部知识增强多模态预训练学习;
2.Prophet:利用多模态小模型提示语言大模型(GPT-3),实现外部知识增强的多模态提示学习
提出问题,以及已有的解决方案:

ROSITA框架:

Prophet框架:

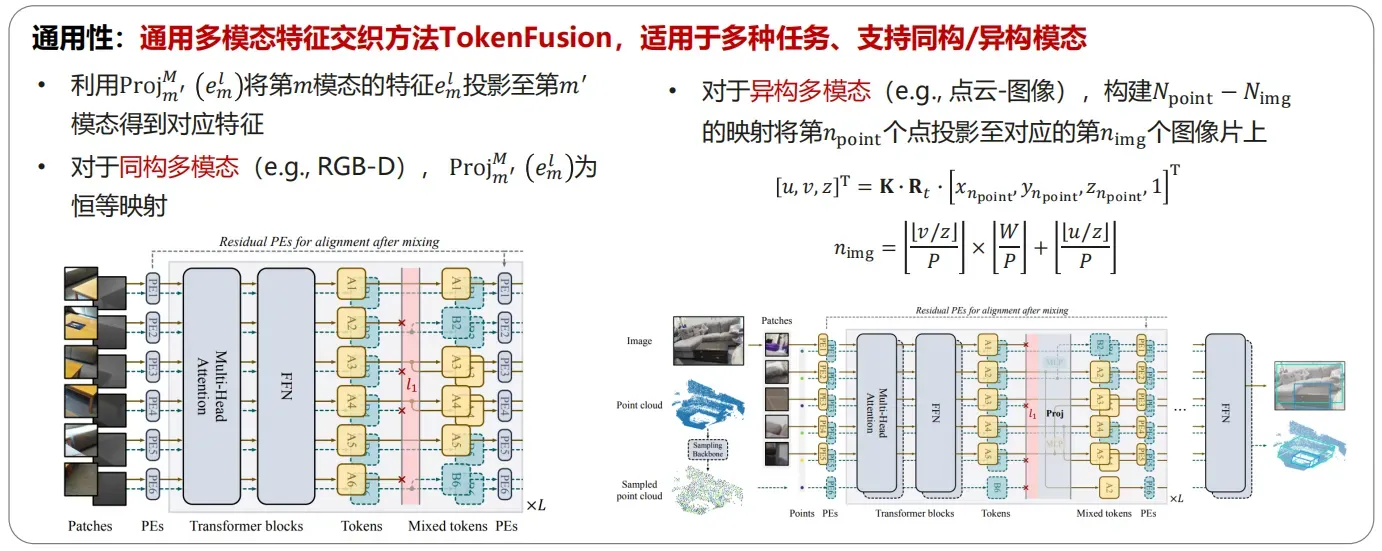
3.多模态交织-多模态融合新方法&新架构
王云鹤-华为
- 不同模态的融合:多模态交织Transformer
• Multimodal Token Fusion for Vision Transformers, CVPR 2022

