目录
一、安装配置环境
代码地址 GitHub – botaoye/OSTrack: [ECCV 2022] Joint Feature Learning and Relation Modeling for Tracking: A One-Stream Framework
按照官网的 option1 方法,在根目录下执行
conda create -n ostrack python=3.8
conda activate ostrack
bash install.sh二、运行测试,遇到的问题
1、按照官网,首先建立各种路径,
执行
python tracking/create_default_local_file.py --workspace_dir . --data_dir ./data --save_dir ./output遇到问题
ImportError: libGL.so.1: cannot open shared object file: No such file or directory解决办法
apt-get install libgl1运行上述脚本后,会在 /root/data/zjx/Code-subject/OSTrack-main/lib/train/admin 目录下生成 local.py 文件 以及 lib/test/evaluation/ 下的 local.py 。里面是各种路径的默认设置。
2、建立训练数据集
在 项目 根目录 路径下 按照官网的 格式 设立。然
python tracking/train.py --script ostrack --config vitb_256_mae_ce_32x4_ep300 --save_dir ./output --mode single --use_wandb 1后设立 预训练权重文件, 创建 pretrained_models 文件夹。
3、运行train 测试
在终端运行按官网来。在 本地编译器 需要运行的 是 lib/train/run_train.py ,其中的参数设置成
Namespace(config=’vitb_256_mae_ce_32x4_ep300′, config_prv=’baseline’, config_teacher=None, distill=0, ip=’127.0.0.1′, mode=’single’, nproc_per_node=None, port=20000, rank=None, save_dir=’./output’, script=’ostrack’, script_prv=None, script_teacher=None, use_lmdb=0, use_wandb=0, world_size=None)
--script ostrack--config vitb_256_mae_ce_32x4_ep300--save_dir ./output--use_lmdb 0--script_prv None--config_prv baseline--distill 0--script_teacher None--config_teacher None--use_wandb 0
当时 只用了GOT10k 一个数据集做运行测试, 所以需要去相应的配置文件下 注销掉 其它用到的数据集。
--script ostrack --config vitb_256_mae_ce_32x4_ep300去这个文件下更改
TRAIN:
DATASETS_NAME:
# - LASOT
- GOT10K_vottrain
# - COCO17
# - TRACKINGNET终端运行时 单卡训练时需要设置参数 –mode single。 那个 wandb 先不用设置,实现需要创建账户的
python tracking/train.py --script ostrack --config vitb_256_mae_ce_32x4_ep300 --save_dir ./output --mode single 遇到的问题
1)
Traceback (most recent call last):
File "/root/data/zjx/Code-subject/OSTrack-main/lib/train/../../lib/train/trainers/base_trainer.py", line 85, in train
self.train_epoch()
File "/root/data/zjx/Code-subject/OSTrack-main/lib/train/../../lib/train/trainers/ltr_trainer.py", line 133, in train_epoch
self.cycle_dataset(loader)
File "/root/data/zjx/Code-subject/OSTrack-main/lib/train/../../lib/train/trainers/ltr_trainer.py", line 74, in cycle_dataset
for i, data in enumerate(loader, 1):
File "/root/anaconda3/envs/ostrack/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 521, in __next__
data = self._next_data()
File "/root/anaconda3/envs/ostrack/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1203, in _next_data
return self._process_data(data)
File "/root/anaconda3/envs/ostrack/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1229, in _process_data
data.reraise()
File "/root/anaconda3/envs/ostrack/lib/python3.8/site-packages/torch/_utils.py", line 425, in reraise
raise self.exc_type(msg)
ValueError: Caught ValueError in DataLoader worker process 0.
Original Traceback (most recent call last):
File "/root/anaconda3/envs/ostrack/lib/python3.8/site-packages/torch/utils/data/_utils/worker.py", line 287, in _worker_loop
data = fetcher.fetch(index)
File "/root/anaconda3/envs/ostrack/lib/python3.8/site-packages/torch/utils/data/_utils/fetch.py", line 44, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/root/anaconda3/envs/ostrack/lib/python3.8/site-packages/torch/utils/data/_utils/fetch.py", line 44, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/root/data/zjx/Code-subject/OSTrack-main/lib/train/../../lib/train/data/sampler.py", line 98, in __getitem__
return self.getitem()
File "/root/data/zjx/Code-subject/OSTrack-main/lib/train/../../lib/train/data/sampler.py", line 108, in getitem
dataset = random.choices(self.datasets, self.p_datasets)[0]
File "/root/anaconda3/envs/ostrack/lib/python3.8/random.py", line 404, in choices
raise ValueError('The number of weights does not match the population')
ValueError: The number of weights does not match the population解决办法:
第一个问题去yaml设置文件中 将 num_worker 设置为0
NUM_WORKER: 0第二个 debug 截图所示
 根据问题出处 lib\train\data\sampler.py — 109
根据问题出处 lib\train\data\sampler.py — 109
dataset = random.choices(self.datasets, self.p_datasets)[0]替换 (因为测试运行时只用了一个数据集 GOT10k)
dataset = self.datasets[0]继续运行测试,遇到
FileNotFoundError: [Errno 2] No such file or directory: '/root/data/zjx/Code-subject/OSTrack-main/tracking/data/got10k/train/GOT-10k_Train_008341/groundtruth.txt'解决办法:GOT10k数据集的格式 改一下, 将 train 文件夹下的所有 split 文件夹下的 文件 放到 train下即可。
继续运行测试,遇到
RuntimeError: CUDA out of memory. Tried to allocate 24.00 MiB (GPU 0; 10.76 GiB total capacity; 9.68 GiB already allocated; 13.56 MiB free; 9.74 GiB reserved in total by PyTorch)解决办法,去 yaml 文件 调小 batch size。
三、阅读代码记录
网络结构
OSTrack(
(backbone): VisionTransformerCE(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
(norm): Identity()
)
(pos_drop): Dropout(p=0.0, inplace=False)
(blocks): Sequential(
(0): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): Identity()
