文章目录
- 1 数据查看
- 2 数据可视化及预处理
- 3 模型训练与精度评价
- 代码汇总
1 数据查看
①数据导入结构查看
输入以下代码,将我们需要的尼日利亚音乐数据集导入notebook并查看其组织结构。
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv("nigerian-songs.csv")#以pandas库的read_csv函数读取csv文件
df.head()#查看前5行数据

# 其中有音乐的基本信息(名称、艺术家、发布日期等),输入以下代码,查看其数据结构:
df.info()
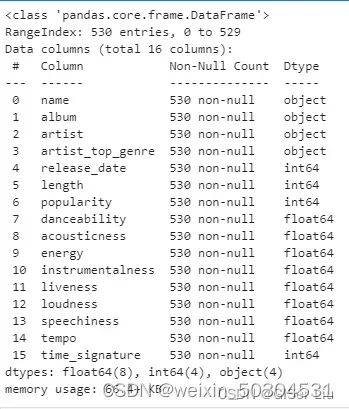
可以看到,尼日利亚音乐数据集中共包含539行样本。有16个待选择数据特征:数值型数据有12个,字符型数据有4个。
②查看数据描述
输入以下代码查看数据描述:
# 数据统计描述,默认只输出数值型变量统计描述
df.describe()
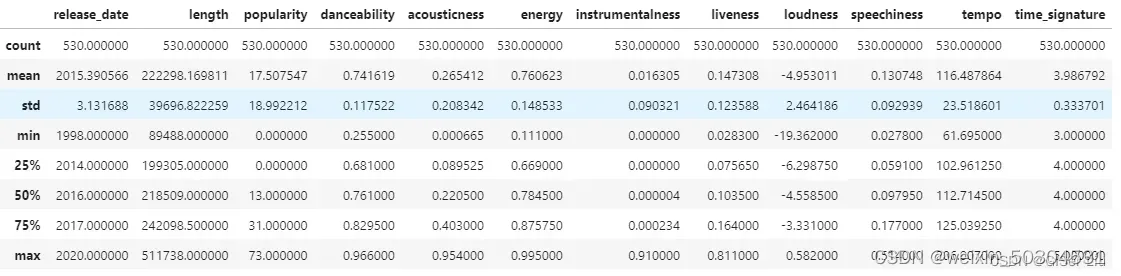
通过查看数据的描述,我们可以看到不同数据特征的数量、均值、方差及不同层次的数值。这些信息可以帮助我们在后面的处理中选择合适的模型或处理方法。
2 数据可视化及预处理
可视化数据,直观查看数据的特征。本次作者使用seaborn库来可视化,seaborn库是基于matplotlib库封装的,可视化效果更棒!😀
# 在此之前我们去掉数据中包含缺失值的样本,避免其影响。查看数据是否有缺失值或异常值,输入以下代码:
df.isnull().sum()
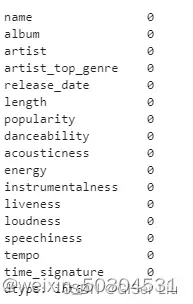
可以看到,本次数据比较干净,没有缺失值。我们开始可视化!😏
①条形图
输入以下代码查看数据集中数量前5名的艺术家类型数量的条形图:
import seaborn as sns#导入seaborn包
top = df['artist_top_genre'].value_counts() #对不同音乐家类型进行统计汇总,格式为列表
plt.figure(figsize=(10,7)) #设置图表大小
sns.barplot(x=top[:5].index,y=top[:5].values) #取出前5行数据的index作为X轴类型,音乐数量作为Y轴数值绘制条形图
plt.xticks(rotation=45) #若X轴标签过长导致可视化效果不好,可进行标签旋转进行调整
plt.title('Top genres',color = 'blue') #设置条形图标题内容及颜色
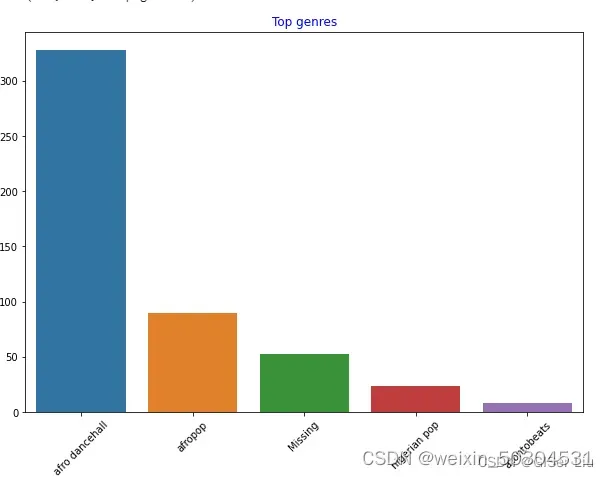
可以看到,前5种风格类型中,afro dancehall风格音乐数量最多;眼尖的同学可能发现,其中有一部分数据是“Missing”,这表示这部分数据是没有类型标签的,方便分析起见,我们将这一部分数据抛弃掉!
