目的:在谷歌的的colab上基于disco diffusion模型实现输入文本输出相应图片的功能
1、disco diffusion托管在谷歌的colab上,登录对应网址如下:
https://colab.research.google.com/github/alembics/disco-diffusion/blob/main/Disco_Diffusion.ipynb
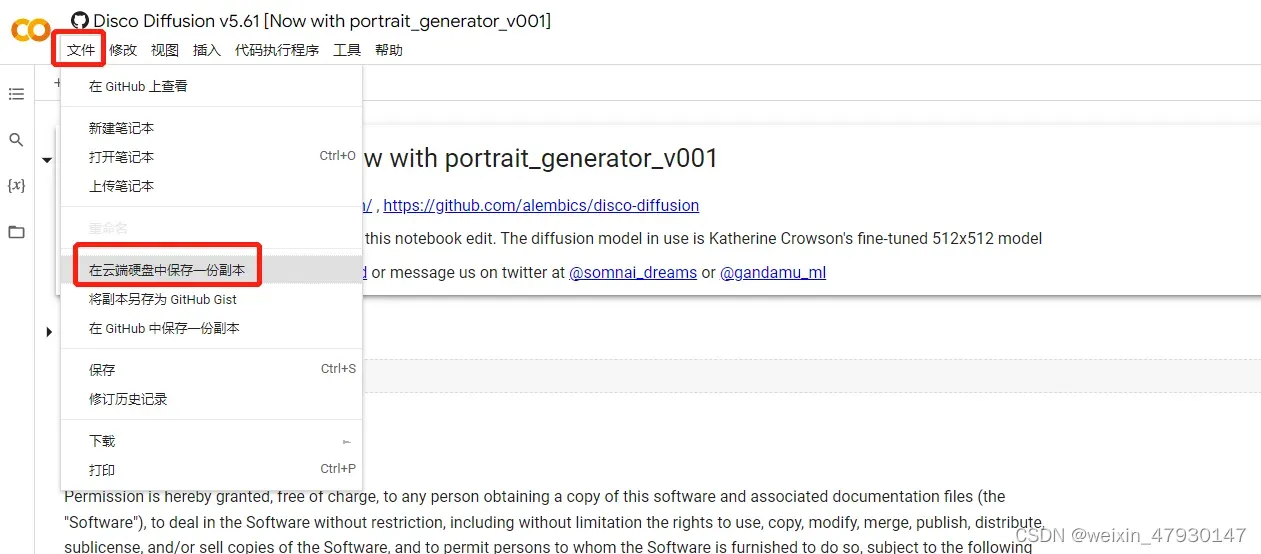
2、保存副本文件
进入页面后,要先在云端硬盘中保存一份副本,在副本上进行接下来的操作。
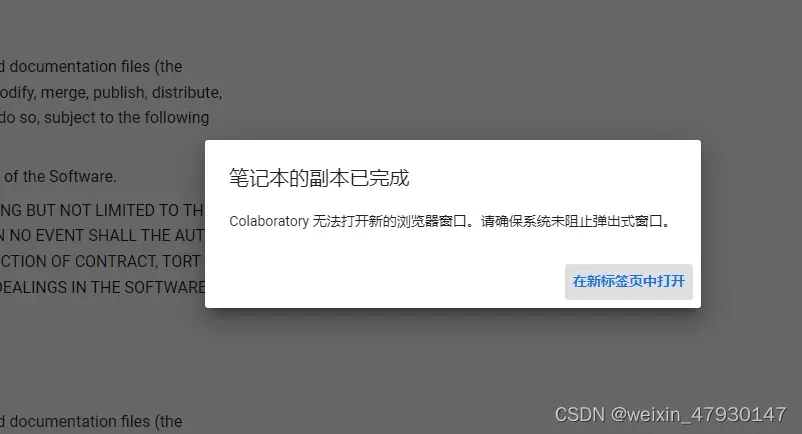
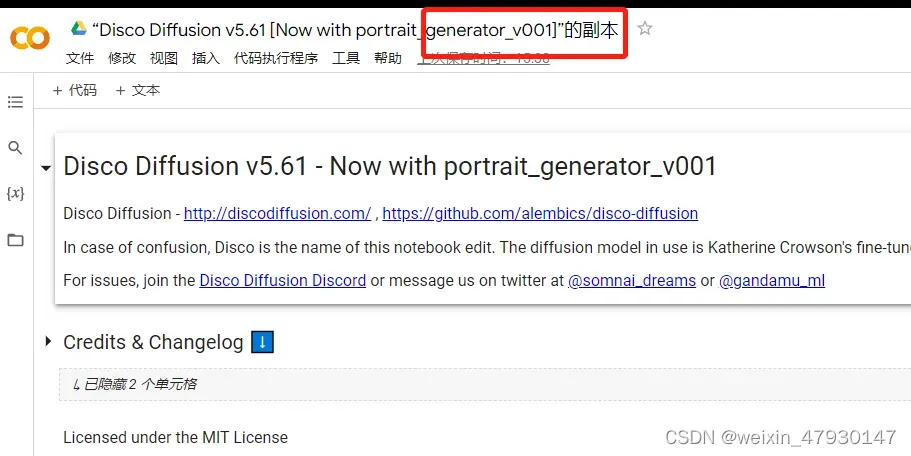
点击“在新标签页中打开”后进入副本页面
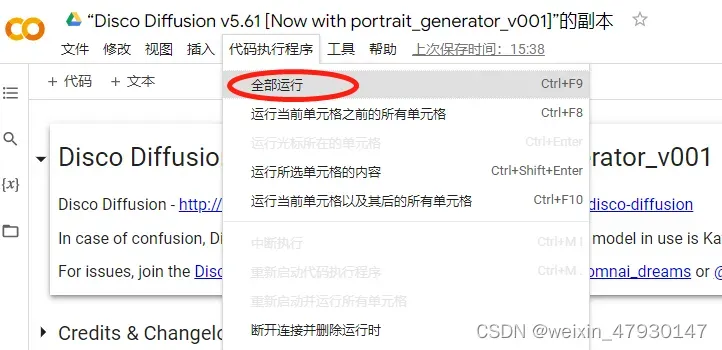
点击确定:

点击“连接到google云端硬盘”
使用谷歌账户登录谷歌云盘
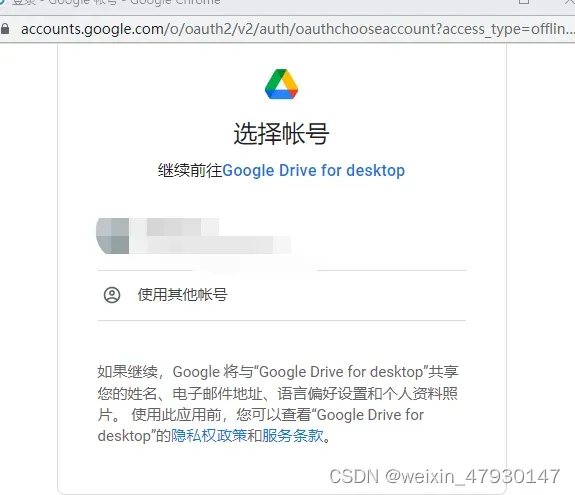
3、输入文本,输出图片
在第三部分的setting中,找到prompt模块,其中text_prompts 中输入文本,
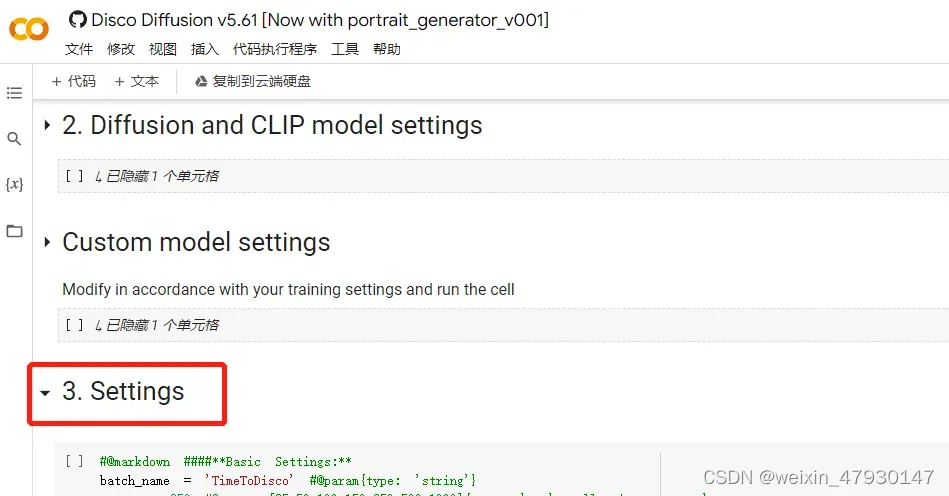

将第四部分中的n_batches设置为1,这样生成的图片就只有一张,
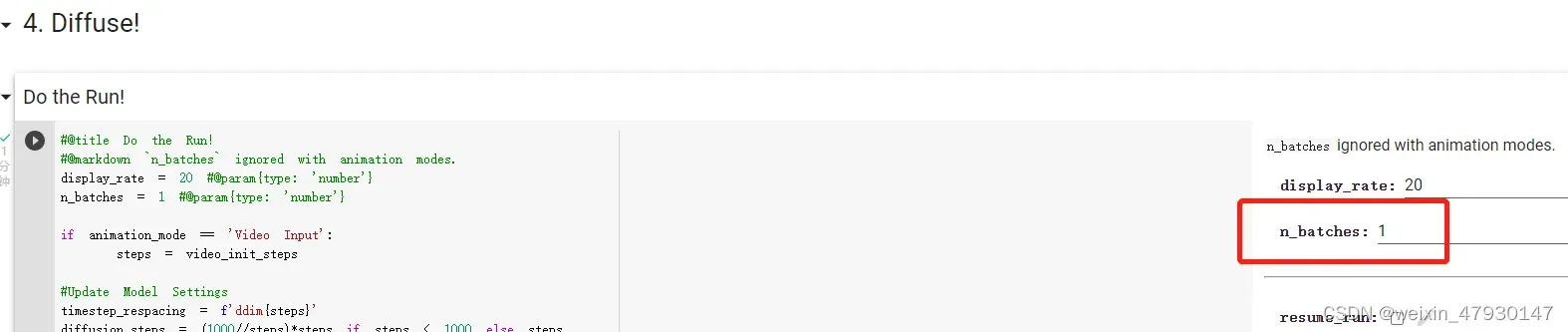
点击全部运行,开始作图
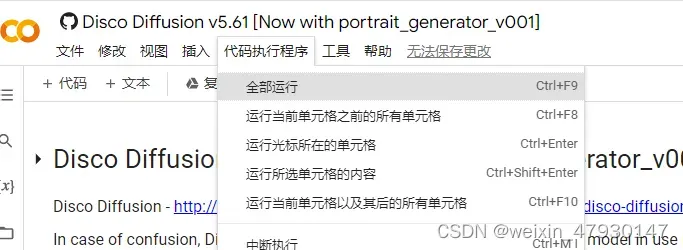
在diffusion模块中 可以看到图片渲染的进度
渲染五分钟后: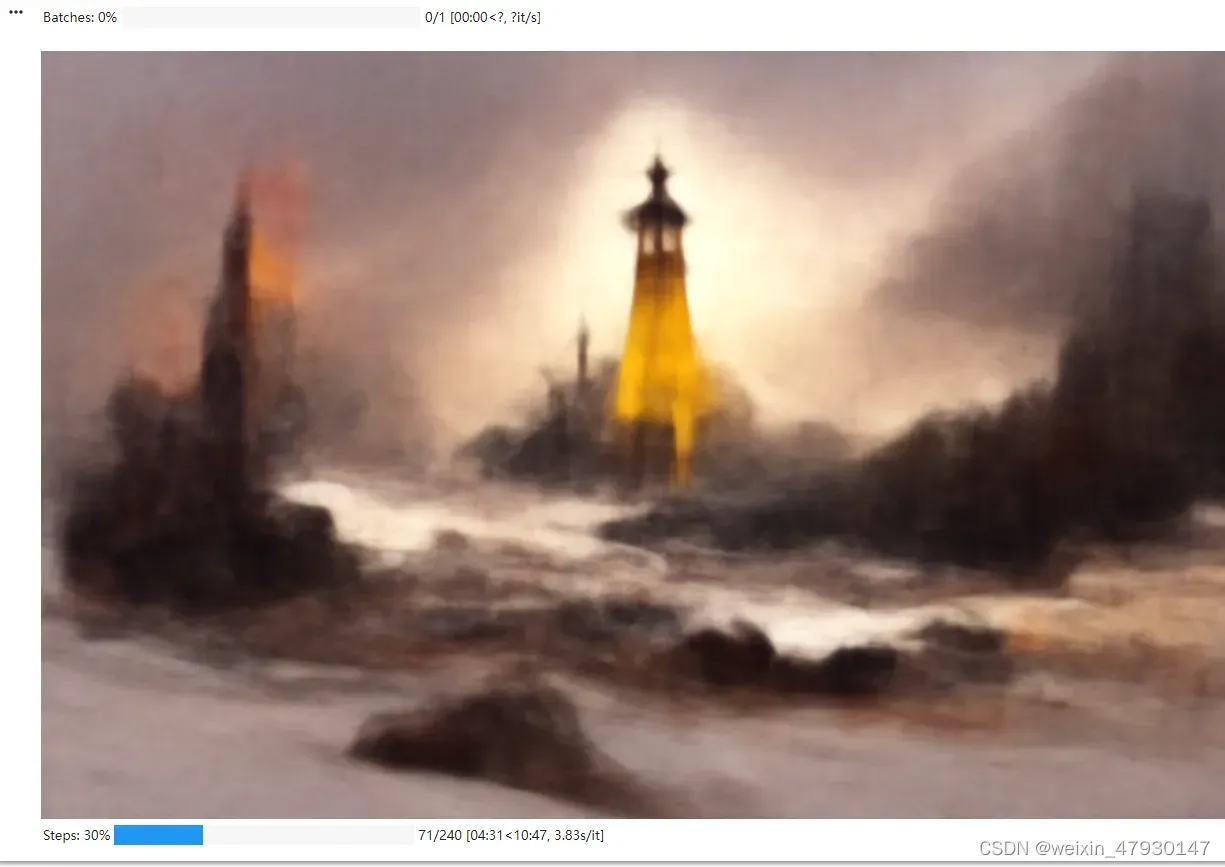
