提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
简介
药物分子发挥效用的根本途径就是通过与相关靶标发生结合来激活相应的下游反应,而分子对接指的就是利用计算的方式去模拟两个分子之间的识别和结合的过程,也因此在早期的药物发现中发挥重要作用。
目前的分子对接算法也主要可以分为如下两类:
- 基于搜索的分子对接算法
这类型的算法是目前的主流,代表性的算法包括Glide,Autodock等。主题上也可以分为两个可以分为两个主要的部分,打分以及构象搜索。其中构象搜索指的给定在蛋白口袋和配体结构情况下,去搜索相关的配体构象。而打分则指的是根据形状匹配度和能量这样的物理化学常数去评估基于搜索得到的配体构象与靶点的结合强度。在以往的研究中,已经有不少研究者们用机器学习方法去优化了打分这个过程,但构象搜索底层其实还是沿用的老一套没有重大的突破。这就使得两个共性问题一直遗留了下来没有解决
- 计算成本高,对于单个分子对接任务,计算搜索的分子对接可能需度要对数百万的构象空间进行搜索和评估。
- 应用场景限制,基于搜索的分子对接往往不适用于蛋白结合口袋未知的情况。
- 基于回归的深度学习分子对接算法
为了解决这两个共性问题,近年来涌现了许多深度学习分子对接方法,主要包括equibind,tankbind和e3bind。这些算法显著提升了分子对接效率但是并未能实现对准确性的显著提高。作者对于这些基于回归的分子对接方法为什么准确性不高做了相应的反思:
- 分子对接本身就是一个充满不确定性的过程,这种不确定性体现针对与某一个靶点,配体的可能拥有多个强结合位置,也就是熟知的结合口袋。此外,在结合口袋内部,配体也有可能因为各种因素产生多种结合构象。因此任何的分子对接方法,都需要在多个”备选答案“去挑选一个正确答案。如下图所示,
- 相关信息量并不足以支撑给出唯一正解。因此在采用回归策略时,容易为了最小化平均损失反而与正确构象发生偏移。
基于上述分析,作者认为分子对接任务本质上更贴近于一个分布的学习和模拟任务,而不是基于回归去确定唯一解。所以提出了采用生成模型进行分子对接任务,提供多个”备选构象“,之后后再去寻找何种构象最贴合实际情况。下图展示的就是diffdock的一个具体工作流程:
