前情提要 :
CSDN
上一篇文章讲述了BERT的全流程,但我们要做的是复现tinyBERT。BERT是一个大家族,里面有BERT-Tiny,BERT-Base,BERT-large等等。 他们的主要区别仅仅是结构不一样, 但是我们今天复现的tinyBERT是和他们不一样的,他的BERT在后面。 这就决定了它不只是结构不同,训练方式也是不同的。
结构差异 :
为了介绍结构的差异,我们先来读一个BERT的设置文档BERT config,一个config便可以决定一个BERT的结构。
{
"hidden_size": 384, #决定token被编码的长度,即特征长度
"intermediate_size": 1536, # MLP第一次映射的长度,这里特征长度乘以4
"max_position_embeddings": 512, # 最大输入长度。
"model_type": "tiny_bert",
"num_attention_heads": 12, # 注意力头个数
"num_hidden_layers": 4, # 堆叠多少层
"vocab_size": 30522 # 训练词典个数,与训练语料有关
}{
"hidden_size": 768,
"intermediate_size": 3072,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"vocab_size": 30522
}上是tinyBert 下是bert-base。我主要把bert家族改变时主要改变的属性拿出来。我们可以看到他们结构上的不同之处。参数的具体意思,可以看前文得到。 这样tinyBERT自然会参数减少很多。 为了性能保持不变,tinyBERT并不像BERT家族那样在无标注上预训练,而是采取了蒸馏学习的方式进行训练。通过对BERT-base的蒸馏,得到了很好的性能。 (可以百度学习一下知识蒸馏)。
