目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯毕业设计-基于深度学习的图像文字识别系统
课题背景和意义
随着信息化水平的不断提升,以图像为主的多媒体信 息迅速成为重要的信息传递媒介,图像中的文字数据包含 丰富的高层语义信息与分析价值。光学字符识别(Optical Character Recognition,OCR)指利用电子设备(例如扫描仪 或数码相机)检查纸上打印的字符,通过检测暗、亮模式确 定其形状,然后用字符识别方法将形状翻译成计算机文字 的过程。它是一种针对印刷体字符,采用光学方式将纸质 文档中的文字转换为黑白点阵的图像文件,并通过识别软 件将图像中的文字转换成文本格式,供文字处理软件进一 步编辑加工的技术,通过该技术可将使用摄像机、扫描仪 等光学输入仪器得到的报刊、书籍、文稿、表格等印刷品图 像信息转化为可供计算机识别和处理的文本信息。目 前,OCR 技术广泛应用于多个领域,比如文档识别、车牌识 别、名片识别、票据识别、身份证识别和驾驶证识别等。如何除错或利用辅助信息提高识别准确率和效率,已成为 OCR 技术研究热门课题。
实现技术思路
一、基本原理
OCR 文字识别技术
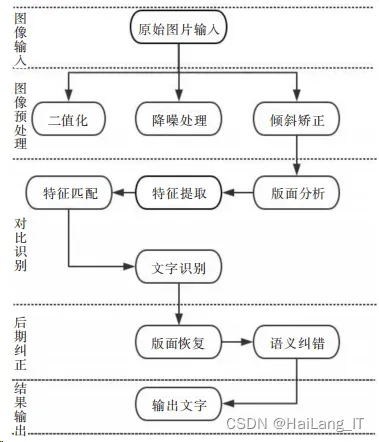
通常 OCR 文字识别过程可分为图像输入、图像预处 理、对比识别、后期纠正和结果输出等步骤。据此可将整 个 OCR 识别流程划分为 5 个部分,图为 OCR 文字识别 系统工作流程。
文字识别常用方法有模板匹配法和几何特征抽取法。
(1)模板匹配法。将输入的文字与给定的各类别标准 文字(模板)进行相关匹配,计算输入文字与各模板的相似 程度,取相似度最大的类别作为识别结果。该方法适用于 识别固定字型的印刷体文字,优点是用整个文字进行相似 度计算,对文字缺损、边缘噪声等具有较强的适应能力;缺 点是当被识别类别数增加时,标准文字模板的数量也随之 增加,增加机器存储容量会降低识别正确率。
(2)几何特征抽取法。抽取文字的一些几何特征,如 文字端点、分叉点、凹凸部分及水平、垂直、倾斜等各方向 的线段、闭合环路等,根据这些特征的位置和相互关系进 行逻辑组合判断,获得识别结果。该识别方式由于利用结 构信息,也适用于变形较大的手写体文字。不足之处在于 当出现文字粘连扭曲、有噪声干扰时,识别效果不佳。
基于深度学习的 LeNet-5 网络
深度学习(Deep Learning)是多层神经网络运用各种机 器学习算法解决图像、文本等各种问题的算法集合。深度 学习的核心是特征学习,它通过组合低层特征形成更加抽 象的高层表示属性类别或特征,从分层网络中获取分层次 的特征信息,以发现数据分布式特征表示,从而解决以往 需要人工设计特征的难题。 利用深度学习进行文字识别,采用的神经网络是卷积 神经网络(Convolutional Neural Networks,CNN),具体选择 使用哪一个经典网络需综合考虑,越深的网络训练得到的 模型越好,但是相应训练难度会增加,此后线上部署时预 测的识别速度也会很慢,所以本文使用经简化改进后的 LeNet-5(-5 表示具有 5 个层)网络,如图所示。

它与原 始 LeNet 稍有不同,比如把激活函数改为目前常用的 ReLu 函数;与现有 conv->pool->ReLu 不同的是其使用的方式是 conv1->pool->conv2->pool2,再接全连接层,但是不变的是 卷积层后仍然紧接池化层。
二、基于深度学习的图像文字识别技术
方法步骤
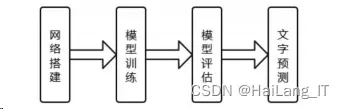
本文在开源的 TensorFlow 框架开发环境下,搭建深度 学习神经网络 LeNet-5 和计算图,将样本文件添加到训练 队列中喂给网络训练,完成充足的训练量后,对模型进行 识别准确率评估,并最终将训练得到的识别模型应用于实 际场景中的图像文字识别实验检测,流程如图所示。
1、网络搭建
深度学习训练的第一步是搭建网络和计算图。文字 识别实质上是一个多分类任务,识别 1 000 个不同的文字, 相当于 1 000 个类别的分类任务。在搭建的网络中加入 batch normalization。 另 外 损 失 函 数 选 择 sparse_soft⁃ max_cross_entropy_with_logits,优化器选择 Adam,学习率设 为 0.1,实现代码如下:
#network: conv2d->max_pool2d->conv2d->max_pool2d->
conv2d->max_pool2d->conv2d->conv2d->max_pool2d->ful⁃
ly_connected->fully_connected
#给 slim.conv2d 和 slim.fully_connected 准 备 了 默 认 参 数 :
batch_norm
with slim.arg_scope([slim.conv2d,slim.fully_connected],
normalizer_fn=slim.batch_norm,
normalizer_params={'is_training':is_training}):
conv3_1 = slim.conv2d(images,64,[3,3],1,padding=
'SAME',scope='conv3_1')
max_pool_1 = slim.max_pool2d(conv3_1,[2,2],[2,2],
