课程资源:
7、模型验证与训练过程可视化【小学生都会的Pytorch】【提供源码】_哔哩哔哩_bilibili
推荐与上一节笔记搭配食用~:
pytorch进阶学习(五):神经网络迁移学习应用的保姆级详细介绍,如何将训练好的模型替换成自己所需模型_好喜欢吃红柚子的博客-CSDN博客
- 训练和测试数据集:data(5个类)
- 验证集:testdata(从data数据集中随便抽取了20多张图片)
- 预训练网络和权重文件:使用resnet34预训练的权重文件,下载地址如下
https://download.pytorch.org/models/resnet34-333f7ec4.pth
目录
一、生成数据集 CreateDataset.py
1. 代码
2. 运行结果
二、预训练模型 PreTrainedModel.py
1. 下载预训练权重文件
2. 使用迁移学习方法修改resnet34神经网络框架并加载预训练权重
3. 模型优化
3.1 模型过程数据的保存与输出
3.2 训练过程
3.3 测试过程
3.4 运行结果
4. 代码
三、模型验证
1. 导入模型结构
2. 加载模型参数
3. 加载图片
4. 验证过程
5. 获取结果
6. 完整代码
四、可视化
1. 代码
2. 绘制图形
一、生成数据集 CreateDataset.py
生成训练集和测试集,分别保存在tes.txt、train.txt和eval.txt文件中;相当于模型的输入。后面做数据加载器dataload的时候从里面读数据。
- test.txt、train.txt:保存测试集和训练集的图片路径和标签
- eval.txt:保存验证集图片数据的路径
1. 代码
'''
生成训练集和测试集,保存在txt文件中
'''
##相当于模型的输入。后面做数据加载器dataload的时候从里面读他的数据
import os
import random#打乱数据用的
def CreateTrainingSet():
# 百分之80用来当训练集
train_ratio = 0.8
# 用来当测试集
test_ratio = 1-train_ratio
rootdata = r"data"#数据的根目录
train_list, test_list = [],[]#读取里面每一类的类别
data_list = []
#生产train.txt和test.txt
class_flag = -1
for a,b,c in os.walk(rootdata):
print(a)
for i in range(len(c)):
data_list.append(os.path.join(a,c[i]))
for i in range(0,int(len(c)*train_ratio)):
train_data = os.path.join(a, c[i])+'\t'+str(class_flag)+'\n'
train_list.append(train_data)
for i in range(int(len(c) * train_ratio),len(c)):
test_data = os.path.join(a, c[i]) + '\t' + str(class_flag)+'\n'
test_list.append(test_data)
class_flag += 1
print(train_list)
random.shuffle(train_list)#打乱次序
random.shuffle(test_list)
with open('train.txt','w',encoding='UTF-8') as f:
for train_img in train_list:
f.write(str(train_img))
with open('test.txt','w',encoding='UTF-8') as f:
for test_img in test_list:
f.write(test_img)
def CreateEvalData():
data_list = []
test_root = r"testdata"
for a, b, c in os.walk(test_root):
for i in range(len(c)):
