今年的数学建模题目出来了,爆肝的日子到来了,作为考生的我带着C题走来了。
首先针对C题第一问的第一部分,做正事之前肯定要先进行准备了,这里需要先进行指标量化。本着由简入深的原则,首先,借用相关系数聊表对本题的敬意,图示如下:
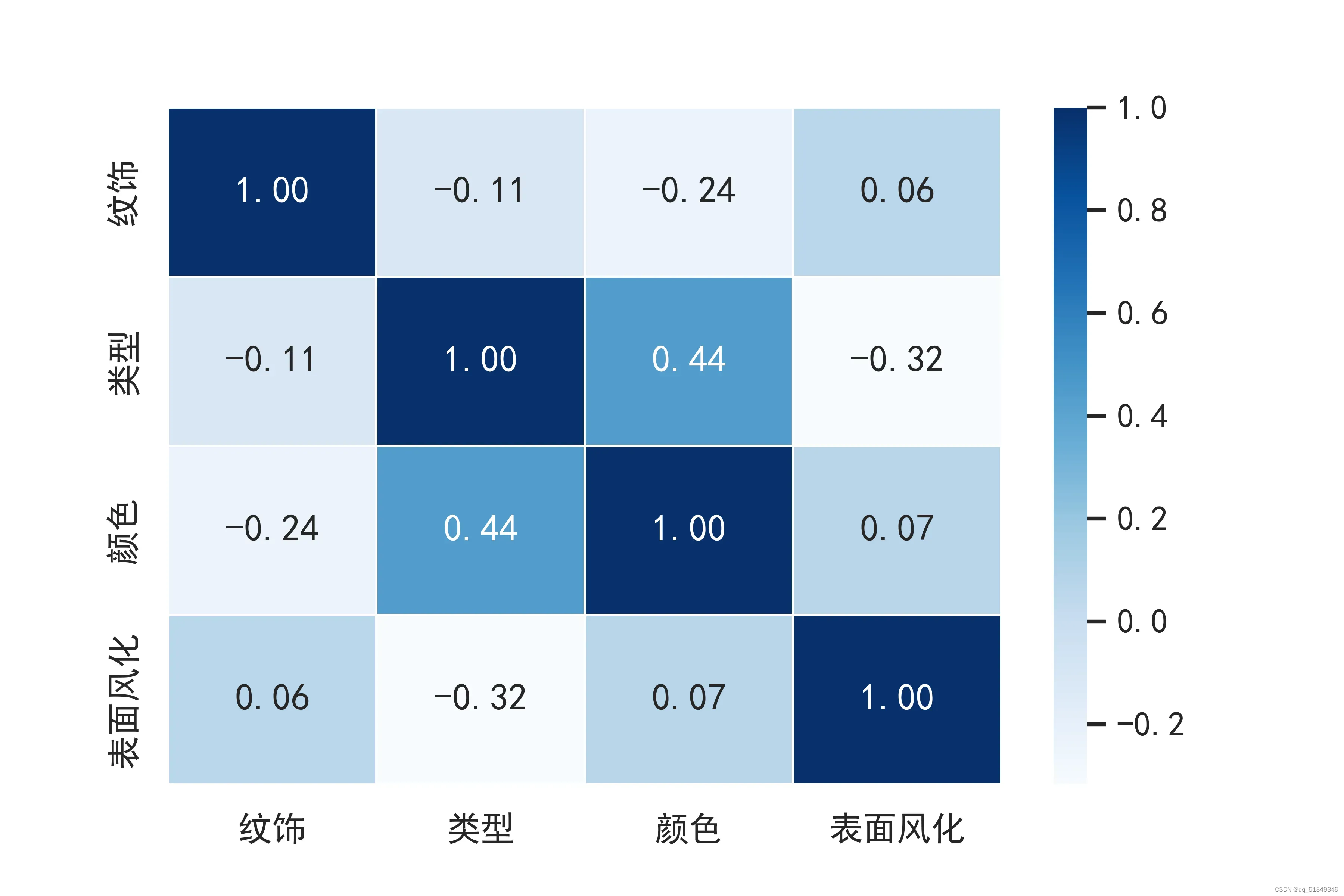
奈何相关系数不给力,吃个闭门羹。没办法的我只能用上土方法,采用描述性统计分析,上图进贡,但为了效果,所以当然应该先把缺失数据剔除单独分析了。下面依次展示在不同指标下文物风化计数,在不同指标下文物无风化计数,当然里面的数字都是我们的分类指标量化结果啦。

通过统计观察,即可得出统计规律。诸如在xx条件下最容易风化,xx条件下不容易风化等结论,为后续分析打下基础。当然为了整的明明白白,填充颜色代表类型,蓝色代表颜色是铅钡,橙色高钾,小伙伴们要看仔细哦。
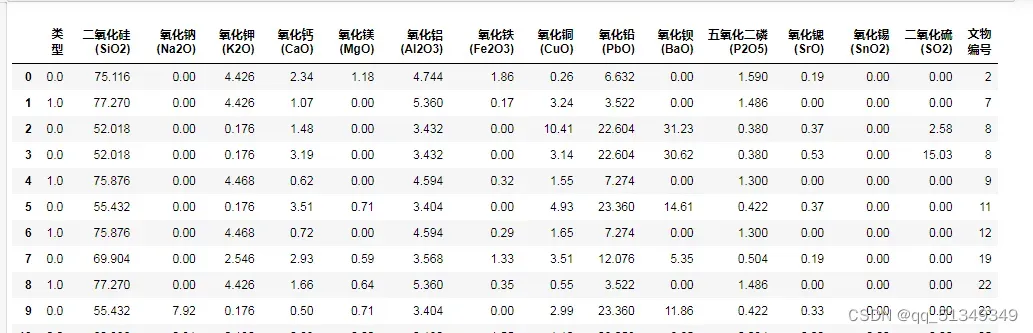
接着统计分析后,表单1个属性间关系就显而易见了,接着完成第一题第二部分。显然要将表单1,2合并才能解决难题。但是表单二里面存在无效数据,需要先进行剔除,为了寻找到不同类型玻璃风化的一线之隔,我们选择画箱线图观察指标分布判断。下面依次展现高钾与铅钡分化前后不同组分占比大小的箱线图。