在大部分数据集中,🤨类似于”Missing”类型的数据在缺失值筛选中并不容易被发现,但它们常常占据着较大部分,我们可以对这些特征绘制条形图来发现它们并进行剔除!😜
继续对全部数据进行可视化。输入以下代码:
df = df[df['artist_top_genre'] != 'Missing']#删去没有音乐风格标签的数据
top = df['artist_top_genre'].value_counts()#统计不同音乐风格的音乐数量
plt.figure(figsize=(10,7))#设置画布尺寸
sns.barplot(x=top.index,y=top.values)#对所有音乐风格数据的标签和数量绘制条形图
plt.xticks(rotation=45)#调整X轴标签角度
plt.title('Top genres',color = 'blue')#设置标题属性
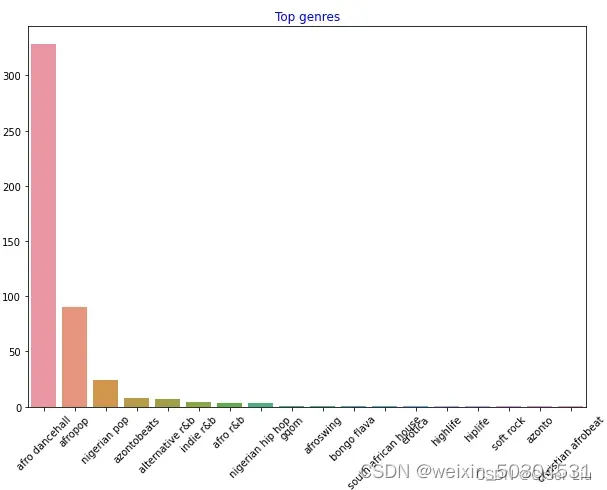
如此一来,不同风格的音乐数据便清晰的展现出来。
为了方便我们的聚类实验,我们提取出数量最多的三类样本及人气大于0的样本作为数据集主体用于之后的聚类。输入以下代码:
df = df[(df['artist_top_genre'] == 'afro dancehall') | (df['artist_top_genre'] == 'afropop') | (df['artist_top_genre'] == 'nigerian pop')]#提取数量前三的样本
df = df[(df['popularity'] > 0)]#提取人气大于0的样本
②热力图
做一个快速测试,看看数据中哪些特征之间存在高度相关。我们对经过筛选的数据进行相关系数计算,并以热力图的方式呈现相关性。输入以下代码 :
corrmat = df.corr() #用于计算相关系数
f, ax = plt.subplots(figsize=(12, 9))#subplots() 函数既创建了一个包含子图区域的画布,又创建了一个 figure 图形对象。
sns.heatmap(corrmat, vmax=.8, square=True) #corrmat值为相关系数,vmax为最大相关系数值用来界定颜色的映射范围,square为bool类型参数,是否使热力图的每个单元格为正方形,默认为False
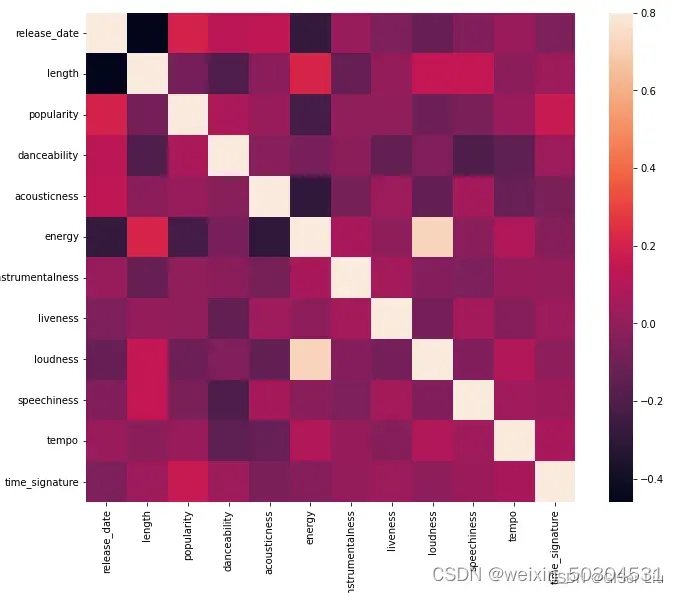
排除矩阵对角线上的相关性(自己与自己本来就高度相关),我们可以看到energy和loudness特征相关形较高。这并不奇怪,因为嘈杂的音乐通常充满激情。
🙄请注意,相关性并不意味着因果关系!我们证明它们相关,但不能证明他们之间的因果关系。
③核密度图
根据它们的受欢迎程度,这三种流派在可跳舞性的看法上是否显着不同?以音乐数据的人气为X轴,以是否可跳舞性为Y轴绘制核密度(KDE)图查看数据的分布。输入以下代码:
sns.set_theme(style="ticks")#set_style( )是用来设置主题的,Seaborn有五个预设好的主题: darkgrid , whitegrid , dark , white ,和 ticks
g = sns.jointplot(#jointplot函数用于绘制双变量图
data=df,#数据为经过筛选预处理的数据
