什么是BERT

BERT是一种预训练语言模型(pre-trained language model, PLM),其全称是Bidirectional Encoder Representations from Transformers。
BERT 在自然语言处理(NLP)领域刷新了 11 个任务的记录,万众瞩目,成为异常火热的一个预训练语言模型。但是 BERT 并不是一个具有极大创新的算法,更多的是一个集大成者,把 BERT 之前各个语言模型的优点集于一身,并作出了适当的改进,而拥有了如今无与伦比的能力。
集大成与创新
BERT 作为一个预训练语言模型,它的预训练思想借鉴了CV领域中的预训思想;
作者借鉴了完形填空任务的思想(双向编码),实则也借鉴了 Word2Vec 的 CBOW 的思想,两者本质上是相同的;
没有使用传统的类 RNN 模型作为特征提取器(ELMo),而是使用了 Transformer 用于特征提取,充分发挥了attention的作用;
真要说创新,也许就是在 CBOW 的思想之上,添加了语言掩码模型(MLM),并减少了训练阶段和推理阶段(微调阶段)的不匹配,避免了过拟合;
由于单词预测粒度的训练到不了句子关系这个层级,为了学会捕捉句子之间的语义联系,BERT 采用了下句预测(NSP )作为无监督预训练的一部分,这也算是BERT的创新。

与ELMo和GPT相比BERT的优势
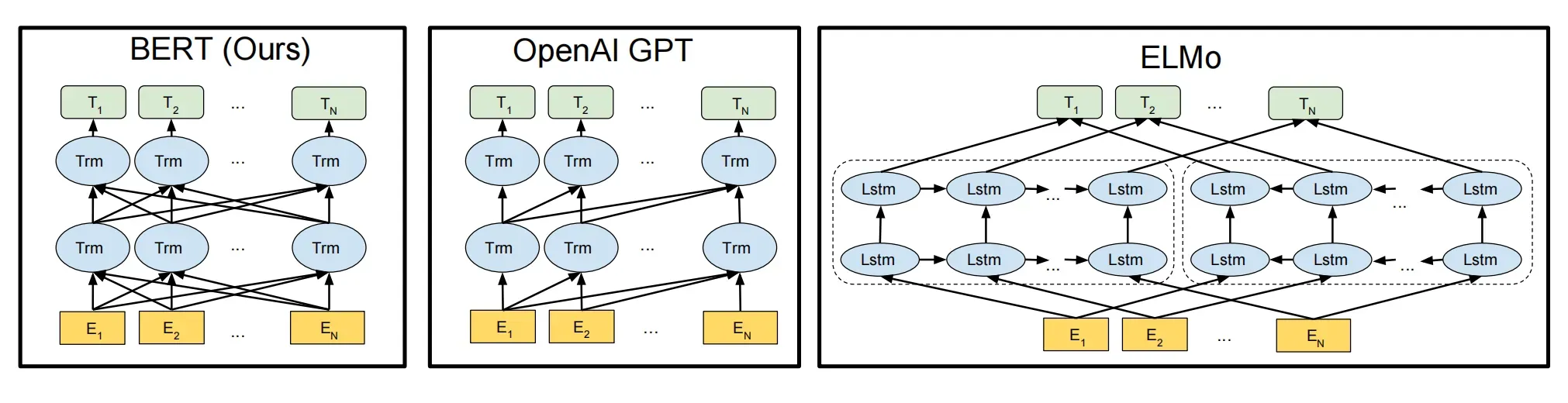
ELMo使用自左向右编码和自右向左编码的两个 LSTM 网络,分别以![]() 和
和![]() 作为目标函数独立训练,将训练得到的特征向量以拼接的形式实现双向编码,本质上还是单向编码,只不过是两个方向上的单向编码拼接而成的双向编码。
作为目标函数独立训练,将训练得到的特征向量以拼接的形式实现双向编码,本质上还是单向编码,只不过是两个方向上的单向编码拼接而成的双向编码。
GPT 使用 Transformer Decoder 作为 Transformer Block,它以![]() 为目标函数,用 Transformer Block 取代 LSTM 作为特征提取器,实现了单向编码,是一个标准的预训练语言模型,即使用 Fine-Tuning 模式解决下游任务。