data_list.append(os.path.join(a, c[i]))
print(data_list)
with open('eval.txt', 'w', encoding='UTF-8') as f:
for test_img in data_list:
f.write(test_img + '\t' + "0" + '\n')
if __name__ == "__main__":
CreateEvalData()
CreateTrainingSet()
2. 运行结果
可以看到产生了3个TXT文件。
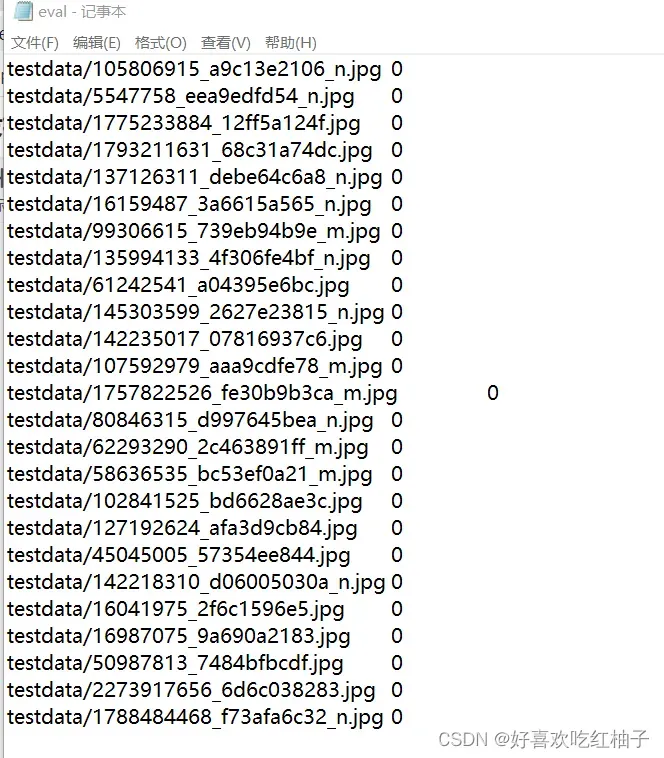
eval.txt文件中每一行由图片路径和0组成,在图片后面补一个0是为了和train.txt和test.txt前面是路径后面是标签的格式统一起来,后面方便统一提取TXT中的信息。
二、预训练模型 PreTrainedModel.py
1. 下载预训练权重文件
在对应网址中下载resnet34预训练参数,修改文件为resnet34_pretrain.pth,保存在项目文件中。

2. 使用迁移学习方法修改resnet34神经网络框架并加载预训练权重
- 我们使用的数据集是5个类别,全连接层FC层的输出应该是5,而我们自己搭建的resnet神经网络的fc层输出为1000(使用的类别数为1000的数据集进行训练),因此需要把fc层的输出改为5;
- 把resnet34的预训练权重文件的fc层参数删掉;
- 在自己搭建的网络中加载权重参数,更新网络中的权重;
- 冻结除了fc层的所有层,为单独训练fc层参数做准备;
- 使用损失函数和梯度下降算法训练fc层的参数;
具体细节可见笔记:pytorch进阶学习(五):神经网络迁移学习应用的保姆级详细介绍,如何将训练好的模型替换成自己所需模型_好喜欢吃红柚子的博客-CSDN博客
3. 模型优化
3.1 模型过程数据的保存与输出
设置epoch=50,在训练过程中:
- 在每一轮epoch中,训练过程中的损失值和测试过程中的准确率和平均损失都会被保存下来,记录在名为mobilenet_36_traindata.txt中进行保存;
- 每10个epoch都会把权重参数保存在resnet_epoch_xx_acc_xx.pth文件中,文件名中对应的epoch数和准确率;我们有50个epoch,所以会保存5个这样的文件,如resnet_epoch_10_acc_xx.pth、resnet_epoch_20_acc_xx.pth等;
- 如果如果一个epoch的acc比上一个要高,就保存一个BEST_resnet_epoch_xx_acc_xx.pth文件,记录当前最大的准确率。
# 一共训练50次
epochs = 50
best = 0.0
for t in range(epochs):
print(f"Epoch {t + 1}\n-------------------------------")
train_loss = train(train_dataloader, model, loss_fn, optimizer)
accuracy, avg_loss = test(test_dataloader, model)
# 记录训练过程值,写入mobilenet_36_traindata.txt文件进行保存
write_result("mobilenet_36_traindata.txt", t+1, train_loss, avg_loss, accuracy)
#10个 epoch保存一次resnet_epoch_xx_acc_xx.pth文件
if (t+1) % 10 == 0:
torch.save(model.state_dict(), "resnet_epoch_"+str(t+1)+"_acc_"+str(accuracy)+".pth")
# 如果一个epoch的acc比上一个要高,就保存一个BEST_resnet_epoch_xx_acc_xx.pth文件,记录当前最高的准确率
if float(accuracy) > best:
best = float(accuracy)
