效果演示:
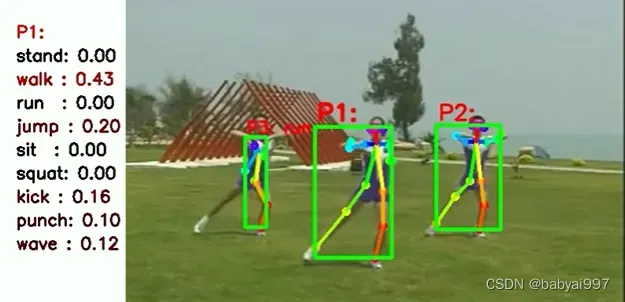
视频演示:
python行为识别行为骨骼框架检测动作识别动作检测行为动作分类
项目下载链接:https://download.csdn.net/download/babyai996/87552750
0环境项目配置教程:https://download.csdn.net/download/babyai996/87552768
一、背景技术
由于在人机交互、智能交通系统、视频监控等多个领域的巨大需求,人体的动作识别越来越受到计算机视觉领域的重视。为了能使计算机识别来自不同场景的动作,其核心是利用判别特征来表征动作,然后对其进行分类。与静态图像识别不同,除了空间运动特征外,还有更为重要的时间运动特征,那么,如何有效提取动作的空间运动特征和时间运动特征是人体动作识别要解决的两个主要问题。
传统的动作识别方法侧重于手工提取有效的时空特征,然后使用不同的分类器对特征进行分类。基于手工特征的动作识别方法的第一步是提取局部特征,在各种外观特征中,方向梯度直方图(HOG)因其对人体空间运动特征的高鲁棒性和高效性而被广泛研究。受HOG的启发,Laptev等人将HOG与光流相结合,设计了光流直方图(HOF)。此外,HOG还被扩展为HOG-3D来提取时空特征。Wang和Schmid提出融合了HOG、HOF和运动边界直方图(MotionBoundary Histograms,MBH)的密集轨迹算法(Dense Trajectories,DT)。在此基础上,又提出了改进的密集轨迹算法(ImprovedDense Trajectories,iDT),主要引进了对背景光流的消除方法,使得所提取的运动特征更集中于对人体动作的描述。同时,Harris-3D、Hessian-3D和3D-SIFT等都是常用的局部描述子。
随着CNNs在图像分类领域取得的巨大成功,人们尝试从原始图像通过多层的卷积层和池化层自动学习动作特征。与图像分类相比动作具有时间运动特征,用于动作识别的CNNs通常会比较复杂,大多数基于CNNs的动作识别方法按照两个步骤来实现:首先利用静态图像建立空间CNNs,然后在时间上将它们融合,这就导致动作之间的时间关系丢失,因此Ji等人设计了3D-CNNs架构,提出通过3D卷积核去提取视频数据的时间和空间特征,这些3D特征提取器在空间和时间维度上操作,因此可以捕捉视频流的运动信息,但是动作识别的准确率较低。
二、内容
本发明的目的是为解决传统动作识别方法存在的动作识别的准确率低的问题。
本发明为解决上述技术问题采取的技术方案是:
步骤一、选用InceptionV3为基础网络结构,建立空间通道卷积神经网络;
步骤二、迁移在ImageNet数据集上预训练好的InceptionV3基础网络结构模型的前10层参数至步骤一建立的空间通道卷积神经网络;将UCF101视频数据集切割为单帧静态图像,将切割好的单帧静态图像随机分成训练集和测试集数据,对空间通道卷积神经网络进行训练和测试;
步骤三、采集待识别视频序列,将待识别视频序列切割为每帧静态图像来作为训练集和测试集数据,对步骤二训练好的空间通道卷积神经网络的参数进行微调后,利用训练集和测试集的每帧静态图像对空间通道卷积神经网络进行训练和测试,输出待识别视频序列的每帧静态图像对应的各个类别的概率值P1,P2,…,PN;
步骤四、建立全局时域通道卷积神经网络,所述全局时域通道卷积神经网络仅在空间通道卷积神经网络的输入层之后增加一层卷积核尺寸为3×3的卷积层,其余的网络结构与空间通道卷积神经网络相同;
步骤五、利用步骤二训练集中每帧静态图像对应的能量运动历史图来训练步骤四建立的全局时域通道卷积神经网络;利用步骤二测试集中每帧静态图像对应的能量运动历史图来测试全局时域通道卷积神经网络;
