ResNeXt就是一种典型的混合模型,由基础的Inception+ResNet组合而成,本质在gruops分组卷积,核心创新点就是用一种平行堆叠相同拓扑结构的blocks代替原来 ResNet 的三层卷积的block,在不明显增加参数量级的情况下提升了模型的准确率,同时由于拓扑结构相同,超参数也减少了,便于模型移植。
关于论文更详细的解读可以看我上一篇笔记:经典神经网络论文超详细解读(八)——ResNeXt学习笔记(翻译+精读+代码复现)
接下来我们进行代码的复现
一、ResNeXt Block 结构
1.1 基础结构
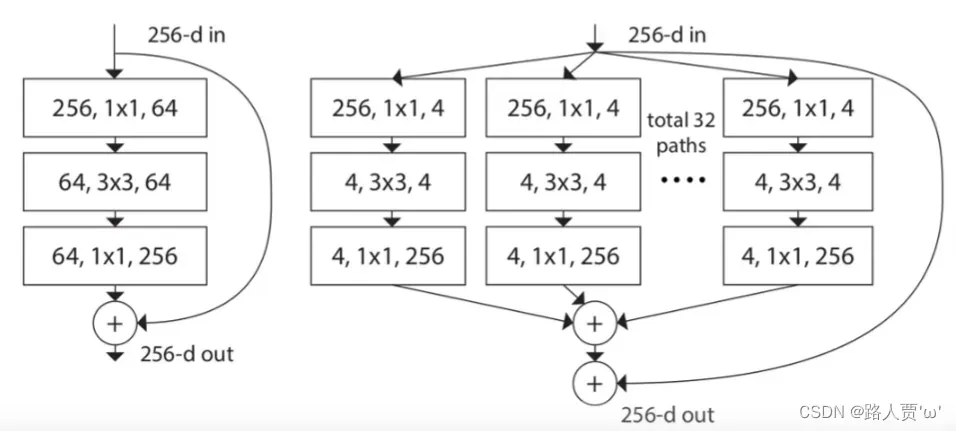
ResNeXt是ResNet基础上的改进版本,改进的部分不多,主要将之前的残差结构换成了另外的一个Block结构,并且使用了组卷积的概念。下图是ResNeXt的一个基础Block。
左图是其基础结构,灵感来自于ResNet的BottleNeck(关于ResNet代码的详细讲解,大家可以看我之前的文章:ResNet代码复现+超详细注释(PyTorch))。受Inception启发论文将Residual部分分成若干个支路,这个支路的数量就是cardinality的含义(Inception代码详细讲解可参考:GoogLeNet InceptionV1代码复现+超详细注释(PyTorch))。
右图是ResNeXt提出的一个组卷积的概念:将输入通道为256的数据通过1*1卷积压缩成大小为4的32组,合起来也就是128通道,然后进行卷积操作后,再用1*1卷积扩充回32组256通道,将32组数据按对应位置相加合成一个256通道的输出。
1.2 三种等效的优化结构
(a)表示先划分,单独卷积并计算输出,最后输出相加。split-transform-merge三阶段形式
(b)表示先划分,单独卷积,然后拼接再计算输出。将各分支的最后一个1×1卷积聚合成一个卷积。
(c)就是分组卷积。将各分支的第一个1×1卷积融合成一个卷积,3×3卷积采用group(分组)卷积的形式,分组数=cardinality(基数) 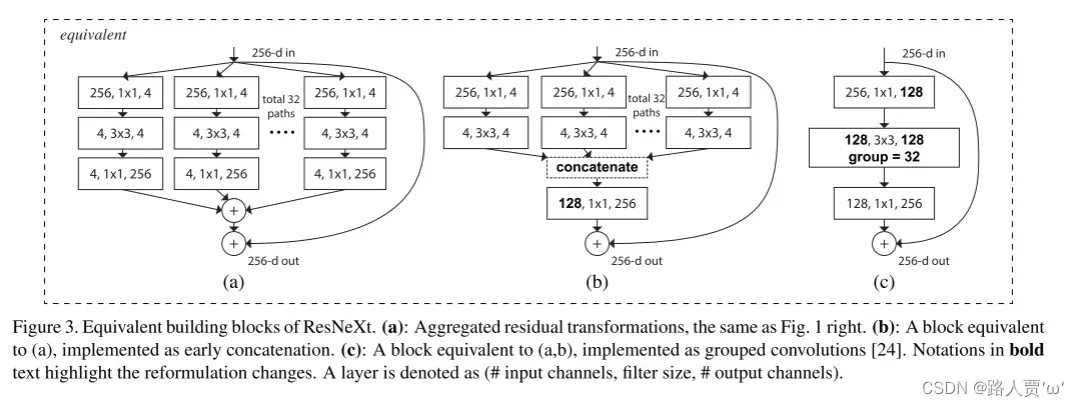
以上三个Block模块在数学计算上是完全等价的。
以(c)为例:通过1×1的卷积层将输入channel从256降为128,然后利用组卷积进行处理,卷积核大小为3×3组数为32,再利用1×1的卷积层进行升维,将输出与输入相加,得到最终输出。
再看(b)模块,就是将第一层和第二层的卷积分组,将第一层卷积(卷积核大小为1×1,每个卷积核有256层)分为32组,每组4个卷积核,这样每一组输出的channel为4;将第二层卷积也分为32组对应第一层,每一组输入的channel为4,每一组4个卷积核输出channel也为4,再将输出拼接为channel为128的输出,再经过一个256个卷积核的卷积层得到最终输出。
对于(a)模块,就是对b模块的最后一层进行拆分,就是将第二层的32组的输出再经过一层(卷积核大小为1×1,每个卷积核有4层,一共有256个卷积核)卷积,再把这32组输出相加得到最终输出。
二、ResNeXt 网络结构
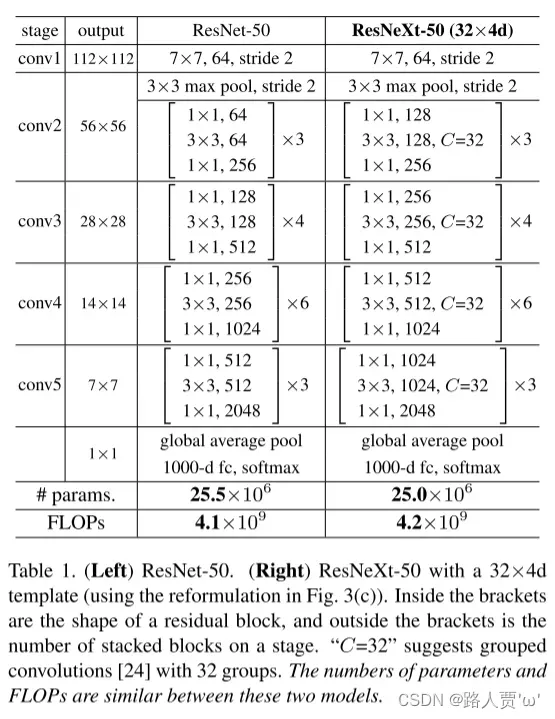
下图是ResNet-50和ResNeXt-50(32x4d)的对比,可以发现二者网络整体结构一致,ResNeXt替换了基本的block。32 指进入网络的第一个ResNeXt基本结构的分组数量C(即基数)为32。4d 表示depth即每一个分组的通道数为4(所以第一个基本结构输入通道数为128)
模型设计两个原则:
(1)如果输出的空间尺寸一样,那么模块的超参数(宽度和卷积核尺寸)也是一样的。
(2)每当空间分辨率/2(降采样),则卷积核的宽度*2。这样保持模块计算复杂度。
三、ResNeXt的PyTorch实现
3.1BasicBlock模块
基础Block模块,也就是对应18/34层的BasicBlock。这里实现和ResNet一样,就不再过多论述。
代码
'''-------------一、BasicBlock模块-----------------------------'''
# 用于ResNet18和ResNet34基本残差结构块
class BasicBlock(nn.Module):
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.left = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU(),
nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(out_channel),
nn.downsample(downsample)
)
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.left(x) # 这是由于残差块需要保留原始输入
out += identity # 这是ResNet的核心,在输出上叠加了输入x
out = F.relu(out)
return out3.2 Bottleneck模块
从表中可以看出,ResNeXt网络每一个convx的第一层和第二层卷积的卷积核个数是ResNet网络的两倍,在代码实现时,需要注意在代码中增加一下两个参数groups和width_per_group(即为group数和conv2中组卷积每个group的卷积核个数)并且根据这两个参数计算出第一层卷积的输出(为ResNet网络的两倍)。
代码
'''-------------二、Bottleneck模块-----------------------------'''
class Bottleneck(nn.Module):
expansion = 4