x="popularity", y="danceability", hue="artist_top_genre",#选择两个变量, 增加hue变量将为图形添加条件颜色,并在边沿轴上绘制单独的密度曲线
kind="kde",#设置绘图类型 KDE指核密度图
)
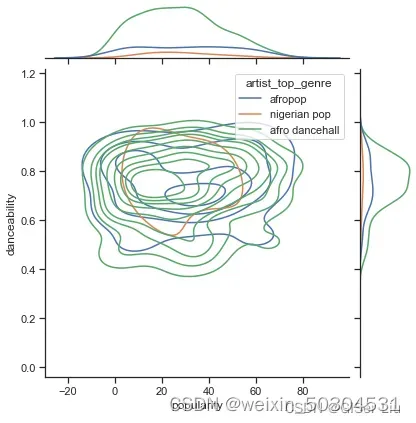
从图上看,这三种流派在人气和可舞蹈性方面松散地对齐。 这说明我们对它进行聚类时将比较麻烦,数据差异太小。
在数据探索阶段我们可以自由去探寻不同特征之间的关系,如果你觉得繁琐 你也可以用批处理函数来快速查看结果,尽管这样少了很多趣味性。🙄
④散点图
我们继续对这两个特征创建散点图查看数据分布。输入以下代码:
ns.FacetGrid(df, hue="artist_top_genre", size=5) \
.map(plt.scatter, "popularity", "danceability") \
.add_legend()
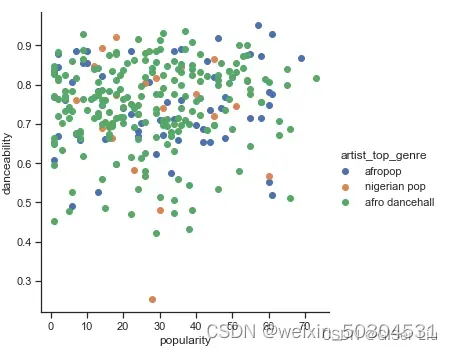
嗯哼,验证了我们上面的猜想,数据分布很复杂,乱糟糟的😅。
对于聚类分析,我们通常可以使用散点图来直观地显示数据聚类,掌握这种类型的可视化非常有用。
⑤箱型图
对于混乱的数据,我们可以使用箱型图来直观的查看数据的分布,从中找出异常数据并进行排除。输入以下代码查看不同数值型特征的箱型图分布:
plt.figure(figsize=(20,20), dpi=200)
plt.subplot(4,3,1)#subplot函数划分了4行3列的画布区域,第三个参数表示图像在其中的位置
sns.boxplot(x = 'popularity', data = df)
plt.subplot(4,3,2)
sns.boxplot(x = 'acousticness', data = df)
plt.subplot(4,3,3)
sns.boxplot(x = 'energy', data = df)
plt.subplot(4,3,4)
sns.boxplot(x = 'instrumentalness', data = df)
plt.subplot(4,3,5)
sns.boxplot(x = 'liveness', data = df)
plt.subplot(4,3,6)
sns.boxplot(x = 'loudness', data = df)
plt.subplot(4,3,7)
sns.boxplot(x = 'speechiness', data = df)
plt.subplot(4,3,8)
sns.boxplot(x = 'tempo', data = df)
plt.subplot(4,3,9)
sns.boxplot(x = 'time_signature', data = df)
plt.subplot(4,3,10)
sns.boxplot(x = 'danceability', data = df)
plt.subplot(4,3,11)
sns.boxplot(x = 'length', data = df)
plt.subplot(4,3,12)
sns.boxplot(x = 'release_date', data = df)
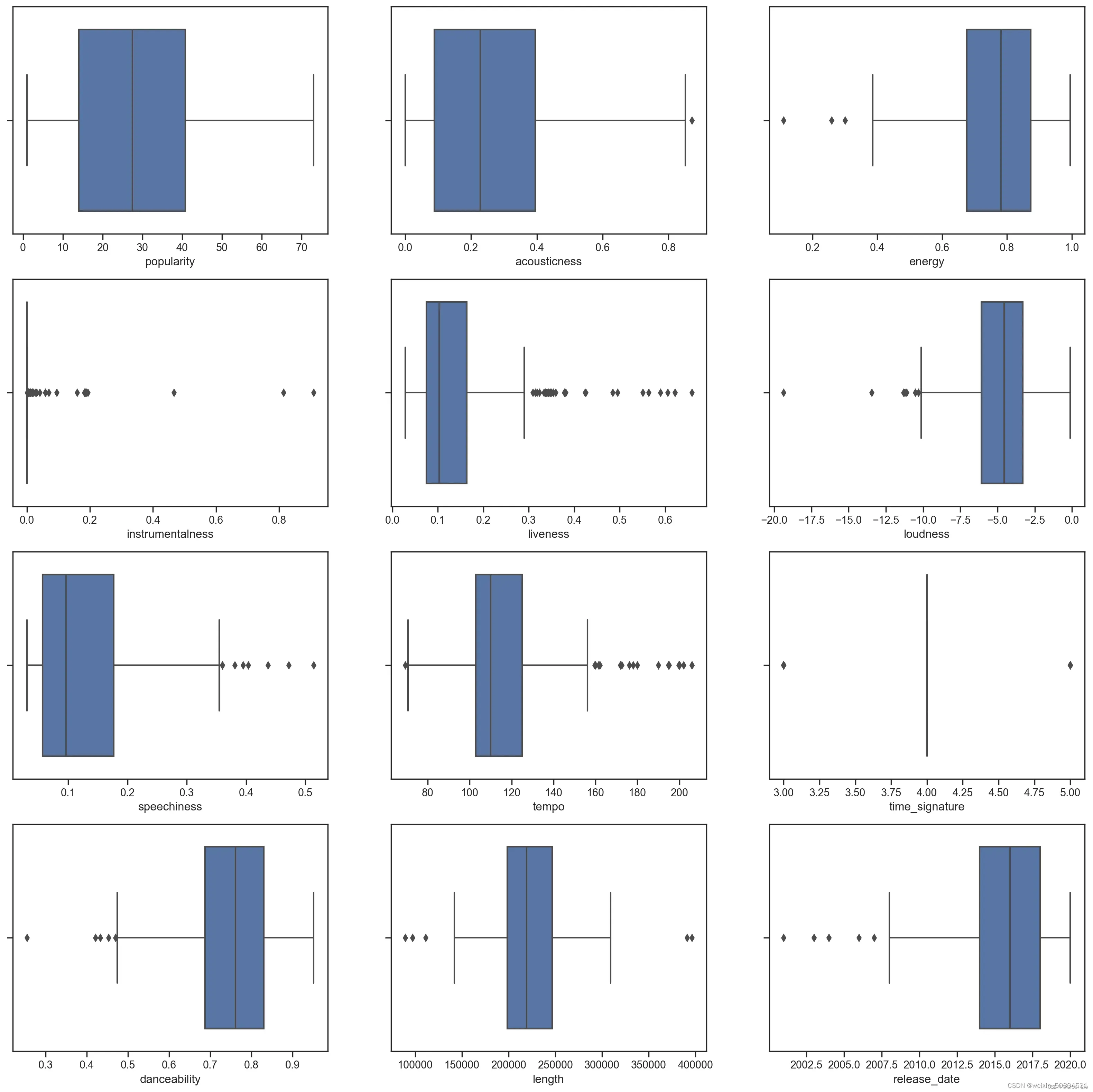
我们可以看到,*星号表示异常值,箱体的位置表示数据的分布区域。图中大量特征是分布不均匀的,异常值较多的样本特征不适合聚类,我们可以对其进行进一步剔除。
