今天继续给大家介绍Python爬虫相关知识,本文主要内容是Python爬虫 xpath解析基础。
一、xpath简介
xpath,即XML Path Language,是一种用来确定XML文档中某部分位置的语言,Xpath以XML为基础,可以提供用户在数据结构树中寻找数据节点的能力,也常常被用于Python爬虫中对于HTML文档的解析。并且相对于re正则表达式和BeautifulSoup相比,xpath具有便捷高效的特点,且具有一定的通用性。
要使用xpath进行解析,那么首先需要安装lxml库,安装命令为:
pip install lxml
二、xpath简单使用
在lxml库中,存在一个etree的对象,如果想使用xpath进行解析,那么就需要先从lxml库中引入该对象,执行命令:
from lxml import etree
在代码中,我们首先需要实例化一个etree对象,然后将被解析的页面源码数据加载到该对象中,然后调用etree对象的xpath方法,利用xpath表达式,就可以实现指定标签的定位和标签内容的捕获。
将页面源码数据加载到该对象中代码如下所示:
page_text=requests.get(url).text
tree=etree.HTML()
此外,xpath还支持从本地的html文档中导入数据,代码如下所示:
tree=etree.parse(FilePath)
使用xpath方法进行标签定位和内容捕获代码如下所示:
tree.xpath(【xpath表达式】)
三、xpath表达式
实际上,在xpath解析中,最重要的就是xpath表达式,xpath表达式决定了我们可以提取出什么样的数据。xpath表达式是一个指定格式的字符串,xpath方法返回的是一个列表,列表中存储的是符合xpath表达式的element对象。
(一)xpath表达式层级递进关系表示
xpath表达式采用层级关系来定位数据,斜杠“/”表示层级关系的递进。例如:
'/html/head/title'
即表示从根节点出发,根节点下的html标签下的head标签下的title标签。
单个斜杠表示一层递进,我们也可以采用两个斜杠来表示多层关系递减,例如:
'/html/body//div'
就可以提取html标签下的body标签下的的所有的div标签。
此外,当我们获取一个标签后,还可以以该标签为基础,再次提取该标签下的子标签,例如:
tree1=tree.xpath('//div[@class="test"]')[0]
tree2=tree1.xpath('./p/a//text()')
在上述代码中,我们第一次使用了正常的xpath表达式提取除了div标签,因为该xpath函数返回的结果是一个列表,因此在这里我们必须取出列表中的元素。这样,tree1即是一个div标签。在第二次使用xpath表达式时,我们以tree1为基础,在xpath表达式中使用了“./”表示本级,这样就可以以tree1中提取出的div标签为基础,进而提取该div标签下的标签了。
(二)xpath表达式标签属性定位和索引定位
xpath表达式还支持属性定位,我们可以使用如下格式:
[@【属性变量】="【属性值】"]
来定位指定属性的元素,例如:
'//div[@id="item"]'
这种xpath表达式就可以定位id属性为item的div标签。
xpath除了可以使用标签属性进行定位以外,还可以使用标签索引进行定位,例如:
'//div[@id="item"]/p[1]'
上述xpath表达式表示在指定的div标签下的第一个p标签,这里的标签索引从1开始计数。
(三)xpath表达式获取标签文本和属性
xpath表达式还支持获取标签的文本,例如:
'//div[@class="text"/a/text()]'
就可以获取指定的a标签下的文本,如果我们把上述xpath表达式修改为:
'//div[@class="text"]/a//text()'
那么也可以获取指定的a标签下的文本,这两者之间的区别在于后者的xpath表达式中text()方法前面存在两条斜杠,而前者的xpath表达式中的text()方法前面只有一条斜杠。结果中的区别在于前者只能够获取a标签中直系文本,而后者可以获取a标签中的所有文本,即如果a标签里面还有别的标签,那么两条斜杠的xpath表达式可以获取这些标签下的所有标签中的文本。
xpath表达式也可以获取标签中的数据,例如:
'//div[@class=text]//a/@href'
上述xpath表达式就可以获取指定a标签中的href属性。
四、xpath解析示例
为了让大家更好的理解xpath解析,简单编写了一段简单的python代码,代码如下所示:
from lxml import etree
import requests
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"}