torch.save(model.state_dict(), "BEST_resnet_epoch_" + str(t+1) + "_acc_" + str(accuracy) + ".pth")3.2 训练过程
在train方法中我们会返回一批batchsize数据的平均loss。
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
avg_total = 0.0
# 从数据加载器中读取batch(一次读取多少张,即批次数),X(图片数据),y(图片真实标签)。
for batch, (X, y) in enumerate(dataloader):
# 将数据存到显卡
X, y = X.cuda(), y.cuda()
# 得到预测的结果pred
pred = model(X)
# 计算预测的误差
loss = loss_fn(pred, y)
avg_total = avg_total+loss.item()
# 反向传播,更新模型参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每训练10次,输出一次当前信息
if batch % 10 == 0:
loss, current = loss.item(), batch * len(X)
#这行代码的作用是在训练模型时输出当前的loss值和训练进度。
#其中,loss值会被格式化为浮点数,current表示当前已经训练的样本数,size表示总的样本数。
#输出的格式为"loss:(loss值][[current/{size]”。其中,“>“表示右对齐,数字表示输出的最小宽度。
print(f"loss: {loss:>5f} [{current:>5d}/{size:>5d}]")
# 定义平均损失
avg_loss = f"{(avg_total % batch_size):>5f}"
return avg_loss3.3 测试过程
test函数返回测试集数据的准确率和损失值
def test(dataloader, model):
size = len(dataloader.dataset)
# 将模型转为验证模式
model.eval()
# 初始化test_loss 和 correct, 用来统计每次的误差
test_loss, correct = 0, 0
# 测试时模型参数不用更新,所以no_gard()
# 非训练, 推理期用到
with torch.no_grad():
# 加载数据加载器,得到里面的X(图片数据)和y(真实标签)
for X, y in dataloader:
# 将数据转到GPU
X, y = X.cuda(), y.cuda()
# 将图片传入到模型当中就,得到预测的值pred
pred = model(X)
# 计算预测值pred和真实值y的差距
test_loss += loss_fn(pred, y).item()
# 统计预测正确的个数
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= size
correct /= size
accuracy = f"{(100*correct):>0.1f}"
avg_loss = f"{test_loss:>8f}"
print(f"correct = {correct}, Test Error: \n Accuracy: {accuracy}%, Avg loss: {avg_loss} \n")
# 增加数据写入功能
return accuracy, avg_loss3.4 运行结果
- epoch=50,需要耐心等待一会训练结束。 可以看到生成了BEST开头的参数文件,每一轮acc都在增加,可以看到准确率最高的一组epoch就是第50组,acc=87.1%,后面就可以选用这一组参数作为神经网络的权重来进行模型的验证。
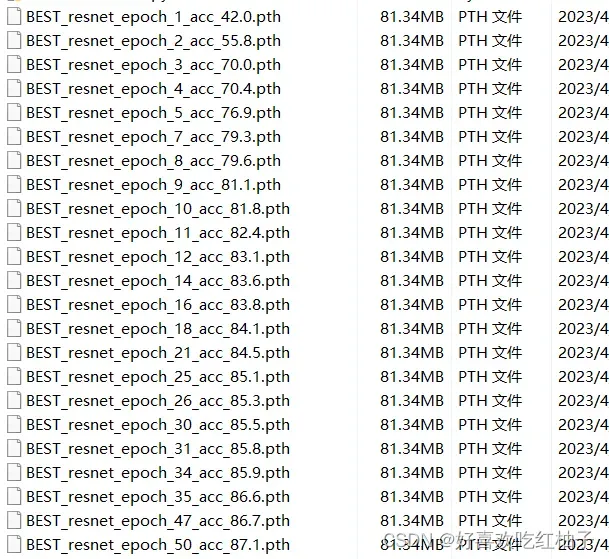
- 生成了第10/20/30/40/50的epoch权重文件
- 生成了mobilenet_36_traindata.txt,保存着训练过程中每一个epoch的训练信息。
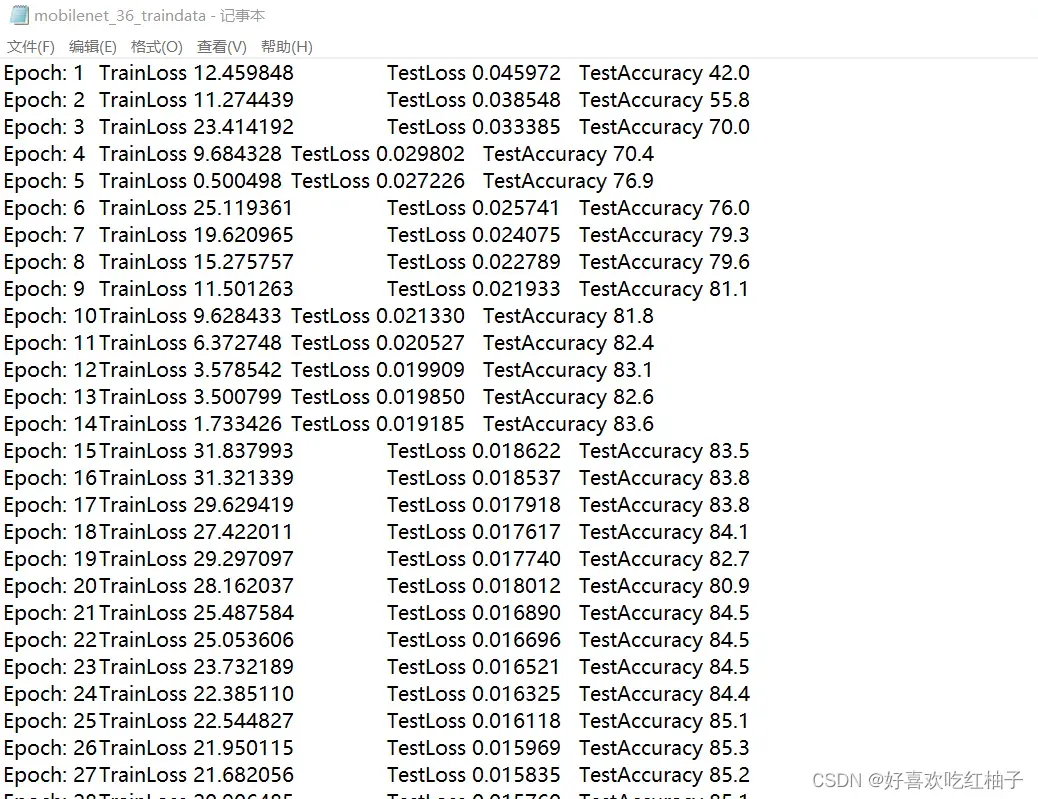
