目录
一、概要
BART(Bidirectional and Auto-Regressive Transformers)模型使用标准的基于Transformer的序列到序列结构,主要区别在于用GeLU(Gaussian Error Linerar Units)激活函数替换了原始结构中的 ReLU,以及参数根据正态分布进行初始化。BART 结合双向的 Transformer 编码器与单向的自回归Transformer解码器,通过对含有噪声的输入文本去噪重构进行预训练,是一种典型的去噪自编码器(Denoising autoencoder)。BART模型的基本结构如下图所示。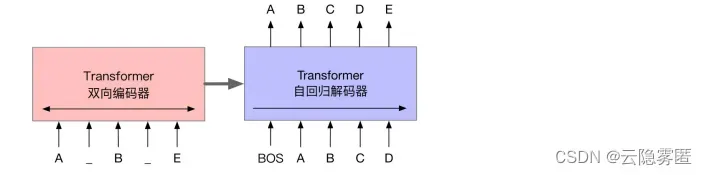 BART的预训练过程可以概括为以下两个阶段。首先,在输入文本中引入噪声,并使用双向编码器编码扰乱后的文本;然后,使用单向的自回归解码器重构原始文本。需要注意的是,编码器的最后一层隐含层表示会作为“记忆”参与解码器每一层的计算。BART模型考虑了多种不同的噪声引入方式,其中包括BERT模型使用的单词掩码。需要注意的是,BERT模型是独立地预测掩码位置的词,而BART模型是通过自回归的方式顺序地生成。
除此之外,BART模型也适用于任意其他形式的文本噪声。
BART的预训练过程可以概括为以下两个阶段。首先,在输入文本中引入噪声,并使用双向编码器编码扰乱后的文本;然后,使用单向的自回归解码器重构原始文本。需要注意的是,编码器的最后一层隐含层表示会作为“记忆”参与解码器每一层的计算。BART模型考虑了多种不同的噪声引入方式,其中包括BERT模型使用的单词掩码。需要注意的是,BERT模型是独立地预测掩码位置的词,而BART模型是通过自回归的方式顺序地生成。
除此之外,BART模型也适用于任意其他形式的文本噪声。二、深入扩展
2.1 预训练任务
BART模型考虑了以下五种噪声引入方式: (1)单词掩码。与BERT模型类似,在输入文本中随机采样一部分单词,并替换为掩码标记(如[MASK]); (2)单词删除。随机采样一部分单词并删除。要处理这类噪声,模型不仅需要预测缺失的单词,还需要确定缺失单词的位置; (3)句子排列变换。根据句号将输入文本分为多个句子,并将句子的顺序随机打乱。为了恢复句子的顺序,模型需要对整段输入文本的语义具备一定的理解能力; (4)文档旋转变换。随机选择输入文本中的一个单词,并旋转文档,使其以该单词作为开始。为了重构原始文本,模型需要从扰乱文本中找到原始文本的开头; (5)文本填充。随机采样多个文本片段,片段长度根据泊松分布(λ=3)进行采样得到。用单个掩码标记替换每个文本片段。当片段长度为0时,意味着插入一个掩码标记。要去除这类噪声,要求模型具有预测缺失文本片段长度的能力。下图对这五类噪声进行了概括: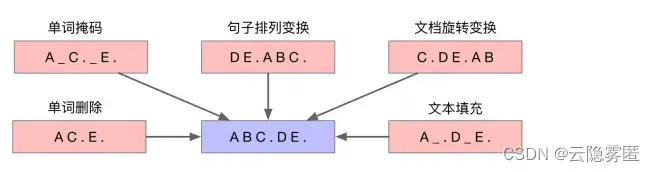
from transformers import BartTokenizer, BartForConditionalGeneration
model = BartForConditionalGeneration.from_pretrained('facebook/bart-base')
tokenizer = BartTokenizer.from_pretrained("facebook/bart-base")
input = "UN Chief Says There Is <mask> in Syria"
batch = tokenizer(input, return_tensors = 'pt')
output_ids = model.generate(input_ids=batch['input_ids'], attention_mask = batch['attention_mask'])
output = tokenizer.batch_decode(output_ids, skip_special_tokens = True)
print(output)
# 输出:['UN Chief Says There Is No War in Syria']2.2 模型精调
预训练的BART模型同时具备文本的表示与生成能力,因此适用于语言理解、文本生成等不同类型的下游任务。对于不同的任务,BART模型的精调方式有所不同。(1)序列分类与序列标注。对于序列分类任务(如文本情感分类),BART模型的编码器与解码器使用相同的输入,将解码器最终时刻的隐含层状态作为输入文本的向量表示,并输入至多类别线性分类器中,再利用该任务的标注数据精调模型参数。与BERT模型的 [CLS] 标记类似,BART模型在解码器的最后时刻额外添加一个特殊标记,并以该标记的隐含层状态作为文本的表示,从而能够利用完整的解码器状态。同样地,对于序列标注任务,编码器与解码器也是使用相同的输入。此时,解码器各个时刻的隐含层状态将作为该时刻单词的向量表示用于类别预测。 (2)文本生成。BART模型可以直接用于条件式文本生成任务,例如抽象式问答(Abstractive question answering)以及文本摘要 (Abstractive summarization)等。在这些任务中,编码器的输入是作为条件的输入文本,解码器则以自回归的方式生成对应的目标文本。 (3)机器翻译。当用于机器翻译任务时,由于源语言与目标语言使用不同的词汇集合,无法直接精调BART模型。因此,研究人员提出将BART模型编码器的输入表示层(Embedding layer)替换为一个小型 Transformer 编码器,用来将源语言中的词汇映射至目标语言的输入表示空间,从而适配BART模型的预训练环境(见图8-25)。由于新引入的源语言编码器参数是随机初始化的,而BART模型大部分的其他参数经过了预训练,使用同一个优化器对两者同时进行训练会出现“步调不一 致”的情况,可能无法取得很好的效果。因此,研究人员将训练过程分为两步。首先,固定 BART模型的大部分参数,只对源语言编码器、BART 模型位置向量和BART预训练编码器第一层的自注意力输入投射矩阵进行训练;然后,对所有的参数进行少量迭代训练。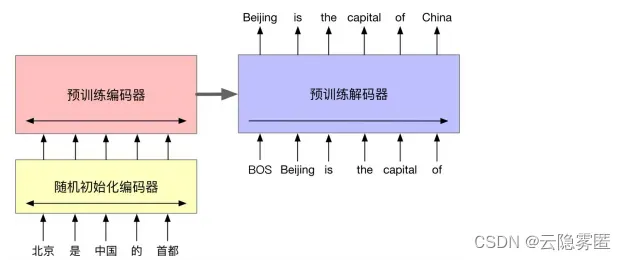
文章出处登录后可见!
已经登录?立即刷新