目录
- 一、系统环境
- 二、数据准备及预处理
- 三、使用Stable Diffusion获取图像信息
- 四、安装训练图形化界面
- 五、参数设置及训练过程
- 六、 效果测试
- 七、常见报错处理
一、系统环境
同上一篇博客,云平台:CPU 1核,GPU 0.5卡,内存 20G;python版本:3.10
准备两个Terminal页面备用,一个打开上一篇博客已经装好的SD WebUI,一个我们安装训练图形化界面kohya_ss,都启动虚拟环境py310。
二、数据准备及预处理
网络上的建议:
- 至少15张图片,每张图片的训练步数不少于100。
- 照片人像要求多角度,特别是脸部特写(尽量高分辨率),多角度,多表情,不同灯光效果,不同姿势等
- 图片构图尽量简单,避免复杂的其他因素干扰
- 可以单张脸部特写+单张服装按比例组成的一组照片(这里比例是3:1)
- 减少重复或高度相似的图片,避免造成过拟合
- 图片解析:stable diffusion webui
- (可选)编辑tag:kohay_ss的Utilities下的Captioning批量给我们处理后的解析词文件增加对应的角色tag和服饰tag或者使用软件
实际训练准备:
-
图片收集(打开我电脑中 《紫罗兰永恒花园》主角姬圈天菜·战力爆棚·人美心善的薇尔莉特 的收藏夹),选二十张图片(主要是头部,包括正面、侧面、抬头、低头等角度),来一张镇楼:

-
批量裁剪,统一格式为512×512,jpg格式(其实格式可以随意,在SD中能够一并转换为png),可以使用Birme网站,非常方便快捷。
三、使用Stable Diffusion获取图像信息
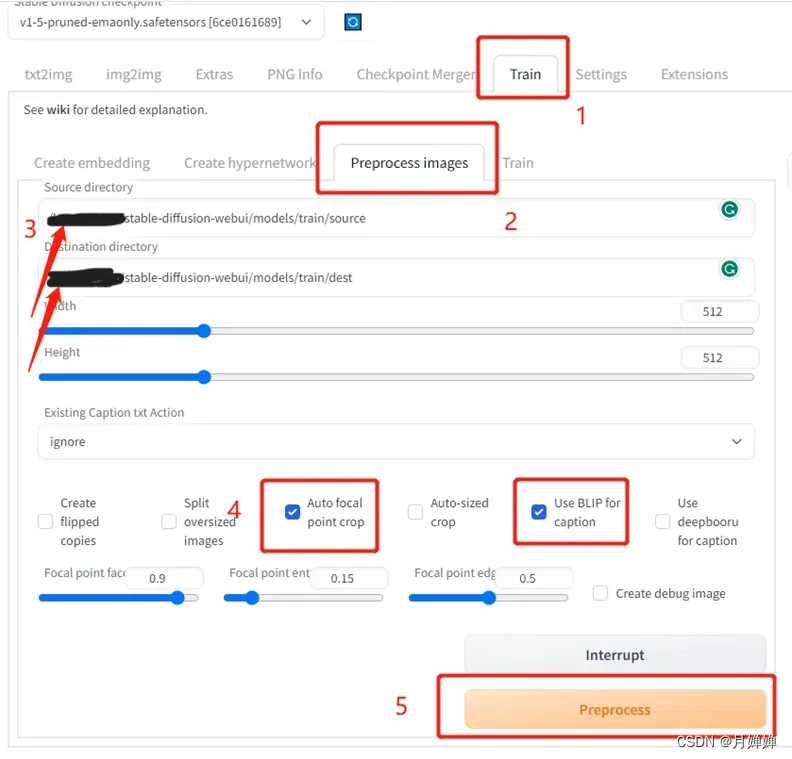
- 在stable-diffusion-webui/models/下新建一个train文件夹,存放原始图片文件夹source,预处理后图片信息文件夹dest
- 打开Stable Diffusion webui界面,设置process images,粘贴文件夹位置,选择参数
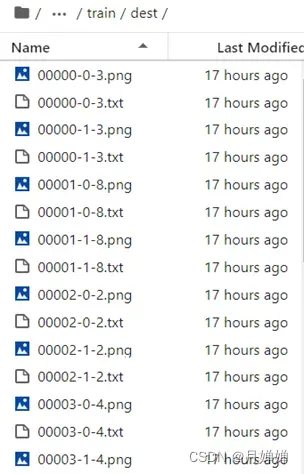
- 处理后的dest文件夹,txt放的是sd中的BLIP模型对图片的文本描述(个人感觉比较简陋,但是也许简易的内容才能不限制创造力的发挥?)
- 举个栗子,你也可以每个txt文件都加点自己的描述,或者使用BooruDatasetTagManager数据集标注工具