4. 代码
'''
纪录训练信息,包括:
1. train loss
2. test loss
3. test accuracy
'''
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision.models import resnet34
from utils import LoadData, write_result
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
avg_total = 0.0
# 从数据加载器中读取batch(一次读取多少张,即批次数),X(图片数据),y(图片真实标签)。
for batch, (X, y) in enumerate(dataloader):
# 将数据存到显卡
X, y = X.cuda(), y.cuda()
# 得到预测的结果pred
pred = model(X)
# 计算预测的误差
loss = loss_fn(pred, y)
avg_total = avg_total+loss.item()
# 反向传播,更新模型参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每训练10次,输出一次当前信息
if batch % 10 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>5f} [{current:>5d}/{size:>5d}]")
# 定义平均损失
avg_loss = f"{(avg_total % batch_size):>5f}"
return avg_loss
def test(dataloader, model):
size = len(dataloader.dataset)
# 将模型转为验证模式
model.eval()
# 初始化test_loss 和 correct, 用来统计每次的误差
test_loss, correct = 0, 0
# 测试时模型参数不用更新,所以no_gard()
# 非训练, 推理期用到
with torch.no_grad():
# 加载数据加载器,得到里面的X(图片数据)和y(真实标签)
for X, y in dataloader:
# 将数据转到GPU
X, y = X.cuda(), y.cuda()
# 将图片传入到模型当中就,得到预测的值pred
pred = model(X)
# 计算预测值pred和真实值y的差距
test_loss += loss_fn(pred, y).item()
# 统计预测正确的个数
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= size
correct /= size
accuracy = f"{(100*correct):>0.1f}"
avg_loss = f"{test_loss:>8f}"
print(f"correct = {correct}, Test Error: \n Accuracy: {accuracy}%, Avg loss: {avg_loss} \n")
# 增加数据写入功能
return accuracy, avg_loss
if __name__ == '__main__':
batch_size = 32
# # 给训练集和测试集分别创建一个数据集加载器
train_data = LoadData("train.txt", True)
valid_data = LoadData("test.txt", False)
train_dataloader = DataLoader(dataset=train_data, num_workers=4, pin_memory=True, batch_size=batch_size, shuffle=True)
test_dataloader = DataLoader(dataset=valid_data, num_workers=4, pin_memory=True, batch_size=batch_size)
