分类目录:《人工智能与大数据面试指南》总目录
《人工智能与大数据面试指南》系列下的内容会持续更新,有需要的读者可以收藏文章,以及时获取文章的最新内容。
随机梯度下降(Stochastic Gradient Descent, SGD)
随机梯度下降(Stochastic Gradient Descent, SGD)在第
个训练迭代的更新
输入:学习率;初始化参数
或第
次输出参数
输出:第
(1) while
(2)从训练集中采包含
个样本
的小批量,其中
对应目标为
(3)
(4)
(5)
(6) return
在实践中,有必要随着时间的推移逐渐降低学习率,因此我们将第步迭代的学习率记作
。这是因为SGD中梯度估计引入的噪声源(
个训练样本的随机采样)并不会在极小点处消失。相比之下,当我们使用批量梯度下降到达极小点时,整个代价函数的真实梯度会变得很小,之后为0,因此批量梯度下降可以使用固定的学习率。保证SGD收敛的一个充分条件是:
实践中,一般会线性衰减学习率直到第次迭代:
在步迭代之后,一般使
保持常数。使用线性策略时,需要选择的参数为
、
和
。通常
被设为需要反复遍历训练集几百次的迭代次数。通常
应设为大约
的1%。主要问题是如何设置
。若
太大,学习曲线将会剧烈振荡,代价函数值通常会明显增加。温和的振荡是良好的,容易在训练随机代价函数(例如使用Dropout的代价函数)时出现。如果学习率太小,那么学习过程会很缓慢。如果初始学习率太低,那么学习可能会卡在一个相当高的代价值。通常,就总训练时间和最终代价值而言,最优初始学习率的效果会好于大约迭代100次后最佳的效果。因此,通常最好是检测最早的几轮迭代,选择一个比在效果上表现最佳的学习率更大的学习率,但又不能太大导致严重的震荡。
参考文章:《随机梯度下降(Stochastic Gradient Descent, SGD)》
Momentum
Momentum旨在加速学习,特别是处理高曲率、小但一致的梯度,或是带噪声的梯度。Momentum 积累了之前梯度指数级衰减的移动平均,并且继续沿该方向移动。Momentum的效果如下图所示所示:
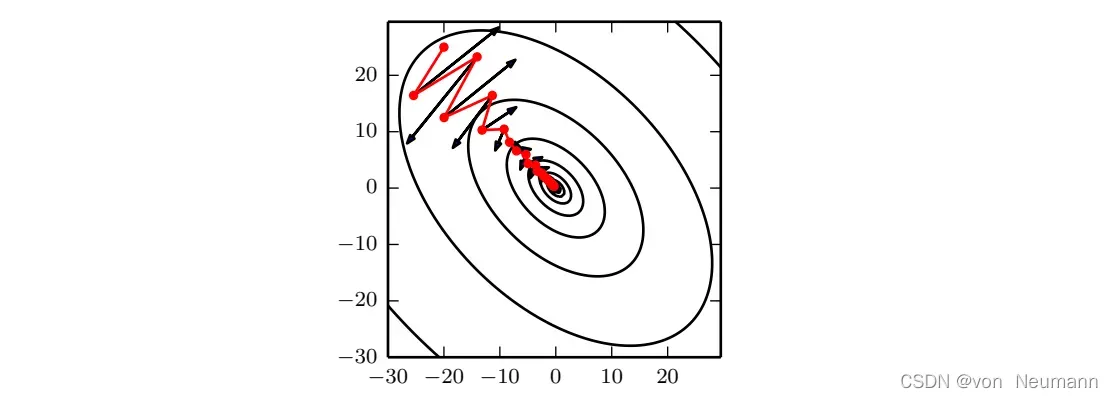
从形式上看,Momentum引入了变量充当速度角色——它代表参数在参数空间移动的方向和速率。速度被设为负梯度的指数衰减平均。名称Momentum来自物理类比,根据牛顿运动定律,负梯度是移动参数空间中粒子的力。动量在物理学上定义为质量乘以速度。在Momentum中,我们假设是单位质量,因此速度向量
也可以看作粒子的动量。超参数
决定了之前梯度的贡献衰减得有多快。更新规则如下:
速度累积了梯度元素
。相对于
,
越大,之前梯度对现在方向的影响也越大。
Momentum(Gradient Descent with Momentum, GDM)第
输入:学习率;初始化参数
;动量参数
;第
输出:第
(1) while
(2)
(3)
(4)
(5)
(6)
(7) return
之前,步长只是梯度范数乘以学习率。现在,步长取决于梯度序列的大小和排列。当许多连续的梯度指向相同的方向时,步长最大。如果Momentum总是观测到梯度,那么它会在方向
上不停加速,直到达到最终速度,其中步长大小为:
因此将Momentum的超参数视为有助于理解。例如,
对应着最大速度10倍于梯度下降算法。在实践中,
的一般取值为0.5、0.9和0.99。和学习率一样,
也会随着时间不断调整。一般初始值是一个较小的值,随后会慢慢变大。随着时间推移调整
没有收缩
重要。根据上面所述,我们就可以看到,在梯度下降的过程中,来回震荡的方向就会由于历史梯度而被抵消,真正需要迅速下降的方向就会被加强。
参考文章:《Momentum(Gradient Descent with Momentum, GDM)》
Nesterov Momentum
受Nesterov Accelerated Gradient算法的启发,Sutskever提出了动量算法的一个变种。这种情况的更新规则如下:
其中参数和