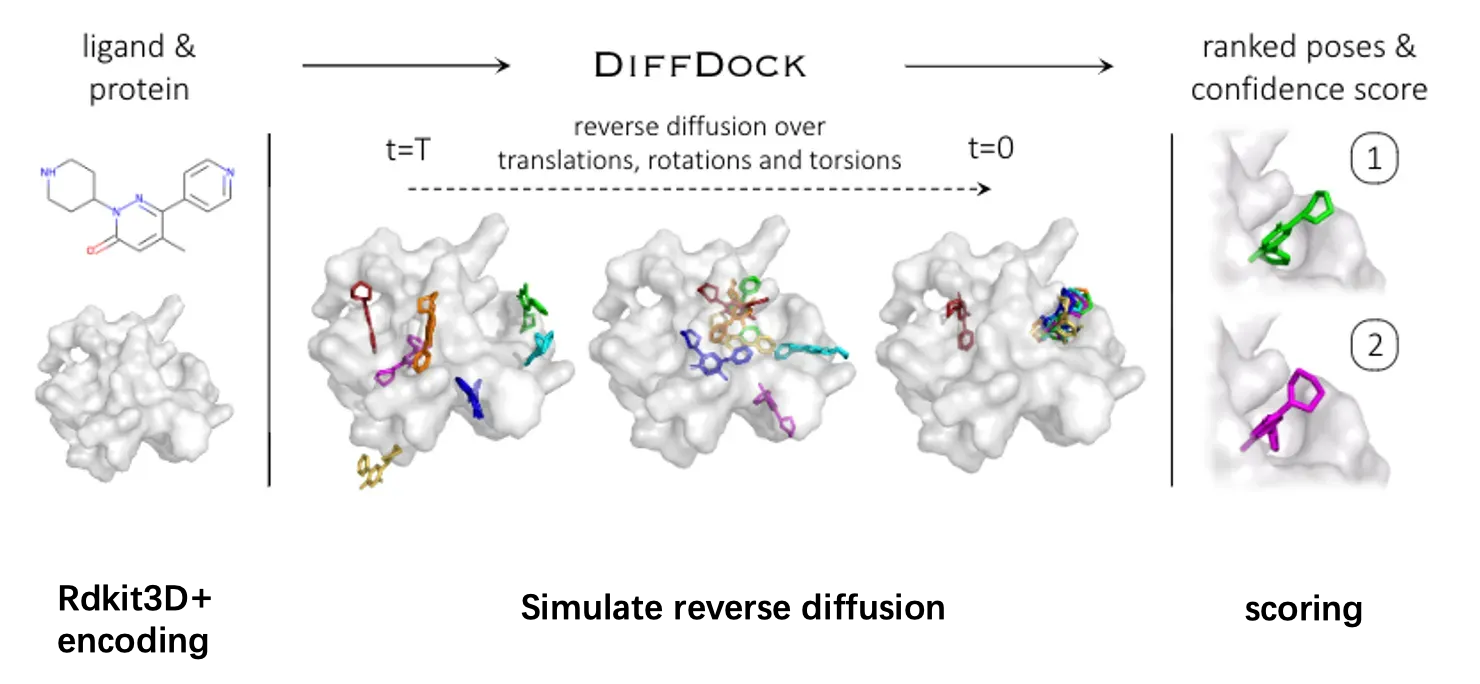
diffdock以配体和靶标的结构信息作为输入,之后对配体进行了一定的构象转换(平移,旋转,扭转)来生成新的配体构象。最后则是对这些生成的配体进行一个合理性的评分以及排名。
一、扩散模型简介
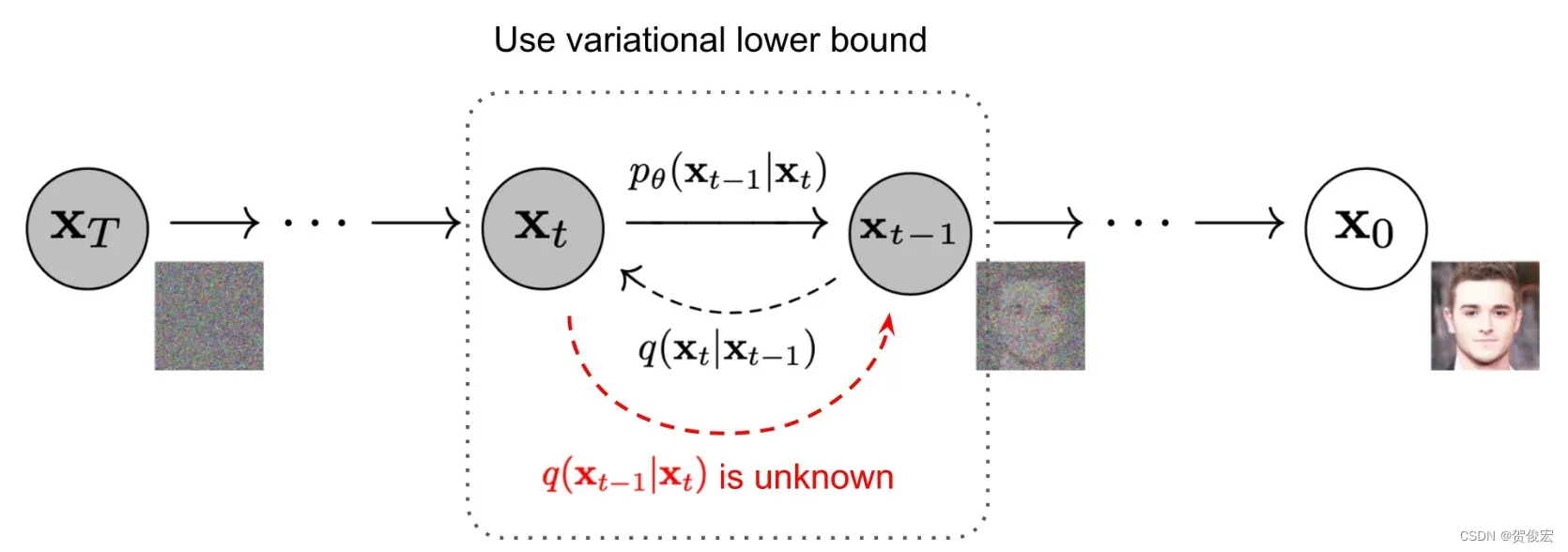
论文中采用的核心算法是扩散模型,在这里对扩散模型做一个简单的回顾,扩散模型分为正向扩散和反向扩散两个过程,以图片作为例子,正向扩散指的是往一张清晰的图片里加入人为制定的噪声,这张图片会逐渐模糊直到最后形成一个完全符合高斯分布的噪声图片。而反向扩散则是指的是利用深度学习模型,去对加噪声的过程进行模仿并逆过来推倒,将模糊的图片逐渐还原成清晰的图片。
二、方法
1. 噪声的制定与扩散
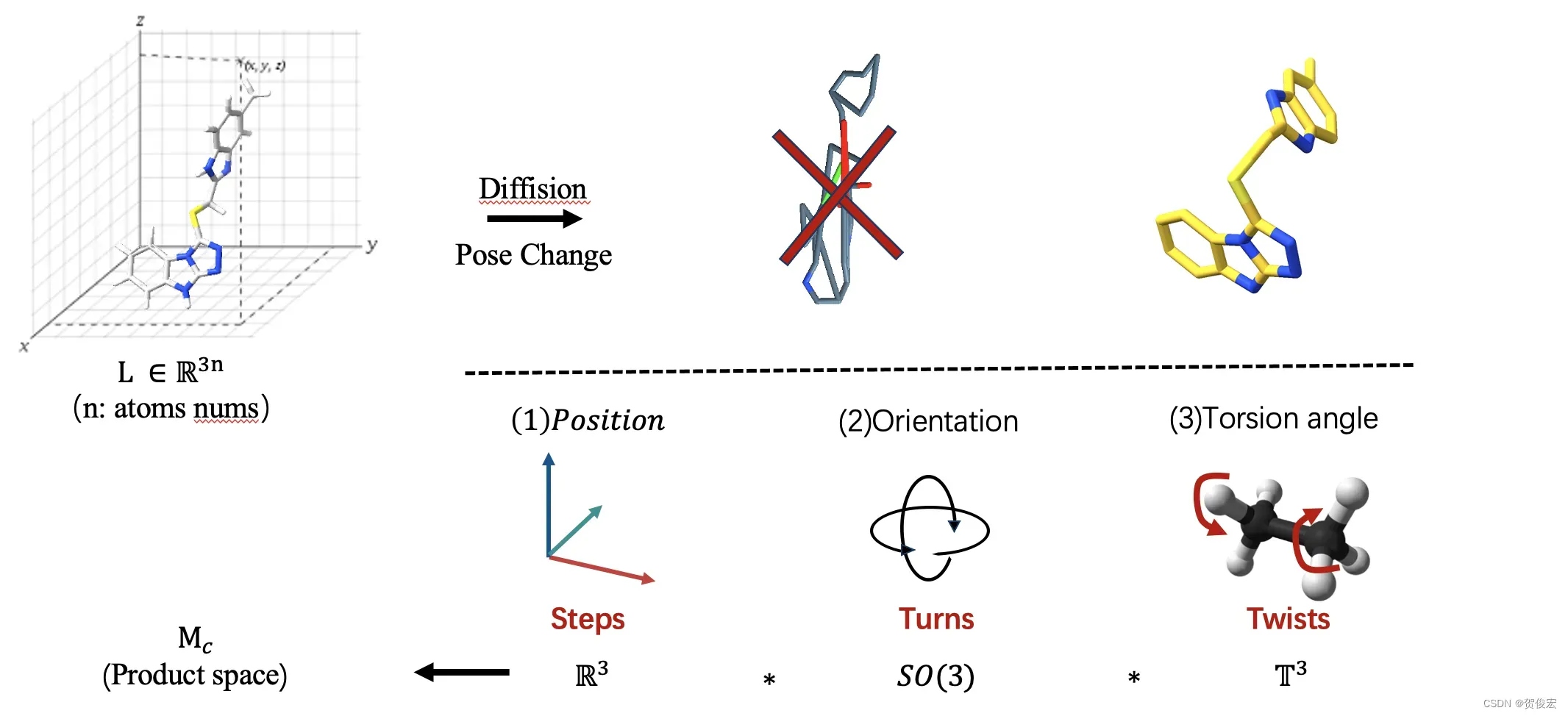