为目标函数,用 Transformer Block 取代 LSTM 作为特征提取器,实现了单向编码,是一个标准的预训练语言模型,即使用 Fine-Tuning 模式解决下游任务。
BERT 也是一个标准的预训练语言模型,它以 ![]() 为目标函数进行训练,BERT 使用的编码器属于双向编码器。
为目标函数进行训练,BERT 使用的编码器属于双向编码器。
区别:
BERT 和 ELMo 的区别在于使用 Transformer Block 作为特征提取器,加强了语义特征提取的能力;
BERT 和 GPT 的区别在于使用 Transformer Encoder 作为 Transformer Block,并且将 GPT 的单向编码改成双向编码,也就是说 BERT 舍弃了文本生成能力,换来了更强的语义理解能力。
优势:
作为一种预训练模型,BERT在特定场景使用时不需要用大量的语料来进行训练,泛化能力较强;
BERT是一种端到端(end-to-end)的模型,不需要我们调整网络结构,使用简单,只需要在最后加上用于不同下游任务的输出层;
基于Transformer,可以实现快速并行,也可以不断增加网络深度,充分发掘DNN模型的特性,提升模型准确率;
和ELMO,GPT等其他预训练模型相比,BERT是一种双向的模型,结合上下文来进行训练,具有更好的性能;
BERT的结构
BERT有两种size:
![]()
![]()
其中,L:Transformer blocks 层数;H:hidden size;A:the number of self-attention heads
base版一共有110M参数,large版有340M的参数,也就是说,不论是base还是large,BERT的参数量都是上亿的,这个量还是相当大的。
BERT的输入
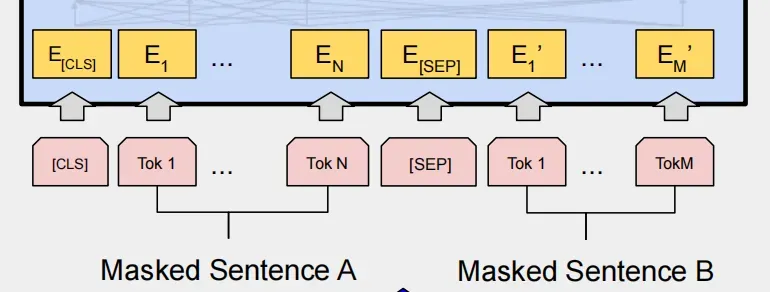
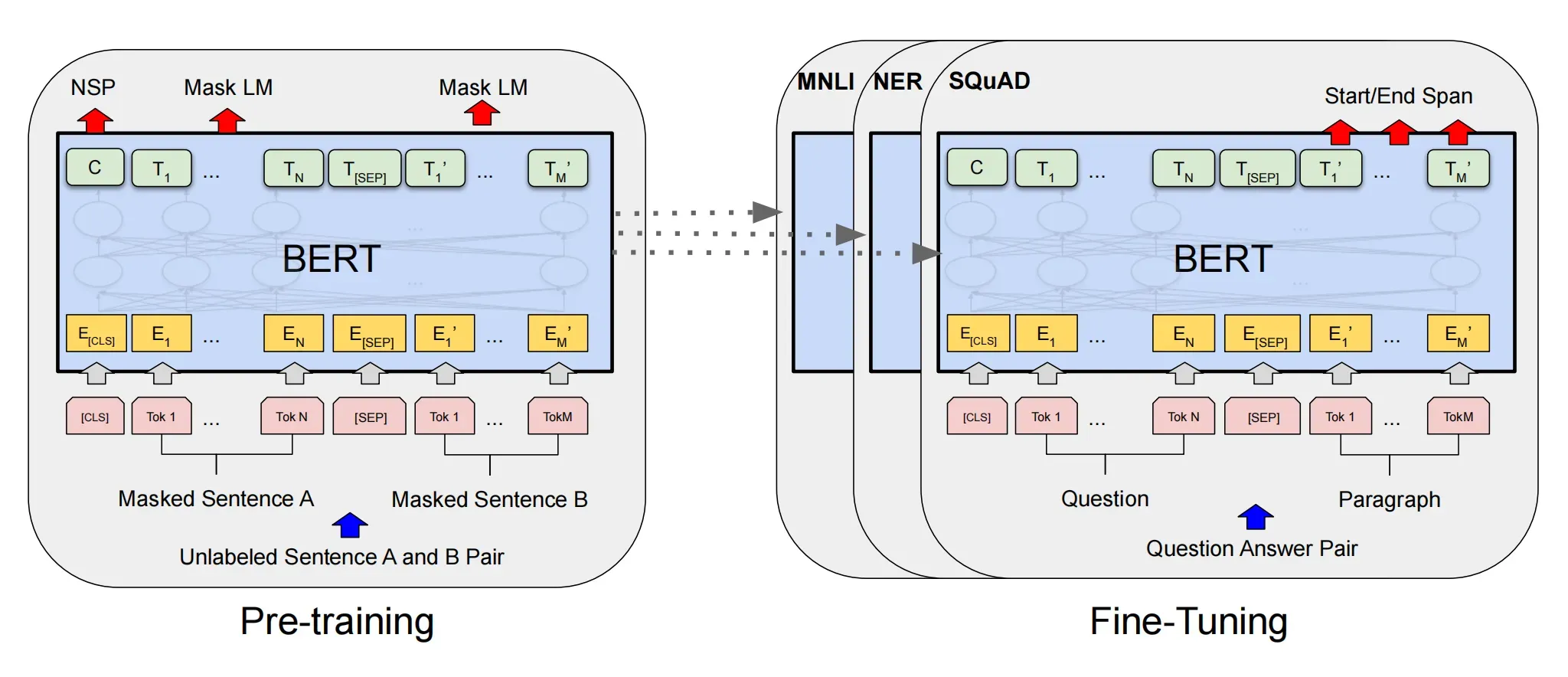
BERT的输入为每一个token对应的表征(图中的粉红色块就是token,黄色块就是token对应的表征),其中单词字典是采用WordPiece算法来进行构建的。为了完成具体的分类任务,除了单词的token之外,作者还在输入的每一个序列开头都插入特定的分类token([CLS]),该分类token对应的最后一层Transformer的输出被用来起到聚集整个序列表征信息的作用。在序列tokens中把分割token([SEP])插入到每个句子后,以分开不同的句子tokens。
