文章目录
一、任务简介
Visual grounding涉及计算机视觉和自然语言处理两个模态。
简要来说,输入是图片(image)和对应的物体描述(sentence\caption\description),输出是描述物体的box。
听上去和目标检测非常类似,区别在于输入多了语言信息,在对物体进行定位时,要先对语言模态的输入进行理解,并且和视觉模态的信息进行融合,最后利用得到的特征表示进行定位预测。
Visual grounding按照是否要对语言描述中所有提及的物体进行定位,可以进一步划分为两个任务:
- Phrase Localization
- Referring Expression Comprehension(REC)
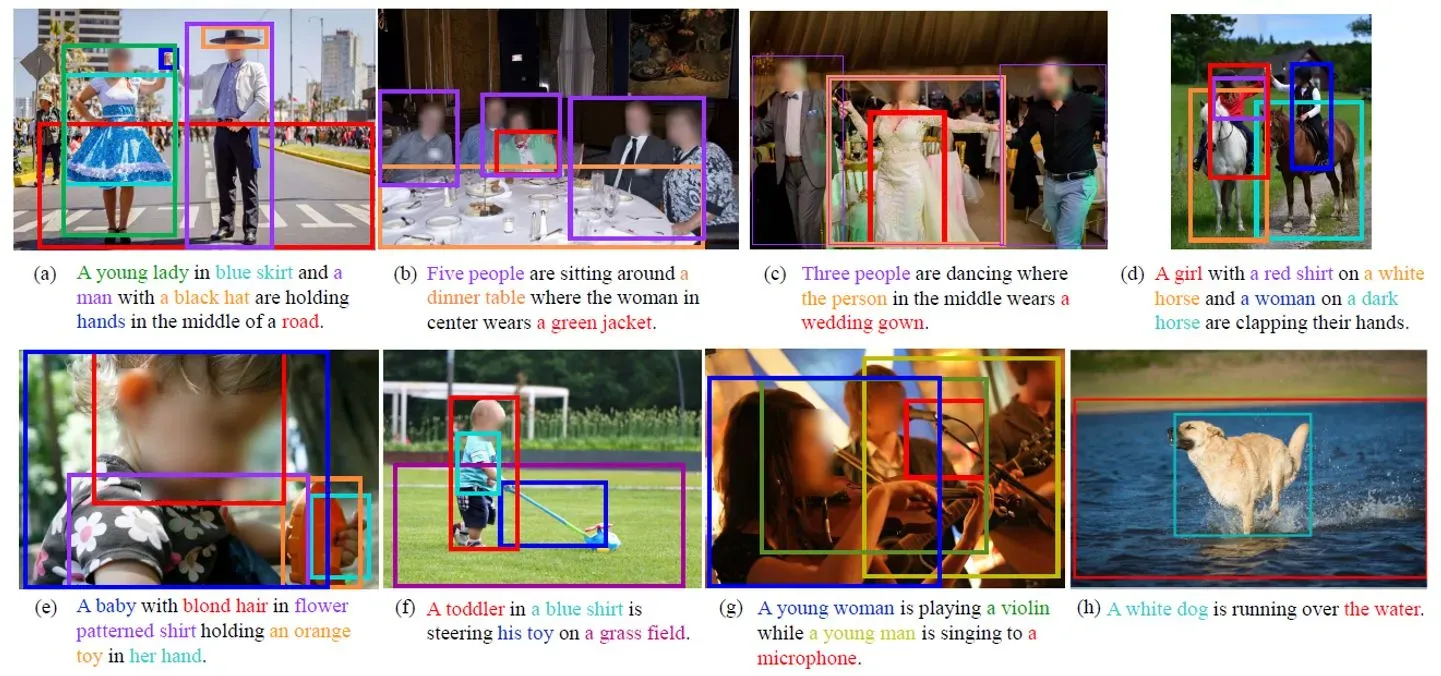
Phrase Localization又称为Phrase Grounding,如上图,对于给定的sentence,要定位其中提到的全部物体(phrase),在数据集中对于所有的phrase都有box标注。

Referring Expression Comprehension也称为Referring expression grounding。见上图,每个语言描述(这里是expression)只指示一个物体,每句话即使有上下文物体,也只对应一个指示物体的box标注。
二、Visual grounding常用数据集与评估指标
2.1 常用数据集
- Phrase Localization
常用的数据集即Flickr30k Entities数据集,包含31783张image,每张图会对应5个不同的caption,所以总共158915个caption,以及244035个phrase-box标注。对于每个phrase还细分为people, clothing, body parts, animals, vehicles, instruments, scene, othera八个不同的类别。
另外很多phrase localization的工作还会在ReferItGame数据集(又称RefCLEF)上进行实验,这个数据集严格来说应该属于REC任务。图片来自ImageCLEF数据集,包含130525个expression,涉及238个不同的物体种类,有96654个物体,19894张图像。其中的数据是通过一种称为refer it game的双人游戏进行标注的,如下图:
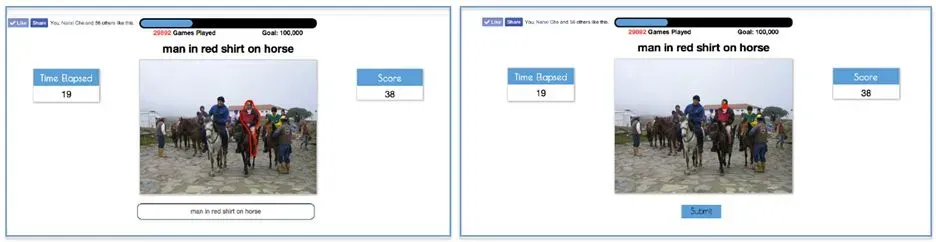
左侧的人根据region来写expression,右侧的人根据expression选择region。