步骤六、对步骤五训练好的全局时域通道卷积神经网络的参数进行微调后,利用步骤三训练集和测试集的每帧静态图像对应的能量运动历史图对全局时域通道卷积神经网络进行训练和测试,输出待识别视频序列每帧静态图像对应的能量运动历史图的各个类别的概率值P1′,P2′,…,PN′;
步骤七、在待识别视频序列中,分别将每帧静态图像对应的空间通道卷积神经网络输出与全局时域通道卷积神经网络输出融合,即计算出每帧静态图像的每个类别的概率平均值将概率平均值最大的类别作为每帧静态图像的动作识别结果。
本发明的有益效果是:本发明提供了一种融合全局时空特征的卷积神经网络人体动作识别方法,本发明建立空间通道卷积神经网络和全局时域通道卷积神经网络,利用UCF101视频数据集对建立的空间通道卷积神经网络和全局时域通道卷积神经网络进行训练和测试;将待识别视频序列的每帧静态图像输入训练好的空间通道卷积神经网络,对网络参数进行微调后,进行训练和测试,并输出待识别视频序列的每帧静态图像对应的各个类别的概率值;将待识别视频序列的每帧图像对应的能量运动历史图依次输入训练好的全局时域通道卷积神经网络进行训练和测试,并输出待识别视频序列每帧静态图像对应的能量运动历史图的各个类别的概率值;再将空间通道卷积神经网络和全局时域通道卷积神经网络的输出结果融合,得到待识别视频序列中每帧静态图像的动作识别结果;与传统的动作识别方法相比,本发明的动作识别方法的识别准确率可以提高至87%以上。
本发明融合了人体动作的空间和时间特征,对人体动作的识别起到很好的作用。
附图说明
图1为本发明所述的一种融合全局时空特征的卷积神经网络人体动作识别方法的流程图;
图2为本发明所述的空间通道多帧融合示意图;
图中表示3帧静态图像的输出融合;
图3为本发明所述的全局时域通道输入配置的示意图;
其中:299×299×1为输入层,299×299×3为经过卷积层后的结果。
三、具体实施方式
下面结合附图对本发明的技术方案作进一步的说明,但并不局限于此,凡是对本发明技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,均应涵盖在本发明的保护范围中。
具体实施方式一:结合图1说明本实施方式。本实施方式所述的一种融合全局时空特征的卷积神经网络人体动作识别方法,该方法的具体步骤为:
步骤一、选用InceptionV3为基础网络结构,建立空间通道卷积神经网络;
步骤二、迁移在ImageNet数据集上预训练好的InceptionV3基础网络结构模型的前10层参数至步骤一建立的空间通道卷积神经网络;将UCF101视频数据集切割为单帧静态图像,将切割好的单帧静态图像随机分成训练集和测试集数据,对空间通道卷积神经网络进行训练和测试;
步骤三、采集待识别视频序列,将待识别视频序列切割为每帧静态图像来作为训练集和测试集数据,对步骤二训练好的空间通道卷积神经网络的参数进行微调后,利用训练集和测试集的每帧静态图像对空间通道卷积神经网络进行训练和测试,输出待识别视频序列的每帧静态图像对应的各个类别的概率值P1,P2,…,PN;
步骤四、建立全局时域通道卷积神经网络,所述全局时域通道卷积神经网络仅在空间通道卷积神经网络的输入层之后增加一层卷积核尺寸为3×3的卷积层,其余的网络结构与空间通道卷积神经网络相同;
步骤五、利用步骤二训练集中每帧静态图像对应的能量运动历史图来训练步骤四建立的全局时域通道卷积神经网络;利用步骤二测试集中每帧静态图像对应的能量运动历史图来测试全局时域通道卷积神经网络;
步骤六、对步骤五训练好的全局时域通道卷积神经网络的参数进行微调后,利用步骤三训练集和测试集的每帧静态图像对应的能量运动历史图对全局时域通道卷积神经网络进行训练和测试,输出待识别视频序列每帧静态图像对应的能量运动历史图的各个类别的概率值P1′,P2′,…,PN′;