4、常用参数
disco diffusion模型中还有诸多参数可以设置,作者整理了主要参数的含义及取值范围,如下表
| 序号 | 分类 | 字段 | 描述 | 取值 |
| 1 | 提示 | text_prompts | 对你希望机器生成的内容进行描述 | |
| 2 | image_prompts | 可以设置一些参考图片,以对其内容的更多描述(可选) | ||
| 3 | 基本设置 | batch_nam | 该次创作图像的文件和文件夹名称 | |
| 4 | steps | 在创建一个图像时,去噪过程被细分为处理的步骤, | 50-10000,默认250,一般来说超过500步的时候,实际上的改善就不是特别明显了 | |
| 5 | width_height | 所需的最终图像大小,以像素为单位 | 默认为[1280,768] 受显卡内存限制。每个边缘长度应设置为 64 像素的倍数,并且在默认 CLIP 模型设置上至少为 512 像素 | |
| 6 | clip_guidance_scale | 用于指示最终图像和描述文本(prompt)的相似度,是非常重要的参数之一。一般来说越高越好,但如果太大的话,它也会过度接近目标并扭曲图像 | 默认5000,可选范围1500-100000 | |
| 7 | tv_scale | 总噪声方差,控制最终输出的 “平滑度”。如果使用,tv_scale将尝试平滑你的最终图像,以减少整体噪声 | 默认为0,可选参数,范围为0-1000,设置为0即可关闭。 | |
| 8 | range_scale: | 用于调整颜色的对比度。较低的range_scale会增加对比度。非常低的值会产生更多鲜艳的或类似海报的图像。较高的range_scale会降低对比度,使图像更加柔和。 | 默认150,可选参数,范围0-1000,0即关闭。 | |
