文章目录
- 1. 多线程
- 2. 创建线程
- 2.1 直接创建
- 2.2 继承创建
- 3. 守护线程
- 4. 阻塞线程
- 5. 线程锁
- 5.1 互斥锁(Lock)
- 5.2 递归锁(RLock)
- 5.3 信号量(Semaphore)
- 5.4 事件(Event)
- 6. ThreadLocal
- 7. 线程池
- 7.1 基本使用
- 7.2 as_completed 方法
- 7.3 wait方法
- 7.4 map方法
- 8. Python线程真相
- 参考文章
1. 多线程
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。Python中的程序默认是只有一个主线程的,也就是说,执行程序的时候,你写的代码都是串行执行的,CPU利用率可能并没有得到很好的利用,还有很多的空闲,而这个时候利用多线程,将程序改为并行的话,CPU利用率将会大大提升,程序速度也就能大大增快。
Python处理线程的模块有两个:thread 和 threading。Python 3已经停用了 thread 模块,并改名为 _thread 模块。Python 3在 _thread 模块的基础上开发了更高级的 threading 模块,因此以下的讲解都是基于 threading 模块。
threading 模块除了包含 _thread 模块中的所有方法外,还提供的其他方法,常用的方法如下:
| 方法 | 描述 |
|---|---|
threading.current_thread() | 返回当前线程的信息 |
threading.enumerate() | 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。 |
threading.active_count() | 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果 |
测试如下:
import threading
if __name__ == "__main__":
print("当前活跃线程的数量", threading.active_count())
print("将当前所有线程的具体信息展示出来", threading.enumerate())
print("当前的线程的信息展示", threading.current_thread())
输出结果:
当前活跃线程的数量 1
将当前所有线程的具体信息展示出来 [<_MainThread(MainThread, started 13228)>]
当前的线程的信息展示 <_MainThread(MainThread, started 13228)>
2. 创建线程
创建线程的方法有两种,一种是直接使用 threading 模块里面的类来进行创建,一种是继承 threading 模块的类写一个类来对线程进行创建。
2.1 直接创建
我们可以通过直接从 threading.Thread 继承创建一个新的子类,并实例化后调用 start() 方法启动新线程,即相当于它调用了线程的 run() 方法。
该方法的参数如下:
threading.Thread(target=None, name=None, args=(), kwargs={})
target 指要创建的线程的方法名,name 指给此线程命名,命名后可以调用 threading.current_thread().name 方法输出该线程的名字, args/kwargs 指 target 指向的方法需要传递的参数,必须是元组形式,如果只有一个参数,需要以添加逗号。
假如我们创建两个线程,一个每隔两秒对传入的数加2,一个每隔1秒对传入的数加1,代码示例如下:
import threading
import time
def job1(num):
while True:
num += 2
print('{} is running >> {}'.format(threading.current_thread().name, num))
time.sleep(2)
new_job = threading.Thread(target=job1, name='Add2', args=(100,))
new_job.start()
n = 1
while True:
n += 1
print('{} is running >> {}'.format(threading.current_thread().name, n))
time.sleep(1)
输出如下:
Add2 is running >> 102
MainThread is running >> 2
MainThread is running >> 3
Add2 is running >> 104
MainThread is running >> 4
MainThread is running >> 5
Add2 is running >> 106
MainThread is running >> 6
MainThread is running >> 7
Add2 is running >> 108
MainThread is running >> 8
MainThread is running >> 9
Add2 is running >> 110
……
2.2 继承创建