在介绍完了扩散模型的基本概念之后,让我们再把眼光重新聚焦回分子对接任务当中,配体的构象其实本质是也就是原子在三维坐标系上的集合,因此本质上也就是数据的分布。但与图片不同的是,小分子构象的正向扩散或者说是构象变化过程是存在一定限制的,配体在本身的键长和原子间的连接方式在构象转变过程中还是会保持基本不变。作者将配体构象变化的范围称为自由度,并将这个自由度划分为了三个部分。也就是文章标题中的steps,turns以及twist,分别对应着配体构象的位置变动,构象翻转以及键的扭转。这三个维度共同构成一个子空间,并且与实际上的配体构象空间相对应。这也就使得正向扩散从直接从配体构象空间采样变成了从ℝ^3, 𝑆𝑂(3),𝕋^3者三个维度的采样。
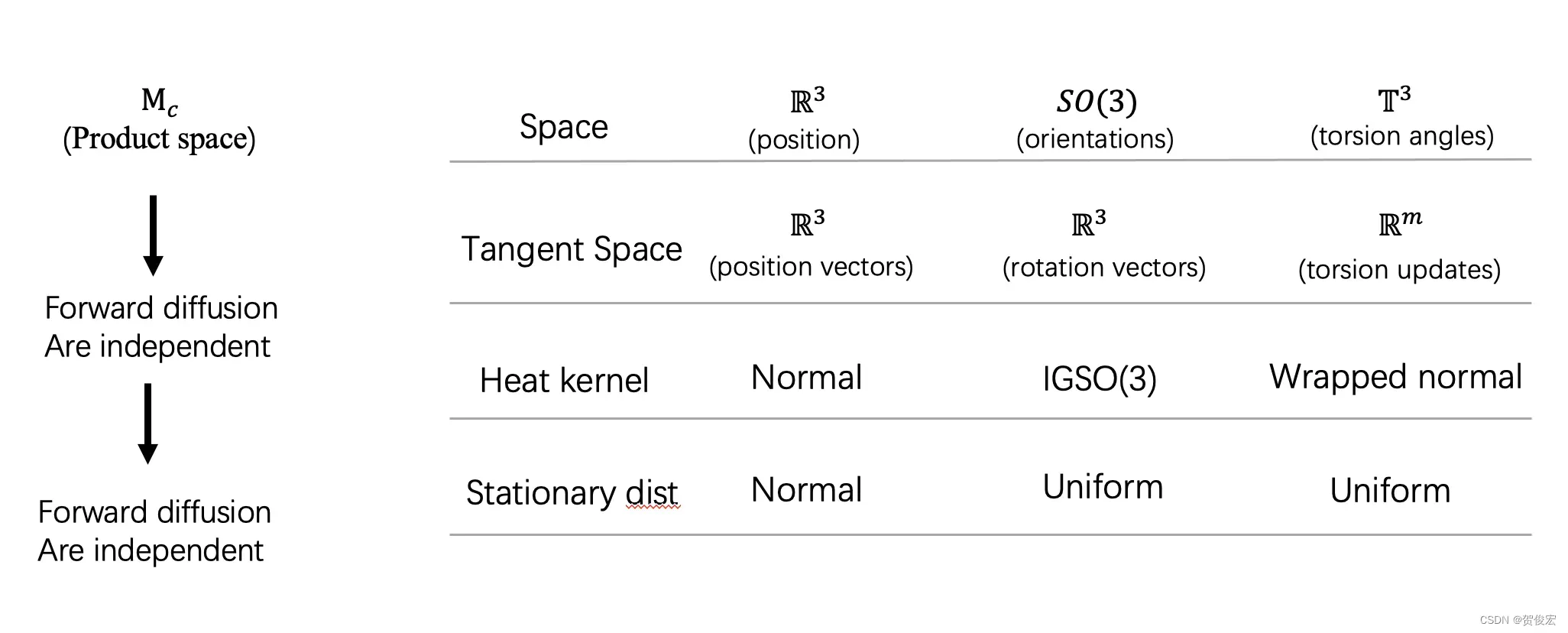
之后文章中有又给出了这三个维度的一个变化规律,也就是概率密度函数。其中空间位置的R3采用的正态分布,旋转SO(3)采用的IGSO(3), 而扭转角采用的是环绕正态分布。并通过重复多次的噪声最终分别达到高斯和均匀的分布的状态。以上就介绍完了diffdock中的加噪声过程