蒸馏学习
BERT系列都是通过MLM和SEQ任务进行学习的。而tinyBERT则是蒸馏。蒸馏可以看作让参数的分布尽量靠近的意思。 很多网络是在网络的输出端蒸馏,希望整个网络的参数都学习到teacher模型。而tinyBERT则是在模型中间进行多次蒸馏。而且在整个训练过程也进行多次蒸馏。
前向过程中的多次蒸馏
tinyBERT,对于n层的teacher bert,设计了一个mapping function :n = g ( m ), 将student bert的第m层映射为原来的teacher的第n层。其实这个映射函数非常简单,就是n = k*g。k就是多少层当作tinyBERT的一层。当k=0时,对应的就是embedding layer。我们可以通过下图理解。图中仅为示例,tinyBERT每层的输出都去蒸馏学习Teacher net三层的输出,就是“一层顶三层”。
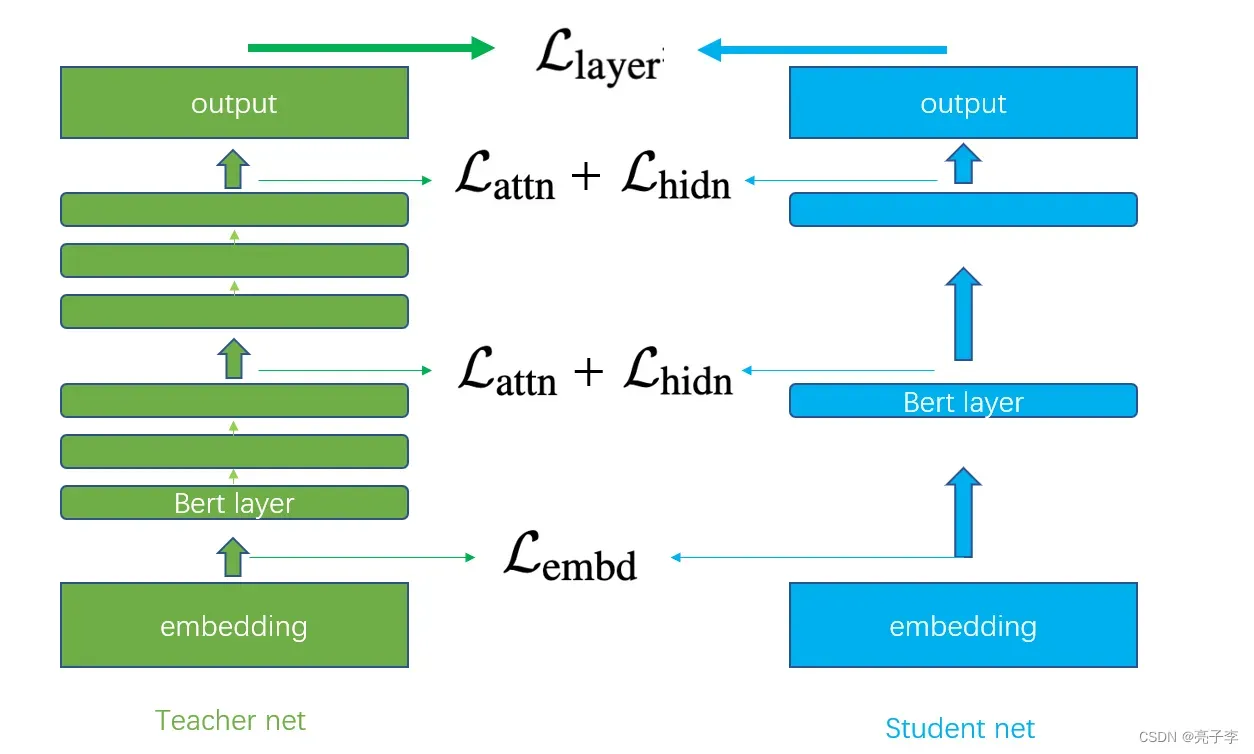
实际上的BERT-base有12层, 对于4层的tinyBERT,正好是三层对一层。 对于蒸馏学习,我们需要根据两个模型的参数或者输出来计算loss,更新模型。从上图中,我们可以看到一共有四种loss,下面分别介绍。
Embedding-layer distillation
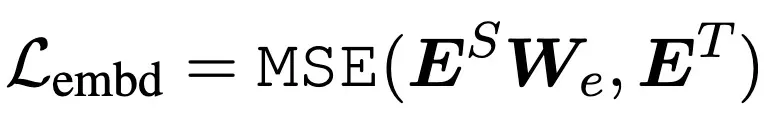
这个是对embedding 矩阵的蒸馏loss,说是矩阵,其实是计算两个模型embedding输出的MSEloss。 而因为Student的embedding层的特征维度和Teacher是不一样的,因此要乘上一个转换的映射矩阵,此矩阵在训练时学习。