# 这里相对于RseNet,在代码中增加一下两个参数groups和width_per_group(即为group数和conv2中组卷积每个group的卷积核个数)
# 默认值就是正常的ResNet
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
# 这里也可以自动计算中间的通道数,也就是3x3卷积后的通道数,如果不改变就是out_channels
# 如果groups=32,with_per_group=4,out_channels就翻倍了
width = int(out_channel * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(width)
# -----------------------------------------
# 组卷积的数,需要传入参数
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel * self.expansion,
kernel_size=1, stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channel * self.expansion)
# -----------------------------------------
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity # 残差连接
out = self.relu(out)
return out3.3搭建ResNeXt网络结构
(1)网络整体结构
根据(c)模块,首先通过1×1的卷积层将输入特征矩阵的channel从256降维到128;再通过3×3的32组group卷积对其进行处理;再通过1×1的卷积层进行将特征矩阵的channel从128升维到256;最后主分支与短路连接的输出进行相加得到最终输出。
代码
'''-------------三、搭建ResNeXt结构-----------------------------'''
class ResNeXt(nn.Module):
def __init__(self,
block, # 表示block的类型
blocks_num, # 表示的是每一层block的个数
num_classes=1000, # 表示类别
include_top=True, # 表示是否含有分类层(可做迁移学习)
groups=1, # 表示组卷积的数
width_per_group=64):
super(ResNeXt, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0]) # 64 -> 128
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)# 128 -> 256
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)# 256 -> 512
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2) # 512 -> 1024
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
# 形成单个Stage的网络结构
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
# 该部分是将每个blocks的第一个残差结构保存在layers列表中。
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion # 得到最后的输出
# 该部分是将每个blocks的剩下残差结构保存在layers列表中,这样就完成了一个blocks的构造。
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
# 返回Conv Block和Identity Block的集合,形成一个Stage的网络结构
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x(2)搭建网络模型
使用时直接调用每种不同层的结构对应的残差块作为参数传入。除了残差块不同以外,每个残差块重复的次数也不同,所以也作为参数。每个不同的模型只需往ResNet模型中传入不同参数即可。
代码
def ResNet34(num_classes=1000, include_top=True):
return ResNeXt(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def ResNet50(num_classes=1000, include_top=True):
return ResNeXt(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def ResNet101(num_classes=1000, include_top=True):
return ResNeXt(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
# 论文中的ResNeXt50_32x4d
def ResNeXt50_32x4d(num_classes=1000, include_top=True):
groups = 32
width_per_group = 4
return ResNeXt(Bottleneck, [3, 4, 6, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
def ResNeXt101_32x8d(num_classes=1000, include_top=True):
groups = 32
