在跑DDP模型时遇到了如下问题.
[W socket.cpp:558] [c10d] The client socket has failed to connect to [localhost]:12355 (errno: 99 – Cannot assign requested address).
测试用的代码如下:
from datetime import datetime
import argparse
import torchvision
import torchvision.transforms as transforms
import torch
import torch.nn as nn
import torch.distributed as dist
from tqdm import tqdm
import torch.multiprocessing as mp
import os
# TCP模式启动很好理解,需要在bash中独立的启动每一个进程,并为每个进程分配好其rank序号。缺点是当进程数多的时候启动比较麻烦。
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7 * 7 * 32, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
def train(gpu, args):
# ---------------------------- 改动之处1 DDP的初始化----------------------------
os.environ['MASTER_ADDR'] = args.master_addr
os.environ['MASTER_PORT'] = args.master_port
# dist.init_process_group(backend='nccl', init_method=args.init_method, rank=gpu, world_size=args.world_size)
dist.init_process_group(backend='nccl', rank=gpu, world_size=args.world_size)
# ------------------------------------------------------------------------------
model = ConvNet()
model.cuda(gpu)
# ---------------------------- 改动之处2 包装模型-------------------------------
model = nn.SyncBatchNorm.convert_sync_batchnorm(model) # 转换为同步BN层
model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu]) # 包装模型
# ------------------------------------------------------------------------------
criterion = nn.CrossEntropyLoss().to(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
train_dataset = torchvision.datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
# --------------------------- 改动之处3 Sampler的使用----------------------------
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset) # , num_replicas=args.world_size, rank=gpu)
# -------------------------------------------------------------------------------
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=args.batch_size,
shuffle=False, # 这里的shuffle变为了False
num_workers=2,
pin_memory=True,
sampler=train_sampler)
start = datetime.now()
total_step = len(train_loader)
for epoch in range(args.epochs):
# -------------------------- 改动之处4 在每个epoch开始前打乱数据顺序-------------------------
train_loader.sampler.set_epoch(epoch)
# ------------------------------------------------------------------------------------------
model.train()
for i, (images, labels) in enumerate(tqdm(train_loader)):
images = images.to(gpu)
labels = labels.to(gpu)
# ---------------- 改动之处5 控制前向过程中是否使用半精度计算,可不加-------------------------
with torch.cuda.amp.autocast(enabled=args.use_mix_precision):
outputs = model(images)
loss = criterion(outputs, labels)
# ------------------------------------------------------------------------------------------
optimizer.zero_grad()
loss.backward()
optimizer.step()
# ----------------------- 改动之处6 只让rank0进程打印输出结果-----------------------------
if (i + 1) % 1000 == 0 and gpu == 0:
print(f'Epoch [{epoch + 1}/{args.epochs}], Step [{i + 1}/{total_step}], Loss: {loss.item()}')
# ----------------------------------------------------------------------------------------
# ----------------------- 改动之处7 清理进程--------------------------------
dist.destroy_process_group()
if gpu == 0:
print("Training complete in: " + str(datetime.now() - start))
# --------------------------------------------------------------------------
def main():
parser = argparse.ArgumentParser()
parser.add_argument('-g', '--gpuid', default=0, type=int,
help="which gpu to use")
parser.add_argument('-e', '--epochs', default=2, type=int,
metavar='N',
help='number of total epochs to run')
parser.add_argument('-b', '--batch_size', default=4, type=int,
metavar='N',
help='number of batchsize')
# ------------------------------- 改动之处 ---------------------------------
parser.add_argument('--master_addr', default='localhost',
help='master address')
parser.add_argument('--master_port', default='12355',
help='master port')
# parser.add_argument('-r', '--rank', default=0, type=int,
# help='rank of current process')
parser.add_argument('--world_size', default=2, type=int,
help="world size")
parser.add_argument('--use_mix_precision', default=False, # 这个不加也没事
action='store_true', help="whether to use mix precision")
# ------------------------------------------------------------------------------
args = parser.parse_args()
# train(args.gpuid, args)
mp.spawn(train, nprocs=args.world_size, args=(args,))
if __name__ == '__main__':
main()
# 运行方法:直接run
上述代码直接运行会报上述的问题,但是好像不会影响运行(?)
一开始我还以为是端口被占用了,经过检查发现并没有问题,猜测可能是多线程运行导致程序出了问题
同时我发现在如下地方加入一行print()代码就不会报这个错误。
def train(gpu, args):
print("test") # 随便打印什么都行
# ---------------------------- 改动之处1 DDP的初始化----------------------------
os.environ['MASTER_ADDR'] = args.master_addr
os.environ['MASTER_PORT'] = args.master_port
# dist.init_process_group(backend='nccl', init_method=args.init_method, rank=gpu, world_size=args.world_size)
dist.init_process_group(backend='nccl', rank=gpu, world_size=args.world_size)
更新
好像不大对,加上这个打印有时候也会报错,但是报错频率明显下降,好怪,重新思考一下这个问题
def train(gpu, args):
# ---------------------------- 改动之处1 DDP的初始化----------------------------
print(f"{gpu} 11111")
os.environ['MASTER_ADDR'] = args.master_addr
os.environ['MASTER_PORT'] = args.master_port
# os.environ['MASTER_ADDR'] = "localhost"
# os.environ['MASTER_PORT'] = "12355"
# dist.init_process_group(backend='nccl', init_method=args.init_method, rank=gpu, world_size=args.world_size)
print(f"{gpu} 22222")
# time.sleep(3)
dist.init_process_group(backend='nccl', rank=gpu, world_size=args.world_size)
print(f"{gpu} 33333")
加上GPU的编号(实验环境是双卡),发现这种情况下会正常运行,也就是说GPU0先启动

出现这种情况,当GPU1先启动时,就会报这个错误,那我们的目标就是让线程1晚点启动
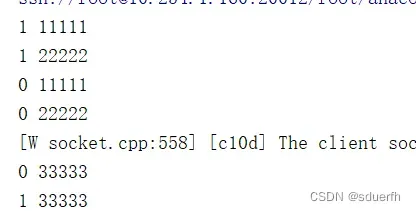
思路已经明确了,让0号线程先于1号线程启动
def train(gpu, args):
# ---------------------------- 改动之处1 DDP的初始化----------------------------
# 让线程1先休眠1秒,确保线程0先启动
if gpu == 1:
time.sleep(1)
print(f"{gpu} 11111")
os.environ['MASTER_ADDR'] = args.master_addr
os.environ['MASTER_PORT'] = args.master_port
# os.environ['MASTER_ADDR'] = "localhost"
# os.environ['MASTER_PORT'] = "12355"
# dist.init_process_group(backend='nccl', init_method=args.init_method, rank=gpu, world_size=args.world_size)
print(f"{gpu} 22222")
# time.sleep(3)
dist.init_process_group(backend='nccl', rank=gpu, world_size=args.world_size)
print(f"{gpu} 33333")
问题得以解决,但是中间原理貌似不是很明白
文章出处登录后可见!
已经登录?立即刷新