3 模型训练与精度评价
①样本选择
现在,选择将用于聚类分析练习的特征列。这些特征列需要具有相似的范围;且其中的文本列数据需要编码为数值数据:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()#创建一个编码器
X = df.loc[:,('artist_top_genre','popularity','danceability','acousticness','loudness','energy')]#loc为Selection by Label函数,即为按标签取数据;将需要的标签数据取出作为X训练特征样本
y = df['artist_top_genre']#将艺术家流派作为Y验证模型精度标签
X['artist_top_genre'] = le.fit_transform(X['artist_top_genre'])#对文本数据进行标签化为数值格式
y = le.transform(y)#对文本数据进行标签化为数值格式
②模型训练
现在,我们需要选择聚类的集群(簇)数量。我们已知可以从中取出3种歌曲类型,因此我们将nclusters赋值为3,输入以下代码:
from sklearn.cluster import KMeans
nclusters = 3 #初始化质心数量,因为我们想要划分3中音乐类型,因此将其赋值为3
seed = 0 #选择随机初始化种子
km = KMeans(n_clusters=nclusters, random_state=seed)#一个random_state对应一个质心随机初始化的随机数种子。如果不指定随机数种子,则 sklearn中的KMeans并不会只选择一个随机模式扔出结果
km.fit(X)#对Kmeans模型进行训练
#使用训练好的模型进行预测
y_cluster_kmeans = km.predict(X)
y_cluster_kmeans

该数组即K-means模型的预测结果,其中数字为每行样本的的聚类结果(0、1 或 2)。
③精度评价
- 轮廓系数(Silhouette Coefficient),是聚类效果好坏的一种评价方式。
- 最佳值为1,最差值为-1。接近0的值表示重叠的群集。负值通常表示样本已分配给错误的聚类,因为不同的聚类更为相似
轮廓系数的公式为:
其中是单个样本离同类簇所有样本的距离的平均数,
是单个样本到不同簇所有样本的平均。
轮廓系数表示了同类样本间距离最小化,不同类样本间距离最大的度量
我们接着使用此预测结果计算“轮廓系数”,输入以下代码:
from sklearn import metrics
score = metrics.silhouette_score(X, y_cluster_kmeans)# metrics.silhouette_score函数用于计算轮廓系数
score
'''
0.5667473
'''
我们的模型轮廓系数是0.54,这表明我们的数据不是特别适合这种类型的聚类,但这不影响我们的教学,实践工作中总是有各种各样的麻烦。我们接着进行训练。
④模型调参
导入第三方库,调整参数进行新一轮训练,我们对簇的数量进行批处理,看看参数值为多少效果最佳:
from sklearn.cluster import KMeans
wcss = []
for i in range(1, 11):