width_per_group = 8
return ResNeXt(Bottleneck, [3, 4, 23, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
3.4测试网络模型
(1)网络模型测试并打印论文中的ResNeXt50_32x4d
if __name__ == '__main__':
model = ResNeXt50_32x4d()
print(model)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
# test()打印模型如下
ResNeXt(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
torch.Size([1, 1000])
Process finished with exit code 0(2)使用torchsummary打印每个网络模型的详细信息
from torchsummary import summary
if __name__ == '__main__':
net = ResNeXt50_32x4d().cuda()
summary(net, (3, 224, 224))打印模型如下
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2d-5 [-1, 256, 56, 56] 16,384
BatchNorm2d-6 [-1, 256, 56, 56] 512
Conv2d-7 [-1, 128, 56, 56] 8,192
BatchNorm2d-8 [-1, 128, 56, 56] 256
ReLU-9 [-1, 128, 56, 56] 0
Conv2d-10 [-1, 128, 56, 56] 4,608
BatchNorm2d-11 [-1, 128, 56, 56] 256
ReLU-12 [-1, 128, 56, 56] 0
Conv2d-13 [-1, 256, 56, 56] 32,768
BatchNorm2d-14 [-1, 256, 56, 56] 512
ReLU-15 [-1, 256, 56, 56] 0
Bottleneck-16 [-1, 256, 56, 56] 0
Conv2d-17 [-1, 128, 56, 56] 32,768
BatchNorm2d-18 [-1, 128, 56, 56] 256
ReLU-19 [-1, 128, 56, 56] 0
Conv2d-20 [-1, 128, 56, 56] 4,608
BatchNorm2d-21 [-1, 128, 56, 56] 256
ReLU-22 [-1, 128, 56, 56] 0
Conv2d-23 [-1, 256, 56, 56] 32,768
BatchNorm2d-24 [-1, 256, 56, 56] 512
ReLU-25 [-1, 256, 56, 56] 0
Bottleneck-26 [-1, 256, 56, 56] 0
Conv2d-27 [-1, 128, 56, 56] 32,768
BatchNorm2d-28 [-1, 128, 56, 56] 256
ReLU-29 [-1, 128, 56, 56] 0
Conv2d-30 [-1, 128, 56, 56] 4,608
BatchNorm2d-31 [-1, 128, 56, 56] 256
ReLU-32 [-1, 128, 56, 56] 0
Conv2d-33 [-1, 256, 56, 56] 32,768
BatchNorm2d-34 [-1, 256, 56, 56] 512
ReLU-35 [-1, 256, 56, 56] 0
Bottleneck-36 [-1, 256, 56, 56] 0
Conv2d-37 [-1, 512, 28, 28] 131,072
BatchNorm2d-38 [-1, 512, 28, 28] 1,024
Conv2d-39 [-1, 256, 56, 56] 65,536
BatchNorm2d-40 [-1, 256, 56, 56] 512
ReLU-41 [-1, 256, 56, 56] 0
Conv2d-42 [-1, 256, 28, 28] 18,432
BatchNorm2d-43 [-1, 256, 28, 28] 512
ReLU-44 [-1, 256, 28, 28] 0
Conv2d-45 [-1, 512, 28, 28] 131,072
BatchNorm2d-46 [-1, 512, 28, 28] 1,024
ReLU-47 [-1, 512, 28, 28] 0
Bottleneck-48 [-1, 512, 28, 28] 0
Conv2d-49 [-1, 256, 28, 28] 131,072
BatchNorm2d-50 [-1, 256, 28, 28] 512
ReLU-51 [-1, 256, 28, 28] 0
Conv2d-52 [-1, 256, 28, 28] 18,432
BatchNorm2d-53 [-1, 256, 28, 28] 512
ReLU-54 [-1, 256, 28, 28] 0
Conv2d-55 [-1, 512, 28, 28] 131,072
BatchNorm2d-56 [-1, 512, 28, 28] 1,024
ReLU-57 [-1, 512, 28, 28] 0
Bottleneck-58 [-1, 512, 28, 28] 0
Conv2d-59 [-1, 256, 28, 28] 131,072
BatchNorm2d-60 [-1, 256, 28, 28] 512
ReLU-61 [-1, 256, 28, 28] 0
Conv2d-62 [-1, 256, 28, 28] 18,432