步骤七、在待识别视频序列中,分别将每帧静态图像对应的空间通道卷积神经网络输出与全局时域通道卷积神经网络输出融合,即计算出每帧静态图像的每个类别的概率平均值将概率平均值最大的类别作为每帧静态图像的动作识别结果。
本实施方式提出的一种融合全局时空特征的卷积神经网络,可以更好的提取动作的时空信息。
具体实施方式二:本实施方式对实施方式一所述的一种融合全局时空特征的卷积神经网络人体动作识别方法进行进一步的限定,本实施方式中步骤一具体过程为:
选用InceptionV3为基础网络结构,去掉基础网络结构最后的全连接层后,从前往后依次增加神经元个数为1024的全连接层、神经元个数为256的全连接层和神经元个数为N个动作类别的全连接层。
本实施方式中的神经元个数为1024的全连接层和神经元个数为256的全连接层的激活函数为relu,神经元个数为10个动作类别的全连接层的激活函数为softmax。
具体实施方式三:本实施方式对实施方式二所述的一种融合全局时空特征的卷积神经网络人体动作识别方法进行进一步的限定,本实施方式中的步骤二的的具体过程为:
迁移在ImageNet数据集上预训练好的InceptionV3基础网络结构模型的前10层的参数,即将模型的第1个卷积层到第3个Inception模块的参数迁移至步骤一建立的空间通道卷积神经网络,将UCF101视频数据集切割为尺寸299×299的标准输入单帧静态图像,将切割好的单帧静态图像随机分成训练集和测试集数据,将训练集中的静态图像依次输入空间通道卷积神经网络,采用Adam梯度下降法进行训练,mini-batch大小设置为32,参数采用Keras默认参数,若对测试集静态图像的识别准确率至少连续10次都未增加,则停止训练。
具体实施方式四:本实施方式对实施方式三所述的一种融合全局时空特征的卷积神经网络人体动作识别方法进行进一步的限定,本实施方式中的步骤三中采集摔倒动作数据集作为待识别视频序列,待识别视频序列包括摔倒、走路和坐下的动作,每个动作包含M个视频序列,将M个视频序列随机分为训练集和测试集,且每个视频序列切割为K帧静态图像;
对空间通道卷积神经网络的参数进行微调,即修改空间通道卷积神经网络最后一层的输出类别为3;
将训练集静态图像依次输入参数微调后的空间通道卷积神经网络,采用Adam梯度下降法训练最后一层全连接层,训练至少10次epoch后,采用随机梯度下降法训练最后两层全连接层,学习率设置为0.0001,Momentum设置为0.9,若对测试集静态图像的识别准确率至少连续10次都未增加,则停止训练;
在空间通道卷积神经网络中采用多帧融合的方式进行动作识别,将输入的当前帧静态图像和之前帧静态图像的输出取平均;输出待识别视频序列的每帧静态图像对应的3个类别的概率值P1,P2和P3。
本实施方式中,多帧融合的方式是指:若输入的当前帧静态图像为第n帧,输出的结果三个类别的概率分别为Pn 1,Pn 2和Pn 3,那么,取平均是指:Pn 1,Pn 2和Pn 3是当前帧单独的输出结果与前面n-1帧的输出结果取平均值。
因为动作是一个三维的时空信号,若空间通道只以当前帧的输出作为判别依据可能会出现较大误差,所以本实施方式在空间通道采用多帧融合的方式进行动作识别,对当前帧和之前固定帧数的识别结果加权平均。如图2所示,将当前帧与前2帧的输出融合,虽然当前帧的识别出现错误,但通过前2帧的矫正最终输出了正确的结果,提高了识别的准确率。
具体实施方式五:本实施方式对实施方式四所述的一种融合全局时空特征的卷积神经网络人体动作识别方法进行进一步的限定,本实施方式中的步骤五的具体过程为:
将步骤二训练集的单帧静态图像的能量运动历史图依次输入建立好的全局时域通道卷积神经网络,采用Adam梯度下降法来训练全局时域通道卷积神经网络,mini-batch大小设置为32,参数采用Keras默认参数,若测试集的动作识别准确率至少连续10次都未增加,则停止训练;