第二种继承的方式来创建一个线程类,继承这个类后,必须要重写其中的 run 方法,也就相当于上述的直接创建中的 start 方法。
下面我用继承类的方式实现与上面的效果一样的多线程。
import threading
import time
class MyThread(threading.Thread):
def __init__(self, n):
super().__init__() #必须调用父类的初始化方法
self.n = n
def run(self) -> None:
while True:
self.n += 2
print('{} is running >> {}'.format(threading.current_thread().name, self.n))
time.sleep(2)
new_job = MyThread(100)
new_job.setName("Add2")
new_job.start()
n = 1
while True:
n += 1
print('{} is running >> {}'.format(threading.current_thread().name, n))
time.sleep(1)
输出与以上输出一致。
3. 守护线程
上面第二节中,我只设置了一个子线程,为什么会有两个线程在分别运行呢?原因就是该程序在启动时都会有一个主线程在进行运行,而我们创建的线程统统都称之为子线程,当我们创建了一个子线程时,加上主线程,就已经有两个线程了。明白了主线程与子线程后,我们再来介绍守护线程。
如果当前python线程是守护线程,那么意味着这个线程是“不重要”的,“不重要”意味着如果他的主线程结束了但该守护线程没有运行完,守护线程就会被强制结束。如果线程是非守护线程,那么父进程只有等到非守护线程运行完毕后才能结束。
- 只要当前 主线程中尚存任何一个非守护线程没有结束,守护线程就全部工作;
- 只有当最后一个非守护线程结束是,守护线程随着主线程一同结束工作。
-
设置全部子线程为守护线程
下面我们设置两个子线程一个子线程每隔1秒加1,一个线程每隔2秒加2,两个子线程都设置为守护线程,主线程等待3秒后结束,看看输出的情况。
import threading import time # 每1秒加1 def job1(num): while True: num += 1 print('{} is running >> {}'.format(threading.current_thread().name, num)) time.sleep(1) # 每2秒加2 def job2(num): while True: num += 2 print('{} is running >> {}'.format(threading.current_thread().name, num)) time.sleep(2) # 线程1,一秒加一 new_job1 = threading.Thread(target=job1, name='Add1', args=(100,)) # 设置为守护线程 new_job1.setDaemon(True) new_job1.start() # 线程2,两秒加二 new_job2 = threading.Thread(target=job2, name='Add2', args=(1,)) new_job2.setDaemon(True) new_job2.start() # 主线程等待3秒 time.sleep(3) print('{} Ending'.format(threading.current_thread().name))输出如下:
Add1 is running >> 101
Add2 is running >> 3
Add1 is running >> 102
Add2 is running >> 5
Add1 is running >> 103
MainThread Ending可以看到,随着输出
MainThread Ending后,程序就运行结束了,这表明子线程全为守护线程时,会随着主线程的结束而强制结束。 -
一个子线程为守护线程,另一个设为非守护线程
下面我们同样设置两个子线程一个子线程每隔1秒加1,一个线程每隔2秒加2,不同的是,一个子线程设为非守护线程,另一个子线程设为守护线程,主线程等待3秒后结束,看看输出的情况。
import threading import time # 每1秒加1 def job1(num): while True: num += 1 print('{} is running >> {}'.format(threading.current_thread().name, num)) time.sleep(1) # 每2秒加2 def job2(num): while True: num += 2 print('{} is running >> {}'.format(threading.current_thread().name, num)) time.sleep(2) # 线程1,一秒加一 new_job1 = threading.Thread(target=job1, name='Add1', args=(100,)) new_job1.start() # 线程2,两秒加二 new_job2 = threading.Thread(target=job2, name='Add2', args=(1,)) # 设置为守护线程 new_job2.setDaemon(True) new_job2.start() # 主线程等待3秒 time.sleep(3) print('{} Ending'.format(threading.current_thread().name))输出结果如下:
Add1 is running >> 101
Add2 is running >> 3
Add1 is running >> 102
Add1 is running >> 103
Add2 is running >> 5
MainThread Ending
Add1 is running >> 104
Add2 is running >> 7
Add1 is running >> 105
Add1 is running >> 106
Add2 is running >> 9
Add1 is running >> 107
Add1 is running >> 108可以看到,上面的主线程结束后,两个子线程并没有结束,这也表明了守护线程会等到非守护线程执行完毕后再被杀死。
需要注意的是, setDaemon 必须写在 start 方法之前。
4. 阻塞线程
join() 方法会使线程进入等待状态(阻塞),直到调用 join() 方法的子线程运行结束。同时你也可以通过设置 timeout 参数来设定等待的时间,该方法参数如下:
join([time]):
其中 time 参数可选,表示阻塞线程的秒数。
import threading
import time
# 每1秒加1
def job1(num):
while True:
num += 1
print('{} is running >> {}'.format(threading.current_thread().name, num))
time.sleep(1)
# 每2秒加2
def job2(num):
while True:
num += 2
print('{} is running >> {}'.format(threading.current_thread().name, num))
time.sleep(2)
# 线程1,一秒加一
new_job1 = threading.Thread(target=job1, name='Add1', args=(100,))
new_job1.start()
# 线程2,两秒加二
new_job2 = threading.Thread(target=job2, name='Add2', args=(1,))
# 设置为守护线程
new_job2.setDaemon(True)
new_job2.start()
# 主线程等待3秒
time.sleep(3)
print('{} Ending'.format(threading.current_thread().name))
运行结果如下:
Add1 is running >> 101
Add1 is running >> 102
Add1 is running >> 103
Add2 is running >> 3
Add1 is running >> 104
Add1 is running >> 105
Add2 is running >> 5
Add1 is running >> 106
MainThread Ending
Add1 is running >> 107
可以看到,前三秒线程1都被阻塞了。
注意, join 方法只能写在 start 方法之后。
5. 线程锁
首先我们先来进行这样一个实验,定义一个全局变量 num=0,使用两个线程分别对其进行1000000次加1以及1000000次加2,最终结果正确的话肯定是3000000对吧,那么最后结果是3000000吗?代码如下:
import threading
import time
num = 0
def job1():
global num
for i in range(1000000):
num += 1
new_job1 = threading.Thread(target=job1, name='Add1')
new_job1.start()
for i in range(1000000):
num += 2
# 等待线程执行完毕
time.sleep(5)
print('num = {}'.format(num))
最后输出结果为:
num = 1595678
并且每一次执行结果都不一样,这是这怎么回事呢?这是因为一个线程在修改数据的时候,另一个线程也在对数据进行修改,这就导致了脏数据的产生,数据库里面应该会经常有类似的问题,这也就有了线程锁产生的必要。下面我将会介绍Python中几种典型的锁。
5.1 互斥锁(Lock)
互斥锁只能开一次然后释放一次,一次开启后必须接上一次关闭,加锁的代码如下:
import threading
import time
num = 0
lock = threading.Lock()
def job1():
global num
for i in range(1000000):
lock.acquire() # 加锁
num += 1
lock.release() # 释放锁
# 上述代码也可以直接写为
# with lock:
# num += 1
new_job1 = threading.Thread(target=job1, name='Add1')
new_job1.start()