padding='SAME',scope='pool1')
conv3_2 = slim.conv2d(max_pool_1,128,[3,3],padding=
'SAME',scope='conv3_2')
max_pool_2 = slim.max_pool2d(conv3_2,[2,2],[2,2],
padding='SAME',scope='pool2')
conv3_3 = slim.conv2d(max_pool_2,256,[3,3],padding=
'SAME',scope='conv3_3')
max_pool_3 = slim.max_pool2d(conv3_3,[2,2],[2,2],
padding='SAME',scope='pool3')
conv3_4 = slim.conv2d(max_pool_3,512,[3,3],padding=
'SAME',scope='conv3_4')
conv3_5 = slim.conv2d(conv3_4,512,[3,3],padding=
'SAME',scope=‘conv3_5’)
max_pool_4 = slim.max_pool2d(conv3_5,[2,2],[2,2],
padding='SAME',scope='pool4')
flatten = slim.flatten(max_pool_4)
fc1 = slim.fully_connected(slim.dropout(flatten,keep_prob),
1024,
activation_fn=tf.nn.relu,scope='fc1')
logits = slim.fully_connected(slim.dropout(fc1,keep_prob),
FLAGS.charset_size,activation_fn=None,scope='fc2')
# 因为没有做热编码,所以使用 sparse_softmax_cross_entro⁃
py_with_logits
loss = tf.reduce_mean (tf.nn.sparse_softmax_cross_entro⁃
py_with_logits(logits=logits,labels=labels))
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(logits,
1),labels),tf.float32))
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
if update_ops:
updates = tf.group(*update_ops)
loss = control_flow_ops.with_dependencies([updates],loss)
global_step = tf.get_variable("step",[],initializer=tf.con⁃
stant_initializer(0.0),trainable=False)
optimizer = tf.train.AdamOptimizer(learning_rate=0.1)
train_op = slim.learning.create_train_op(loss,optimizer,glob⁃
al_step=global_step)
probabilities = tf.nn.softmax(logits)2、模型训练
训练之前需先设计好数据,为高效地进行网络训练作 好铺垫。主要步骤如下:
(1)创建数据流图。该图由一些流水线阶段组成,阶 段间用队列连接在一起。第一阶段将生成并读取文件名, 并将其排到文件名队列中;第二阶段从文件中读取数据 (使用 Reader),产生样本且把样本放在一个样本队列中。
根据不同的设置,或者拷贝第二阶段的样本,使其相 互独立,因此可以从多个文件中并行读取。在第二阶段排 队操作,即入队到队列中去,在下一阶段出队。因为将开 始运行这些入队操作的线程,所以训练循环会使样本队列 中的样本不断出队,如图所示。
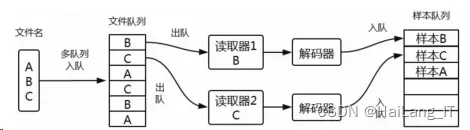
样本队列的入队操作在主线程中进行,Session 中可以 多个线程一起运行。在数据输入的应用场景中,入队操作 从硬盘中读取输入进行,再放到内存中,速度较慢。使用 QueueRunner 可以创建一系列新的线程进行入队操作,让 主线程继续使用数据。如果在训练神经网络的场景中,则 训练网络和读取数据异步,主线程在训练网络时,另一个 线程再将数据从硬盘读入内存。
训练时数据读取模式如上所述,则训练代码设计为:
with tf.Session (config=tf.ConfigProto (gpu_options=gpu_op⁃
tions,allow_soft_placement=True))as sess:
# batch data 获取
train_images, train_labels = train_feeder.input_pipeline
(batch_size=FLAGS.batch_size,aug=True)
test_images, test_labels = test_feeder.input_pipeline
(batch_size=FLAGS.batch_size)
graph = build_graph(top_k=1) # 训练时 top k = 1