2. 去噪(打分)模型
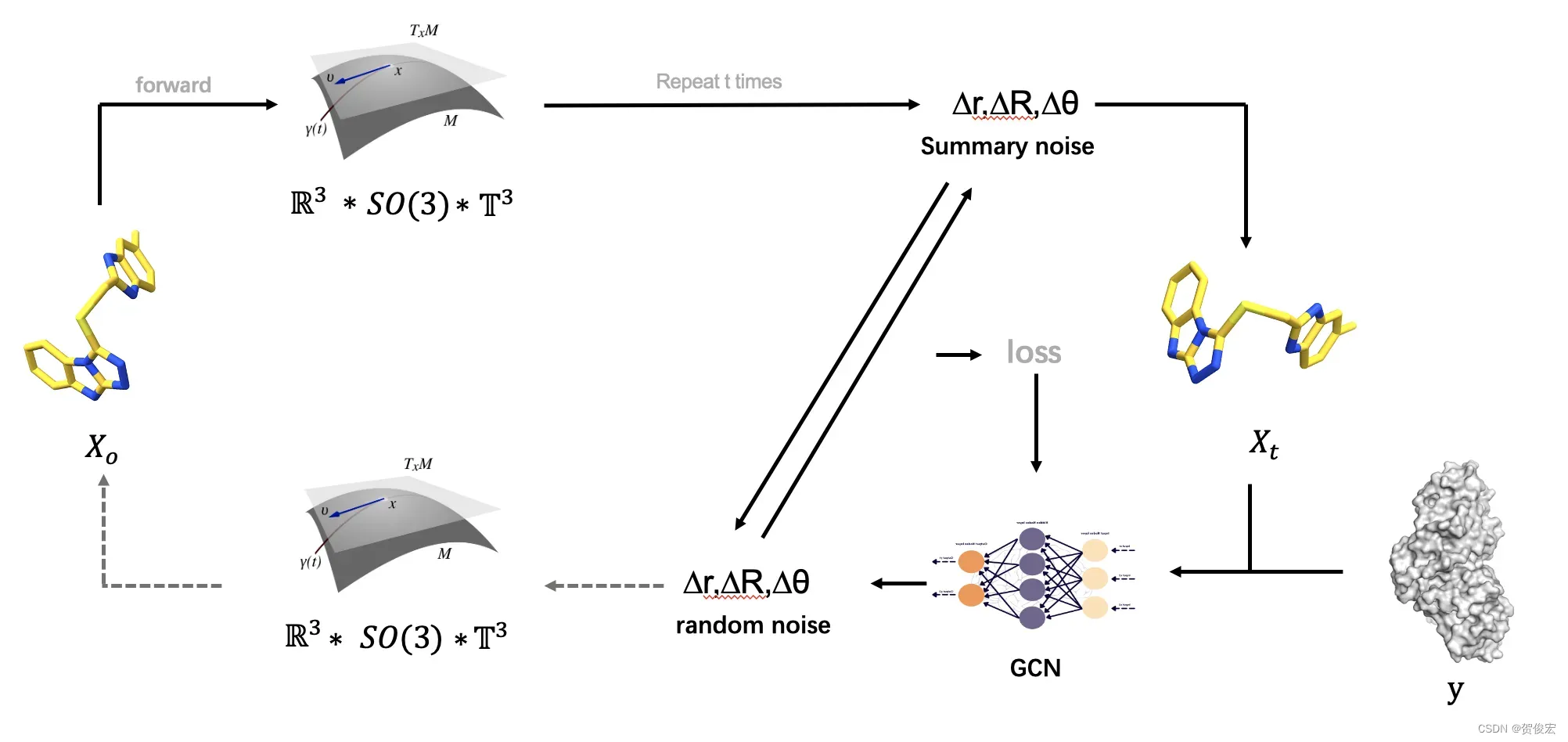
模型训练过程是基于已知的小分子的构象进行的,首先将已知的配体构象X0映射到子空间中,在对子空间进行一个重复t次的随机采样,并将三个维度的噪声进行累计得到一个累积噪声,并随之获取了一个新的配体构象Xt。Xt和蛋白构象y将作为输入共同投入到一个图卷机神经网络模型中,文章中将这个模型称为score model。Score model的输出是一个随机的逆噪声,但不会执行反向扩散的过程。而是和已知的噪声进行一个比对,两者的差异就是模型模型的损失,而模型也将根据损失值调整内部的参数。以上过程会在每个训练样本之上进行循环,直到score 模型能够针对输入Xy以及蛋白构象精准预测逆噪声。
当score模型训练好了以后,对于一个任意的配体和蛋白就能够通过score model和子空间去更新配体的位置,旋转以及键的旋转,从而实现分子对接的过程。
3. 置信度模型