Pompt: a painting of a boat in a body of water with mountains in the background and fog in the sky
四、安装训练图形化界面
- 在另外一个启动了py310的Terminal界面,git下载基于gradio的kohya_ss训练图形化界面。
git clone https://github.com/bmaltais/kohya_ss.git
- 打开对应的文件夹,执行accelerate config命令
cd /home/share/kohya_ss
accelerate config
- 按需回答问题,比如:

- 打开webui界面
python kohya_gui.py --listen 0.0.0.0 --server_port 7861 --inbrowser --share
- 可能会报错:
AttributeError: module 'gradio' has no attribute 'themes',更新gradio即可
pip install gradio --upgrade
- 复制你的网络链接,用浏览器打开如下图所示,说明安装OK啦!
五、参数设置及训练过程
本文如标题所示,是使用Lora训练,其他的训练方法例如Dreambooth,可以参考此篇博客Stable Diffusion 绘图了解详情~
- 在stable-diffusion-webui/models/train下新建image、model、log文件夹,将分别存放预处理后的图片及描述文档、训练的模型以及系统日志文件
重点:
在image下新建“单个图片训练次数_任意命名”文件夹,例如单张图片训练100次,命名为mr,则该文件夹名设置为“100_mr“,接着再将dest文件夹中的所有内容复制到100_mr文件夹下( 源代码在loraui.py文件中,通过split函数来获取训练次数repeats,所以千万不要设置错误 )。此外,根据资料,lora最低训练总次数是1500次,为了避免过拟合,尽量图片在15张及以上,15张对应单张训练100次,10张对应单张训练150次。
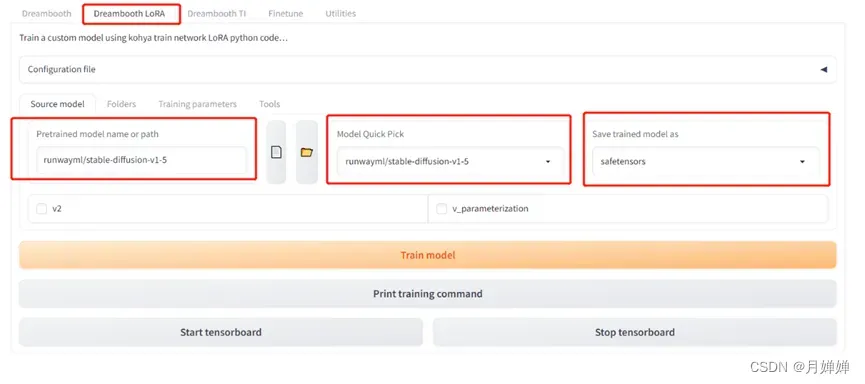
- 参数设置,找网上推荐的参数配置的位置找得我脑袋疼~~>_<~~
简而言之:
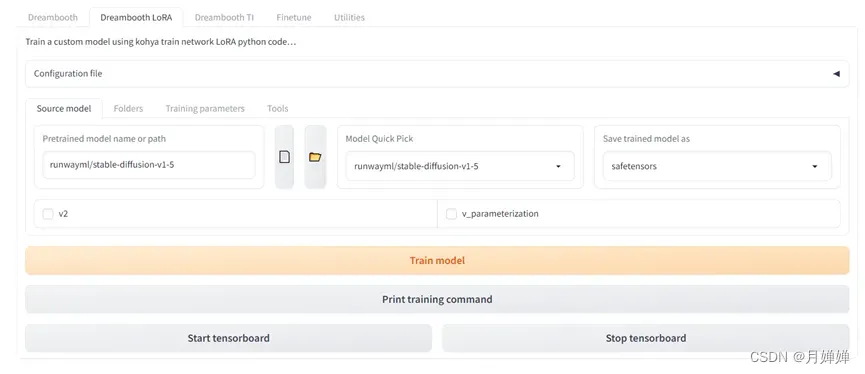
a. 打开对应训练方法的参数配置界面Dreambooth LoRA
b. Folders首先复制三个文件夹到对应位置,接着命名输出模型
c. 至于Training Parameters设置,综合网上的资料+个人训练效果,感觉默认参数对配置要求不高,如果是小白,默认就足够了,大佬估计看看名称也知道调什么能出更好的效果(比如训练批次、学习率这些)。
- 设置完后点一下gui页面中的train model按钮开始训练,回到terminal中可以看到如下画面:

- 训练结束后,打开model文件夹或者执行
ls -lh就可以看到训练后的文件

六、 效果测试
- 将生成的safetensors文件复制到
stable-diffusion-webui/models/Lora文件夹下,重启一下Stable Diffusion WeuUI,然后点击“Show Extra Network”按钮。在Lora标签里选择刚生成的Lora模型,在上方Prompt框里会显示Lora模型已经使用,两端有尖括号,填入提示词即可生成相应的图片。
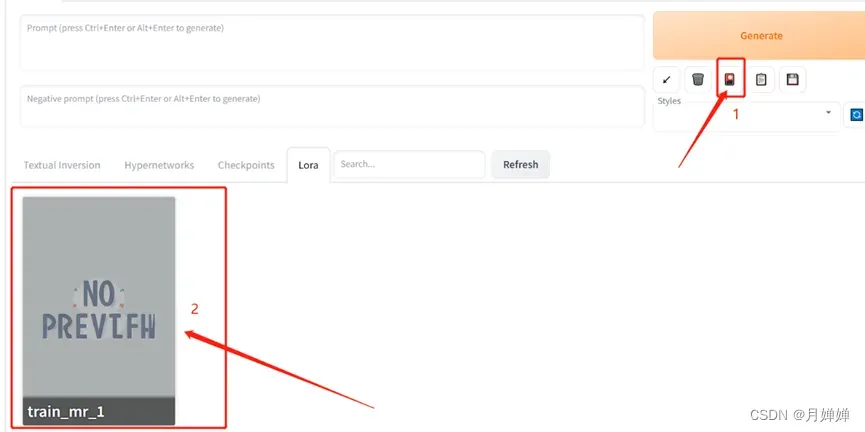
- 举个栗子:(Sampling Steps越大,越像原始数据集)
Prompt:a girl with blonde hair and blue eyes standing in front of a blue sky with clouds and a green eye and windy day and sunshine and butterflies < lora:last:1 >

效果完全不及京阿尼的画师(不过我也不希望AI取代人类,还是非常尊重原创的,此文只是为了熟悉一个新兴的技术)。另外,私以为也不是完全没有优化的空间,有几个思路都可尝试:更换预训练模型(这里我用的是SD v1.5,但肯定有针对漫画人物训练的ckpt)、增加训练批次、使用更合适的优化器等等。
七、常见报错处理
某人的痛苦回忆录
- 用两个terminal分别打开sd和kohya_ss页面,如果先运行kohya_ss可能会更新一些必须的库,导致sd卡在配置requirements一处,可以单独在sd的terminal中运行下面的代码(不要打成requirements.txt!)。安装结束后,再
sh webui.sh --share启动sd。
pip install -r requirements_versions.txt
ValueError: invalid literal for int() with base 10: '.ipynb'‘
cd ./stable-diffusion-webui/models/train/image_violet/
ls -la
发现数据文件夹中存在.ipynb_checkpoints,“.”的存在会影响int使用,删除这个checkpoints文件,重新点train model即可
rm -rf .ipynb_checkpoints
find . -name ".ipynb_checkpoints" -exec rm -rf {} \;
NameError: name 'split' is not defined
关闭url,重新运行
python kohya_gui.py --listen 0.0.0.0 --server_port 7861 --inbrowser –share
AttributeError: module 'gradio' has no attribute 'themes'更新gradio
pip install gradio --upgrade
ValueError: SchedulerType.CONSTANT does not require num_warmup_steps. Set None or 0
当LR Scheduler为constant的时候,不需要设置LR warmup
修改成cosine,LR warmup设置为10(即默认设置)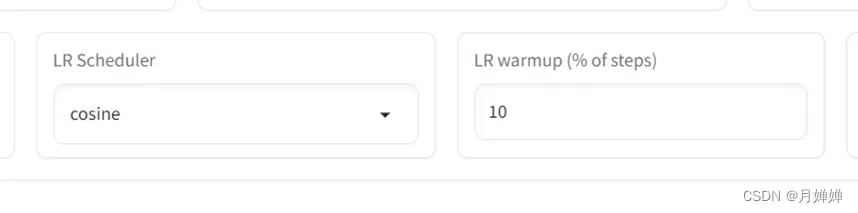
OSError: Port 7861 is in use. If a gradio.Blocks is running on the port, you can close() it or gradio.close_all().
换个端口号(比如7863)重新运行subprocess.CalledProcessError: Command '['./envs/py310/bin/python', 'train_network.py', '--enable_bucket','.....']' returned non-zero exit status 1
不要用AdamW8bit,用AdamW就行(也是默认设置,所以像我一样的小白,不要一开始就调参,会非常痛苦)
文章出处登录后可见!
已经登录?立即刷新