kmeans = KMeans(n_clusters = i, init = 'k-means++', random_state = 42)
kmeans.fit(X)
wcss.append(kmeans.inertia_) 获取K-means算法的SSE
参数介绍:
- range():这里用for循环是为了迭代训练轮数,这里我们设置训练10轮
- random_state:确定初始化质心的随机数生成。
- wcss:用于存储 “聚类内平方和” 测量聚类内所有点到聚类质心的平方平均距离。
- inertia_:K-Means算法试图选择质心来最小化“惯性”,“衡量内部相干聚类的尺度”。该值在每次迭代时都会追加到 wcss 变量中。这个评价参数表示的是簇中某一点到簇中距离的和,这种方法虽然在评估参数最小时表现了聚类的精细性
- k-means++:在Scikit-learn中,你可以使用’k-means++’优化,它“初始化质心(通常情况下)彼此相距较远,可能比随机初始化有更好的结果。
我们使用 lineplot 函数绘制随着类别(簇)数量的增加,inertia_参数值变化趋势的折线图。
plt.figure(figsize=(10,5))
sns.lineplot(range(1, 11), wcss,marker='o',color='red')
plt.title('Elbow')
plt.xlabel('Number of clusters')
plt.ylabel('WCSS')
plt.show()
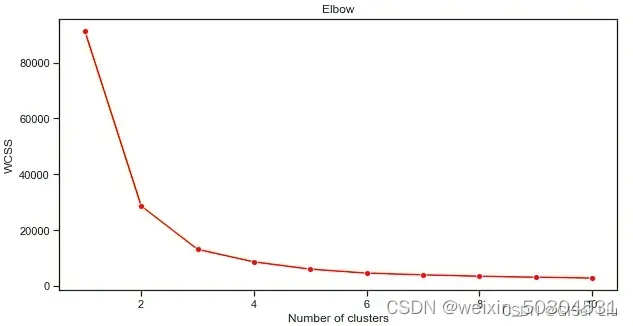
再次尝试模型训练与精度评价过程,这次设置3轮聚类,并将聚类结果以散点图显示:
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3)#设置聚类的簇(类别)数量
kmeans.fit(X)#对模型进行训练
labels = kmeans.predict(X)#输出预测值
plt.scatter(df['popularity'],df['danceability'],c = labels)#以人气为X轴,可舞蹈性为Y轴,标签为类别绘制散点图
plt.xlabel('popularity')
plt.ylabel('danceability')
plt.show()
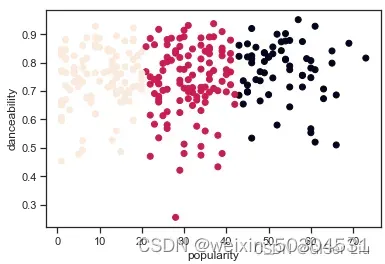
输入以下代码检查模型的准确度:
labels = kmeans.labels_#提取出模型中样本的预测值labels
correct_labels = sum(y == labels)#统计预测正确的值
print("Result: %d out of %d samples were correctly labeled." % (correct_labels, y.size))
print('Accuracy score: {0:0.2f}'. format(correct_labels/float(y.size)))
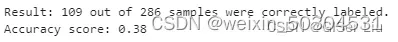
代码汇总
import matplotlib.pyplot as plt
import pandas as pd
# 数据导入
df = pd.read_csv("nigerian-songs.csv")#以pandas库的read_csv函数读取csv文件