通过箱线图选择数据分布风化前后数据分布差异最大的指标即是区分是否风化的关键指标,适当选择分化前后同一指标极值与中值作为该指标区分节点即可完成是否风化的判别,于是这一部分也就迎刃而解了。
至于第一题第三部分,颗粒理解为训练模型插补。利用未风化数据训练模型对已风化数据化学成分插补,即可预测得到风化前可能的各成分占比。模型选择因人而异,但是结果可以借鉴参考
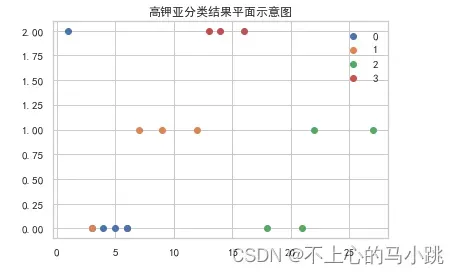
由于精力有限,目前也就这样了,后期也没时间了。但是关于后2问小有看法。针对第二问,可以比较不同类型的玻璃在分化前后化学成分含量显著不同变量作为区分标准,类似第一问。关于亚分类,可以选择变量运用决策树算法,其上的节点即代表划分方式。至于敏感性,可以参考灵敏度分析,通过决策树也可一目了然。
第三问,纯粹的预测项目,选择数据,训练分类模型,简简单单。但还是推荐树模型,因为这样解决敏感性时,树群一画,轻松明了。
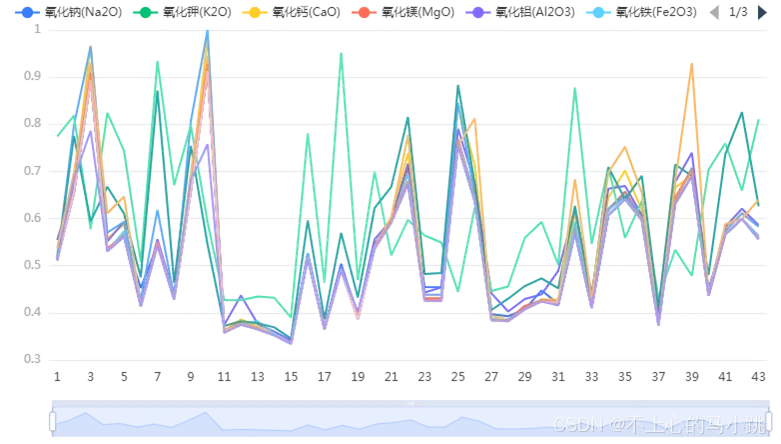
第四问,可以搞个不同成分的近似比,借助灰色关联分析,也可较好完成。关系系数图可用作参考。
文章出处登录后可见!