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(1): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.009)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(2): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.018)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(3): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.027)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(4): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.036)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(5): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.045)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(6): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.055)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(7): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.064)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(8): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.073)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(9): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.082)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(10): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.091)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(11): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.100)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
)
(norm): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
)
(box_head): CenterPredictor(
(conv1_ctr): Sequential(
(0): Conv2d(768, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2_ctr): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3_ctr): Sequential(
(0): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv4_ctr): Sequential(
(0): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv5_ctr): Conv2d(32, 1, kernel_size=(1, 1), stride=(1, 1))
(conv1_offset): Sequential(
(0): Conv2d(768, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2_offset): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3_offset): Sequential(
(0): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv4_offset): Sequential(
(0): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv5_offset): Conv2d(32, 2, kernel_size=(1, 1), stride=(1, 1))
(conv1_size): Sequential(
(0): Conv2d(768, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2_size): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3_size): Sequential(
(0): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv4_size): Sequential(
(0): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv5_size): Conv2d(32, 2, kernel_size=(1, 1), stride=(1, 1))
)
)1、打印日志处
1)
script_name: ostrack.py config_name: vitb_256_mae_ce_32x4_ep300.yamlrun_training.py — 42
2)
New configuration is shown below.
MODEL configuration: {'PRETRAIN_FILE': 'mae_pretrain_vit_base.pth', 'EXTRA_MERGER': False, 'RETURN_INTER': False, 'RETURN_STAGES': [], 'BACKBONE': {'TYPE': 'vit_base_patch16_224_ce', 'STRIDE': 16, 'MID_PE': False, 'SEP_SEG': False, 'CAT_MODE': 'direct', 'MERGE_LAYER': 0, 'ADD_CLS_TOKEN': False, 'CLS_TOKEN_USE_MODE': 'ignore', 'CE_LOC': [3, 6, 9], 'CE_KEEP_RATIO': [0.7, 0.7, 0.7], 'CE_TEMPLATE_RANGE': 'CTR_POINT'}, 'HEAD': {'TYPE': 'CENTER', 'NUM_CHANNELS': 256}}
TRAIN configuration: {'LR': 0.0004, 'WEIGHT_DECAY': 0.0001, 'EPOCH': 300, 'LR_DROP_EPOCH': 240, 'BATCH_SIZE': 4, 'NUM_WORKER': 0, 'OPTIMIZER': 'ADAMW', 'BACKBONE_MULTIPLIER': 0.1, 'GIOU_WEIGHT': 2.0, 'L1_WEIGHT': 5.0, 'FREEZE_LAYERS': [0], 'PRINT_INTERVAL': 50, 'VAL_EPOCH_INTERVAL': 20, 'GRAD_CLIP_NORM': 0.1, 'AMP': False, 'CE_START_EPOCH': 20, 'CE_WARM_EPOCH': 80, 'DROP_PATH_RATE': 0.1, 'SCHEDULER': {'TYPE': 'step', 'DECAY_RATE': 0.1}}
DATA configuration: {'SAMPLER_MODE': 'causal', 'MEAN': [0.485, 0.456, 0.406], 'STD': [0.229, 0.224, 0.225], 'MAX_SAMPLE_INTERVAL': 200, 'TRAIN': {'DATASETS_NAME': ['GOT10K_vottrain'], 'DATASETS_RATIO': [1, 1, 1, 1], 'SAMPLE_PER_EPOCH': 60000}, 'VAL': {'DATASETS_NAME': ['GOT10K_votval'], 'DATASETS_RATIO': [1], 'SAMPLE_PER_EPOCH': 10000}, 'SEARCH': {'SIZE': 256, 'FACTOR': 4.0, 'CENTER_JITTER': 3, 'SCALE_JITTER': 0.25, 'NUMBER': 1}, 'TEMPLATE': {'NUMBER': 1, 'SIZE': 128, 'FACTOR': 2.0, 'CENTER_JITTER': 0, 'SCALE_JITTER': 0}}train_script.py — 32 33
3)
No matching checkpoint file foundbase_trainer.py — 174
4)
[train: 1, 50 / 15000] FPS: 5.9 (5.0) , DataTime: 0.508 (0.002) , ForwardTime: 0.171 , TotalTime: 0.681 , Loss/total: 50.35498 , Loss/giou: 1.22484 , Loss/l1: 0.28600 , Loss/location: 46.47531 , IoU: 0.07033ltr_trainer.py — 112
2、debug 参数记录
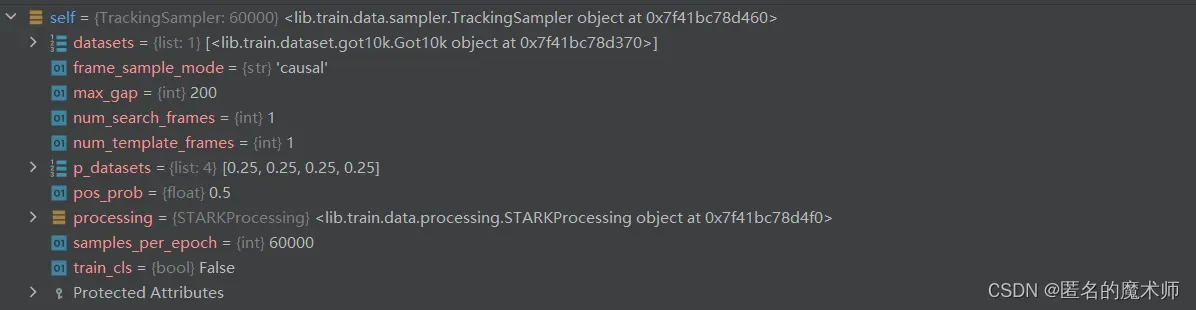
1、settings
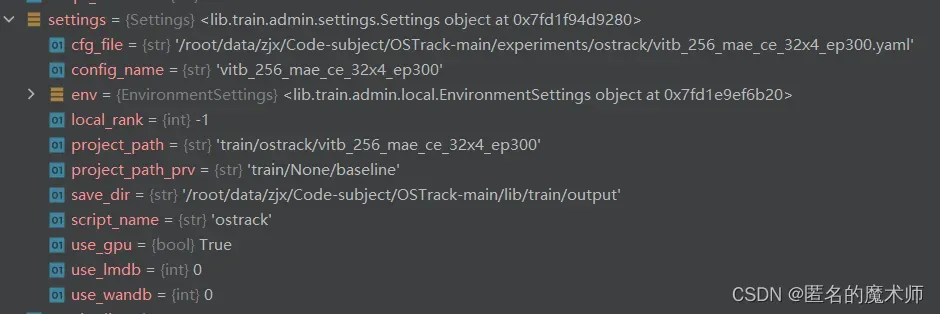
2、config
{'MODEL': {'PRETRAIN_FILE': 'mae_pretrain_vit_base.pth', 'EXTRA_MERGER': False, 'RETURN_INTER': False, 'RETURN_STAGES': [], 'BACKBONE': {'TYPE': 'vit_base_patch16_224', 'STRIDE': 16, 'MID_PE': False, 'SEP_SEG': False, 'CAT_MODE': 'direct', 'MERGE_LAYER': 0, 'ADD_CLS_TOKEN': False, 'CLS_TOKEN_USE_MODE': 'ignore', 'CE_LOC': [], 'CE_KEEP_RATIO': [], 'CE_TEMPLATE_RANGE': 'ALL'}, 'HEAD': {'TYPE': 'CENTER', 'NUM_CHANNELS': 256}}, 'TRAIN': {'LR': 0.0001, 'WEIGHT_DECAY': 0.0001, 'EPOCH': 500, 'LR_DROP_EPOCH': 400, 'BATCH_SIZE': 16, 'NUM_WORKER': 8, 'OPTIMIZER': 'ADAMW', 'BACKBONE_MULTIPLIER': 0.1, 'GIOU_WEIGHT': 2.0, 'L1_WEIGHT': 5.0, 'FREEZE_LAYERS': [0], 'PRINT_INTERVAL': 50, 'VAL_EPOCH_INTERVAL': 20, 'GRAD_CLIP_NORM': 0.1, 'AMP': False, 'CE_START_EPOCH': 20, 'CE_WARM_EPOCH': 80, 'DROP_PATH_RATE': 0.1, 'SCHEDULER': {'TYPE': 'step', 'DECAY_RATE': 0.1}}, 'DATA': {'SAMPLER_MODE': 'causal', 'MEAN': [0.485, 0.456, 0.406], 'STD': [0.229, 0.224, 0.225], 'MAX_SAMPLE_INTERVAL': 200, 'TRAIN': {'DATASETS_NAME': ['LASOT', 'GOT10K_vottrain'], 'DATASETS_RATIO': [1, 1], 'SAMPLE_PER_EPOCH': 60000}, 'VAL': {'DATASETS_NAME': ['GOT10K_votval'], 'DATASETS_RATIO': [1], 'SAMPLE_PER_EPOCH': 10000}, 'SEARCH': {'SIZE': 320, 'FACTOR': 5.0, 'CENTER_JITTER': 4.5, 'SCALE_JITTER': 0.5, 'NUMBER': 1}, 'TEMPLATE': {'NUMBER': 1, 'SIZE': 128, 'FACTOR': 2.0, 'CENTER_JITTER': 0, 'SCALE_JITTER': 0}}, 'TEST': {'TEMPLATE_FACTOR': 2.0, 'TEMPLATE_SIZE': 128, 'SEARCH_FACTOR': 5.0, 'SEARCH_SIZE': 320, 'EPOCH': 500}}3、actor