Hidden states based distillation and Attention based distillation
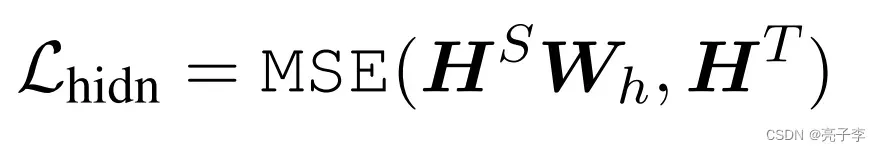
前文我们提到,BERTlayer每一层包含两部分,一个是自注意力层,一个是MLP(也就是两层全连接)。 hidden states层的蒸馏就是指的全连接层的层间蒸馏,而attention自然指的是注意力层注意力分数矩阵,也就是q和k算出来的那个值 的蒸馏学习。
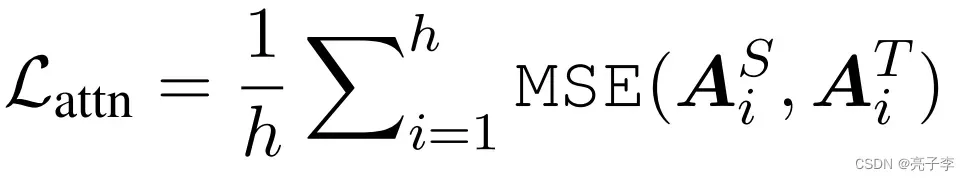
Prediction-layer distillation
这个蒸馏,属于是回归本质了。是对最终输出层输出结果的 softmax进行蒸馏学习。
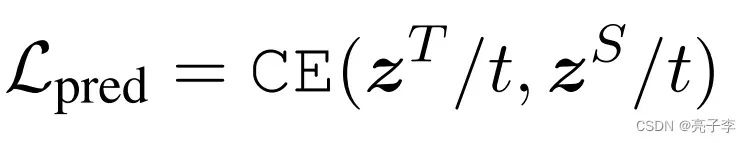
T是蒸馏学习中的温度系数。对输出蒸馏时,采用的是带温度系数的交叉熵loss。
训练过程中的多次蒸馏
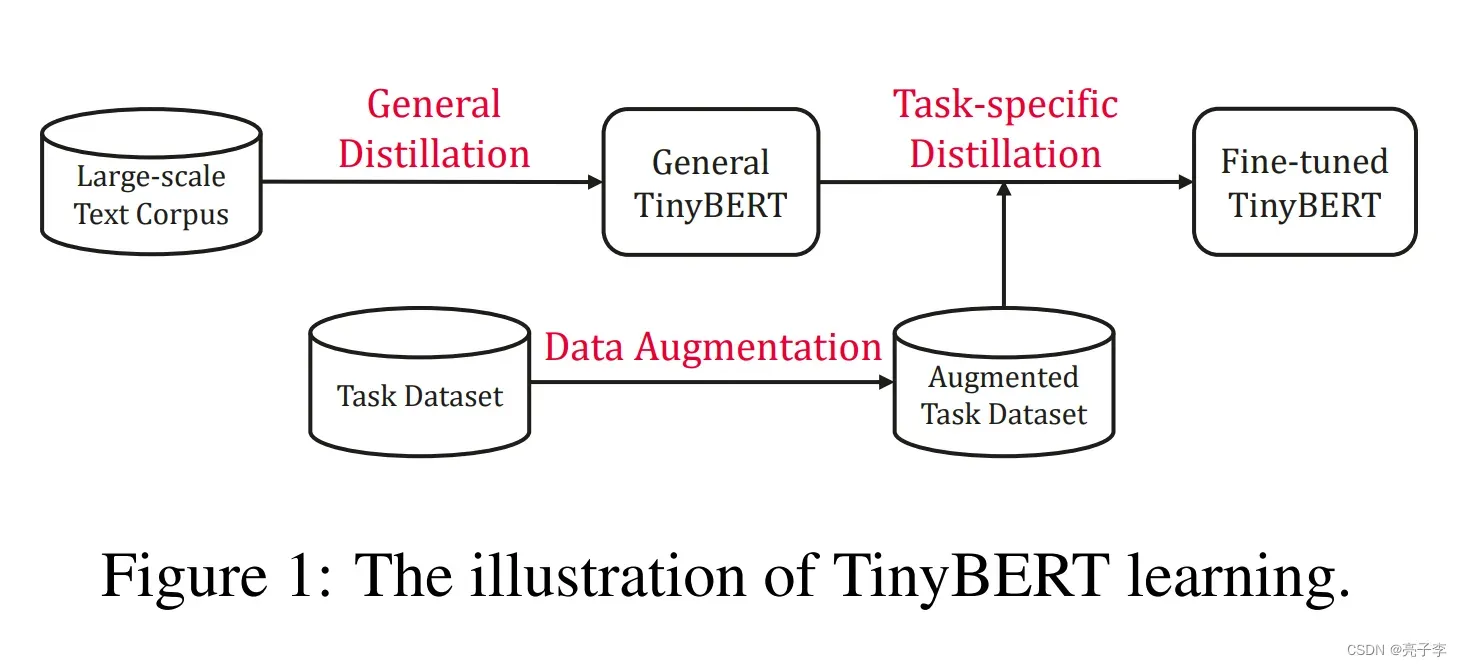
tinyBERT 并不是像其他蒸馏那样,直接根据成品的Teacher model在分类时蒸馏,而是采用了模仿teacher训练过程的方法。他的蒸馏分两步:General Distillation 与 Task-specific Distillation. 前者是模仿BERT在大规模语料库进行预训练,后者则是在特定的任务上进行分类训练。值得注意的是,在预训练蒸馏阶段,使用的Teacher 模型是仅仅经过预训练未微调的BERT,而在特定任务分类蒸馏训练阶段,使用的Teacher 模型是在特定任务上经过微调的BERT。
到这里,我们已经完成了tinyBERT的多阶段,多层次蒸馏,得到了性能很好,又很快的tinyBERT模型。oumeideta!
