一、人脸修复算法
1.算法简介
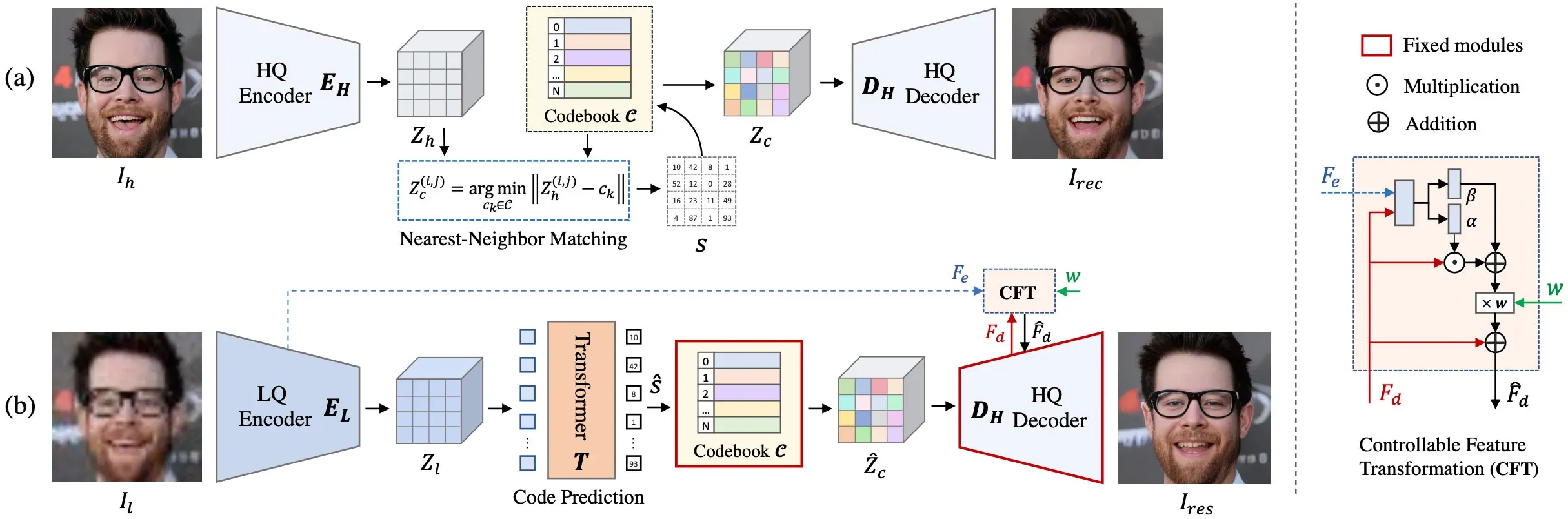
CodeFormer是一种基于AI技术深度学习的人脸复原模型,由南洋理工大学和商汤科技联合研究中心联合开发,它能够接收模糊或马赛克图像作为输入,并生成更清晰的原始图像。算法源码地址:https://github.com/sczhou/CodeFormer
这种技术在图像修复、图像增强和隐私保护等领域可能会有广泛的应用。算法是由南洋理工大学和商汤科技联合研究中心联合开发的,结合了VQGAN和Transformer。
VQGAN是一个生成模型,通常用于图像生成任务。它使用了向量量化技术,将图像编码成一系列离散的向量,然后通过解码器将这些向量转化为图像。这种方法通常能够生成高质量的图像,尤其在与Transformer等神经网络结合使用时。
Transformer是一种广泛用于自然语言处理和计算机视觉等领域的神经网络架构。它在序列数据处理中表现出色,也可以用于图像生成和处理任务。
在监控、安全和隐私保护领域,人脸图像通常会受到多种因素的影响,其中包括光照、像素限制、聚焦问题和人体运动等。这些因素可能导致图像模糊、变形或者包含大量的噪声。在这种情况下,尝试恢复清晰的原始人脸图像是一个极具挑战性的任务。
盲人脸复原是一个不适定问题(ill-posed problem),这意味着存在多个可能的解决方案,而且从有限的观察数据中无法唯一确定真实的原始图像。因此,在这个领域中,通常需要依赖先进的计算机视觉和图像处理技术,以及深度学习模型,来尝试改善模糊或受损图像的质量。
一些方法和技术可以用于处理盲人脸复原问题,包括但不限于:
深度学习模型: 使用卷积神经网络(CNN)和生成对抗网络(GAN)等深度学习模型,可以尝试从模糊或变形的人脸图像中恢复原始细节。
超分辨率技术: 超分辨率方法旨在从低分辨率图像中重建高分辨率图像,这也可以用于人脸图像复原。
先验知识: 利用先验知识,如人脸结构、光照模型等,可以帮助提高复原的准确性。
多模态融合: 结合不同传感器和信息源的数据,可以提高复原的鲁棒性。
然而,即使使用这些技术,由于问题的不适定性,完全恢复清晰的原始人脸图像仍然可能是一项极具挑战性的任务,特别是在极端条件下。在实际应用中,可能需要权衡图像质量和可用的信息,以达到最佳的结果。
2.算法效果
在官方公布修复的人脸效果里面,可以看到算法在各种输入的修复效果:
老照片修复