for i in range(1000000):
lock.acquire() # 加锁
num += 2
lock.release() # 释放锁
# 等待线程执行完毕
time.sleep(3)
print('num = {}'.format(num))
5.2 递归锁(RLock)
RLock与Lock最大的区别就是RLock可以开多次,再进行多次释放,也就是说RLock支持大锁里面套小锁。示例如下:
import threading, time
def run1():
lock.acquire()
print("grab the first part data")
global num
num += 1
lock.release()
return num
def run2():
lock.acquire()
print("grab the second part data")
global num2
num2 += 1
lock.release()
return num2
def run3():
lock.acquire()
res = run1()
print('--------between run1 and run2-----')
res2 = run2()
lock.release()
print(res, res2)
if __name__ == '__main__':
num, num2 = 0, 0
lock = threading.RLock()
for i in range(3):
t = threading.Thread(target=run3)
t.start()
while threading.active_count() != 1:
print(threading.active_count())
else:
print('----all threads done---')
print(num, num2)
5.3 信号量(Semaphore)
互斥锁同时只允许一个线程修改数据,而Semaphore是同时允许一定数量的线程修改数据,比如只有五个位置的餐桌,如果人坐满了,那么只有等一个人吃完后下一个人才能上桌。
下面设置信号量为3,每个线程执行三秒钟的时间,看看线程执行的时间是怎样的。
import threading
import time
# 设置信号量,即同时执行的线程数为3
lock = threading.BoundedSemaphore(3)
def job1():
lock.acquire()
print('{} is coming, {}'.format(threading.current_thread().name, time.strftime('%H:%M:%S',time.localtime(time.time()))))
time.sleep(3)
lock.release()
for i in range(10):
new_job1 = threading.Thread(target=job1, name='Thread{}'.format(i))
new_job1.start()
输出结果为:
Thread0 is coming, 16:44:41
Thread1 is coming, 16:44:41
Thread2 is coming, 16:44:41
Thread3 is coming, 16:44:44
Thread5 is coming, 16:44:44
Thread4 is coming, 16:44:44
Thread6 is coming, 16:44:47
Thread8 is coming, 16:44:47
Thread7 is coming, 16:44:47
Thread9 is coming, 16:44:50
上面的线程每三个是同一时间执行的,这也就说明了我们设置的信号量限制了同时执行的线程的数量。
5.4 事件(Event)
Event类会在全局定义一个Flag,当 Flag=False 时,调用 wait() 方法会阻塞所有线程;而当 Flag=True 时,调用 wait() 方法不再阻塞。形象的比喻就是“红绿灯”:在红灯时阻塞所有线程,而在绿灯时又会一次性放行所有排队中的线程。Event类有四个方法:
| 方法 | 描述 |
|---|---|
set() | 将Flag设置为True |
wait() | 阻塞所有线程 |
clear() | 将Flag设置为False |
is_set() | 返回bool值,判断Flag是否为True |
Event的一个好处是:可以实现线程间通信,通过一个线程去控制另一个线程。
例如,这里设置两个线程,线程1对全局变量 num 每次加1,线程2对全局变量 num 每次加2,各持续1000000次,现要求线程1在线程2加了500000次且自身加了700000次时,不再进行加法操作,实现代码如下:
import threading
import time
num = 0
event = threading.Event()
event.set() # 设定Flag = True
lock = threading.BoundedSemaphore(1)
def job1():
global num
for i in range(1000000):
# 如果加了70w次并且被阻塞,就跳出循环
if i == 700000 and not event.is_set():