BatchNorm2d-63 [-1, 256, 28, 28] 512
ReLU-64 [-1, 256, 28, 28] 0
Conv2d-65 [-1, 512, 28, 28] 131,072
BatchNorm2d-66 [-1, 512, 28, 28] 1,024
ReLU-67 [-1, 512, 28, 28] 0
Bottleneck-68 [-1, 512, 28, 28] 0
Conv2d-69 [-1, 256, 28, 28] 131,072
BatchNorm2d-70 [-1, 256, 28, 28] 512
ReLU-71 [-1, 256, 28, 28] 0
Conv2d-72 [-1, 256, 28, 28] 18,432
BatchNorm2d-73 [-1, 256, 28, 28] 512
ReLU-74 [-1, 256, 28, 28] 0
Conv2d-75 [-1, 512, 28, 28] 131,072
BatchNorm2d-76 [-1, 512, 28, 28] 1,024
ReLU-77 [-1, 512, 28, 28] 0
Bottleneck-78 [-1, 512, 28, 28] 0
Conv2d-79 [-1, 1024, 14, 14] 524,288
BatchNorm2d-80 [-1, 1024, 14, 14] 2,048
Conv2d-81 [-1, 512, 28, 28] 262,144
BatchNorm2d-82 [-1, 512, 28, 28] 1,024
ReLU-83 [-1, 512, 28, 28] 0
Conv2d-84 [-1, 512, 14, 14] 73,728
BatchNorm2d-85 [-1, 512, 14, 14] 1,024
ReLU-86 [-1, 512, 14, 14] 0
Conv2d-87 [-1, 1024, 14, 14] 524,288
BatchNorm2d-88 [-1, 1024, 14, 14] 2,048
ReLU-89 [-1, 1024, 14, 14] 0
Bottleneck-90 [-1, 1024, 14, 14] 0
Conv2d-91 [-1, 512, 14, 14] 524,288
BatchNorm2d-92 [-1, 512, 14, 14] 1,024
ReLU-93 [-1, 512, 14, 14] 0
Conv2d-94 [-1, 512, 14, 14] 73,728
BatchNorm2d-95 [-1, 512, 14, 14] 1,024
ReLU-96 [-1, 512, 14, 14] 0
Conv2d-97 [-1, 1024, 14, 14] 524,288
BatchNorm2d-98 [-1, 1024, 14, 14] 2,048
ReLU-99 [-1, 1024, 14, 14] 0
Bottleneck-100 [-1, 1024, 14, 14] 0
Conv2d-101 [-1, 512, 14, 14] 524,288
BatchNorm2d-102 [-1, 512, 14, 14] 1,024
ReLU-103 [-1, 512, 14, 14] 0
Conv2d-104 [-1, 512, 14, 14] 73,728
BatchNorm2d-105 [-1, 512, 14, 14] 1,024
ReLU-106 [-1, 512, 14, 14] 0
Conv2d-107 [-1, 1024, 14, 14] 524,288
BatchNorm2d-108 [-1, 1024, 14, 14] 2,048
ReLU-109 [-1, 1024, 14, 14] 0
Bottleneck-110 [-1, 1024, 14, 14] 0
Conv2d-111 [-1, 512, 14, 14] 524,288
BatchNorm2d-112 [-1, 512, 14, 14] 1,024
ReLU-113 [-1, 512, 14, 14] 0
Conv2d-114 [-1, 512, 14, 14] 73,728
BatchNorm2d-115 [-1, 512, 14, 14] 1,024
ReLU-116 [-1, 512, 14, 14] 0
Conv2d-117 [-1, 1024, 14, 14] 524,288
BatchNorm2d-118 [-1, 1024, 14, 14] 2,048
ReLU-119 [-1, 1024, 14, 14] 0
Bottleneck-120 [-1, 1024, 14, 14] 0
Conv2d-121 [-1, 512, 14, 14] 524,288
BatchNorm2d-122 [-1, 512, 14, 14] 1,024
ReLU-123 [-1, 512, 14, 14] 0
Conv2d-124 [-1, 512, 14, 14] 73,728
BatchNorm2d-125 [-1, 512, 14, 14] 1,024
ReLU-126 [-1, 512, 14, 14] 0
Conv2d-127 [-1, 1024, 14, 14] 524,288
BatchNorm2d-128 [-1, 1024, 14, 14] 2,048
ReLU-129 [-1, 1024, 14, 14] 0
Bottleneck-130 [-1, 1024, 14, 14] 0
Conv2d-131 [-1, 512, 14, 14] 524,288
BatchNorm2d-132 [-1, 512, 14, 14] 1,024
ReLU-133 [-1, 512, 14, 14] 0
Conv2d-134 [-1, 512, 14, 14] 73,728
