《Knowledge Tracing:A Survey》
论文在2023年2月收录于ACM Computing Surveys(IF好像有14)
https://dl.acm.org/doi/pdf/10.1145/3569576
后文里,我用技能一词 来 代替原文中的KC – knowledge component = 其他文献的知识点
引文
教学是促进知识转移的重要活动 新冠促进 教育系统的数字化转型
目前的挑战
- 每个题目可能对应多个技能
- 技能之间存在依赖性,例如k1是k2的先决条件
- 学生的遗忘行为会导致认知下降,对遗忘特征建模,技能可以根据遗忘相关性排序
DLKT的方向:1. 记忆结构 2. 注意力机制 3. 图表示学习 4. 文本特征 5. 遗忘特征
研究问题
RQ1. KT方法的主要类别,之间的区别
RQ2. 数据集,以及预处理和使用
RQ3. KT的研究可以利于哪些应用领域
RQ4. 未来的研究机遇和挑战
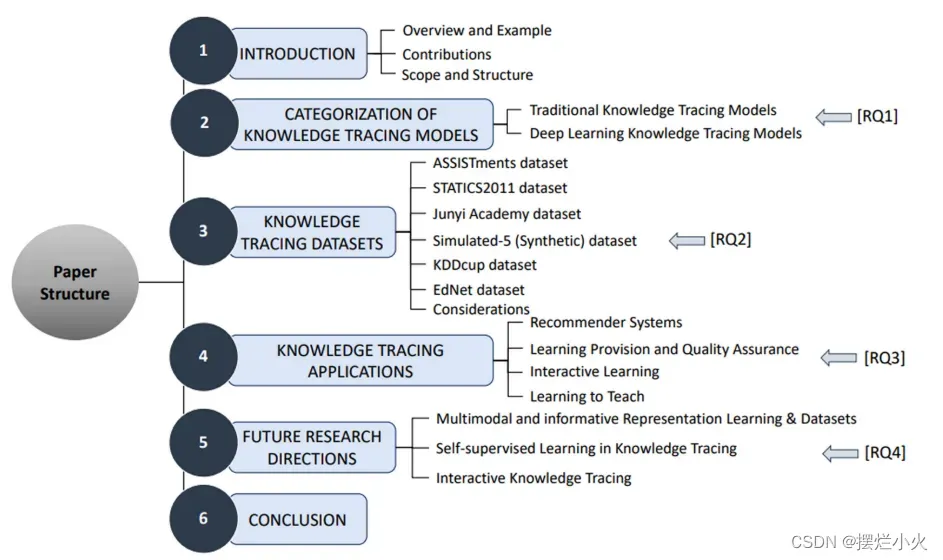
相关工作
传统KT
BKT,个性化BKT,动态BKT ; IRT,AFM,PFA,KTM
(这里就不一一阐述了,文章中对各种模型都进行了介绍,并对它们模型参数、推理和时间分析)
深度学习KT
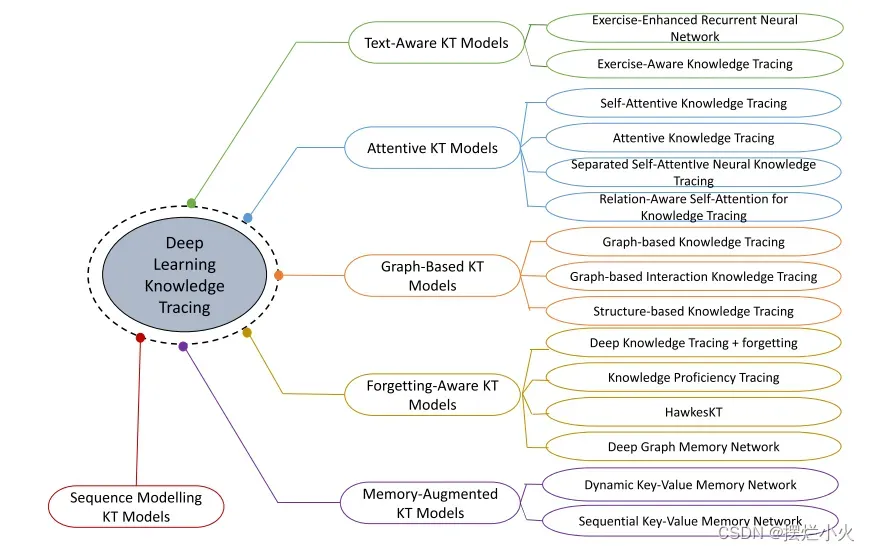
-
序列建模的KT模型: DKT、DKT+、DKT-DSC(根据学生的表现聚类分组,实时更新类信息)
-
记忆增强的KT模型: DKVMN、SKVMN(采用Hop-LSTM,两个LSTM问题相关时才连接,捕获相似技能的题目之间长期依赖关系)
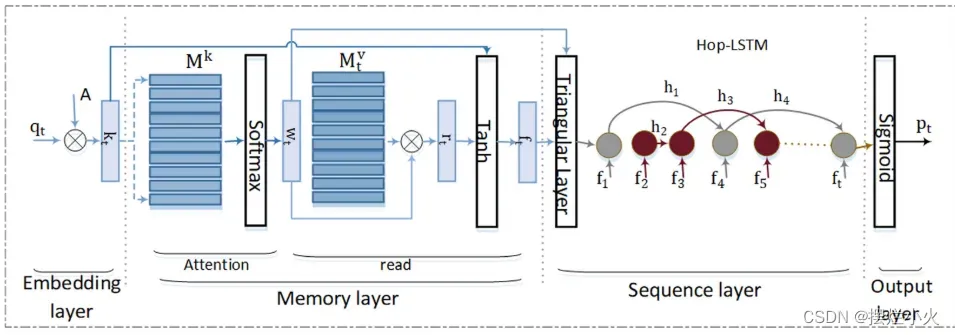
-
注意力KT模型: SAKT、AKT(单调注意机制,考虑了遗忘效应,并提出基于Rasch的嵌入表示-问题偏离技能程度)、SAINT(将交互分为题目和答案分别放入编码器和解码器中)、SAINT+(考虑答题消耗时间和两次答题时间间隔)、RKT(将注意力权重+关联系数-题目关系(文本信息与过去题目间关系)和遗忘关系)、CKT(注意力和1D卷积网络结合,考虑过去答题顺序和个性化技能掌握水平)、CoKT(考虑之前的历史记录和同辈学生的知识状态情况 协同过滤思想)
-
图KT模型: GKT(技能作为图节点、边表示依赖关系 构建图方法:端到端or统计技能的先后次数)、GIKT(利用题目和技能之间关系图)、SKT(捕获相似性和先决性 假设题目1/1技能 总结图数据的时间和空间效应)、PEBG(通过预训练方法捕获内在外部和相似性关系,并融合题目难度于一个二部图)
-
文本感知的KT模型: EERNN(双向LSTM从题目文本提取表征)、EKT(在预测阶段加入多个技能信息,用知识状态矩阵替代向量)、AdaptKT(迁移训练好的KT到目标域,用深度自编码器处理文本数据形成嵌入)、RKT、HGKT
-
遗忘感知的KT模型: DKT+Forgetting(同一技能答题次数、相同技能的题目时间间隔、第一题和最后一题时间间隔)、KPT(利用先验信息(题目技能关系和学生的学习曲线+遗忘曲线理论)进行概率矩阵分解)、HawkesKT(点过程自适应建模时序交叉效应,问题之间相互作用且存在不同速率的衰减)、DGMN(结合GNN和遗忘记忆,在技能空间建模遗忘特征并融合题目嵌入和图嵌入)、LPKT(预测阶段考虑学习增益,3个记忆细胞(新题目+之前答题时间与间隔、遗忘门输出遗忘效应、预测门考虑前两者))