page_text=requests.get(url='https://www.baidu.com/',headers=headers).text
tree=etree.HTML(page_text)
#使用xpath表达式层级递进关系获取标签
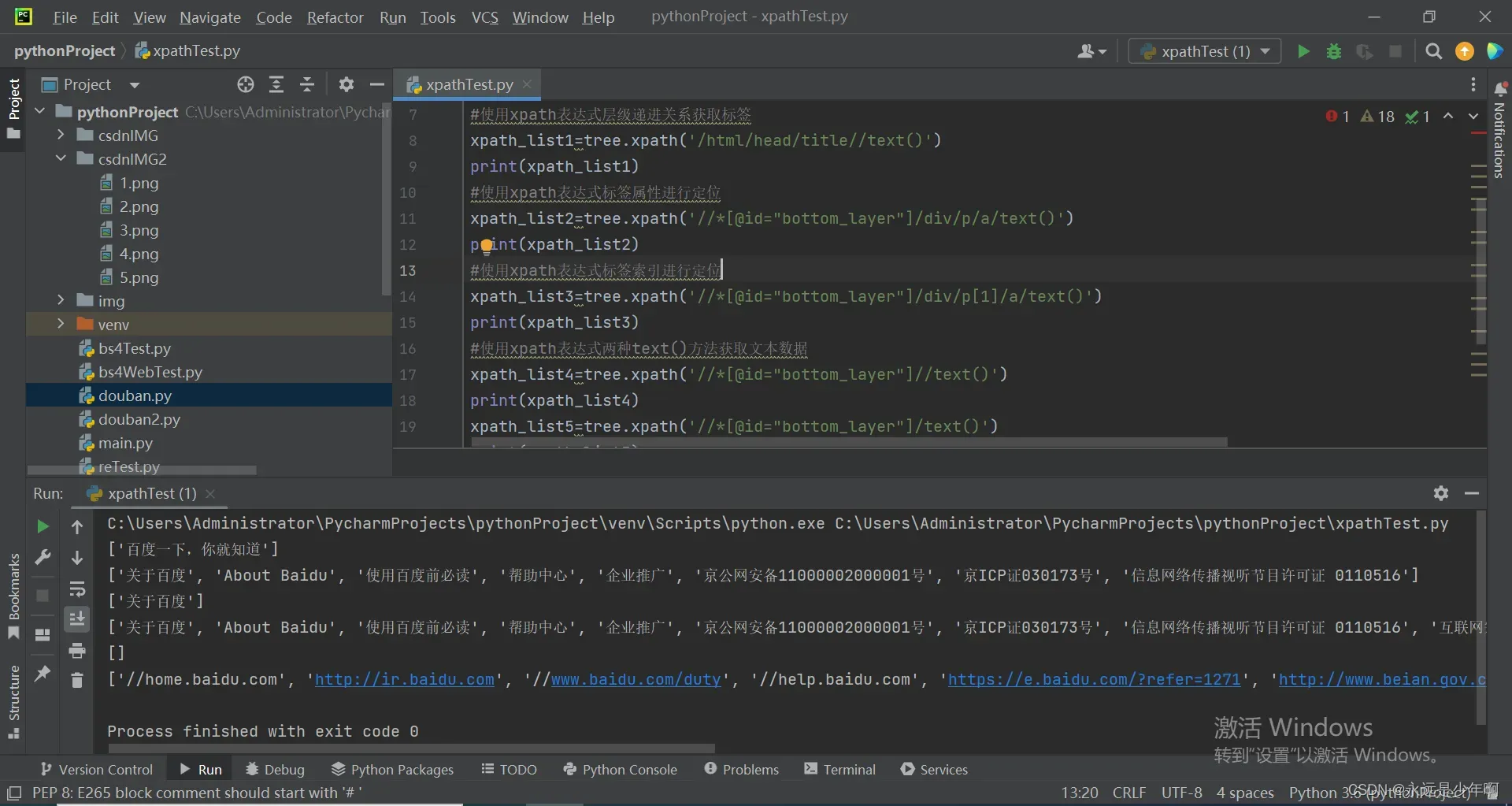
xpath_list1=tree.xpath('/html/head/title//text()')
print(xpath_list1)
#使用xpath表达式标签属性进行定位
xpath_list2=tree.xpath('//*[@id="bottom_layer"]/div/p/a/text()')
print(xpath_list2)
#使用xpath表达式标签索引进行定位
xpath_list3=tree.xpath('//*[@id="bottom_layer"]/div/p[1]/a/text()')
print(xpath_list3)
#使用xpath表达式两种text()方法获取文本数据
xpath_list4=tree.xpath('//*[@id="bottom_layer"]//text()')
print(xpath_list4)
xpath_list5=tree.xpath('//*[@id="bottom_layer"]/text()')
print(xpath_list5)
#使用xpath表达式获取标签中的属性
xpath_list6=tree.xpath('//*[@id="bottom_layer"]//a/@href')
print(xpath_list6)
上述代码执行结果如下所示:
五、通过浏览器获得xpath表达式
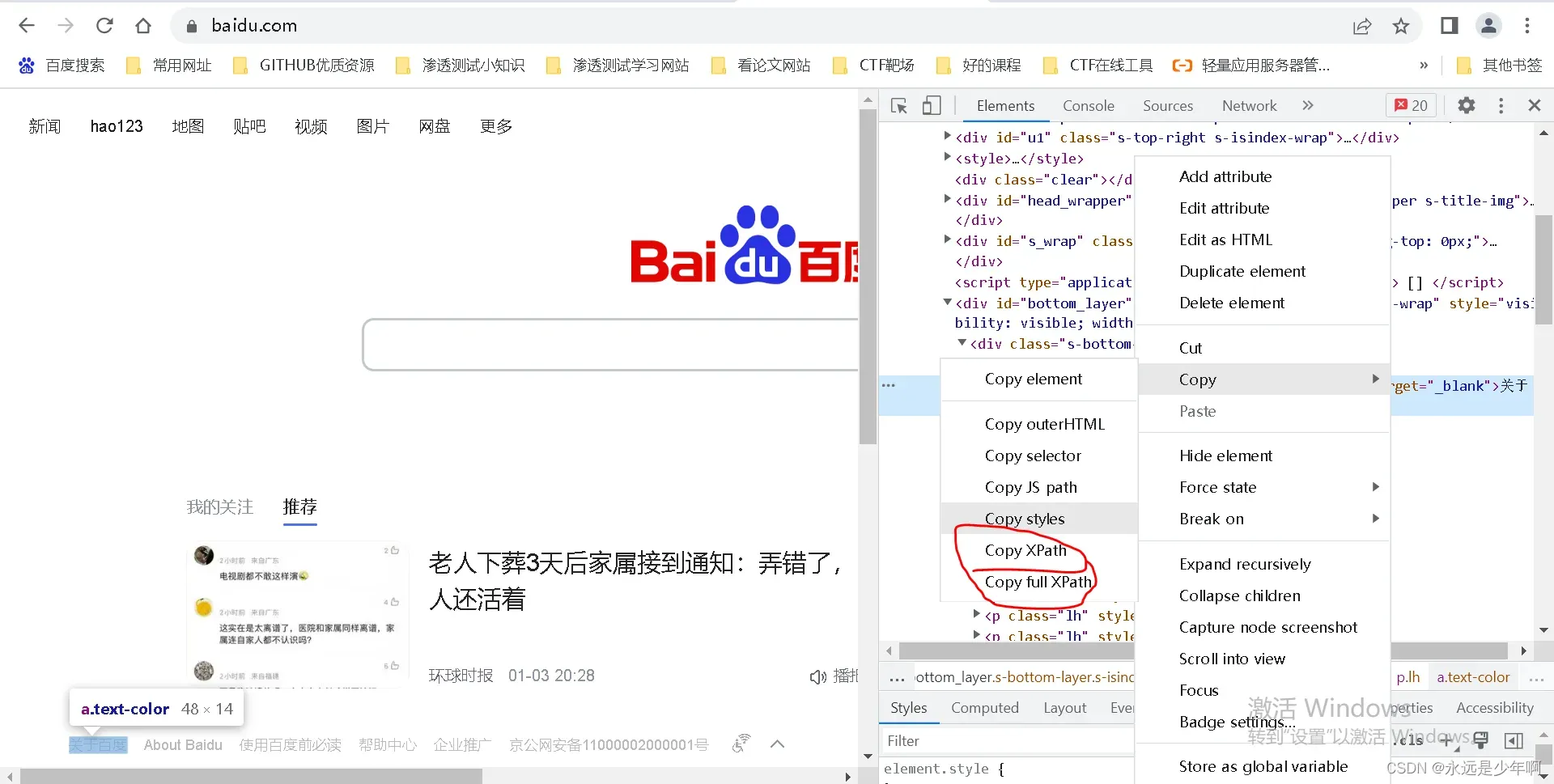
我们在学习了上述xpath表达式以后,就可以很方便的使用xpath表达式来提取数据了。但是对于一个比较复杂的网页,使用xpath表达式来提取数据是一件不那么简单的事情。然而,现在的浏览器有自动复制xpath表达式的功能,我们在打开浏览器开发者工具后,就可以在里面直接复制xpath表达式了,如下所示:
原创不易,转载请说明出处:https://blog.csdn.net/weixin_40228200
文章出处登录后可见!