- Referring expression comprehension
常用的有三个数据集RefCOCO, RefCOCO+, RefCOCOg。这三个数据集的区别可以通过下面的样例理解:

2.2 评估指标
- prediction box和groud-truth box的交并比(intersection over
union,IoU)大于0.5记为一次正确定位,以此来计算准确率(Accuracy)
最近的一些工作使用Recall@k指标,表示预测概率前k大的prediction box和ground-truth box的IoU大于0.5的定位准确率。
- Pointing game,选择最终预测的attention mask中权重最大的像素位置,如果该点落在ground-truth区域内,记为一次正确定位。相比Acc指标更加宽松
三、Visual grounding主流做法
目前Visual grounding可以分为全监督(Fully-supervised)、弱监督(Weakly-supervised)、无监督(Unsupervised)三种。
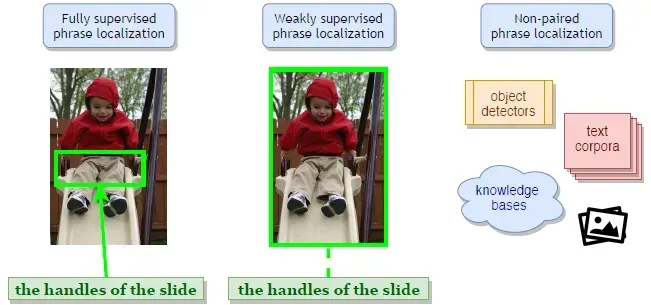
- 全监督(Fully-supervised):顾名思义,就是有object-phrase的box标注信息
- 弱监督(Weakly-supervised):输入只有image和对应的sentence,没有sentence中的object-phrase的box标注
- 无监督(Unsupervised):image-sentence的信息都没有。目前据我所知,只有ICCV2019的WPT[5]是无监督,非常有意思,结果也很有比较价值
全监督中,现在的做法可以分为two-stage和one-stage两种做法。
two-stage就是第一个阶段先通过RPN或者传统的算法(Edgebox、SelectiveSearch)等提取候选的proposals以及它们的features,然后在第二个阶段进行详细的推理,例如常见的做法是把视觉特征和语言特征投射到一个公共的向量空间,计算相似度,选择最相近的proposal作为预测结果。
one-stage则是基于目标检测领域的one-stage模型,例如YOLO、RetinaNet等。
弱监督由于缺少phrase和box之间的mapping,会额外设计很多损失函数,例如基于reconstruction,引入external knowledge,基于image-caption匹配设计loss的等等。
文章出处登录后可见!