讨论:
- 知识状态:单知识/多知识,趋势是 开发一种动态捕获复杂技能上的知识状态表征
- 知识依赖性:先决条件。未来路径:注意力机制学习题目在相关技能程度、用基于图的模型学习题目技能关系
- 特征增强:遗忘、文本。虽然提高性能 但也限制了适用性
KT 数据集
ASSISTments Datasets
小学数学练习 包括多选、文本题、开放式题
A09:123个技能,只有2/3有技能,一个问题最多四个技能
A12:大部分问题没有对应的技能,因此总体性能较低
A15:100个问题(题目id、答题学生id、答题正确率、日志)稀疏度很低 答题密集
ASSISTChall:102个技能 也是密集数据集
Statics2011
卡内基梅隆大学工程静力学课程,通常被预处理为129297次交互
Junyi
台湾电子学习平台junyi学院收集,722个题目 41个技能 数学
Synthetic
由Piech提出的模拟合成数据集,训练集和测试集都包含50个题目 1个技能 ,每个题目被回答4000次,不需要预处理。
KDDCup
2010年KDDcup教育数据挖掘挑战赛 对代数题的回答 来自卡内基公司的智能导学系统“The Cognitive Tutors”,包含3个子集
Algebra 2005-2006:每个题目被分为子问题 且和1个或多个技能相关
Algebra 2006-2007:类似05,该数据集时间戳存在问题,采用率低
Bridge to Algebra:493个技能。
EdNet
分层数据集由KT1-4表示不同类型的学生活动。KT1 188个技能 KT2 包含用户解决问题时的活动 KT3包含 学生学习方式(看讲座) KT4 最完整,包含各类信息包括购买 Riid TUTOR在线导学平台 致力于为国际交流练习英语 韩国
综合考虑
相同数据集不同数量的技能以及不同实验设置会影响报告结果。大部分数据集不提供人口统计信息,基于性别等其他类别预测无法实现。基准数据集一直在更新,公开数据集版本有助于获得一致可比的结果
KT应用
教育推荐系统
用KT模型评估学生的知识状态 用推荐模型根据知识状态来推荐学习材料
实例: 基于图的推荐方法。根据学生的知识状态将学生分组,为每组推荐最合适的练习类型。老师选择特定技能,模型基于历史信息构建动态知识图(点是学生知识向量,边是对技能掌握程度的相似性),图被聚类为节点组,每个组用GNN构造共享嵌入
交互式教育视频推荐模型、强化学习推荐器
学习提供和质量保证
教师用KT模型根据学生历史记录模拟,识别最合适的课程,最大化学生的知识增益
使用KT模型评估每个模块的影响来评估课程结构在实现其预定目标方面的有效性,对学生知识增长的影响
**实例:**作者使用DKT模型来跟踪学生在学习特定课程模块之后的知识状态的进展,然后,行动者-批评者强化学习代理考虑不同课程模块之间的知识状态及其预定义的关系(即,先决条件),并采取行动为学生选择下一个要学习的模块,以最大化他们在实现课程目标中的知识收获。按照这种方法,课程结构可以动态地适应学生的需要和技能,而不是采用一种不能适合所有学生的固定结构。
通过交互学习提高学生参与度
交互式教育(奖励、动作) 教育游戏可以比传统方式(课本、课堂)更好地适应我们自然学习能力