df.head()#查看前5行数据
# 查看其数据结构
df.info()
# 查看数据是否有缺失值或异常值
df.isnull().sum()
# 数据统计描述,默认只输出数值型变量统计描述
df.describe()
'''
基于量纲不同无法比较,对数据进行标准化
'''
# 数据0-1标准化
df_normalized_data = df_raw.apply(lambda x: (x - np.min(x)) / (np.max(x) - np.min(x)))
# print(df_normalized_data)
'''
画图了解基本的数据情况
'''
# 画图
import seaborn as sns#导入seaborn包
top = df['artist_top_genre'].value_counts() #对不同音乐家类型进行统计汇总,格式为列表
plt.figure(figsize=(10,7)) #设置图表大小
sns.barplot(x=top[:5].index,y=top[:5].values) #取出前5行数据的index作为X轴类型,音乐数量作为Y轴数值绘制条形图
plt.xticks(rotation=45) #若X轴标签过长导致可视化效果不好,可进行标签旋转进行调整
plt.title('Top genres',color = 'blue') #设置条形图标题内容及颜色
# 对全部数据进行可视化
df = df[df['artist_top_genre'] != 'Missing']#删去没有音乐风格标签的数据
top = df['artist_top_genre'].value_counts()#统计不同音乐风格的音乐数量
plt.figure(figsize=(10,7))#设置画布尺寸
sns.barplot(x=top.index,y=top.values)#对所有音乐风格数据的标签和数量绘制条形图
plt.xticks(rotation=45)#调整X轴标签角度
plt.title('Top genres',color = 'blue')#设置标题属性
# 核密度图
sns.set_theme(style="ticks")#set_style( )是用来设置主题的,Seaborn有五个预设好的主题: darkgrid , whitegrid , dark , white ,和 ticks
g = sns.jointplot(#jointplot函数用于绘制双变量图
data=df,#数据为经过筛选预处理的数据
x="popularity", y="danceability", hue="artist_top_genre",#选择两个变量, 增加hue变量将为图形添加条件颜色,并在边沿轴上绘制单独的密度曲线
kind="kde",#设置绘图类型 KDE指核密度图
)
#散点图
#首先调用一下画图的库
import matplotlib.pyplot as plt
plt.scatter(data['sepal-length'], data['sepal-width'], edgecolors=None, plotnonfinite=False, )
#记得用完了这个函数要show一下,不然成不了图片
plt.show()