break
lock.acquire()
num += 1
lock.release()
print('num = {}'.format(num))
event.set()
new_job1 = threading.Thread(target=job1, name='Add1')
new_job1.start()
for i in range(1000000):
# 如果执行了50w次,则阻塞进程
if i == 500000:
event.clear() # 设置Flag=False
event.wait() # 阻塞进程
print('num = {}'.format(num))
lock.acquire()
num += 2
lock.release()
# 等待线程执行完毕
time.sleep(3)
print('num = {}'.format(num))
6. ThreadLocal
在多线程环境下,每个线程都有自己的数据。一个线程使用自己的局部变量比使用全局变量好,因为局部变量只有线程自己能看见,不会影响其他线程,而全局变量的修改必须加锁。
但是局部变量也有问题,就是在函数调用的时候,传递起来很麻烦,比如我们需要将所有线程的数据传到另一个函数中去,那么我们要每个数据都是用参数传递吗?这样太过于麻烦,形式如下:
import threading
def add(n):
return n + n
def divid(n):
return n / 2
def times(a, b):
return a * b
def job1(num):
num_add = add(num)
num_divid = divid(num)
n = times(num_add, num_divid)
print('{} result >> {}'.format(threading.current_thread().name, n))
for i in range(5):
t = threading.Thread(target=job1, args=(i,), name='Thread{}'.format(i))
t.start()
输出如下:
Thread0 result >> 0.0
Thread1 result >> 1.0
Thread2 result >> 4.0
Thread3 result >> 9.0
Thread4 result >> 16.0
很容易就能看出,一次次的在job1中传递参数太过麻烦了,如果参数少还好,参数多的话,那简直会晕了头,那么,这就需要使用到 ThreadLocal 了。
ThreadLocal 能够管理每一个线程的数据,只需要将线程的数据放进去,然后再读出来即可,其会自动区分每个线程,使得数据不会混合,将上述例子改为 ThreadLocal 后,代码如下:
import threading
# 创建全局ThreadLocal对象
local_data = threading.local()
def add():
# 取出ThreadLocal中的数据
n = local_data.num
local_data.num_add = n + n
def divid():
n = local_data.num
local_data.num_divid = n / 2
def times():
local_data.result = local_data.num_add * local_data.num_divid
def job1(num):
# 将数据存入ThreadLocal中
local_data.num = num
add()
divid()
times()
print('{} result >> {}'.format(threading.current_thread().name, local_data.result))
for i in range(5):
t = threading.Thread(target=job1, args=(i,), name='Thread{}'.format(i))
t.start()
可以看到,如上代码中的数据根本没有参数传递,直接将所有的数据都存入了 ThreadLocal 对象中,就像在类中的 self 一样,十分的方便简洁。
7. 线程池
不是线程数量越多,程序的执行效率就越快。线程也是一个对象,是需要占用资源的,线程数量过多的话肯定会消耗过多的资源,同时线程间的上下文切换也是一笔不小的开销,所以有时候开辟过多的线程不但不会提高程序的执行效率,反而会适得其反使程序变慢,得不偿失。
为了防止无尽的线程被初始化,于是线程池就诞生了。当线程池初始化时,会自动创建指定数量的线程,有任务到达时直接从线程池中取一个空闲线程来用即可,当任务执行结束时线程不会消亡而是直接进入空闲状态,继续等待下一个任务。而随着任务的增加线程池中的可用线程必将逐渐减少,当减少至零时,任务就需要等待了。这就最大程度的避免了线程的无限创建,当所需要使用的线程不知道有多少时,一般都会使用线程池。
在 python 中使用线程池有两种方式,一种是基于第三方库 threadpool,另一种是基于 python3 新引入的库 concurrent.futures.ThreadPoolExecutor,这里我们介绍一下后一种。
7.1 基本使用
首先先了解以下方法
submit