第t帧静态图像对应的能量运动历史图中的坐标为(x,y)的像素点的灰度值为Hτ(x,y,t),按照更新函数得到:
式中:(x,y)是第t帧静态图像对应的能量运动历史图中的像素点的位置,max代表取0和Hτ(x,y,t-1)-δ中较大的值,Hτ(x,y,t-1)是第t-1帧静态图像对应的能量运动历史图中的坐标为(x,y)的像素点的灰度值;τ为持续时间,δ为衰退参数;
ψ(x,y,t)为更新函数,判断各个像素点在当前帧是否为前景,若为前景则ψ(x,y,t)等于1,否则ψ(x,y,t)等于0;
ψ(x,y,t)通过帧间差分法得到:
D(x,y,t)=|I(x,y,t)-I(x,y,te)|
式中:I(x,y,t)是第t帧静态图像中位于(x,y)坐标的像素点的灰度值;I(x,y,te)是前一有效帧静态图像中位于(x,y)坐标的像素点的灰度值;ξ是用来判别前景和背景的阈值;D(x,y,t)是I(x,y,t)与I(x,y,te)的差的绝对值;
计算能量运动历史图的过程为:
若当前帧静态图像为有效帧,则更新一次能量运动历史图,否则不更新;
有效帧的判断原则是:设第一帧静态图像为有效帧,若当前帧静态图像相对于前一有效帧静态图像的运动能量大于阈值μ,则当前帧为有效帧;
定义Et为第t帧静态图像It相对于前一个有效帧静态图像Ite的运动能量:
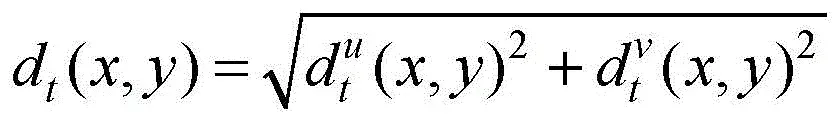
其中:C为第t帧静态图像相对于前一有效帧静态图像的有位移的像素点的个数;h和w分别是第t帧静态图像的宽度和高度;dt(x,y)是第t帧静态图像中像素点(x,y)相对于前一有效帧静态图像的位移;是第t帧静态图像与前一有效帧静态图像之间像素点(x,y)在水平方向的位移,是第t帧静态图像与前一有效帧静态图像之间像素点(x,y)在竖直方向的位移;
计算全局性的稠密光流:
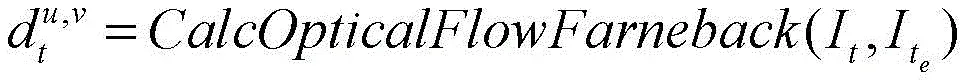
式中:
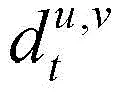
是第t帧静态图像与前一有效帧静态图像之间水平方向和竖直方向的光流;CalcOpticalFlowFarneback是光流函数。
EMHI是一种基于视觉的模板,通过计算一段时间内同一位置的像素变化,将人体动作用图像灰度值的形式表现出来。考虑到很多动作是跨越很多帧的,若利用每一帧来更新EMHI,则较早期的动作会失去作用,所以提出一种基于有效帧的方法来更新。
实质上是通过像素点的位移大小来判断是否为有效帧,但如果只是通过求图像内所有像素点的位移之和是不可行的。由于视角不同,运动的人物在图像中的比例是不同的,距离镜头近的人物做一个微小动作就可能得到很大的运动能量,所以通过除以有效像素的个数来消除视角的影响。
具体实施方式六:本实施方式对实施方式五所述的一种融合全局时空特征的卷积神经网络人体动作识别方法进行进一步的限定,本实施方式中的步骤六根据步骤三中采集的摔倒动作数据集,对全局时域通道卷积神经网络的参数进行微调,即修改全局时域通道卷积神经网络最后一层的输出类别为3;
将训练集中每帧静态图像对应的能量运动历史图依次输入参数微调后的全局时域通道卷积神经网络,采用Adam梯度下降法训练最后一层全连接层,至少训练10次epoch后,采用随机梯度下降法训练最后两层全连接层,学习率设置为0.0001,Momentum设置为0.9,若对测试集能量运动历史图的识别准确率至少连续10次都未增加,则停止训练;输出待识别视频序列每帧静态图像对应的能量运动历史图的3个类别的概率值P1′,P2′和P3′。