4、self.loaders

5、最终的 out

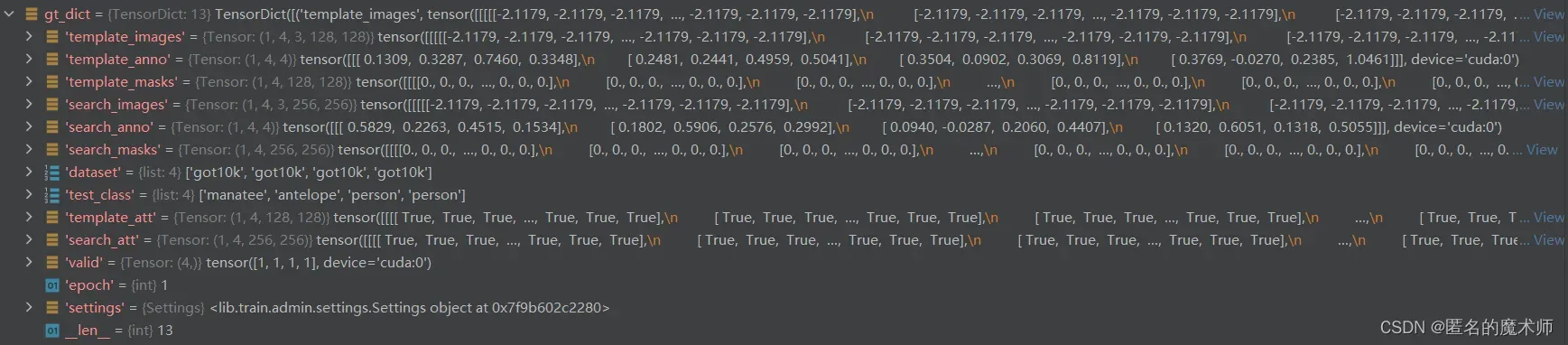
6、gt_dict
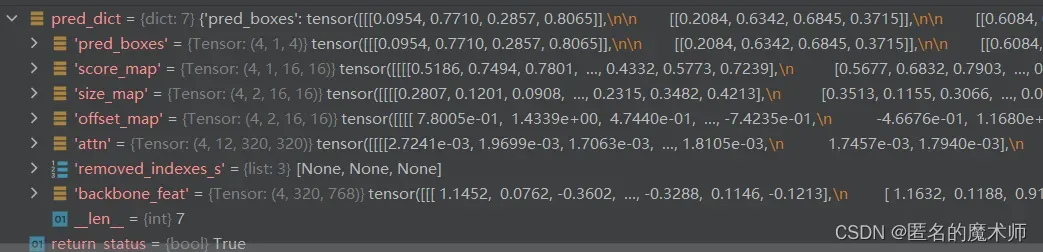
7、pred_dict
8、model_kwargs