| 9 | sat_scale | 过饱和调整。如果使用, sat_scale将有助于减轻过饱和度,如果你的图像过于饱和,可以增加 sat_scale来降低饱和度。 | 可选参数,默认设置为0,即关闭,范围0-20000 | |
| 10 | cutn_batches | 每次迭代,AI 将图像切割为一个个小的图像块,称之为切片。并将每个切片与“提示”进行比较,以决定如何指导下一个扩散步骤。更多的切片通常可以产生更好的图像,因为 DD 在每个时间步有更多的机会微调图像精度。 | 1-8,默认为4 | |
| 11 | skip_augs | DD 采用了“torchvision 增强”,在图像创建过程中引入随机图像缩放、透视和其他选择性调整。这些增强原本是想帮助提高图像质量,但可能对边缘产生您不想要的“平滑”效果。 | 默认为否 | |
| 12 | init_image | 可选参数,作为AI生成图像的参考图像,也是起点图像,如果保持默认值(None),那么生成的结果就是一开始我们看到的噪声图像。 | 用户上传 | |
| 13 | init_scale | 这控制了CLIP在多大程度上会试图匹配提供的init_image。这与上面的 clip_guidance_scale相互平衡。较大的值时,图像就不会在扩散过程中变化很大。而太多的clip_guidance_scale,初始图像可能会被丢失。 | 默认值1000,可选范围10-20000, | |