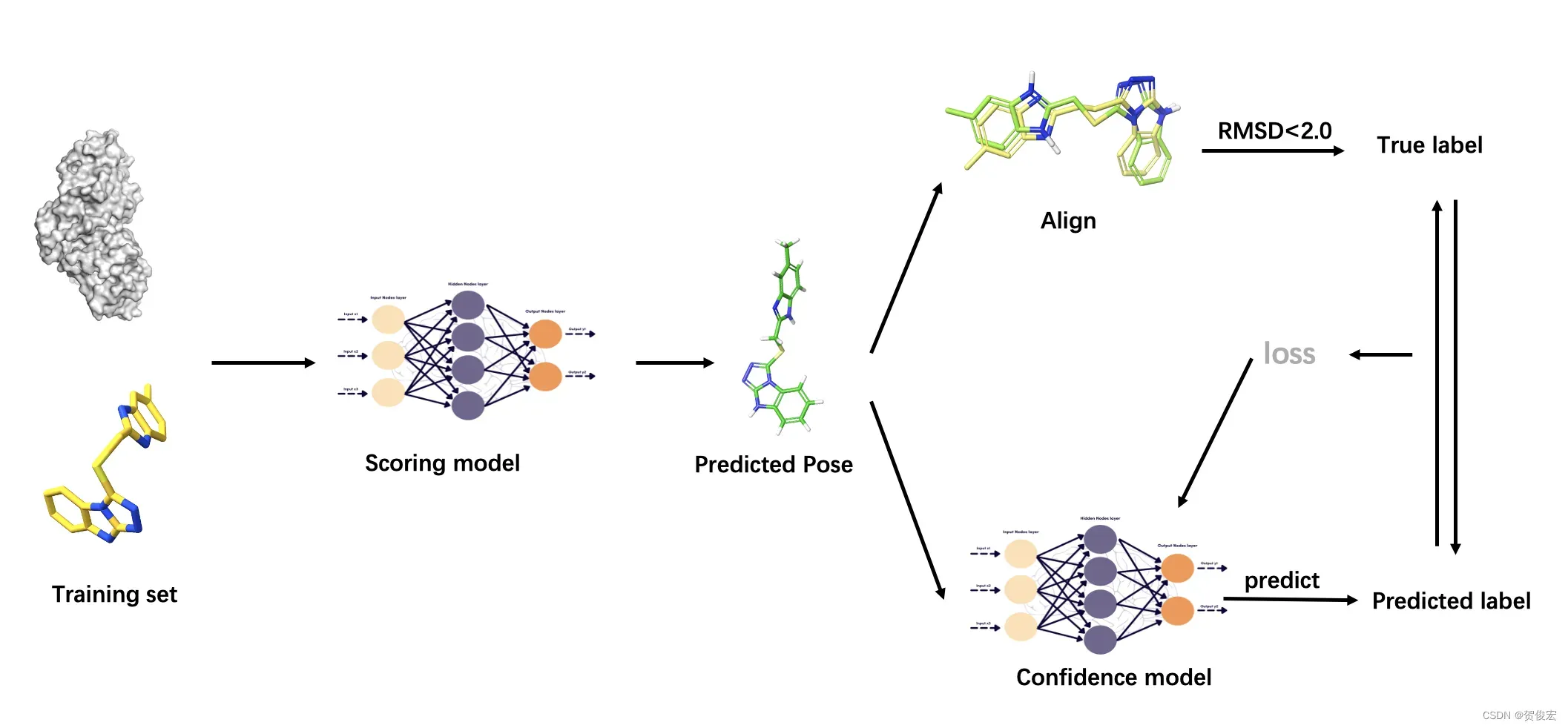
为了去评估这些生成的分子复合物体系的可信度,文章中又训练了一个置信度模型。训练的方式如图所示,将所有的训练样本投入到score model中进行分子构象的生成,之后将预测的配体构象训练样本进行align,然后根据RMSD值是否小于2判定预测是否成功并给予标签。置信度模型则是通过蛋白和预测的小分子构象去预测标签。预测标签与真实标签之间会计算一个交叉熵损失用于更新模型的参数。
4. 工作流回顾
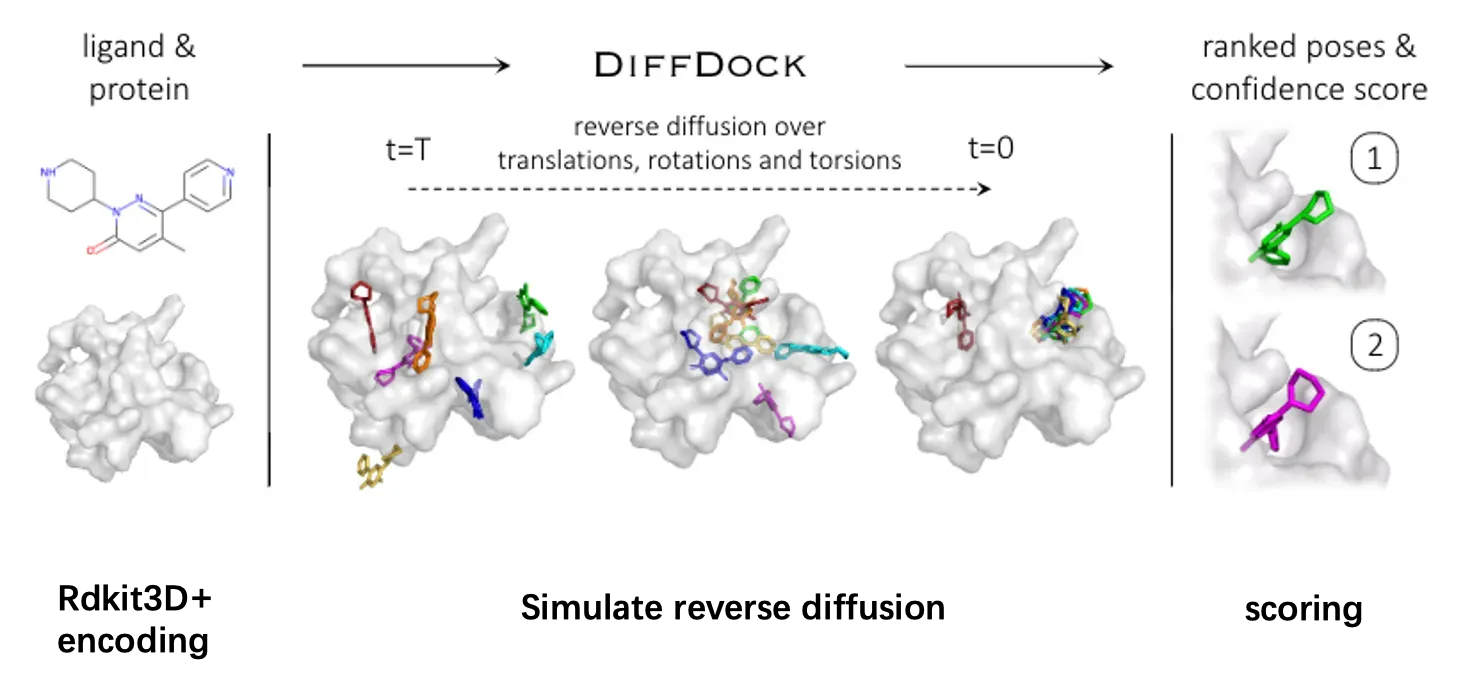
以上就介绍了完了diffdock中涉及的方法,最后对模型的整体工作流程做一个回顾,工作流程主要是三部分,第一部分是将输入进行编码。这里的输入指的是小分子的结构以及靶标的构象,当输入的小分子结构是2维的时候,将会采用RDKIt去计算一个低能构象,将结构转为三维。之后模型会对配体构象分别进行平移,旋转以及键扭转的逆向扩散过程。获取得到多个配体构象,最后则是根据置信度模型对这些pose进行一个打分和排名。