9、data

10、index

11、checkpoint

12、dir_list
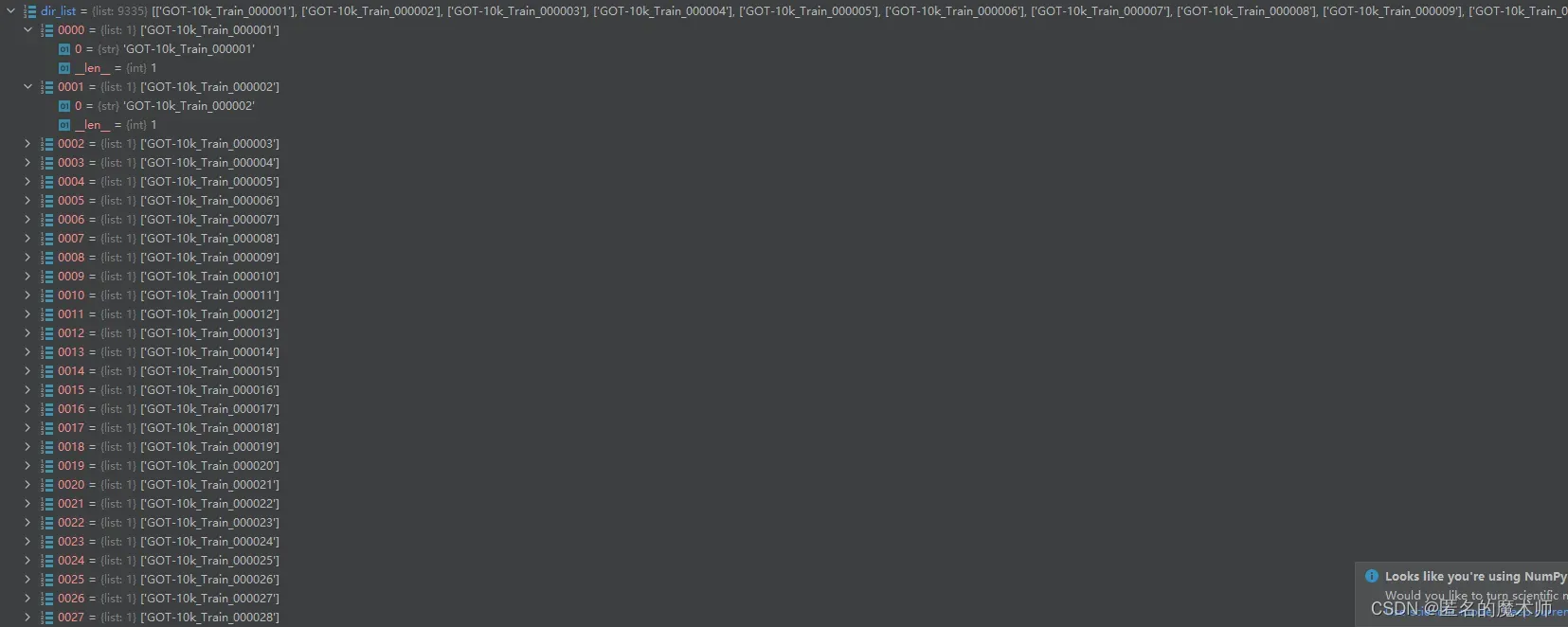
dir_list

13、seq_ids

14、self.sequence_list

15、meta_info
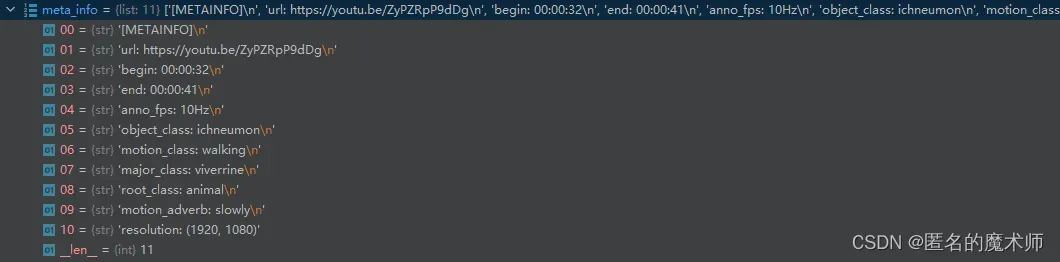
[‘[METAINFO]\n’, ‘url: https://youtu.be/ZyPZRpP9dDg\n’, ‘begin: 00:00:32\n’, ‘end: 00:00:41\n’, ‘anno_fps: 10Hz\n’, ‘object_class: ichneumon\n’, ‘motion_class: walking\n’, ‘major_class: viverrine\n’, ‘root_class: animal\n’, ‘motion_adverb: slowly\n’, ‘resolution: (1920, 1080)’]
16、object_meta