上代码
下载基于torch的代码,让我们看看具体的训练过程吧!
Pretrained-Language-Model/TinyBERT at master · huawei-noah/Pretrained-Language-Model · GitHub
https://huggingface.co/bert-base-uncased/tree/main
事前准备
如果你想跟我一样跑通代码,你需要下载一下内容
1, BERT-base模型
这个就是teacher模型啦。bert-base-uncased at main
2,wiki数据集。
关于WIKI下载
维基下载页面说明(指南) – 走看看
我下载的这个:
https://dumps.wikimedia.org/enwiki/20220601/enwiki-20220601-pages-articles-multistream1.xml-p1p41242.bz2
然后使用WikiExtractor提取和整理数据集中的文本,使用步骤如下
- pip install wikiextractor
- python -m wikiextractor.WikiExtractor -o 【目标文件】-b 【大小】 【源文件】
注意这个 大小 他是够多少就形成一个文件,也就是如果写了1M 就会形成很多个1M的输出文件 我用的就是1M

我用的是AA里的00号文件,我们只是跑示例而已。
glue 数据集
https://github.com/nyu-mll/GLUE-baselines
可以只下载一个任务,比如QNLI。 自行参照readme 更改任务名即可。
代码阅读
预训练蒸馏。
--pregenerated_data data --teacher_model /home/model/bert --do_lower_case --train_batch_size 4 --output_dir model --student_model config代码文件是general_distill.py
在pycharm 运行编辑配置中 输入上面的参数 。 大部分都是位置参数。自己训练的时候需要按自己的文件夹调整。 注意tiny_bert的config文件 在开头参数里,把bert的config改几个参数就行。
我们主要看的是模型的训练,所以数据,设置什么的都先不看了。 所以直接到这一步。
这是取数据,可以看到取了四个数据。可以在这里介绍一下,一句文本,会有一个tokenizer的东西对他做处理,生成3个东西。
input_ids : 代码里给每个词都编了号 ,这个就是那个号
input_mask: 输入中标记哪些词模型需要考虑,哪些不需要考虑。比如,输入长度不够时会被pad,这些pad的mask就为0,不需要考虑。
segment_ids: 标记属于哪个句子
其余的两个则是预训练任务需要的。
lm_labels_ids: 被遮盖的词的编号
is_next:输出的两个句子是不是上下文。
student_atts, student_reps = student_model(input_ids, segment_ids, input_mask)tinyBERT的前向。我们可以看看student模型的样子。
class TinyBertForPreTraining(BertPreTrainedModel):
def __init__(self, config, fit_size=768):
super(TinyBertForPreTraining, self).__init__(config)
self.bert = BertModel(config)
self.cls = BertPreTrainingHeads(
config, self.bert.embeddings.word_embeddings.weight)
self.fit_dense = nn.Linear(config.hidden_size, fit_size)
self.apply(self.init_bert_weights)
def forward(self, input_ids, token_type_ids=None,
attention_mask=None, masked_lm_labels=None,
next_sentence_label=None, labels=None):
sequence_output, att_output, pooled_output = self.bert(
input_ids, token_type_ids, attention_mask)
tmp = []
for s_id, sequence_layer in enumerate(sequence_output):
tmp.append(self.fit_dense(sequence_layer))
sequence_output = tmp
return att_output, sequence_output很简单的写法。BertModel 会根据你的设置返回一个BERT模型。他的输出是可以调控的。这里输出了三个东西。
sequence output 包含了每一层bertlayer的输出
att_output 包含了每一层的注意力分数。
pooled_output 最后一层的输出的pool值。可以取meanpool 也可以取cls。
而fit_dense就是前文所提到的,因为两个模型的特征维度不同,需要使用的转换矩阵。
cls等会再用到。(好吧 也没看到用在哪里)
teacher_reps, teacher_atts, _ = teacher_model(input_ids, segment_ids, input_mask)得到teacher的注意力分数和输出。