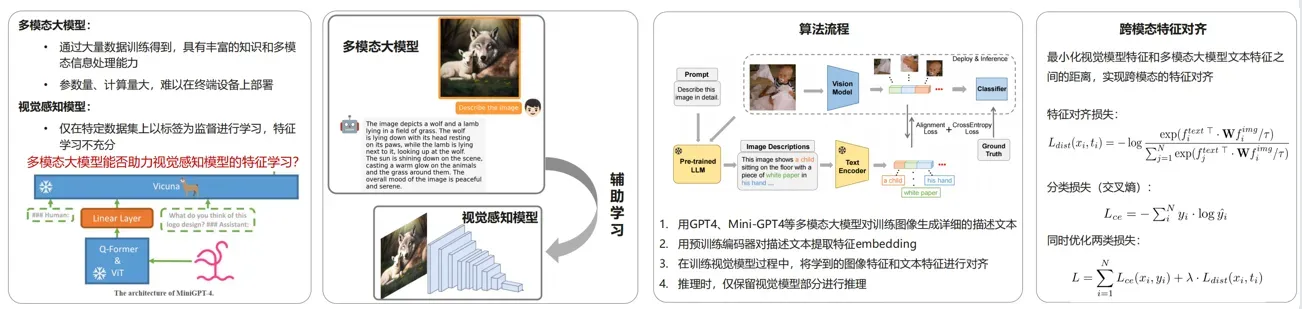
- GPT4Image:基于大模型助教的图像识别方法
• GPT4Image: Can Large Pre-trained Models Help Vision Models on Perception Tasks
- 单一模态的设计:极简骨干网络VanillaNet
• VanillaNet: the Power of Minimalism in Deep Learning, arxiv 2305.12972
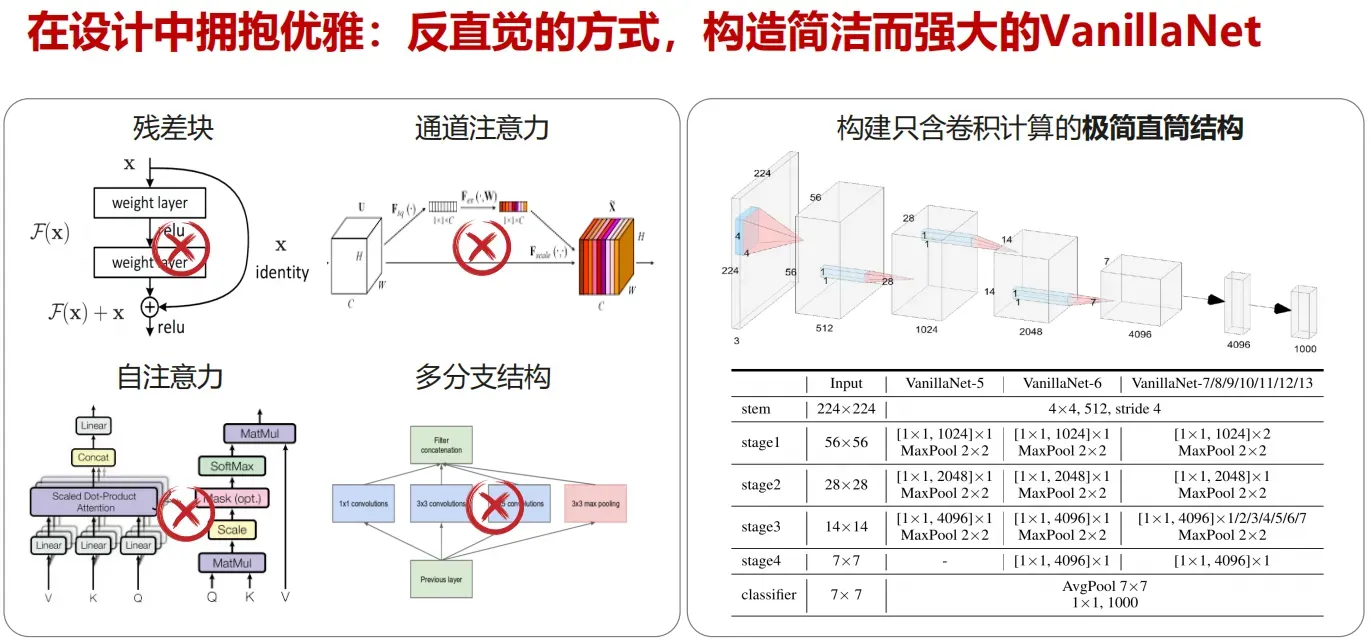
4.基于 LLM 的多模态提示学习:框架、提示数据及评测标准
邵婧 商汤科技
随着语言大模型的迅猛发展,文字成为连接各种模态信息的天然媒介,通过文
字与其他模态信息的交互学习,我们可以在丰富的跨模态领域应用中获得更有泛化性的感知、理解和生成等能力。由于跨模态数据和任务存在巨大鸿沟,如何做好关联对齐并有效融合仍面临巨大挑战。本次报告基于近期大模型进展,从支持从图像、视频及三维数据的理解、认知与生成等多种任务出发,介绍跨模态提示学习的数据和框架构建、评测标准设计等方面。并结合应用案例,深入探讨多模态大模型的现状和挑战
主要介绍了海豚大模型:

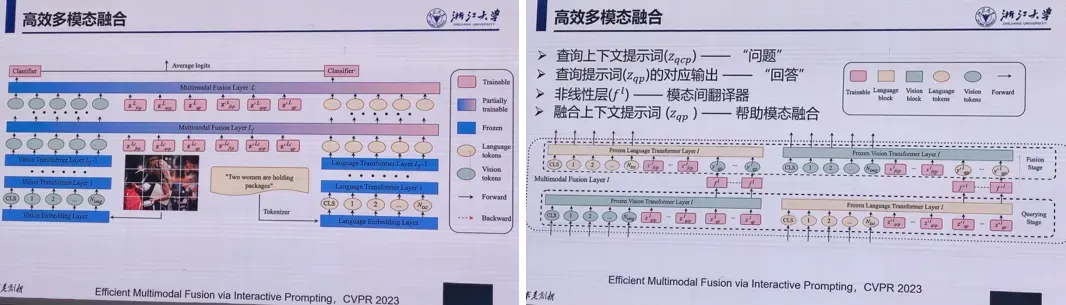
5.模态鸿沟与交互式提示学习
朱霖潮 浙江大学
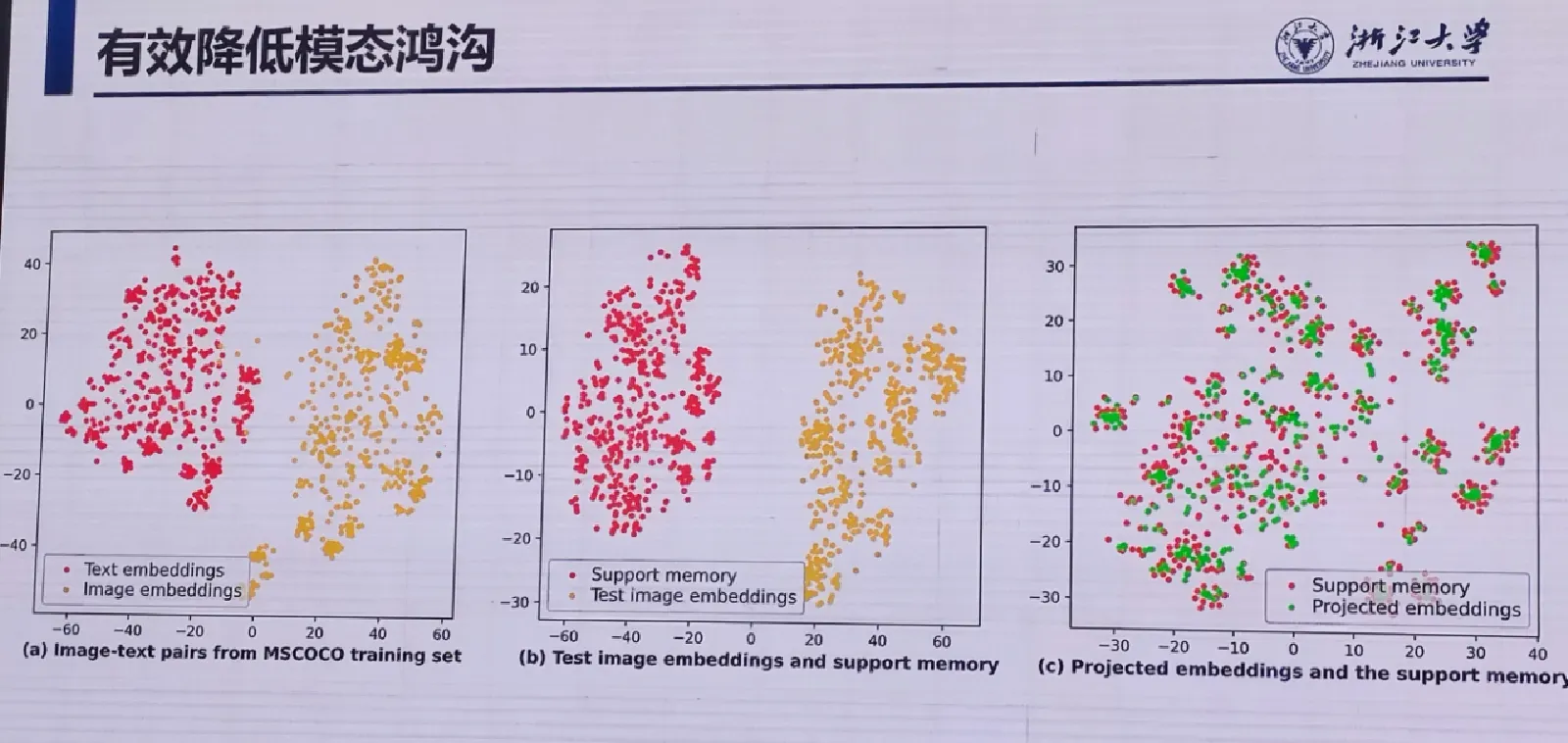
随着多模态数据的增加,多模态分析成为研究的热点。在多模态分析中,迁移与对齐技术能够将不同模态的信息对齐并进行多模态的迁移,提高任务的效果和性能。本次报告介绍多模态领域常见的模态鸿沟问题,以及降低模态鸿沟的方法,包括基于提示词的迁移、多任务学习、零样本学习等。报告还将结合实验和应用案例,深入探讨多模态分析中的应用
- 细粒度语义对齐的视觉语言预训练