# ------------------------下面介绍如何绘制多变量聚类散点图-----------------------------
# 对二分类的散点图绘制,网上教程很多,此篇文章主要介绍多分类的散点图绘制问题
# 首先,对原数据进行 PCA 降维处理,获得散点图的横纵坐标轴数据
pca = PCA(n_components=2) # 提取两个主成分,作为坐标轴
pca.fit(df_normalized_data)
data_pca = pca.transform(df_normalized_data)
data_pca = pd.DataFrame(data_pca, columns=['PC1', 'PC2'])
data_pca.insert(data_pca.shape[1], 'labels', labs)
# centers pca 对 K-means 的聚类中心降维,对应到散点图的二维坐标系中
pca = PCA(n_components=2)
pca.fit(centers)
data_pca_centers = pca.transform(centers)
data_pca_centers = pd.DataFrame(data_pca_centers, columns=['PC1', 'PC2'])
# Visualize it:
plt.figure(figsize=(8, 6))
plt.scatter(data_pca.values[:, 0], data_pca.values[:, 1], s=3, c=data_pca.values[:, 2], cmap='Accent')
plt.scatter(data_pca_centers.values[:, 0], data_pca_centers.values[:, 1], marker='o', s=55, c='#8E00FF')
plt.show()
'''
使用箱型图来直观的查看数据的分布,从中找出异常数据并进行排除。输入以下代码查看不同数值型特征的箱型图分布
'''
plt.figure(figsize=(20,20), dpi=200)
plt.subplot(4,3,1)#subplot函数划分了4行3列的画布区域,第三个参数表示图像在其中的位置
sns.boxplot(x = 'popularity', data = df)
plt.subplot(4,3,2)
sns.boxplot(x = 'acousticness', data = df)
plt.subplot(4,3,3)
sns.boxplot(x = 'energy', data = df)
plt.subplot(4,3,4)
sns.boxplot(x = 'instrumentalness', data = df)
plt.subplot(4,3,5)
sns.boxplot(x = 'liveness', data = df)
plt.subplot(4,3,6)
sns.boxplot(x = 'loudness', data = df)
plt.subplot(4,3,7)
sns.boxplot(x = 'speechiness', data = df)
plt.subplot(4,3,8)
sns.boxplot(x = 'tempo', data = df)
'''
快速测试,看看数据中哪些特征之间存在高度相关。我们对经过筛选的数据进行相关系数计算
'''
# 热力图
corrmat = df.corr() #用于计算相关系数