teacher_reps = [teacher_rep.detach() for teacher_rep in teacher_reps] # speedup 1.5x
teacher_atts = [teacher_att.detach() for teacher_att in teacher_atts]
因为是不更新teacher模型的,所以这里要把teacher模型的输出从张量图上取下来。
new_teacher_reps = [teacher_reps[i * layers_per_block] for i in range(student_layer_num + 1)]
new_student_reps = student_reps
可以看到 层数对应的计算。 取对应层的最后一层的输出。也就是第3,6,9,12层的输出。
for student_att, teacher_att in zip(student_atts, new_teacher_atts):
student_att = torch.where(student_att <= -1e2, torch.zeros_like(student_att).to(device),
student_att)
teacher_att = torch.where(teacher_att <= -1e2, torch.zeros_like(teacher_att).to(device),
teacher_att)
att_loss += loss_mse(student_att, teacher_att)计算注意力分数的loss。
new_teacher_reps = [teacher_reps[i * layers_per_block] for i in range(student_layer_num + 1)]
new_student_reps = student_reps
for student_rep, teacher_rep in zip(new_student_reps, new_teacher_reps):
rep_loss += loss_mse(student_rep, teacher_rep)你会发现 BERT的输出有13个,其中第一个是embedding的输出。 上面这个代码段,会保留0,3,6,9,12层的输出。这个loss计算 可以得到 L_hide 和L_embd。在预训练阶段 没有pred的loss。 只需要这三个loss进行回传更新模型。
任务蒸馏
在特定任务上进行蒸馏。代码是 task_distill 参数是下面的,我用的时QNLI数据集。去掉了数据增广,因为数据增广只是提前处理,而不是在训练时增广。 记得将前面预训练阶段得到的tinybert的模型保存文件名字改为: pytorch_model.bin.。torch只认这个。
–teacher_model /home/model/bert –student_model /home/reapper/tinybert/model –data_dir /home/dataset/glue/QNLI –task_name qnli –output_dir model/qnli –do_lower_case –learning_rate 3e-5 –num_train_epochs 3 –eval_step 100 –max_seq_length 128 –train_batch_size 32 –pred_distill
数据部分我就不说了,GLUE的数据都是有现成的读的方法。介绍一下QNLI,QNLI的一条数据是有两句话,然后判断两句话是蕴含关系还是非蕴含关系,也就是二分类任务。
我们直接上模型。
if not args.do_eval:
teacher_model = TinyBertForSequenceClassification.from_pretrained(args.teacher_model, num_labels=num_labels)
teacher_model.to(device)
student_model = TinyBertForSequenceClassification.from_pretrained(args.student_model, num_labels=num_labels)
student_model.to(device)我们发现他是用同一个模型读入的,前面提过了,只要config不同,结果就不同。

输入数据和上面很像。多了个seq_lengths,表示文本本身词的个数(padding前)。
student_logits, student_atts, student_reps = student_model(input_ids, segment_ids, input_mask,
is_student=True)
with torch.no_grad():
teacher_logits, teacher_atts, teacher_reps = teacher_model(input_ids, segment_ids, input_mask)
与前文一样,执行模型前向,teacher不计算梯度。不同的是,输出多了一个logits,熟悉的人都知道,这个就是分类头的输出,我们进模型内部看一下。
class TinyBertForSequenceClassification(BertPreTrainedModel):
def __init__(self, config, num_labels, fit_size=768):
super(TinyBertForSequenceClassification, self).__init__(config)
self.num_labels = num_labels