BatchNorm2d-135 [-1, 512, 14, 14] 1,024
ReLU-136 [-1, 512, 14, 14] 0
Conv2d-137 [-1, 1024, 14, 14] 524,288
BatchNorm2d-138 [-1, 1024, 14, 14] 2,048
ReLU-139 [-1, 1024, 14, 14] 0
Bottleneck-140 [-1, 1024, 14, 14] 0
Conv2d-141 [-1, 2048, 7, 7] 2,097,152
BatchNorm2d-142 [-1, 2048, 7, 7] 4,096
Conv2d-143 [-1, 1024, 14, 14] 1,048,576
BatchNorm2d-144 [-1, 1024, 14, 14] 2,048
ReLU-145 [-1, 1024, 14, 14] 0
Conv2d-146 [-1, 1024, 7, 7] 294,912
BatchNorm2d-147 [-1, 1024, 7, 7] 2,048
ReLU-148 [-1, 1024, 7, 7] 0
Conv2d-149 [-1, 2048, 7, 7] 2,097,152
BatchNorm2d-150 [-1, 2048, 7, 7] 4,096
ReLU-151 [-1, 2048, 7, 7] 0
Bottleneck-152 [-1, 2048, 7, 7] 0
Conv2d-153 [-1, 1024, 7, 7] 2,097,152
BatchNorm2d-154 [-1, 1024, 7, 7] 2,048
ReLU-155 [-1, 1024, 7, 7] 0
Conv2d-156 [-1, 1024, 7, 7] 294,912
BatchNorm2d-157 [-1, 1024, 7, 7] 2,048
ReLU-158 [-1, 1024, 7, 7] 0
Conv2d-159 [-1, 2048, 7, 7] 2,097,152
BatchNorm2d-160 [-1, 2048, 7, 7] 4,096
ReLU-161 [-1, 2048, 7, 7] 0
Bottleneck-162 [-1, 2048, 7, 7] 0
Conv2d-163 [-1, 1024, 7, 7] 2,097,152
BatchNorm2d-164 [-1, 1024, 7, 7] 2,048
ReLU-165 [-1, 1024, 7, 7] 0
Conv2d-166 [-1, 1024, 7, 7] 294,912
BatchNorm2d-167 [-1, 1024, 7, 7] 2,048
ReLU-168 [-1, 1024, 7, 7] 0
Conv2d-169 [-1, 2048, 7, 7] 2,097,152
BatchNorm2d-170 [-1, 2048, 7, 7] 4,096
ReLU-171 [-1, 2048, 7, 7] 0
Bottleneck-172 [-1, 2048, 7, 7] 0
AdaptiveAvgPool2d-173 [-1, 2048, 1, 1] 0
Linear-174 [-1, 1000] 2,049,000
================================================================
Total params: 25,028,904
Trainable params: 25,028,904
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 361.78
Params size (MB): 95.48
Estimated Total Size (MB): 457.83
----------------------------------------------------------------
Process finished with exit code 03.5完整代码
import torch
import torch.nn as nn
import torch.nn.functional as F
'''-------------一、BasicBlock模块-----------------------------'''
# 用于ResNet18和ResNet34基本残差结构块
class BasicBlock(nn.Module):
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.left = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU(),
nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(out_channel),
nn.downsample(downsample)
)
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.left(x) # 这是由于残差块需要保留原始输入
out += identity # 这是ResNet的核心,在输出上叠加了输入x
out = F.relu(out)
return out
'''-------------二、Bottleneck模块-----------------------------'''
class Bottleneck(nn.Module):
expansion = 4
# 这里相对于RseNet,在代码中增加一下两个参数groups和width_per_group(即为group数和conv2中组卷积每个group的卷积核个数)
# 默认值就是正常的ResNet
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