# 如果显卡可用,则用显卡进行训练
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
'''
修改ResNet34模型的最后一层
'''
pretrain_model = resnet34(pretrained=False)
num_ftrs = pretrain_model.fc.in_features # 获取全连接层的输入
pretrain_model.fc = nn.Linear(num_ftrs, 5) # 全连接层改为不同的输出
# 预先训练好的参数, 'https://download.pytorch.org/models/resnet34-333f7ec4.pth'
pretrained_dict = torch.load('./resnet34_pretrain.pth')
# # 弹出fc层的参数
pretrained_dict.pop('fc.weight')
pretrained_dict.pop('fc.bias')
# # 自己的模型参数变量,在开始时里面参数处于初始状态,所以很多0和1
model_dict = pretrain_model.state_dict()
# # 去除一些不需要的参数
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
# # 模型参数列表进行参数更新,加载参数
model_dict.update(pretrained_dict)
# 改进过的预训练模型结构,加载刚刚的模型参数列表
pretrain_model.load_state_dict(model_dict)
'''
冻结部分层
'''
# 将满足条件的参数的 requires_grad 属性设置为False
for name, value in pretrain_model.named_parameters():
if (name != 'fc.weight') and (name != 'fc.bias'):
value.requires_grad = False
#
# filter 函数将模型中属性 requires_grad = True 的参数选出来
params_conv = filter(lambda p: p.requires_grad, pretrain_model.parameters()) # 要更新的参数在parms_conv当中
model = pretrain_model.to(device)
# 定义损失函数,计算相差多少,交叉熵,
loss_fn = nn.CrossEntropyLoss()
''' 控制优化器只更新需要更新的层 '''
optimizer = torch.optim.SGD(params_conv, lr=1e-3) # 初始学习率
#
# 一共训练50次
epochs = 50
best = 0.0
for t in range(epochs):
print(f"Epoch {t + 1}\n-------------------------------")
train_loss = train(train_dataloader, model, loss_fn, optimizer)
accuracy, avg_loss = test(test_dataloader, model)
# 记录训练过程值,写入mobilenet_36_traindata.txt文件进行保存
write_result("mobilenet_36_traindata.txt", t+1, train_loss, avg_loss, accuracy)
#10个 epoch保存一次resnet_epoch_xx_acc_xx.pth文件
if (t+1) % 10 == 0:
torch.save(model.state_dict(), "resnet_epoch_"+str(t+1)+"_acc_"+str(accuracy)+".pth")
# 如果一个epoch的acc比上一个要高,就保存一个BEST_resnet_epoch_xx_acc_xx.pth文件,记录当前最高的准确率
if float(accuracy) > best:
best = float(accuracy)
torch.save(model.state_dict(), "BEST_resnet_epoch_" + str(t+1) + "_acc_" + str(accuracy) + ".pth")
print("Train PyTorch Model Success!")三、模型验证
使用我们训练好的神经网络,对验证集中的图片进行数据验证。
1. 导入模型结构
定义我们修改过fc层输出的resnet34网络。
'''
1. 导入模型结构
'''
# 设置自己的模型
model = resnet34(pretrained=False)
num_ftrs = model.fc.in_features # 获取全连接层的输入
model.fc = nn.Linear(num_ftrs, 5) # 全连接层改为不同的输出
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")2. 加载模型参数
使用训练的准确率最高的一组参数的权重文件,我的名为”./BEST_resnet_epoch_50_acc_87.1.pth”,把参数加载到神经网络中,然后把模型转换到cuda中;
'''
2. 加载模型参数
'''
# 调用最好的acc的一组参数权重
model_loc = "./BEST_resnet_epoch_50_acc_87.1.pth"
model_dict = torch.load(model_loc)
model.load_state_dict(model_dict)
# 把模型转换到cuda中
model = model.to(device)3. 加载图片
使用LoadData和DataLoader加载验证集中的图片。
'''
3. 加载图片
'''
# 加载验证集中的图片
valid_data = LoadData("eval.txt", train_flag=False)
test_dataloader = DataLoader(dataset=valid_data, num_workers=2, pin_memory=True, batch_size=1)
4. 验证过程
把对验证数据集中每一张图片的预测标签和概率都存储在label_list,likelihood_list两个列表里
def eval(dataloader, model):
label_list = []
likelihood_list = []
model.eval()
with torch.no_grad():
# 加载数据加载器,得到里面的X(图片数据)和y(真实标签)
for X, y in dataloader:
# 将数据转到GPU
X = X.cuda()
# 将图片传入到模型当中就,得到预测的值pred
pred = model(X)
# 获取可能性最大的标签
label = torch.softmax(pred,1).cpu().numpy().argmax()
label_list.append(label)
# 获取可能性最大的值(即概率)
likelihood = torch.softmax(pred,1).cpu().numpy().max()
likelihood_list.append(likelihood)
return label_list,likelihood_list
5. 获取结果
把标签列表里的标签号转换为对应的类别文字,使用pandas进行列表的绘制,输出每一张图片的类别和概率,同时还可以把该表格保存在csv文件中。
'''
4. 获取结果
'''
#
label_list, likelihood_list = eval(test_dataloader, model)
label_names = ["daisy", "dandelion","rose","sunflower","tulip"]
result_names = [label_names[i] for i in label_list]
list = [result_names, likelihood_list]
df = pd.DataFrame(data=list)