具体实施方式七:本实施方式对实施方式六所述的一种融合全局时空特征的卷积神经网络人体动作识别方法进行进一步的限定,本实施方式计算出所述摔倒动作数据集的每帧静态图像的每个类别的概率平均值
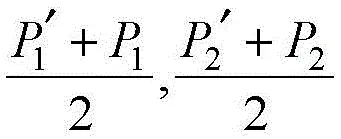
和将概率平均值最大的类别作为每帧静态图像的动作识别结果。
四、实施
本文选用UCF101数据库对识别效果进行判定,UCF101数据库包含101种动作的13320段视频,动作的场景复杂。随后将训练好的网络迁移至本文项目中的小样本数据集。
本发明设计的是双通道CNNs,空间通道卷积神经网络和全局时域通道卷积神经网络的基础网络结构均采用Inception V3基础网络结构,空间通道卷积神经网络的输入为单帧静态图像,全局时域通道卷积神经网络的输入为单帧图像的运动能量历史图(EMHI),采用两个通道单独训练的方法,最后将两个通道输出的结果进行融合,来识别人体动作。
在UCF101空间通道数据集上训练至较高的识别率后迁移至小样本数据集进行微调,测试集选用每个视频序列中连续30帧进行评估.同时,为了对多帧融合算法的有效性进行探究,在空间卷积通道分别采用3帧融合、5帧融合和10帧融合的方式。
测试结果如表1所示,在UCF101数据集,空间通道识别准确率为70.2%,利用多帧融合的方式将准确率分别提升到70.9%、71.3%和71.5%。在本发明的小样本数据集上表现更好,空间通道识别准确率为73.4%,利用多帧融合的方式将准确率分别提升到74.7%、74.9%和75.1%。小样本数据集只有3类动作,动作类别远少于UCF101数据集,所以误差更小。而通过多帧融合的方式确实能提高识别准确率,减小误差,证明了多帧融合方法的有效性。
表1空间通道平均识别率
利用视频数据集分别计算MHI和EMHI作为全局时域通道训练数据集,在UCF101全局时域通道数据集上训练至较高的识别率后迁移至小样本数据集进行微调,测试方法与空间通道相同,分别比较MHI和EMHI的识别效果。由于我们的全局时域通道的输入是单通道的灰度图,而时域通道的输入是RGB图。如图3所示,本发明在输入层之后多加一层卷积层,卷积核的数量为3,边界处采取补0的方法,这样就满足了时域通道的输入层结构。
测试结果如表2所示,在UCF101数据集,利用MHI的动作识别准确率为75.8%,EMHI的动作识别率为78.3%。在小样本数据集上MHI的动作识别准确率为78.4%,EMHI的动作识别率为80.2%。总体来看,EMHI的动作识别准确率要高于MHI,验证了本发明提出的EMHI在动作识别中的有效性。
表2全局时域通道平均识别率
将空间通道卷积网络与全局时域通道卷积网络的识别结果融合,测试方法相同。测试结果如表3所示,在UCF101数据集的平均识别率为85.2%,在小样本数据集的平均识别率为87.2%。可知,空间通道和全局时域通道的深度特征学习能力彼此间互补。
表3双通道平均识别率
本发明提出一种基于空间和全局时域特征的双通道卷积神经网络人体动作识别框架,能够对人体动作信息进行很好地深度特征提取。其中空间通道采用多帧融合的方式进行识别,实验结果表明该方法能有效提高空间通道的识别准确率;全局时域通道采用本发明提出的基于运动能量的具有自适应能力的EMHI,相比较于传统的MHI能够更加有效的提取全局动作时域特征。双通道采取平均融合的方式对动作综合识别,实验结果表明两个通道彼此互补,提高了动作识别的精度。此外本文提出的利用大型动作数据集进行预训练,迁移至小样本数据集表现出更好的识别精度,验证了该方法的有效性。
项目下载链接:https://download.csdn.net/download/babyai996/87552750
0环境项目配置教程:https://download.csdn.net/download/babyai996/87552768
文章出处登录后可见!