17、

18、
19、
排序后
20、

21、

22、

23、

24、

25、

26、

27、

3、一些入口
1) dataloader 的建立
train_script.py — 48
loader_train, loader_val = build_dataloaders(cfg, settings)2) 创建模型
train_script.py — 55
net = build_ostrack(cfg)这里面包括 预训练权重的加载, 以及 加载 整个模型
3) Loss actor 以及 optimer等
train_script.py — 71 始
这里的 actor 就是执行训练过程的
4)train 过程开始
train_script.py —88
5) 数据送入模型
在这上面的是
actors/ostrack.py — 69
这里才算是 数据送入模型的开始
ostrack\ostrack.py — 40
6)forward pass
actors\ostrack.py — 31
前向传播过程
7)compute loss
actors\ostrack.py — 34
8) 断点续训
base_trainer.py — 169
4、模型处理过程
1) 送入backbone
x, aux_dict = self.backbone(z=template, x=search,
ce_template_mask=ce_template_mask,
ce_keep_rate=ce_keep_rate,
return_last_attn=return_last_attn, ) # 跳转到 vit_ce.py---191 x Tensor:(4,320,768)首先进行 patch_embed
x = self.patch_embed(x)
z = self.patch_embed(z)处理过程为
def forward(self, x):
# allow different input size
# B, C, H, W = x.shape
# _assert(H == self.img_size[0], f"Input image height ({H}) doesn't match model ({self.img_size[0]}).")
# _assert(W == self.img_size[1], f"Input image width ({W}) doesn't match model ({self.img_size[1]}).")
x = self.proj(x) # Tensor:(4,768,16,16)
if self.flatten:
x = x.flatten(2).transpose(1, 2) # BCHW -> BNC # Tensor:(4,256,768)
x = self.norm(x) # Tensor:(4,256,768)
return x先经过 16X16 的卷积,然后再拉直
文中的
![]()
attn.py — 37
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)得到输出的bbox过程
def cal_bbox(self, score_map_ctr, size_map, offset_map, return_score=False):
max_score, idx = torch.max(score_map_ctr.flatten(1), dim=1, keepdim=True) # shape都是 Tensor:(4,1) 按 batch 拿出最大的得分和所对应的索引
idx_y = idx // self.feat_sz # Tensor:(4,1)
idx_x = idx % self.feat_sz # Tensor:(4,1)
idx = idx.unsqueeze(1).expand(idx.shape[0], 2, 1) # Tensor:(4,2,1)
size = size_map.flatten(2).gather(dim=2, index=idx) # Tensor:(4,2,1)
offset = offset_map.flatten(2).gather(dim=2, index=idx).squeeze(-1) # Tensor:(4,2)
# bbox = torch.cat([idx_x - size[:, 0] / 2, idx_y - size[:, 1] / 2,
# idx_x + size[:, 0] / 2, idx_y + size[:, 1] / 2], dim=1) / self.feat_sz
# cx, cy, w, h
bbox = torch.cat([(idx_x.to(torch.float) + offset[:, :1]) / self.feat_sz,
(idx_y.to(torch.float) + offset[:, 1:]) / self.feat_sz,
size.squeeze(-1)], dim=1) # Tensor:(4,4)
if return_score:
return bbox, max_score
return bbox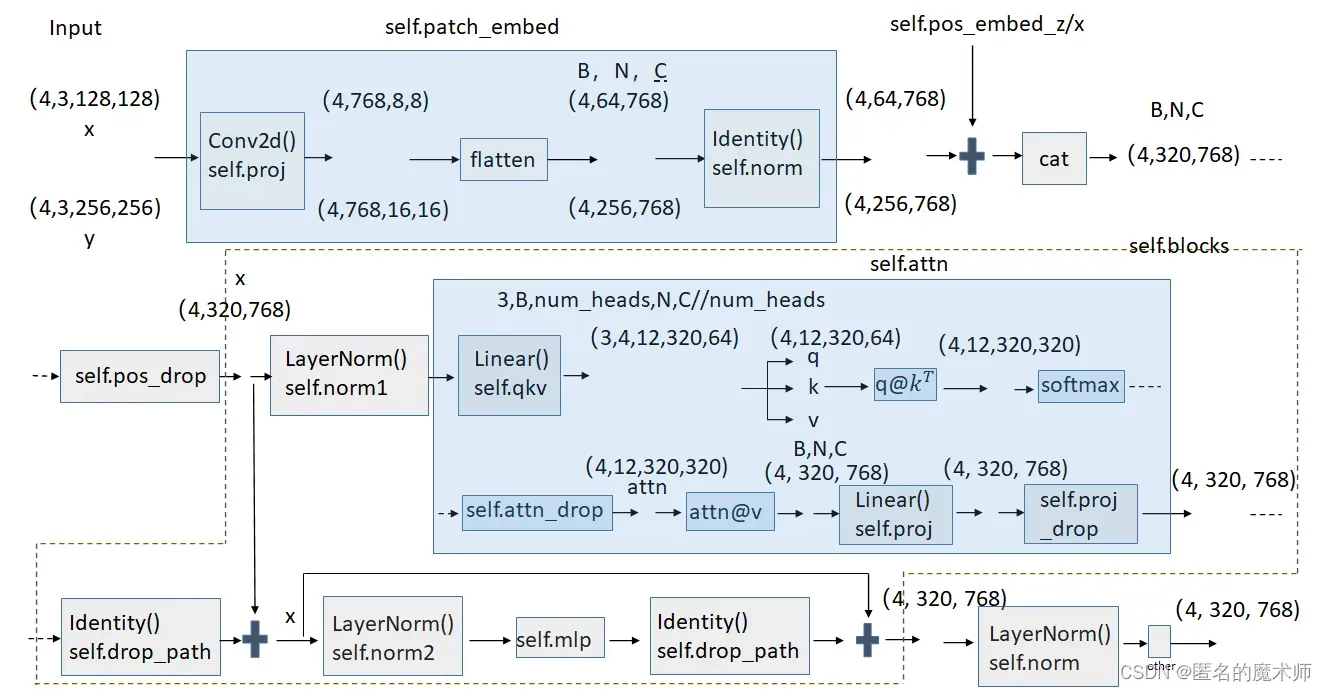
5、加载预训练 backbone
骨干网络模型定义处
vit_ce.py — 197
backbone结构:
VisionTransformerCE(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
(norm): Identity()
)
(pos_drop): Dropout(p=0.0, inplace=False)
(blocks): Sequential(
(0): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): Identity()