三、结果
1. 对接成功率与消耗时间对比与评估
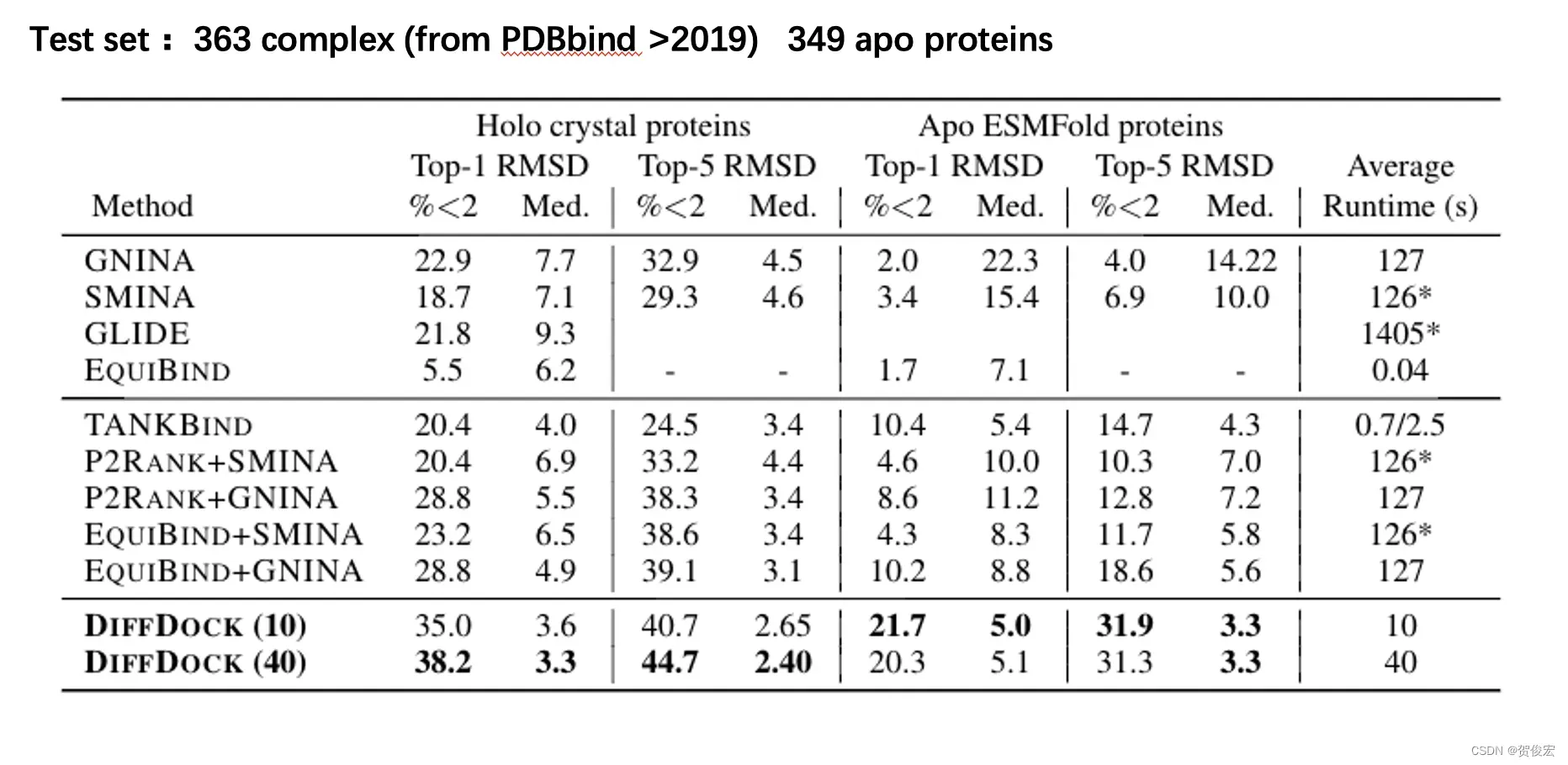
对模型表现的一个总体评估,主要是分为两个部分。首先是跟其他对接算法的评估,一共测评了6种算法。测试集是来自于PDBbind中的396个复合物构象。按照自对接后RMSD能否达到2以内作为判断对接成功与否的标准。可以看到在blind对接任务中, 也就第一个大篮中,由GNINa取得了最高的成功率在top1和top5分别是22.9%以及32.9%。而在提供了蛋白口袋对接中,是由gnina+equiband实现了最性能。但diffdock无论在生成10个构象还是40个构象的情况下,top1成功率都实现了5个百分点以上的提升。除了进行实验构象的分子对接意外,diffdock还进行了基于计算预测结构的分子对接,在这类型的任务上,diffdock展现了非常强的优势,在其他算法top1成功率最高只能达到%10左右的时候,它可以达到20%。 最后则是计算资源消耗的问题,相比于基于搜索的算法gnina,diffdock的时间缩短了3-12倍
