目录
1.1多元线性回归的基本原理
线性回归是机器学习中最简单的回归算法,多元线性回归指的就是一个样本有多个特征的线性回归问题。对于一个有在这个表达式中,被统称为模型的参数,其中
被称为截距(intercept),
~
被称为回归系数(regression coefficient),有时也用
如果考虑有m个样本,是包含了m个全部样本的回归结果列向量,我们可以使用矩阵来表示这个方程,其中
可以被看做是一个结构为(1,n)的列矩阵,
是一个结构为(m,n)的特征矩阵,则有:
1.2 最小二乘法求解多元线性回归的参数
为了求解让RSS最小化的参数向量,通过最小化真实值和预测值之间的RSS来求解参数的方法叫做最小二乘法。最终得到参数
最优解为
。
1.3 linear_model.LinearRegression
class sklearn.linear_model.LinearRegression (fifit_intercept=True, normalize=False, copy_X=True, n_jobs=None)
| 参数 | 含义 |
|---|---|
| fit_intercept | 布尔值,可不填,默认为True 是否计算截距,如果设置为False,则不会计算截距。 |
| normalize | 布尔值,可不填,默认为False 当fit_intercept设置为False时,将忽略此参数,如果为True,则特征矩阵X在进入回归之前将会被减去均值(中心化)并除以L2范式(缩放)。 如果要进行标准化,则需在fit数据之前使用preprocessing模块中的标准化专用类StandarScaler |
| copy_X | 布尔值,可不填,默认为True 若为真,则将在X.copy()上进行操作,否则原本的特征矩阵X可能被线性回归影响并覆盖。 |
| n_jobs | 整数或None,可不填,默认为None 用于计算的作业数。只有在多标签的回归和数据量足够大的时候才生效。除非None在joblib.parallel_backend上下文中,否则None统一表示为1。如果输入-1,则表示使用全部的cpu来进行计算。 |
1.4 案例
from sklearn.linear_model import LinearRegression as LR
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.datasets import fetch_california_housing as fch
import pandas as pd
housevalue=fch()
x=pd.DataFrame(housevalue.data)
y=housevalue.target
x.columns=housevalue.feature_names
xtrain,xtest,ytrain,ytest=train_test_split(x,y,test_size=0.3,random_state=420)
# 恢复索引
for i in [xtrain,xtest]:
i.index=range(i.shape[0])
# 建模
reg=LR().fit(xtrain,ytrain)
yhat=reg.predict(xtest)#预测yhat
reg.coef_ #w,系数向量array([ 4.37358931e-01, 1.02112683e-02, -1.07807216e-01, 6.26433828e-01,
5.21612535e-07, -3.34850965e-03, -4.13095938e-01, -4.26210954e-01])reg.intercept_ #截距-36.256893229203946[*zip(xtrain.columns,reg.coef_)][('MedInc', 0.43735893059684),
('HouseAge', 0.010211268294493828),
('AveRooms', -0.10780721617317682),
('AveBedrms', 0.6264338275363777),
('Population', 5.21612535346952e-07),
('AveOccup', -0.003348509646333501),
('Latitude', -0.41309593789477195),
('Longitude', -0.4262109536208474)]
| 属性 | 含义 |
|---|---|
| coef_ | 数组,形状为(n_features),或者(n_taargets,n_features) 线性回归方程中估计出的系数。如果在fit中传递多个标签(当y为二维或以上的时候),则返回的系数形状为(n_targets,n_features)的二维数组,而如果仅传递一个标签,则返回的系数是长度为n_features的数组 |
| intercept_ | 数组,线性回归中的截距项 |
1.5 多元线性回归的模型评估指标
1.5.1 MSE均方误差&MAE绝对均值误差
RSS残差平方和,它的本质是我们的预测值与真实值之间的差异,所以RSS既是我们的损失函数,也是我们回归类模型的模型评估指标之一。但是,RSS有着致命的缺点:它是一个无界的和,可以无限地大。我们只知道,我们想要求解最小的RSS,从RSS的公式来看,它不能为负,所以RSS越接近0越好,但我们没有一个概念,究竟多小才算好,多接近0才算好?为了应对这种状况,sklearn中使用RSS的变体,均方误差MSE(mean squared error)来衡量我们的预测值和真实值的差异:
from sklearn.metrics import mean_squared_error as MSE
MSE(yhat,ytest)0.5309012639324575虽然均方误差永远为正,但是sklearn中的参数scoring下,均方误差作为评判标准时,却是计算”负均方误差“(neg_mean_squared_error)。这是因为sklearn在计算模型评估指标的时候,会考虑指标本身的性质,均方误差本身是一种误差,所以被sklearn划分为模型的一种损失(loss)。在sklearn当中,所有的损失都使用负数表示,因此均方误差也被显示为负数了。真正的均方误差MSE的数值,其实就是 neg_mean_squared_error去掉负号的数字。(2) 调用交叉验证的类cross_val_score并使用里面的scoring参数
cross_val_score(reg,x,y,cv=10,scoring="neg_mean_squared_error").mean()-0.5509524296956613ytest.mean()2.0819292877906976测试集平均值为2.08,而均方误差却达到0.5,可见误差较大
除了MSE,我们还有与MSE类似的MAE(Mean absolute error,绝对均值误差):
1.5.2 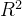
对于回归类算法而言,只探索数据预测是否准确是不足够的。除了数据本身的数值大小之外,我们还希望我们的模型能够捕捉到数据的”规律“,比如数据的分布规律,单调性等等,而是否捕获了这些信息并无法使用MSE来衡量。
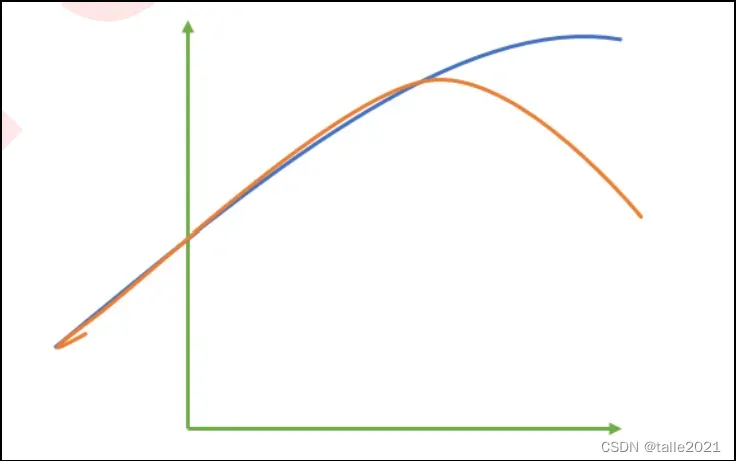
这张图中,其中红色线是我们的真实标签,而蓝色线是我们的拟合模型。这是一种比较极端,但的确可能发生的情况。这张图像上,前半部分的拟合非常成功,看上去我们的真实标签和我们的预测结果几乎重合,但后半部分的拟合却非常糟糕,模型向着与真实标签完全相反的方向去了。对于这样的一个拟合模型,如果我们使用MSE来对它进行判断,它的MSE会很小,因为大部分样本其实都被完美拟合了,少数样本的真实值和预测值的巨大差异在被均分到每个样本上之后,MSE就会很小。但这样的拟合结果必然不是一个好结果,因为一旦我的新样本是处于拟合曲线的后半段的,我的预测结果必然会有巨大的偏差,而这不是我们希望看到的。所以,我们希望找到新的指标,除 了判断预测的数值是否正确之外,还能够判断我们的模型是否拟合了足够多的,数值之外的信息。
为了衡量模型对数据上的信息量的捕捉,我们定义了 和可解释性方差分数(explained_variance_score,EVS):
# 调用R2
from sklearn.metrics import r2_score
r2_score(ytest,yhat) # 或:r2_score(y_true=ytest,y_pred=yhat)0.6043668160178813(2)从线性回归LinearRegression的接口score来进行调用
r2=reg.score(xtest,ytest)
r20.6043668160178813(3)EVS调用方法,可以从metrics中导入,也可以在交叉验证中输入”explained_variance“来调用。
from sklearn.metrics import explained_variance_score as EVS
EVS(Ytest,Yhat)0.6046102673854398cross_val_score(reg,x,y,cv=10,scoring="explained_variance").mean()0.5384986901370823import matplotlib.pyplot as plt
plt.plot(range(len(ytest)),sorted(ytest),c="black",label="data")
plt.plot(range(len(yhat)),sorted(yhat),c="red",label="data")
plt.legend()
plt.show()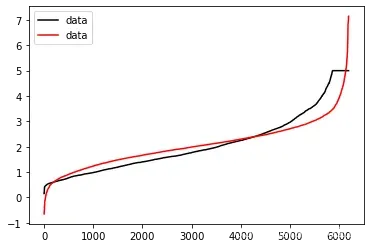
PS:EVS和是异曲同工的,两者都是衡量 1 – 没有捕获到的信息占总信息的比例,EVS和
难道不应该相等吗?但从我们的结果来看,两者虽然相似,但却并不完全相等,这中间的差值究竟是什么呢?
和EVS有什么不同?
首先看一组有趣的情况:
import numpy as np
rng=np.random.RandomState(42)
x=rng.randn(100,80)
y=rng.randn(100)
cross_val_score(LR(),x,y,cv=5,scoring='r2')array([-178.71468148, -5.64707178, -15.13900541, -77.74877079,
-60.3727755 ])以上说明了也可以为负!!!
 许多教材和博客中让
许多教材和博客中让文章出处登录后可见!