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(1): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.009)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(2): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.018)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(3): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.027)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(4): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.036)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(5): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.045)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(6): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.055)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(7): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.064)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(8): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.073)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(9): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.082)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(10): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.091)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(11): CEBlock(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.100)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
)
(norm): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
)加载的cfg文件内容
{‘MODEL’: {‘PRETRAIN_FILE’: ‘mae_pretrain_vit_base.pth’, ‘EXTRA_MERGER’: False, ‘RETURN_INTER’: False, ‘RETURN_STAGES’: [], ‘BACKBONE’: {‘TYPE’: ‘vit_base_patch16_224_ce’, ‘STRIDE’: 16, ‘MID_PE’: False, ‘SEP_SEG’: False, ‘CAT_MODE’: ‘direct’, ‘MERGE_LAYER’: 0, ‘ADD_CLS_TOKEN’: False, ‘CLS_TOKEN_USE_MODE’: ‘ignore’, ‘CE_LOC’: [3, 6, 9], ‘CE_KEEP_RATIO’: [0.7, 0.7, 0.7], ‘CE_TEMPLATE_RANGE’: ‘CTR_POINT’}, ‘HEAD’: {‘TYPE’: ‘CENTER’, ‘NUM_CHANNELS’: 256}}, ‘TRAIN’: {‘LR’: 0.0004, ‘WEIGHT_DECAY’: 0.0001, ‘EPOCH’: 300, ‘LR_DROP_EPOCH’: 240, ‘BATCH_SIZE’: 4, ‘NUM_WORKER’: 0, ‘OPTIMIZER’: ‘ADAMW’, ‘BACKBONE_MULTIPLIER’: 0.1, ‘GIOU_WEIGHT’: 2.0, ‘L1_WEIGHT’: 5.0, ‘FREEZE_LAYERS’: [0], ‘PRINT_INTERVAL’: 50, ‘VAL_EPOCH_INTERVAL’: 20, ‘GRAD_CLIP_NORM’: 0.1, ‘AMP’: False, ‘CE_START_EPOCH’: 20, ‘CE_WARM_EPOCH’: 80, ‘DROP_PATH_RATE’: 0.1, ‘SCHEDULER’: {‘TYPE’: ‘step’, ‘DECAY_RATE’: 0.1}}, ‘DATA’: {‘SAMPLER_MODE’: ‘causal’, ‘MEAN’: [0.485, 0.456, 0.406], ‘STD’: [0.229, 0.224, 0.225], ‘MAX_SAMPLE_INTERVAL’: 200, ‘TRAIN’: {‘DATASETS_NAME’: [‘GOT10K_vottrain’], ‘DATASETS_RATIO’: [1, 1, 1, 1], ‘SAMPLE_PER_EPOCH’: 60000}, ‘VAL’: {‘DATASETS_NAME’: [‘GOT10K_votval’], ‘DATASETS_RATIO’: [1], ‘SAMPLE_PER_EPOCH’: 10000}, ‘SEARCH’: {‘SIZE’: 256, ‘FACTOR’: 4.0, ‘CENTER_JITTER’: 3, ‘SCALE_JITTER’: 0.25, ‘NUMBER’: 1}, ‘TEMPLATE’: {‘NUMBER’: 1, ‘SIZE’: 128, ‘FACTOR’: 2.0, ‘CENTER_JITTER’: 0, ‘SCALE_JITTER’: 0}}, ‘TEST’: {‘TEMPLATE_FACTOR’: 2.0, ‘TEMPLATE_SIZE’: 128, ‘SEARCH_FACTOR’: 4.0, ‘SEARCH_SIZE’: 256, ‘EPOCH’: 300}}
6、标签的设计
gt_guassuan_pans
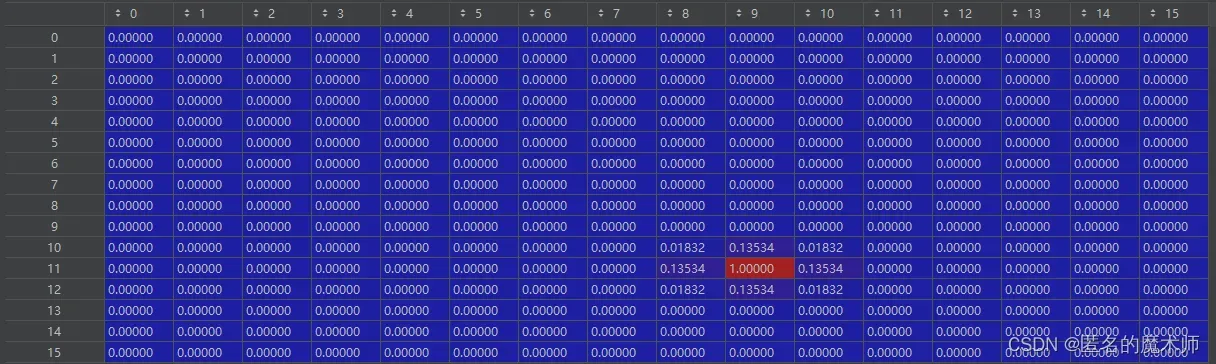
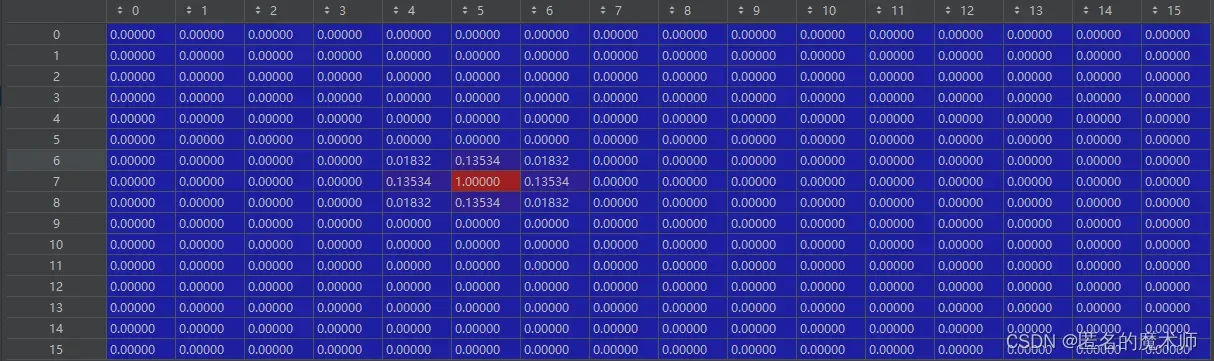
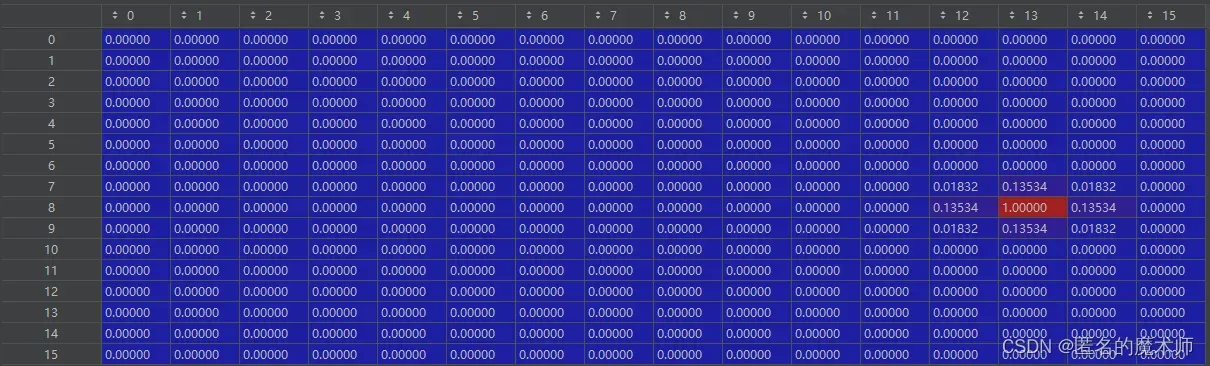
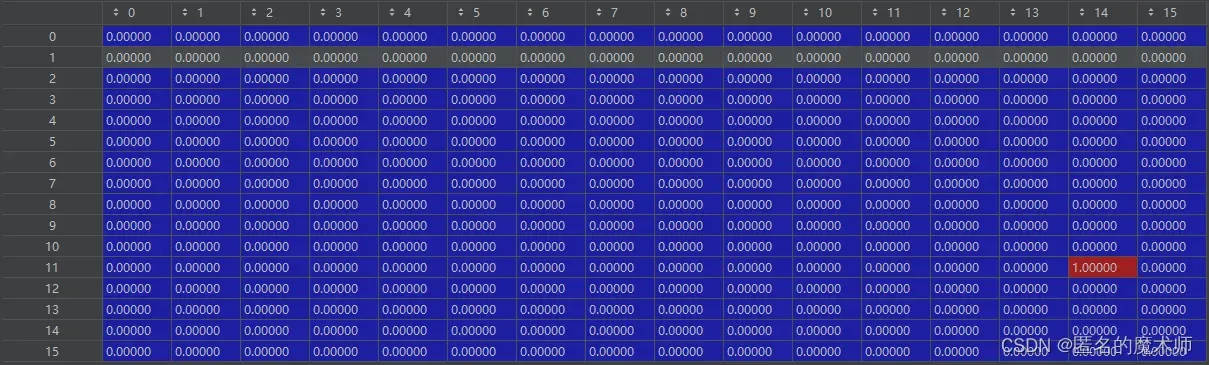
它的设立跟 gt_bbox 的 有关,这个是分类标签
7、datalodaer的创建
train_script.py — 48
用到了数据增强。
数据的加载 ,这个就与Dataloader 与 Dataset 的机制有关了。 自己定义导入数据时需要继承 Dataset 父类,并重写 __len__ 和 __getitem__ 方法。
这里的代码实现主要在 data\sampler.py 文件中。
对于got10k,每个视频序列下包含的文件如下所示