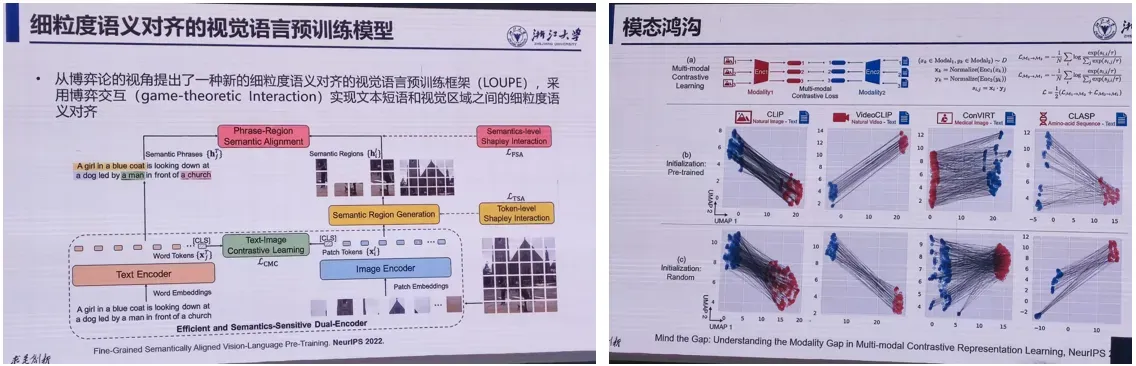
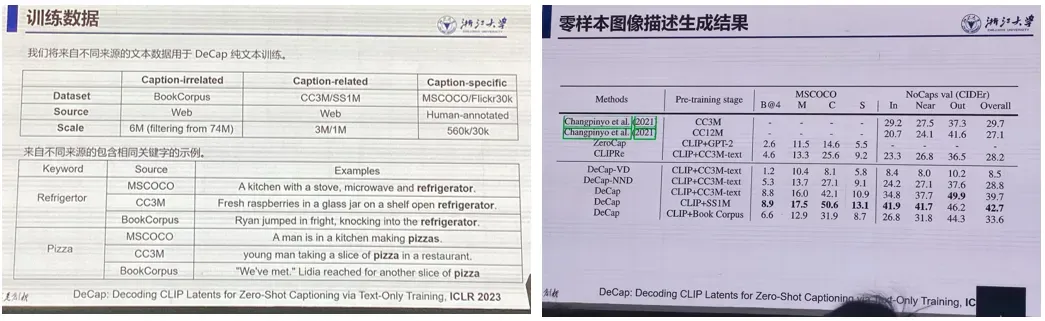
2. 视觉场景的自动语言描述