self.bert = BertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, num_labels)
self.fit_dense = nn.Linear(config.hidden_size, fit_size)
self.apply(self.init_bert_weights)
def forward(self, input_ids, token_type_ids=None, attention_mask=None,
labels=None, is_student=False):
sequence_output, att_output, pooled_output = self.bert(input_ids, token_type_ids, attention_mask,
output_all_encoded_layers=True, output_att=True)
logits = self.classifier(torch.relu(pooled_output))
tmp = []
if is_student:
for s_id, sequence_layer in enumerate(sequence_output):
tmp.append(self.fit_dense(sequence_layer))
sequence_output = tmp
return logits, att_output, sequence_output看到 出了bert外,还有一个分类头,一个用于蒸馏的线性映射fit_dense。没了,就这么简简单单。从bert得到pool的特征后,直接relu分类就完事了。
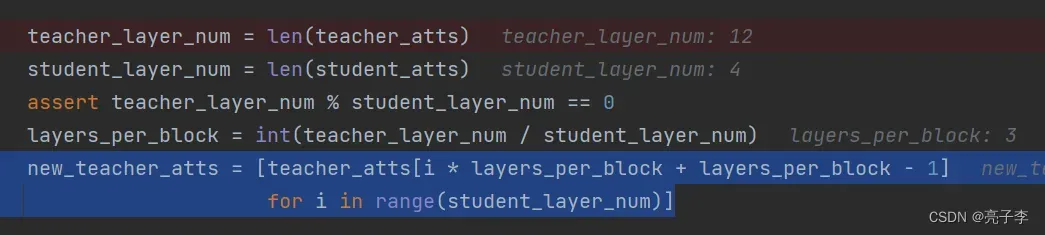
teacher_layer_num = len(teacher_atts)
student_layer_num = len(student_atts)
assert teacher_layer_num % student_layer_num == 0
layers_per_block = int(teacher_layer_num / student_layer_num)
new_teacher_atts = [teacher_atts[i * layers_per_block + layers_per_block - 1]
for i in range(student_layer_num)]
for student_att, teacher_att in zip(student_atts, new_teacher_atts):
student_att = torch.where(student_att <= -1e2, torch.zeros_like(student_att).to(device),
student_att)
teacher_att = torch.where(teacher_att <= -1e2, torch.zeros_like(teacher_att).to(device),
teacher_att)
tmp_loss = loss_mse(student_att, teacher_att)
att_loss += tmp_lossatt_loss: 与预训练时一致。
new_teacher_reps = [teacher_reps[i * layers_per_block] for i in range(student_layer_num + 1)]
new_student_reps = student_reps
for student_rep, teacher_rep in zip(new_student_reps, new_teacher_reps):
tmp_loss = loss_mse(student_rep, teacher_rep)
rep_loss += tmp_losshideloss 和 embdloss 与预训练一致。
if not args.pred_distill:
else:
if output_mode == "classification":
cls_loss = soft_cross_entropy(student_logits / args.temperature,
teacher_logits / args.temperature)
elif output_mode == "regression":
loss_mse = MSELoss()
cls_loss = loss_mse(student_logits.view(-1), label_ids.view(-1))
loss = cls_losspred loss 我们可以看到,他是有开关的,也就是可以选择不训练。 他这里是 如果是蒸馏前面的层,这里就不用蒸馏分类层了。 相当于bert输出已经蒸馏过了。 如果不蒸馏前面的层,就蒸馏分类层,。
我们现在是分类模式,所以loss是用softCE计算的,如果你看了模型蒸馏,你肯定知道这个东西。其实就是本来对于分类任务,他的target都是one-hot形式的:【0,1】 这样的,现在变成了【0.1,0.9】这样的。 这也是蒸馏的原理之一。 温度系数这里是1.
至此,我们得到了所有的四个loss 回传即可完成模型训练。
事后
至此,我们完成了tinyBERT的训练,得到了一个快速版的BERT。
代码我读起来很快,主要因为我对bert和transformer已经有了很深的了解。 如果对BERT不了解,这个博客也是很好的机会,你可以慢慢调试,一步一步的看BERT内部是怎么构成的,向量在里面是如何传递的。
这篇博文大部分内容来自个人经验和论文,如果有什么错误,请联系我,谢谢。
文章出处登录后可见!