其中 absence.label 是occlusion 的,内部内容举例
with open(occlusion_file, 'r', newline='') as f:
occlusion = torch.ByteTensor([int(v[0]) for v in csv.reader(f)])
# =======
tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=torch.uint8)cover.label 举例
with open(cover_file, 'r', newline='') as f:
cover = torch.ByteTensor([int(v[0]) for v in csv.reader(f)]) # Tensor:(110,)
# =================
tensor([8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 7, 5, 1, 2, 4, 5, 8, 8, 8, 8,
8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8,
8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8,
8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8,
8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8], dtype=torch.uint8)视频序列采样时, 模板帧需要在 search 前面
# Sample test and train frames in a causal manner, i.e. search_frame_ids > template_frame_ids建立一个 训练单位 data
sampler.py — 157
data = TensorDict({'template_images': template_frames,
'template_anno': template_anno['bbox'],
'template_masks': template_masks,
'search_images': search_frames,
'search_anno': search_anno['bbox'],
'search_masks': search_masks,
'dataset': dataset.get_name(),
'test_class': meta_obj_test.get('object_class_name')})裁剪的区域是根据bbox 来的,将 输入 resize成 128X128 processing_utils.py — 68
输入的normalize 过程
transforms.py — 255
输入数据的 数据增强操作顺序
范围 (0~255)归一化到 (0,1)
然后进行 数据增强
最后归一化
def transform_image(self, image): return tvisf.normalize(image, self.mean, self.std, self.inplace)
随机数的影响 transforms.py — 102
rand_params = self.roll()模板时