f, ax = plt.subplots(figsize=(12, 9))#subplots() 函数既创建了一个包含子图区域的画布,又创建了一个 figure 图形对象。
sns.heatmap(corrmat, vmax=.8, square=True) #corrmat值为相关系数,vmax为最大相关系数值用来界定颜色的映射范围,square为bool类型参数,是否使热力图的每个单元格为正方形,默认为False
'''
手肘法确定 K 数目
'''
from sklearn.cluster import KMeans
wcss = []
for i in range(1, 11):
kmeans = KMeans(n_clusters = i, init = 'k-means++', random_state = 42)
kmeans.fit(X)
wcss.append(kmeans.inertia_) # 获取K-means算法的SSE
'''
range():这里用for循环是为了迭代训练轮数,这里我们设置训练10轮
random_state:确定初始化质心的随机数生成。
wcss:用于存储 “聚类内平方和” 测量聚类内所有点到聚类质心的平方平均距离。
inertia_:K-Means算法试图选择质心来最小化“惯性”,“衡量内部相干聚类的尺度”。该值在每次迭代时都会追加到 wcss 变量中。这个评价参数表示的是簇中某一点到簇中距离的和,这种方法虽然在评估参数最小时表现了聚类的精细性
k-means++:在Scikit-learn中,你可以使用’k-means++'优化,它“初始化质心(通常情况下)彼此相距较远,可能比随机初始化有更好的结果。
'''
# lineplot 函数绘制随着类别(簇)数量的增加,inertia_参数值变化趋势的折线图。
plt.figure(figsize=(10,5))
sns.lineplot(range(1, 11), wcss,marker='o',color='red')
plt.title('Elbow')
plt.xlabel('Number of clusters')
plt.ylabel('WCSS')
plt.show()
'''
训练模型
'''
# 模型训练与精度评价过程,这次设置3轮聚类,并将聚类结果以散点图显示:
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3)#设置聚类的簇(类别)数量
kmeans.fit(X)#对模型进行训练
labels = kmeans.predict(X)#输出预测值
plt.scatter(df['popularity'],df['danceability'],c = labels)#以人气为X轴,可舞蹈性为Y轴,标签为类别绘制散点图
plt.xlabel('popularity')
plt.ylabel('danceability')
plt.show()
'''
模型评估
'''
# 轮廓系数
from sklearn import metrics
score = metrics.silhouette_score(X, y_cluster_kmeans)# metrics.silhouette_score函数用于计算轮廓系数
score
一文读懂K-Means原理与Python实现
Python | 实现 K-means 聚类——多维数据聚类散点图绘制
文章出处登录后可见!