数据集与结果:
- 高效多模态融合
提出一种相互查询的机制:
消融实验与效果:
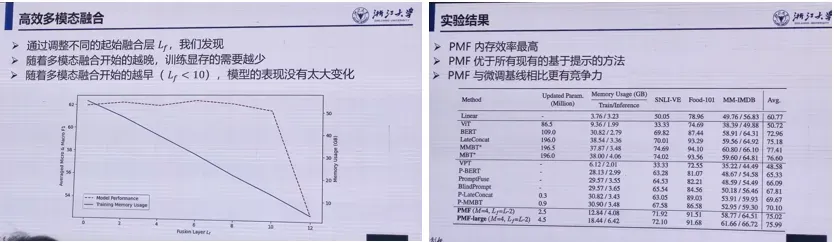
总结:
模态对齐:
模态间对产信息可用于自监督训练;
降低模态鸿沟能明显提升迁移性能,可采用无参数化方法降低模态鸿沟,提升视觉知识与文本知识的对产水平;模态融合
基于提示的模态融合
Workshop 13:三维视觉技术前沿
Workshop 14:视觉内容生成
1.多模态通用生成模型的基本框架与最新进展
卢志武 中国人民大学
摘要:多模态预训练在过去三年得到飞速的发展,涌现出OpenAI CLIP、Stable Diffusion等优秀模型。受 ChatGPT 的启发,多模态预训练出现新的变化,开始更关注多模态通用生成。本报告首先给出多模态通用生成模型的定义与基本框架。然后从语言生成、图像生成和视频生成三个方面展开,介绍我们的最新研究进展。最后还会对多模态通用生成模型的发展趋势进行展望。
通用架构:

随后讲了unidiffuser和ChatImg的应用,以及Video DIffusion Transformer的原理

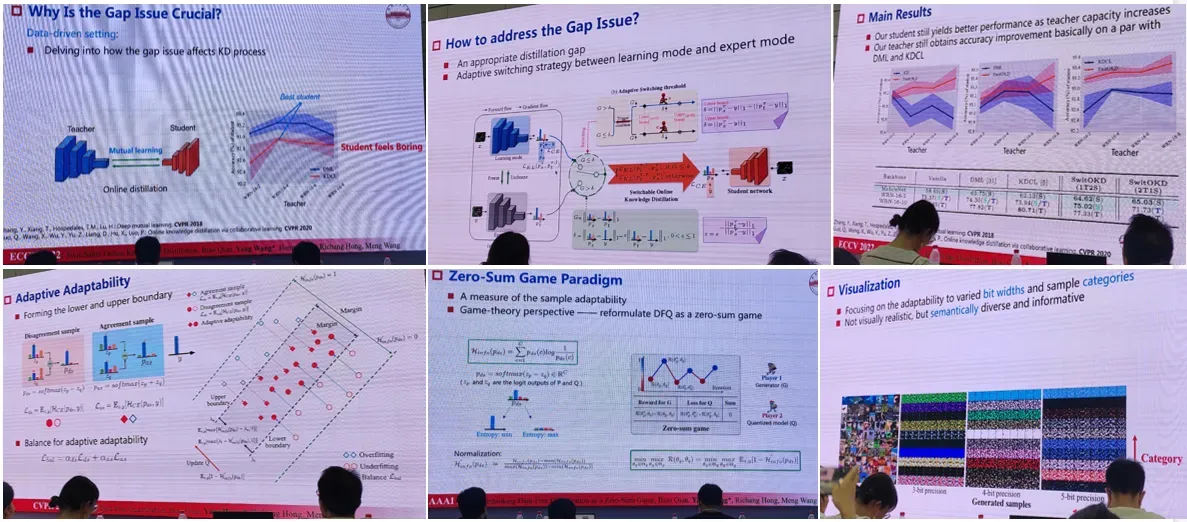
2.知识蒸馏场景下的样本生成
王杨 合肥工业大学
摘要:近年来,基于数据安全与隐私问题,无数据场景下的知识蒸馏方法获得了越来越多的关注。然而,现有方法侧重于恢复原始数据,忽略了生成样本对于学生模型的适应性,在涉及老师-学生网络模型存在较大差异的情况下,仍然面临着诸多挑战。在本次报告中,我们首先通过以下几个问题介绍关于知识蒸馏的差异性研究:老师学生模型差异性为什么以及什么时候会影响学生的性能?如何衡量老师学生间的差异性?然后,我们立足无数据量化任务,通过泛化误差分析,深入研究孤立学生模型所导致的欠拟合、过拟合问题。围绕生成样本的适应性,首次提出零和博弈观点进而分析无数据量化,解决了模型差异性问题,同时为生成样本构建上下边界,通过边缘优化,在无数据蒸馏过程中实现理想样本的生成。
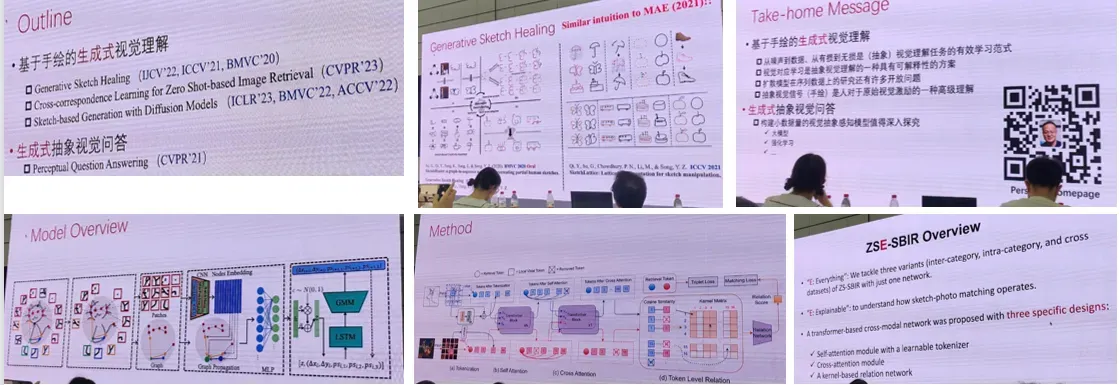
3.跨模态生成视角下的抽象视觉理解
齐勇刚 北京邮电大学
摘要:对视觉信号的感知与理解是计算机视觉与机器学习的一项核心任务。相比于自然图像,抽象图像(如手绘草图、推理图)常常是由人创作的视觉信号,蕴含的信息更加抽象,机器视觉算法理解此类图像往往更加困难。齐勇刚博士将围绕抽象视觉理解任务,分享他在基于手绘的跨模态生成与检索、基于序列模型的生成式手绘分割、残缺手绘的生成式理解、基于扩散模型的手绘生成、生成式感知视觉问答等问题上的若干最新研究成果
4.面向艺术肖像画的媒体艺术生成与评估
易冉 上海交通大学
摘要:人工智能内容生成已经引发内容创作行业的产业革命,艺术肖像画是人工智能内容生成领域的重要分支。本次报告主要分享面向艺术肖像画的媒体艺术风格生成的系列研究工作。首先,针对成对数据、单风格生成,我们提出针对线条的距离变换损失和层次化结构的生成模型,与基于流形映射的理论解释和精细艺术肖像生成模型;针对非成对数据、多风格生成,我们提出基于非对称循环结构的生成模型以解决源域、目标域信息不对称导致的信息隐藏问题,提出肖像线条画质量评估指标和基于风格空间搜索的未知新风格肖像画生成方法。其次,针对多模态信息融合问题,我们提出基于特征空间弹性匹配的语音驱动艺术肖像说话视频生成方法,基于语言模型指导的小样本扩散模型风格迁移方法,以及基于扩散模型的 3D 内容成方法。最后,针对内容生成质量难以评估的特点,我们提出了图像艺术美感评估方法,以助力后续的媒体艺术生成研究。

5.From Paint by Example to Generalized Image Editing
古纾旸 微软亚洲研究院
摘要:近年来,语言引导下的图像编辑技术越来越成功。然而,这些技术往往缺乏局部控制。我们首次研究了范例引导的图像编辑作为实现更精确控制的一种方法。我们通过使用自监督训练来分离和重新组织源图像和范例来实现这一点。为了避免复制粘贴的琐碎的解决方案,我们提出了一个information bottleneck和 strong augmentations。此外,为了保证可控性,我们为范例图像设计了一个任意形状的掩模。我们的框架涉及到一个单一的正向扩散模型,没有迭代优化。这种新技术允许以高保真度对 in-the-wild 图像进行可控编辑。通过将其与语言引导的编辑方法相结合,我们提出了一个通用的图像编辑框架,它可以处理各种基于语言指令的图像编辑操作。
整体效果:

解决方案与改进:

Workshop 15:自监督视觉表征学习
Workshop 17:视觉知识和多重知识表达
Workshop 19:优秀学生论坛
代码如下(示例):
代码如下(示例):
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
文章出处登录后可见!