每一个token对应的表征,实际上是由三部分组成的,分别是对应的token,分割 embeddings和位置 embeddings:
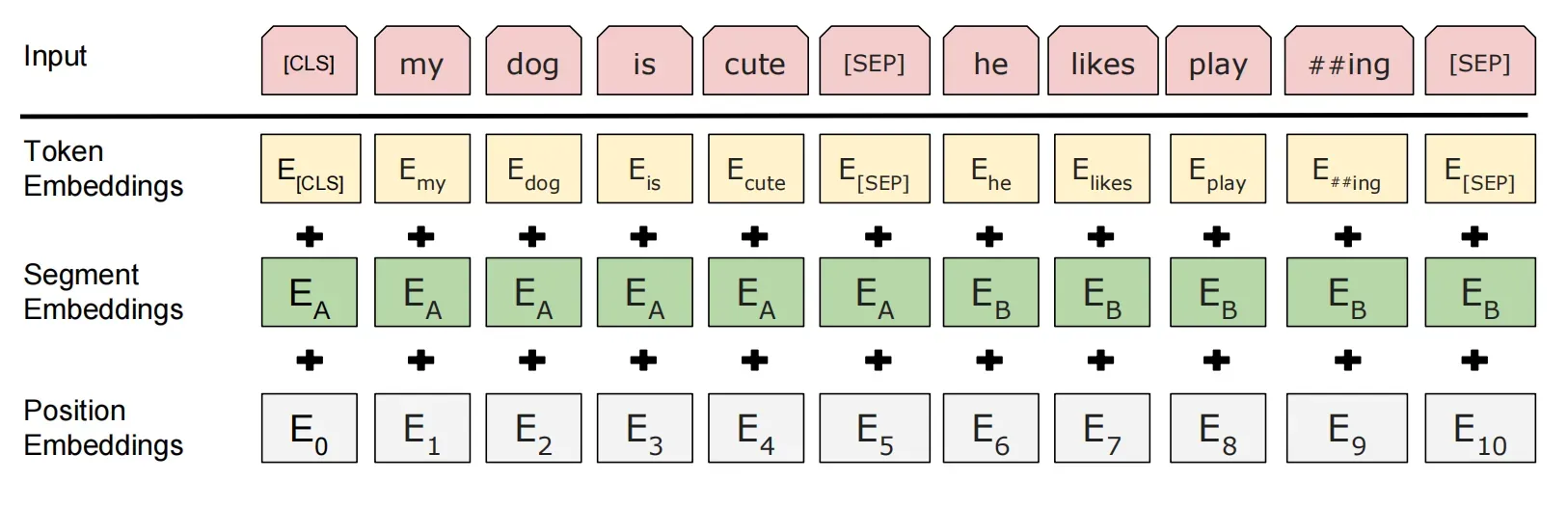
token embeddings:将各个词转换成固定维度的向量。在BERT中,每个词会被转换成768维的向量表示。在实际代码实现中,输入文本在送入token embeddings 层之前要先进行tokenization处理。此外,两个特殊的token会被插入到tokenization的结果的开头 ([CLS])和结尾 ([SEP])
segment embeddings: 用于区分一个token属于句子对中的哪个句子。Segment Embeddings 层只有两种向量表示。前一个向量是把0赋给第一个句子中的各个token, 后一个向量是把1赋给第二个句子中的各个token。如果输入仅仅只有一个句子,那么它的segment embedding就是全0 。
position embeddings:Transformers无法编码输入的序列的顺序性,所以要在各个位置上学习一个向量表示来将序列顺序的信息编码进来。加入position embeddings会让BERT理解下面这种情况:“ I think, therefore I am ”,第一个 “I” 和第二个 “I”应该有着不同的向量表示。
这3种embedding都是768维的,最后要将其按元素相加,得到每一个token最终的768维的向量表示。
BERT的输出
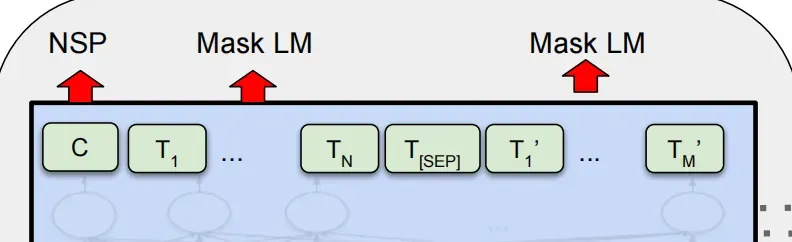
BERT最终输出的就是句子中每个token的768维的向量,第一个位置C为分类token([CLS])对应的最后一层Transformer的输出,它的向量表示蕴含了这个句子整体的信息。![]() 则代表其他token对应的最后层Transformer的输出。对于一些token级别的任务(如:序列标注和问答任务),就把