| 14 | skip_steps | 去噪的前几个步骤往往是非常戏剧性的,有些步骤 (可能占总数的10-15%) 可以被跳过而不而不影响最终的图像。但与此同时,这项值过大意味着跳过了太多的步骤,剩下的噪声可能不够产生新的内容,因此可能没有 “剩余时间 “来完成一幅满意的图像。 | 必须可以整除steps,默认值10。如果有init_image,则需要跳过大约50%的steps来保证和init_image的相似 | |
| 15 | Models Settings | diffusion_model | 提供9种可选的扩散模型 | |
| 16 | use_secondary_model | 是否选用次级模型 | 默认为是 | |
| 17 | CLIP settings | 提供9种可选的clip模型 | VITB32、RN50等 | |
| 18 | OpenCLIP settings | 提供13种可选的OpenCLIP模型 | ||
| 19 | 切割安排 | cut_overview | 切割,设置越高,细节就越细节 | [12]*400+[4]*600 |
| 20 | cut_innercut | 切割,值越大,主体越小,一般用来控制图片的视距 | [4]*400+[12]*600 | |
| 21 | cut_ic_pow | 画面精细程度,值越大,画面越精美清晰 | [1]*1000,取值范围0.5-100(方括号内) | |
| 22 | 高级设置 | perlin_init | 通常情况下,程序会使用一个充满随机噪声的图像作为扩散曲线的起点。如果选择了 perlin_init,程序将使用一个 Perlin 噪声模型作为初始状态。 | |
| 23 | perlin_mode | 设置 Perlin 噪声的类型:彩色、灰色或两者的混合,给你额外的噪声类型选择。 | ||
| 24 | set_seed | 在扩散代码的深处,有一个随机数“种子”,它被用来作为确定扩散初始状态的基础。默认情况下,它是随机的,但你也可以指定你自己的种子。 | ||