搜索区域时

说明 随机数对于模板和搜索区域不统一。
8、 数据的加载过程
数据的加载过程都是在 sampler 中实现的,它重写了 Dataset 类中的方法, 所以Dataloadre 加载 导入输入数据时 从这里进行。
class TrackingSampler(torch.utils.data.Dataset):而 processing 中的内容是对 原始的输入数据进行处理 ,在这里面包括 裁剪resize, 数据增强, 归一化 等 处理。
注意,是否使用 lmdb 是由 use_lmdb 参数决定的。
2、 最终的预测
def forward(self, x, gt_score_map=None):
""" Forward pass with input x. """
score_map_ctr, size_map, offset_map = self.get_score_map(x) # Tensor:(4,1,16,16) , Tensor:(4,2,16,16), Tensor:(4,2,16,16)
# assert gt_score_map is None
if gt_score_map is None: # True
bbox = self.cal_bbox(score_map_ctr, size_map, offset_map) # Tensor:(4,4)
else:
bbox = self.cal_bbox(gt_score_map.unsqueeze(1), size_map, offset_map)
return score_map_ctr, bbox, size_map, offset_map都用上了,中和这些计算bbox head.py — 131
3、 保存训练的模型
base_trainer.py –198
# only save the last 10 checkpoints
save_every_epoch = getattr(self.settings, "save_every_epoch", False)
save_epochs = [79, 159, 239]
if epoch > (max_epochs - 1) or save_every_epoch or epoch % 40 == 0 or epoch in save_epochs or epoch > (max_epochs - 5):
# if epoch > (max_epochs - 10) or save_every_epoch or epoch % 100 == 0:
if self._checkpoint_dir:
if self.settings.local_rank in [-1, 0]:
self.save_checkpoint()文章出处登录后可见!