则代表其他token对应的最后层Transformer的输出。对于一些token级别的任务(如:序列标注和问答任务),就把![]() 输入到额外的输出层中进行预测。对于一些句子级别的任务(如:自然语言推断和情感分类任务),就把C输入到额外的输出层中,这里也就解释了为什么要在每一个token序列前都要插入特定的分类token。
输入到额外的输出层中进行预测。对于一些句子级别的任务(如:自然语言推断和情感分类任务),就把C输入到额外的输出层中,这里也就解释了为什么要在每一个token序列前都要插入特定的分类token。
BERT的预训练
实际上预训练的概念在CV中已经是很成熟了,应用十分广泛。CV中所采用的预训练任务一般是ImageNet图像分类任务,完成图像分类任务的前提是必须能抽取出良好的图像特征,同时ImageNet数据集有规模大、质量高的优点,因此常常能够获得很好的效果。
虽然NLP领域没有像ImageNet这样质量高的人工标注数据,但是可以利用大规模文本数据的自监督性质来构建预训练任务。因此BERT构建了两个预训练任务,分别是Masked Language Model和Next Sentence Prediction。
Masked Language Model
Masked LM 可以形象地称为完形填空问题,随机掩盖掉每一个句子中15%的词,用其上下文来去判断被盖住的词原本应该是什么。举例来说:有这样一个未标注句子 my dog is hairy ,我们可能随机选择了hairy进行遮掩,就变成 my dog is [mask] ,训练模型去预测 [mask] 位置的词,使预测出 hairy的可能性最大,在这个过程中就将上下文的语义信息学习并体现到模型参数中去了。
然而,由于[MASK]并不会出现在下游任务的微调(fine-tuning)阶段,因此预训练阶段和微调阶段之间产生了不匹配(这里很好理解,就是预训练的目标会令产生的语言表征对[MASK]敏感,但是却对其他token不敏感)。
因此BERT采用了以下策略来解决这个问题:
首先在每个训练序列中以15%的概率随机地选中某个token位置用于预测,假如是第i个token被选中,则会被替换成以下三个token之一
80%的时候是[MASK]。如:my dog is hairy——>my dog is [MASK]