其中submit(fn, *args, **kwargs)fn为方法名,其后的*args, **kwargs为该方法的参数。ThreadPoolExecutor
最常用的是ThreadPoolExecutor(max_workers=None, thread_name_prefix='', initializer=None, initargs=())max_workers参数,即线程池中的线程数。
下面用一个例子来说明方法的使用,假如我们需要向线程池申请2单位的线程,运行一个加法操作并返回结果,且每个加法操作会等待3秒,则代码如下:
import time
from concurrent.futures import ThreadPoolExecutor
# 对两数进行加法,并停留3秒
def add(a, b):
time.sleep(3)
return a + b
task = []
# 加法的两个因数
list_a = [1, 2, 3, 4, 5]
list_b = [6, 7, 8, 9, 10]
# 使用with上下问管理器,就不用管如何关线程池了
with ThreadPoolExecutor(2) as pool:
# 将每一个线程都进行提交
for i in range(len(list_a)):
task.append(pool.submit(add, list_a[i], list_b[i]))
# 输出每个线程运行的结果
for i in task:
print('result = {}'.format(i.result()))
result 方法能够输出对应的线程运行后方法的返回结果,如果线程还在运行,那么其会一直阻塞在那里,直到该线程运行完,当然,也可以设置 result(timeout),即如果调用还没完成那么这个方法将等待 timeout 秒。如果在 timeout 秒内没有执行完成,concurrent.futures.TimeoutError 将会被触发。
7.2 as_completed 方法
as_completed(fs, timeout=None)
返回一个包含 fs 所指定的 Future 实例的迭代器,在没有任务完成的时候,会一直阻塞,如果设置了 timeout 参数,timeout 秒之后结果仍不可用,则返回的迭代器将引发 concurrent.futures.TimeoutError。 timeout 可以为整数或浮点数。 如果 timeout 未指定或为 None,则不限制等待时间。
当有某个任务完成的时候,该方法会 yield 这个任务,就能执行 for 循环下面的语句,然后继续阻塞住,循环到所有的任务结束。同时,先完成的任务会先返回给主线程。
将上面的程序改为使用 as_completed 后为:
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
def add(a, b):
time.sleep(3)
return a + b
task = []
list_a = [1, 2, 3, 4, 5]
list_b = [6, 7, 8, 9, 10]
with ThreadPoolExecutor(2) as pool:
for i in range(len(list_a)):
task.append(pool.submit(add, list_a[i], list_b[i]))
# 使用as_completed遍历
for i in as_completed(task):
print('result = {}'.format(i.result()))
该方法与第一种的直接遍历所具有的优势是,不需要等待所有线程全部返回,而是每返回一个子线程就能够处理,上面的result方法会阻塞后面的线程。
7.3 wait方法
wait() 方法如下:
wait(fs, timeout=None, return_when=ALL_COMPLETED)
fs 为指定的 Future 实例,timeout 可以用来控制返回前最大的等待秒数。 timeout 可以为 int 或 float 类型。 如果 timeout 未指定或为 None ,则不限制等待时间。return_when 指定此函数应在何时返回。它必须为以下常数之一:
| 常数 | 描述 |
|---|---|
FIRST_COMPLETED | 等待第一个线程结束时返回,即结束等待 |
FIRST_EXCEPTION | 函数将在任意可等待对象因引发异常而结束时返回。当没有引发任何异常时它就相当于 ALL_COMPLETED |
ALL_COMPLETED | 函数将在所有可等待对象结束或取消时返回 |
我们在上例中添加一个 wait 方法如下:
import time
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
def add(a, b):
time.sleep(3)
return a + b
task = []
list_a = [1, 2, 3, 4, 5]
list_b = [6, 7, 8, 9, 10]
with ThreadPoolExecutor(2) as pool:
for i in range(len(list_a)):
task.append(pool.submit(add, list_a[i], list_b[i]))
# 等待所有线程执行完再往下
wait(task, return_when=ALL_COMPLETED)