发挥了和标准动量方法中类似的作用。Nesterov动量和标准动量之间的区别体现在梯度计算上。Nesterov动量中,梯度计算在施加当前速度之后。因此,Nesterov动量可以解释为往标准动量方法中添加了一个校正因子。
Nesterov Momentum第
输入:学习率
输出:第
(1) while
(2)
(3)
(4)
(5)
(6)
(7) return
在凸批量梯度的情况下,Nesterov Momentum将额外误差收敛率从(k步后)改进到
。可惜,在随机梯度的情况下,Nesterov Momentum没有改进收敛率。
参考文章:《Nesterov Momentum》
AdaGrad
AdaGrad算法独立地适应所有模型参数的学习率,缩放每个参数反比于其所有梯度历史平方值总和的平方根。具有损失最大偏导的参数相应地有一个快速下降的学习率,而具有小偏导的参数在学习率上有相对较小的下降。净效果是在参数空间中更为平缓的倾斜方向会取得更大的进步。
在凸优化背景中,AdaGrad算法具有一些令人满意的理论性质。然而,经验上已经发现,对于训练深度神经网络模型而言,从训练开始时积累梯度平方会导致有效学习率过早和过量的减小。其是想就是对于每个参数,初始化一个变量为0,然后每次将该参数的梯度平方求和累加到这个变量
上,然后在更新这个参数的时候,学习率就变为
,这里的
是为了数值稳定性而加上的,因为有可能
的值为0。AdaGrad在某些深度学习模型上效果不错,但不是全部。
AdaGrad算法
输入:全局学习率;小常数
(为了数值稳定大约设为
;)
输出:神经网络参数
(1) 初始化梯度累积变量
(2) while
(1)
(2)
(3)
(4)
(5) return
参考文章:《AdaGrad》
RMSProp
RMSProp算法修改AdaGrad以在非凸设定下效果更好,改变梯度积累为指数加权的移动平均。AdaGrad旨在应用于凸问题时快速收敛。当应用于非凸函数训练神经网络时,学习轨迹可能穿过了很多不同的结构,最终到达一个局部凸的区域。AdaGrad根据平方梯度的整个历史收缩学习率,可能使得学习率在达到这样的凸结构前就变得太小了。RMSProp使用指数衰减平均以丢弃遥远过去的历史,使其能够在找到凸碗状结构后快速收敛,它就像一个初始化于该碗状结构的AdaGrad算法实例。相比于AdaGrad,使用移动平均引入了一个新的超参数,用来控制移动平均的长度范围。
RMSProp算法
输入:全局学习率;初始参数
;
输出:神经网络参数
(1) 初始化梯度累积变量
(2) while
(1)
(2)
(3)
(4)
(5) return
以及使用Nesterov Momentum的RMSProp算法:
使用Nesterov Momentum的RMSProp算法
输入:全局学习率
输出:神经网络参数
(1) 初始化梯度累积变量
(2) while
(1)
(2)
(3)
(4)
(4)
(5) return
经验上,RMSProp已被证明是一种有效且实用的深度神经网络优化算法。目前它是深度学习从业者经常采用的优化方法之一。
参考文章:《RMSProp》
Adam
Adam是另一种学习率自适应的优化算法:
Adam算法
输入:步长(建议默认为:
);初始参数
;
输出:神经网络参数
(1) 初始化一阶和二阶矩变量
(2) 初始化时间步
(3) while
(4)
(5)
(6)
(7)
(8)
(9)
(10)
(11)
(12) return
“Adam”这个名字派生自短语“Adaptive Moments”。早期算法背景下,它也许最好被看作结合RMSProp和具有一些重要区别的Momentum的变种。首先,在Adam中,Momentum直接并入了梯度一阶矩(指数加权)的估计。将Momentum加入RMSProp最直观的方法是将Momentum应用于缩放后的梯度。结合缩放的Momentum使用没有明确的理论动机。其次,Adam包括偏置修正,修正从原点初始化的一阶矩(Momentum项)和(非中心的)二阶矩的估计。RMSProp也采用了(非中心的)二阶矩估计,然而缺失了修正因子。因此,不像Adam, RMSProp二阶矩估计可能在训练初期有很高的偏置。Adam通常被认为对超参数的选择相当鲁棒,尽管学习率有时需要从建议的默认修改。
文章出处登录后可见!