10%的时候是随机的其他token。如:my dog is hairy——>my dog is apple
10%的时候是原来的token。如:my dog is hairy——>my dog is hairy
再用该位置对应的 Ti去预测出原来的token(输入到全连接,然后用softmax输出每个token的概率,最后用交叉熵计算loss)。
该策略令到BERT不再只对[MASK]敏感,而是对所有的token都敏感,以致能抽取出任何token的表征信息。
综上三个特点,在正确的信息(10%)、未知的信息(80% MASK,使模型具有预测能力)、错误的信息(加入噪声10%,使模型具有纠错能力)都有的情况下,模型获取了全局全量的信息。
Next Sentence Prediction
一些如问答、自然语言推断等任务需要理解两个句子之间的关系,而MLM任务倾向于抽取token层次的表征,因此不能直接获取句子层次的表征。为了使模型能够有能力理解句子间的关系,BERT使用了NSP任务来预训练,简单来说就是预测两个句子是否连在一起。
具体的做法是:对于每一个训练样例,我们在语料库中挑选出句子A和句子B来组成,50%的时候句子B就是句子A的下一句(标注为IsNext),剩下50%的时候句子B是语料库中的随机句子(标注为NotNext)。接下来把训练样例输入到Bert模型中,用[CLS]对应的C信息去进行二分类的预测。
训练样例如下:
Input1=[CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Label1=IsNext
Input2=[CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label2=NotNext
把每一个训练样例输入到BERT中可以相应获得两个任务对应的loss,再把这两个loss加在一起就是整体的预训练loss。(也就是两个任务同时进行训练)
可以明显地看出,这两个任务所需的数据其实都可以从无标签的文本数据中构建(自监督性质),比CV中需要人工标注的ImageNet数据集可简单多了。
整理:
https://zhuanlan.zhihu.com/p/98855346
文章出处登录后可见!