df2 = pd.DataFrame(df.values.T, columns=["label", "likelihood"])
print(df2)
# 使用pandas把预测结果保存
df2.to_csv('testdata.csv', encoding='gbk')pycharm控制台输出的结果:

保存在testdata.csv文件中的预测表格:
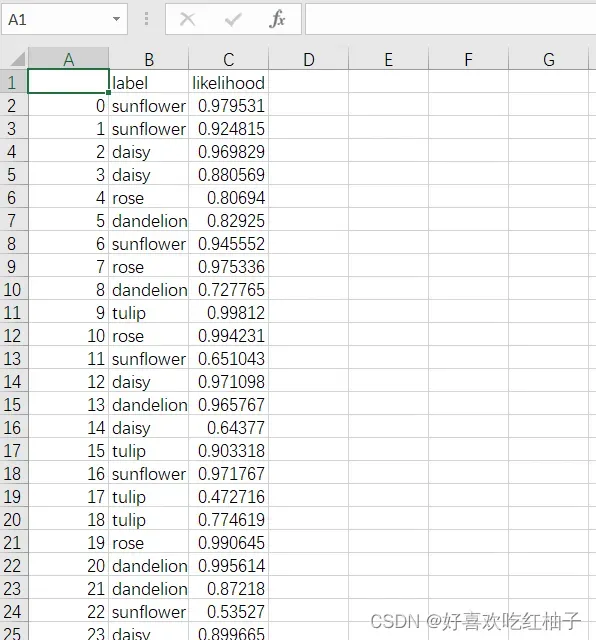
6. 完整代码
'''
1.单幅图片验证
2.多幅图片验证
'''
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision.models import resnet34
from utils import LoadData, write_result
import pandas as pd
def eval(dataloader, model):
label_list = []
likelihood_list = []
model.eval()
with torch.no_grad():
# 加载数据加载器,得到里面的X(图片数据)和y(真实标签)
for X, y in dataloader:
# 将数据转到GPU
X = X.cuda()
# 将图片传入到模型当中就,得到预测的值pred
pred = model(X)
# 获取可能性最大的标签
label = torch.softmax(pred,1).cpu().numpy().argmax()
label_list.append(label)
# 获取可能性最大的值(即概率)
likelihood = torch.softmax(pred,1).cpu().numpy().max()
likelihood_list.append(likelihood)
return label_list,likelihood_list
if __name__ == "__main__":
'''
1. 导入模型结构
'''
# 设置自己的模型
model = resnet34(pretrained=False)
num_ftrs = model.fc.in_features # 获取全连接层的输入
model.fc = nn.Linear(num_ftrs, 5) # 全连接层改为不同的输出
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
'''
2. 加载模型参数
'''
# 调用最好的acc的一组参数权重
model_loc = "./BEST_resnet_epoch_50_acc_87.1.pth"
model_dict = torch.load(model_loc)
model.load_state_dict(model_dict)
# 把模型转换到cuda中
model = model.to(device)
'''
3. 加载图片
'''
# 加载验证集中的图片
valid_data = LoadData("eval.txt", train_flag=False)
test_dataloader = DataLoader(dataset=valid_data, num_workers=2, pin_memory=True, batch_size=1)
'''
4. 获取结果
'''
#
label_list, likelihood_list = eval(test_dataloader, model)
label_names = ["daisy", "dandelion","rose","sunflower","tulip"]
result_names = [label_names[i] for i in label_list]
list = [result_names, likelihood_list]
df = pd.DataFrame(data=list)
df2 = pd.DataFrame(df.values.T, columns=["label", "likelihood"])
print(df2)
# 使用pandas把预测结果保存
df2.to_csv('testdata.csv', encoding='gbk')四、可视化