教育游戏作为KT的一个很好地应用前景,它的核心是评估玩家的知识进步并调整游戏体验(难度、对手能力等)
Learning to teach
虚拟学生(采用强化学习or机器学习模型的智能体)被视为需要学习一组技能的真实学生
Learning to teach: KT模型跟踪学生的知识状态,把输出作为教师模型的输入,定制学生代理模型的学习过程,教师优化处理教学策略。
讨论
-
传统的KT(BKT等)对KT问题简化,假设知识状态是二元随机变量或对每个题目一个技能,保证后验计算易于处理
-
IRT和因子分析方法 假设之前的学习能力除了历史题目可用 会限制冷启动等情况 ,适用于原始技能简单应用,状态概率是可解释的。
-
深度KT方法 早期RNN 限制了多个技能和长期依赖性 适用于技能少 序列段的场景
-
记忆增强的KT 由于存储记忆结构需要额外的成本 适用于内存和计算资源可用的场景
-
注意力KT 使用多头开销加大 适用于处理多个技能的长期依赖关系 且 有多个GPU可用并行分配注意力头
-
图KT可用捕获复杂问题和技能关系,但基于先验,在应用场景中难以保证,近期有研究[GKT]希望直接从题目回答序列中学习图结构
-
文本感知KT 不适用于不提供题目/技能文本标记的应用
KT未来研究方向
多模态与信息表征学习/数据集
题目的描述(图像、数学公式)更丰富的信息嵌入被忽略了。因此引出方向:**1.**那些信息数据可以用于改进KT模型的性能 2. 如何为KT任务表示这些数据 3. 如何为KT任务创建数据集来实现更丰富的嵌入表征学习。 EKT虽没有多模态数据集但融合多个特征空间的信号
自监督学习
SSL采用对比损失来自动生成标签,这种预训练模型可以被转移到下游任务以利用有限的标记数据以监督学习方式进行训练。创建预训练模型(存在的语言模型/cv)来生成KT的信息表示,探索在冷启动场景或数据不准确的情况下,它如何缓解这类限制
交互式KT
目前主要是观察交互历史来估计状态的被动方法。由题目回答反应来驱动的交互式方式未被探索。交互式方法很适合冷启动场景,通过提问或不同技能的问题来揭示学生的知识状态。 优化问题的抽象策略也是可探索方向,利用强化学习方法来给出最大的reward
可解释XAI
模型的逻辑性和结构的透明性是有利于教育的。方向:1. 解释KT预测过程的技术,算法决策如何影响学习过程or课程设计。 2. 知识蒸馏来理解解释其他模型预测[42] 可用于KT。
<!–[42] Anselm Haselhoff, Jan Kronenberger, Fabian Kuppers, and Jonas Schneider. 2021. Towards black-box explainability with Gaussian discriminant knowledge distillation. In CVPR. 21–28. –>
结论
不同的段落用来回答不同的RQ。其中对于RQ4未来研究方向
- 利用多模态数据增强KT的态势感知
- 自监督技术利用未标记数据和有限标记的数据
- 交互式和可解释性技术,可以带来更好的预测和可见性。
文章到此结束了,这一篇文献可以说是非常全面的总结了KT的各个方面,不愧是顶刊,包括最后的研究方向都是近两年大家的发展趋势,根据引文可以发现2022年之后等重要模型例如Bi-clkt、CL4KT 可能在这篇文章后发出 这些都是本文所提出未来研究方向的进一步扩展,值得大家去研读
文章出处登录后可见!