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
# 设置多线程协调器
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess,coord=co⁃
ord)
train_writer = tf.summary.FileWriter(FLAGS.log_dir + '/train',
sess.graph)
test_writer = tf.summary.FileWriter(FLAGS.log_dir + '/val')
start_step = 0(2)指令执行。设置最大迭代步数为 16 002,每 100 步进行一次验证,每 500 步存储一次模型。 训练过程的损失函数 loss 和精度函数 accuracy 变换 曲线如图所示。
loss 变换曲线: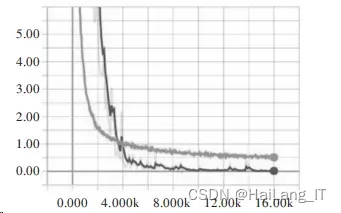
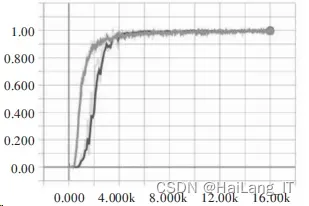
损失(loss)和精度(accuracy)是用于衡量模型预测偏 离其训练对象期望值的衡量指标,从图可以看出 loss 和 accuracy 最大值分别稳定在 0.05、0.9 左右,说明模 型训练顺利完成,已具备替代训练对象进行文字识别工作 的能力。
(3)模型性能评估。在对模型进行训练调试之后,再 对模型性能进行评估,计算模型 top 1(识别结果的第一个 是正确的概率)和 top 5(识别结果的前 5 个中有正确结果 的概率)的准确率,使模型应用效果达到最佳。计算模型 top 1 和 top 5 准确率的代码为:
i = 0
acc_top_1,acc_top_k = 0.0,0.0
while not coord.should_stop():
i += 1
start_time = time.time()
test_images_batch,test_labels_batch = sess.run([test_imag⁃
es,test_labels])
feed_dict ={graph[‘images’]:test_images_batch,
graph[‘labels’]:test_labels_batch,
graph[‘keep_prob’]:1.0,
graph[‘is_training’]:False}
batch_labels,probs,indices,acc_1,acc_k = sess.run([graph
[‘labels’],
graph[‘predicted_val_top_k’],
graph[‘predicted_index_top_k’],
graph[‘accuracy’],
graph[‘accuracy_top_k’]],
feed_dict=feed_dict)
final_predict_val += probs.tolist()
final_predict_index += indices.tolist()
groundtruth += batch_labels.tolist()
acc_top_1 += acc_1
acc_top_k += acc_k
end_time = time.time()
logger.info(“the batch{0}takes{1}seconds,accuracy ={2}
(top_1){3}(top_k)”
.format(i,end_time - start_time,acc_1,acc_k))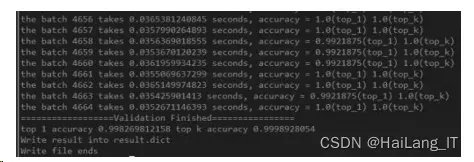
从图中可以看出,识别模型 top 1 和 top 5 分别达到了 99.8%、99.9%,识别准确率很高。
实验结果
从某文档中截取出一段文字以图片格式保存,再使用 文字切割算法把文字段落切割为单字,如图所示。
文字截取:
文字段落切割为单字:

对文字段落进行识别,由于使用的是 GPU,识别速度 非常快,除去系统初始化时间,全部图像识别时耗不超过 1s。其中输出的信息分别是:当前识别的图片路径、模型预 测出的 top 3 汉字(置信度由高到低排列)、对应的汉字 ID、 对应概率。在识别完成之后,将所有识别文字按顺序组合 成原始段落排列,如图所示。
文字段落识别结果 1:
文字段落识别结果 2:

从图中可以看出单字的识别非常准确,在最后显示的 文字段落识别结果中可以看到仅个别文字识别出现偏差, 整体识别效果佳,说明该模型的识别能力可满足一般实际 场景印刷体文字识别要求。
三、总结
经过测试,基于深度学习的图像文字识别模型在模型 评估上 top 1 的正确率达到了 99.8%。与传统 OCR 相比, 基于深度学习的 OCR 技术在识别准确率方面有大幅上 升。在一些比较理想的环境下,文字识别效果较好,但是 处理复杂场景或一些干扰比较大的文字图像时,识别效果 有待提高,后续将对模型作进一步优化。 随着 OCR 技术的迅猛发展,文本检测和识别技术将拓 展更多语言支持。从图像中提取文字对于图像高层次语 义理解、索引和检索意义重大。结合深度学习的神经网络 和 NPL 语义分析提升 OCR 识别纠错能力,帮助个体提升效率、创造价值,是未来重要发展趋势。
实现效果图样例
图像文字识别系统:
我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!
最后
文章出处登录后可见!