2. 自身参数以及置信度模型评估
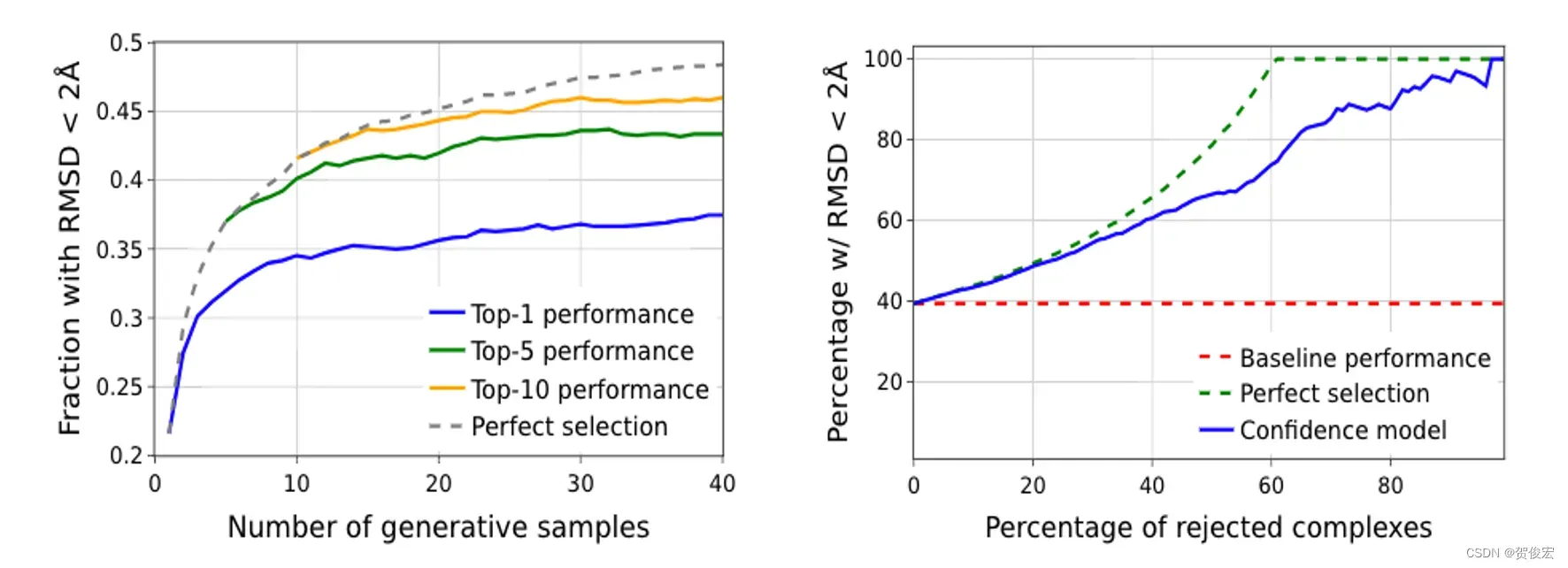
首先看到左边这张图。展示的是分别生成1~40个分子构象的时候,模型性能的变化。可以看到采样0~20以内的时候,随着生成分子增多对接的成功率是有一个相对显著的提升的。但超过20提升就不明显了,甚至在30~40这个区间会出现top5和top10还出现了一个轻微的下降。此外就是当取到top10的时候,其实已经很接近模型生成分子的最优解了。
右图展示的是剔除置信度排名靠后的分子,剩余分子的对接成功率情况。当只取置信度排名靠前三分之一的对接成功率可以达到80%以上,这也就从侧面说明了置信度能够良好的反应预测构象是否准确。
四、相关资料
文献:https://arxiv.org/abs/2210.01776
公开课:https://www.youtube.com/watch?v=HOlVUEZr7Nw
文章出处登录后可见!