# 这里也可以自动计算中间的通道数,也就是3x3卷积后的通道数,如果不改变就是out_channels
# 如果groups=32,with_per_group=4,out_channels就翻倍了
width = int(out_channel * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(width)
# -----------------------------------------
# 组卷积的数,需要传入参数
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel * self.expansion,
kernel_size=1, stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channel * self.expansion)
# -----------------------------------------
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity # 残差连接
out = self.relu(out)
return out
'''-------------三、搭建ResNeXt结构-----------------------------'''
class ResNeXt(nn.Module):
def __init__(self,
block, # 表示block的类型
blocks_num, # 表示的是每一层block的个数
num_classes=1000, # 表示类别
include_top=True, # 表示是否含有分类层(可做迁移学习)
groups=1, # 表示组卷积的数
width_per_group=64):
super(ResNeXt, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0]) # 64 -> 128
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)# 128 -> 256
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)# 256 -> 512
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2) # 512 -> 1024
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
# 形成单个Stage的网络结构
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
# 该部分是将每个blocks的第一个残差结构保存在layers列表中。
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion # 得到最后的输出
# 该部分是将每个blocks的剩下残差结构保存在layers列表中,这样就完成了一个blocks的构造。
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
# 返回Conv Block和Identity Block的集合,形成一个Stage的网络结构
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def ResNet34(num_classes=1000, include_top=True):
return ResNeXt(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def ResNet50(num_classes=1000, include_top=True):
return ResNeXt(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def ResNet101(num_classes=1000, include_top=True):
return ResNeXt(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
# 论文中的ResNeXt50_32x4d
def ResNeXt50_32x4d(num_classes=1000, include_top=True):
groups = 32
width_per_group = 4
return ResNeXt(Bottleneck, [3, 4, 6, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
def ResNeXt101_32x8d(num_classes=1000, include_top=True):
groups = 32
width_per_group = 8
return ResNeXt(Bottleneck, [3, 4, 23, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
'''
if __name__ == '__main__':
model = ResNeXt50_32x4d()
print(model)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
# test()
'''
from torchsummary import summary
if __name__ == '__main__':
net = ResNeXt50_32x4d().cuda()
summary(net, (3, 224, 224))
文章出处登录后可见!