| 25 | eta | 是一个扩散模型变量,它在每个时间步长中混入随机量的比例噪声。0 是没有噪音,1.0 是更多的噪音。你可以把 eta 值调到 0 以下,但可能会给你带来不可预测的结果。 | 0-1,默认值是 0.8, | |
| 26 | clamp_grad | clamp_grad 是一个内部限制器可以阻止程序产生极端的结果。如果在关闭 clamp_grad 的情况下,图像发生了巨大的变化,这可能意味着你的 clip_guidance_scale 太高,应该降低。 | 默认开启 | |
| 27 | clamp_max | 为图像提供更平滑、更柔和的色彩,但设置更高的值 (0.15 – 0.3) 可以提供有趣的对比度和鲜度。 | 0-0.3,默认值是 0.05, | |
| 28 | 运行设置 | n_batches | 此变量设置您希望 DD 创建的静止图像的数量。 | 1-100,默认50 |
| 29 | display_rate | 在DD运行期间,您可以使用此变量监控正在创建的每个图像的进度。如果 display_rate 设置为 50,DD 将在每 50 个迭代完成时显示一次进行中的图像。 | 5-500,默认50 | |
| 30 | resume_run | 如果您的运行被中断(例如您自己终止了进程,或者因为断开连接),您可以使用此复选框从中断的地方恢复您的批处理运行。但是,您不得更改批处理中的设置,否则无法可靠地恢复。 |
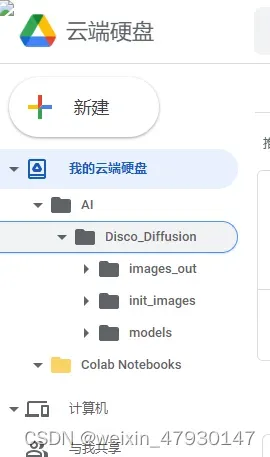
4、查看和下载生成的图片
在谷歌云端硬盘的AI文件夹下的Disco_Diffusion下的images_out文件夹中存放了生成的图片。
文章出处登录后可见!
已经登录?立即刷新