使用我们在前面训练过程中保存的mobilenet_36_traindata.txt文件,该文件中保存着训练过程中每一个epoch的准确率acc和损失函数TrainLoss,TestLoss和TestAccuracy
1. 代码
import matplotlib.pyplot as plt
import numpy as np
# 画图表
def getdata(data_loc):
epoch_list = []
train_loss_list = []
test_loss_list = []
acc_list = []
with open(data_loc, "r") as f:
for i in f.readlines():
data_i = i.split("\t")
epoch_i = float(data_i[0][7:])
train_loss_i = float(data_i[1][10:])
test_loss_i = float(data_i[2][9:])
acc_i = float(data_i[3][13:])
epoch_list.append(epoch_i)
train_loss_list.append(train_loss_i)
test_loss_list.append(test_loss_i)
acc_list.append(acc_i)
print(len(epoch_list), len(train_loss_list))
return epoch_list, train_loss_list, test_loss_list, acc_list
if __name__ == "__main__":
data_loc = r"mobilenet_36_traindata.txt"
epoch_list, train_loss_list, test_loss_list, acc_list = getdata(data_loc)
# #train_loss
# plt.plot(epoch_list, train_loss_list)
#
# plt.legend(["model"])
# plt.xticks(np.arange(0, 50, 5)) # 横坐标的值和步长
# plt.yticks(np.arange(0, 100, 10)) # 横坐标的值和步长
# plt.xlabel("Epoch")
# plt.ylabel("train_loss")
# plt.title("Train Loss")
# plt.show()
# 准确率曲线
# plt.plot(epoch_list, acc_list)
#
# plt.legend(["model"])
# plt.xticks(np.arange(0, 50, 5)) # 横坐标的值和步长
# plt.yticks(np.arange(0, 100, 10)) # 横坐标的值和步长
# plt.xlabel("Epoch")
# plt.ylabel("Accurancy(100%)")
# plt.title("Model Accuracy")
# plt.show()
# test_loss
plt.plot(epoch_list, test_loss_list)
plt.legend(["model"])
plt.xticks(np.arange(0, 50, 5)) # 横坐标的值和步长
plt.yticks(np.arange(0, 1, 10)) # 横坐标的值和步长
plt.xlabel("Epoch")
plt.ylabel("test_loss(100%)")
plt.title("Test Loss")
plt.show()2. 绘制图形
- 绘制出的准确率acc曲线:
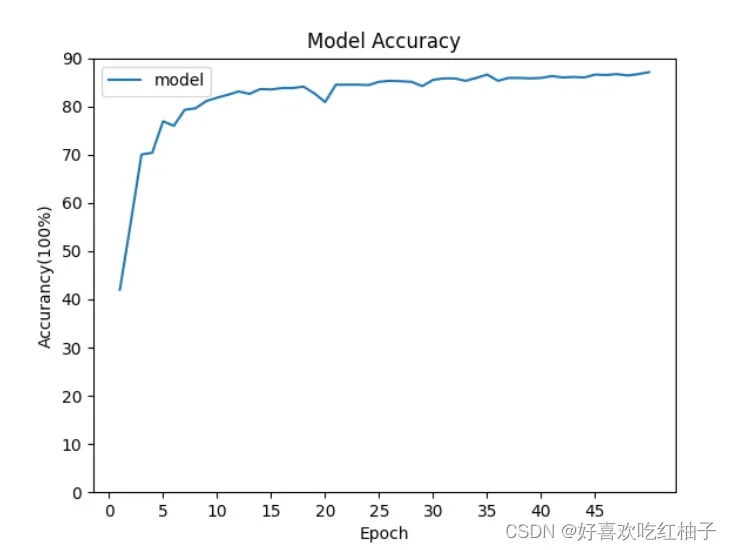
- 绘制出的train loss曲线:
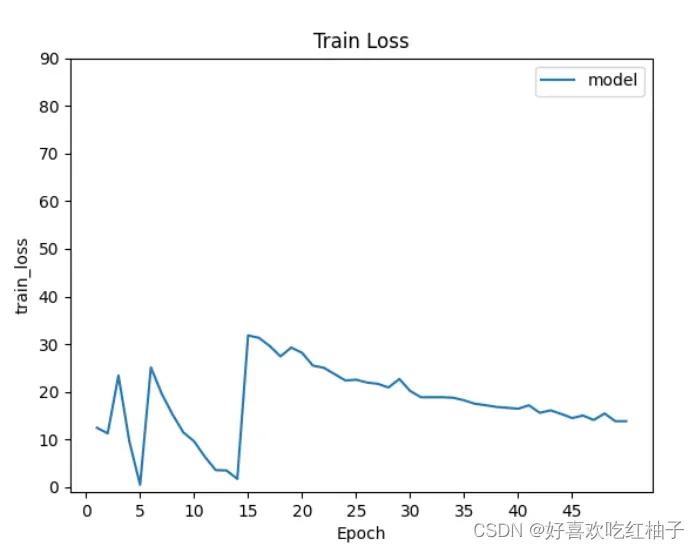
- 绘制出的test loss曲线:(纵坐标从0到1)
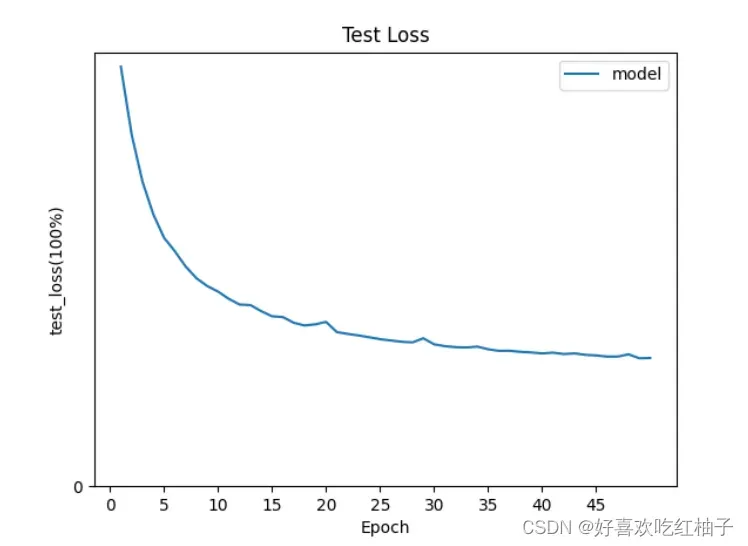
文章出处登录后可见!