for i in task:
print('result = {}'.format(i.result()))
7.4 map方法
map 方法参数如下:
map(func, *iterables, timeout=None, chunksize=1)
func 参数为多线程指向的方法名,*iterables 实际上是该方法的参数,该方法的参数必须是可迭代对象,即元组或列表等,不能单纯的传递 int 或字符串,如果 timeout 设定的时间小于线程执行时间会抛异常 TimeoutError,默认为 None 则不加限制。
使用 map 方法,有两个特点:
- 无需提前使用submit方法
- 返回结果的顺序和元素的顺序相同,即使子线程先返回也不会获取结果
将上例使用 map 方法后的示例如下:
import time
from concurrent.futures import ThreadPoolExecutor
def add(a, b):
time.sleep(3)
return a + b
task = []
list_a = [1, 2, 3, 4, 5]
list_b = [6, 7, 8, 9, 10]
with ThreadPoolExecutor(2) as pool:
# map中list_a与list_b按照下标一一对应
for result in pool.map(add, list_a, list_b):
print('result = {}'.format(result))
8. Python线程真相
实际上,Python中的多线程其实并没有我们以为的那么有用,Python中的多线程其实是一种假象的多线程。
Python的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
GIL是Python解释器设计的历史遗留问题,通常我们用的解释器是官方实现的CPython,要真正利用多核,除非重写一个不带GIL的解释器。
所以,在Python中,可以使用多线程,但不要指望能有效利用多核。如果一定要通过多线程利用多核,那只能通过C扩展来实现,不过这样就失去了Python简单易用的特点。
这就相当于我有12个核的CPU,尽管使用了Python的多线程,比如我一共开了12个线程,但是,不管这个线程时占用一个内核还是12个内核,每一个时间段都只能有1个线程在CPU中进行运行,然后根据时间片轮转的方式,切换到下一个线程,下一个线程再进行运行。所以说,Python中的多线程实际上是一种并发而不是并行。但是,Python其实是能够实现并行的,那就是利用多进程来实现。
下面我们参照这篇文章的回答来进行实验验证。
我的电脑是12核的,下面我写一个12线程的无限循环,再看看CPU的利用率。
from threading import Thread
def loop():
while True:
pass
if __name__ == '__main__':
for i in range(12):
t = Thread(target=loop)
t.start()
while True:
pass
在程序运行了约20秒后,CPU利用率如下,可以发现,CPU的利用率基本上没有什么变化,下面我们看看使用多进程时的CPU利用率。
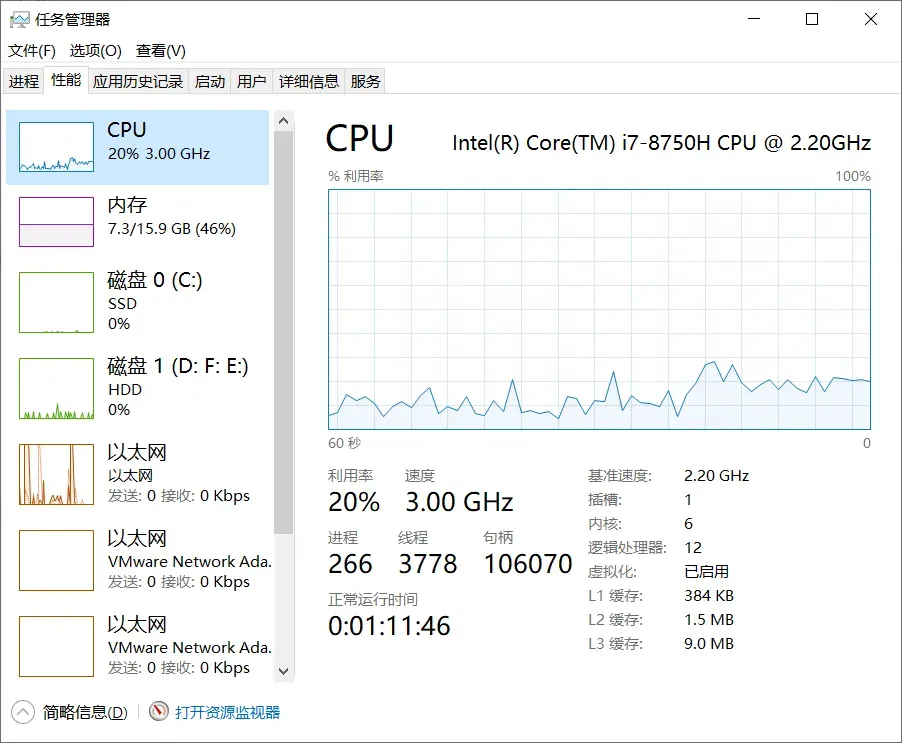
这里使用多进程开12个无限循环的进程,代码如下。
from multiprocessing import Process
def loop():
while True:
pass
if __name__ == '__main__':
for i in range(12):
t = Process(target=loop)
t.start()
while True:
pass
CPU利用率如下,可以看到,COU利用率一瞬间就冲到了100%,这表示Python中的多进程实际上是可以并行运行的,但是多线程却是并发运行的。
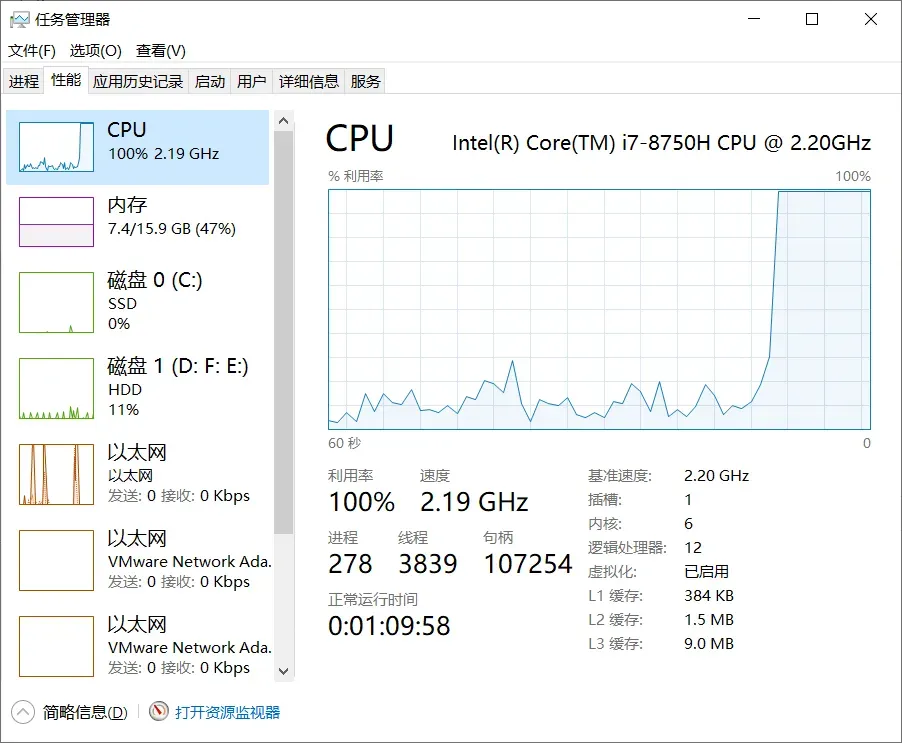
参考文章
[1] : https://www.liaoxuefeng.com/wiki/1016959663602400/1017629247922688
[2] : https://blog.csdn.net/weixin_44850984/article/details/89165731
[3] : https://www.runoob.com/python3/python3-multithreading.html
[4] : https://zhuanlan.zhihu.com/p/490353142
[5] : https://blog.csdn.net/Elon15/article/details/125350491
[6] : https://www.cnblogs.com/fjfsu/p/15709155.html
[7] : https://blog.csdn.net/hhl134/article/details/122366629
[8] : https://www.cnblogs.com/goldsunshine/p/16878089.html
[9] : https://docs.python.org/zh-cn/3.7/library/concurrent.futures.html
文章出处登录后可见!