目录
Text-based Person Retrieval 任务介绍
博主是做多模态相关的,最近刚刚接触了语言行人检索 (Text-based Person Retrieval) 这个任务,觉得挺有意思,开一个专栏来记录一下该任务的常用数据集和一些经典工作。
语言行人检索应该算是 多模态检索 和 行人重识别 两个任务的交叉子任务,任务本身并不难理解,就是给定一段文本描述当作查询 query,然后检索到所描述的行人图片即可,如下图所示。
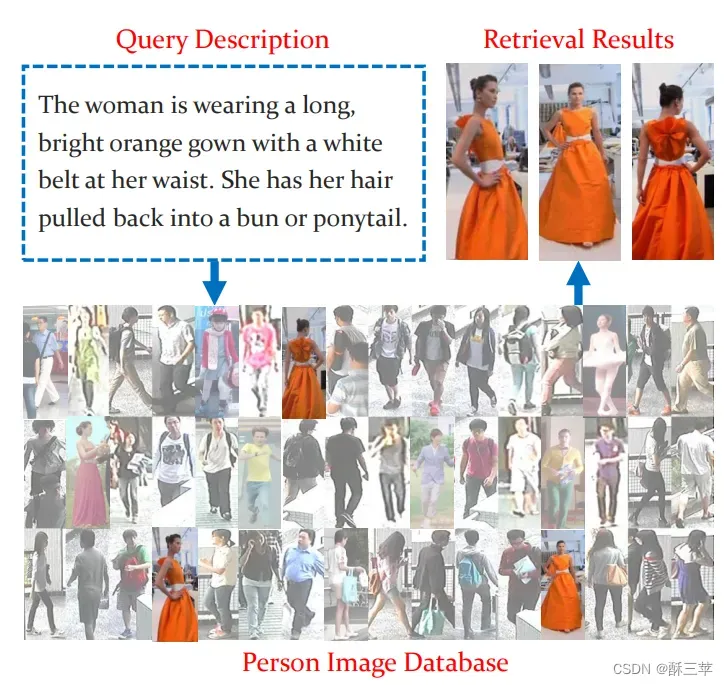
同时,在待检索的图像数据库中,是存在同一人物的不同照片的,它们在数据集中标注的id是一样的,跟ReID还有点关系。
综上来看,语言行人检索和普通的跨模态图文匹配的不同点主要包括如下两个方面:
- 存在重识别相关的任务,即不仅要完成语言到图片的检索,模型还应该具备判断同一人物 id 的能力。
- 细粒度特点,语言行人检索中,不同的人彼此之间只存在细粒度的差异,而并不存在类别上的差异,属于跨模态细粒度检索,比普通的跨模态检索任务要难。
常用数据集
到目前为止,语言行人检索领域常用的数据集包括CUHK-PEDES、ICFG-PEDES、RSTPReid三个,先看一下 paper with code 上CUHK-PEDES数据集的排行情况,如下所示。
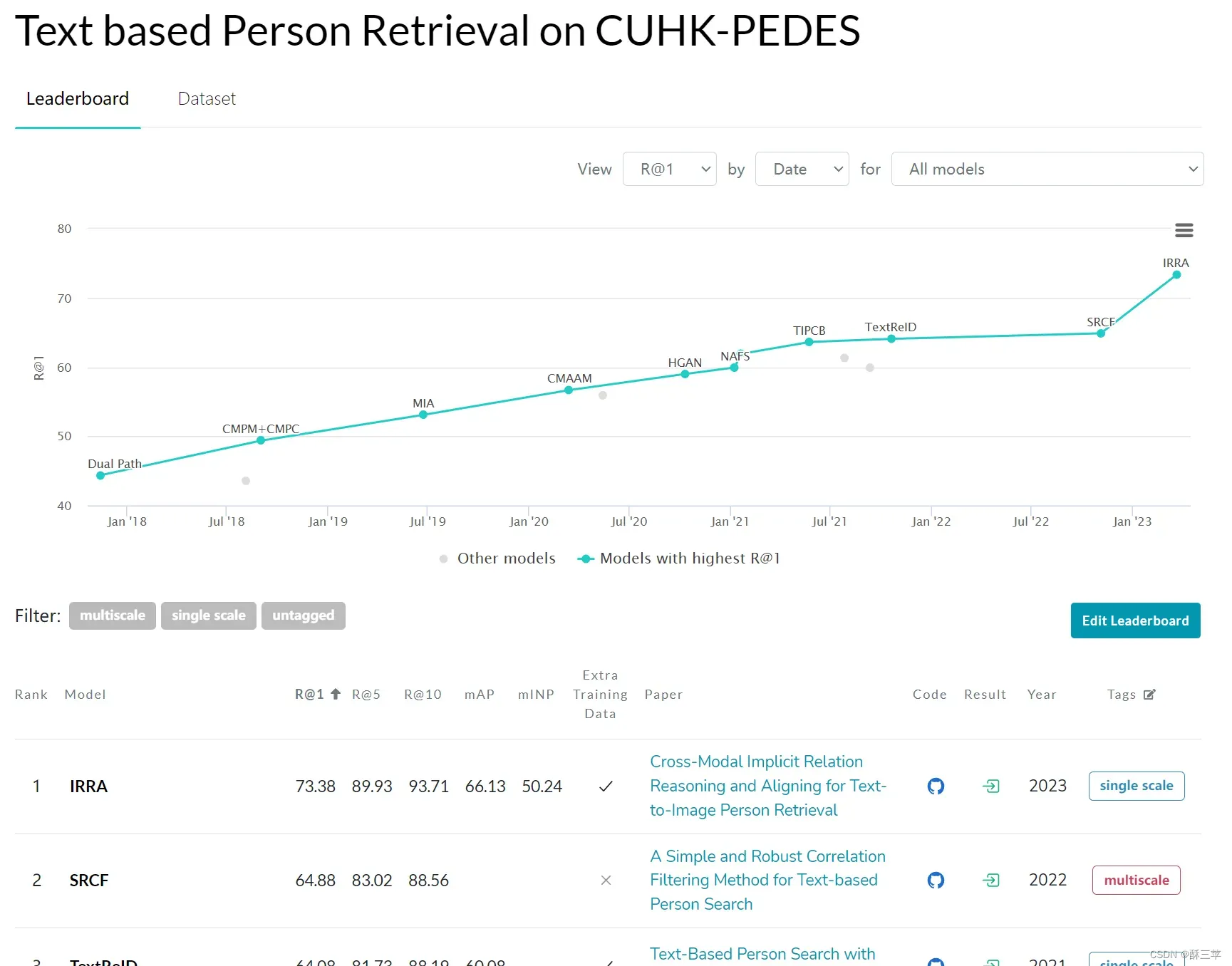
可以看出该任务的分数已经被刷的比较高了,IRRA的Rank1分数已经能够达到73.38%,再往上刷也不是一容易的事情。接下来大致记录一下该领域常用数据集的基本情况。
CUHK-PEDES 数据集
repo地址:https://github.com/ShuangLI59/Person-Search-with-Natural-Language-Description
CUHK-PEDES是第一个专门用于语言行人检索的数据集,它包含40206张图像和80412个文本描述,共13003个id。根据官方的数据集划分,训练集由11003个身份、34054张图片和68108个文本描述组成;验证集和测试集分别包含3078张和3074张图像,6158张和6156张文本描述,两者都具有1000个身份;
ICFG-PEDES 数据集
repo地址:https://github.com/zifyloo/SSAN
ICFG-PEDES共包含4102个身份的54522张图像,每个图像只有一个对应的文本描述。该数据集分为训练集和测试集,前者包含3102个身份的34674个图文对,后者包含剩余1000个身份的19848个图文对。描述的平均长度为37.2个单词
RSTPReid 数据集
repo地址:https://github.com/NjtechCVLab/RSTPReid-Dataset
RSTPReid共包含来自4101个身份的20505张图像,每个身份都有5张不同相机拍摄的对应图像,每张图像都有2个文本描述,每个描述不少于23个单词。根据官方的数据集划分,训练集、验证集和测试集分别包含3701、200和200个身份。
文章出处登录后可见!