人脸修复

黑白人脸图像增强修复

人脸恢复

二、模型部署
如果想用C++进行模型推理部署,首先要把模型转换成onnx,转成onnx就可以使用onnxruntime c++库进行部署,或者使用OpenCV的DNN也可以,转成onnx后,还可以再转成ncnn模型使用ncnn进行模型部署。原模型可以从官方开源界面可以下载。
模型推理这块有两种做法,一是不用判断有没有人脸,直接对全图进行超分,但这种方法好像对本来是清晰的图像会出现bug,就是生成一些无法理解的处理。
1. C++使用onnxruntime部署模型
#include "CodeFormer.h"
CodeFormer::CodeFormer(std::string model_path)
{
//OrtStatus* status = OrtSessionOptionsAppendExecutionProvider_CUDA(sessionOptions, 0); ///nvidia-cuda加速
sessionOptions.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);
std::wstring widestr = std::wstring(model_path.begin(), model_path.end()); ///如果在windows系统就这么写
ort_session = new Ort::Session(env, widestr.c_str(), sessionOptions); ///如果在windows系统就这么写
///ort_session = new Session(env, model_path.c_str(), sessionOptions); ///如果在linux系统,就这么写
size_t numInputNodes = ort_session->GetInputCount();
size_t numOutputNodes = ort_session->GetOutputCount();
Ort::AllocatorWithDefaultOptions allocator;
for (int i = 0; i < numInputNodes; i++)
{
input_names.push_back(ort_session->GetInputName(i, allocator));
Ort::TypeInfo input_type_info = ort_session->GetInputTypeInfo(i);
auto input_tensor_info = input_type_info.GetTensorTypeAndShapeInfo();
auto input_dims = input_tensor_info.GetShape();
input_node_dims.push_back(input_dims);
}
for (int i = 0; i < numOutputNodes; i++)
{
output_names.push_back(ort_session->GetOutputName(i, allocator));
Ort::TypeInfo output_type_info = ort_session->GetOutputTypeInfo(i);
auto output_tensor_info = output_type_info.GetTensorTypeAndShapeInfo();
auto output_dims = output_tensor_info.GetShape();
output_node_dims.push_back(output_dims);
}
this->inpHeight = input_node_dims[0][2];
this->inpWidth = input_node_dims[0][3];
this->outHeight = output_node_dims[0][2];
this->outWidth = output_node_dims[0][3];
input2_tensor.push_back(0.5);
}
void CodeFormer::preprocess(cv::Mat &srcimg)
{
cv::Mat dstimg;
cv::cvtColor(srcimg, dstimg, cv::COLOR_BGR2RGB);
resize(dstimg, dstimg, cv::Size(this->inpWidth, this->inpHeight), cv::INTER_LINEAR);
this->input_image_.resize(this->inpWidth * this->inpHeight * dstimg.channels());
int k = 0;
for (int c = 0; c < 3; c++)
{
for (int i = 0; i < this->inpHeight; i++)
{
for (int j = 0; j < this->inpWidth; j++)
{
float pix = dstimg.ptr<uchar>(i)[j * 3 + c];
this->input_image_[k] = (pix / 255.0 - 0.5) / 0.5;
k++;
}
}
}
}
cv::Mat CodeFormer::detect(cv::Mat &srcimg)
{
int im_h = srcimg.rows;
int im_w = srcimg.cols;
this->preprocess(srcimg);
std::array<int64_t, 4> input_shape_{ 1, 3, this->inpHeight, this->inpWidth };
std::vector<int64_t> input2_shape_ = { 1 };
auto allocator_info = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);
std::vector<Ort::Value> ort_inputs;
ort_inputs.push_back(Ort::Value::CreateTensor<float>(allocator_info, input_image_.data(), input_image_.size(), input_shape_.data(), input_shape_.size()));
ort_inputs.push_back(Ort::Value::CreateTensor<double>(allocator_info, input2_tensor.data(), input2_tensor.size(), input2_shape_.data(), input2_shape_.size()));
std::vector<Ort::Value> ort_outputs = ort_session->Run(Ort::RunOptions{ nullptr }, input_names.data(), ort_inputs.data(), ort_inputs.size(), output_names.data(), output_names.size());
post_process
float* pred = ort_outputs[0].GetTensorMutableData<float>();
//cv::Mat mask(outHeight, outWidth, CV_32FC3, pred); /经过试验,直接这样赋值,是不行的
const unsigned int channel_step = outHeight * outWidth;
std::vector<cv::Mat> channel_mats;
cv::Mat rmat(outHeight, outWidth, CV_32FC1, pred); // R
cv::Mat gmat(outHeight, outWidth, CV_32FC1, pred + channel_step); // G
cv::Mat bmat(outHeight, outWidth, CV_32FC1, pred + 2 * channel_step); // B
channel_mats.push_back(rmat);
channel_mats.push_back(gmat);
channel_mats.push_back(bmat);
cv::Mat mask;
merge(channel_mats, mask); // CV_32FC3 allocated
///不用for循环遍历cv::Mat里的每个像素值,实现numpy.clip函数
mask.setTo(this->min_max[0], mask < this->min_max[0]);
mask.setTo(this->min_max[1], mask > this->min_max[1]); 也可以用threshold函数,阈值类型THRESH_TOZERO_INV
mask = (mask - this->min_max[0]) / (this->min_max[1] - this->min_max[0]);
mask *= 255.0;
mask.convertTo(mask, CV_8UC3);
//cvtColor(mask, mask, cv::COLOR_BGR2RGB);
return mask;
}
void CodeFormer::detect_video(const std::string& video_path,const std::string& output_path, unsigned int writer_fps)
{
cv::VideoCapture video_capture(video_path);
if (!video_capture.isOpened())
{
std::cout << "Can not open video: " << video_path << "\n";
return;
}
cv::Size S = cv::Size((int)video_capture.get(cv::CAP_PROP_FRAME_WIDTH),
(int)video_capture.get(cv::CAP_PROP_FRAME_HEIGHT));
cv::VideoWriter output_video(output_path, cv::VideoWriter::fourcc('m', 'p', '4', 'v'),
30.0, S);
if (!output_video.isOpened())
{
std::cout << "Can not open writer: " << output_path << "\n";
return;
}
cv::Mat cv_mat;
while (video_capture.read(cv_mat))
{
cv::Mat cv_dst = detect(cv_mat);
output_video << cv_dst;
}
video_capture.release();
output_video.release();
}
先试试官方给的样本的效果:

薄马赛克的超分效果:


厚马赛克的超分效果不是很好,就是有点贴脸的感觉:

如果是已经是清晰的图像,超分之后不是很理想,基本上是不能用的,onnx这个效果只能优化人脸:


2.onnx模型python推理
import os
import cv2
import argparse
import glob
import torch
import torch.onnx
from torchvision.transforms.functional import normalize
from basicsr.utils import imwrite, img2tensor, tensor2img
from basicsr.utils.download_util import load_file_from_url
from basicsr.utils.misc import gpu_is_available, get_device
from facelib.utils.face_restoration_helper import FaceRestoreHelper
from facelib.utils.misc import is_gray
import onnxruntime as ort
from basicsr.utils.registry import ARCH_REGISTRY
pretrain_model_url = {
'restoration': 'https://github.com/sczhou/CodeFormer/releases/download/v0.1.0/codeformer.pth',
}
if __name__ == '__main__':
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device = get_device()
parser = argparse.ArgumentParser()
parser.add_argument('-i', '--input_path', type=str, default='./inputs/whole_imgs',
help='Input image, video or folder. Default: inputs/whole_imgs')
parser.add_argument('-o', '--output_path', type=str, default=None,
help='Output folder. Default: results/<input_name>_<w>')
parser.add_argument('-w', '--fidelity_weight', type=float, default=0.5,
help='Balance the quality and fidelity. Default: 0.5')
parser.add_argument('-s', '--upscale', type=int, default=2,
help='The final upsampling scale of the image. Default: 2')
parser.add_argument('--has_aligned', action='store_true', help='Input are cropped and aligned faces. Default: False')
parser.add_argument('--only_center_face', action='store_true', help='Only restore the center face. Default: False')
parser.add_argument('--draw_box', action='store_true', help='Draw the bounding box for the detected faces. Default: False')
# large det_model: 'YOLOv5l', 'retinaface_resnet50'
# small det_model: 'YOLOv5n', 'retinaface_mobile0.25'
parser.add_argument('--detection_model', type=str, default='retinaface_resnet50',
help='Face detector. Optional: retinaface_resnet50, retinaface_mobile0.25, YOLOv5l, YOLOv5n, dlib. \
Default: retinaface_resnet50')
parser.add_argument('--bg_upsampler', type=str, default='None', help='Background upsampler. Optional: realesrgan')
parser.add_argument('--face_upsample', action='store_true', help='Face upsampler after enhancement. Default: False')
parser.add_argument('--bg_tile', type=int, default=400, help='Tile size for background sampler. Default: 400')
parser.add_argument('--suffix', type=str, default=None, help='Suffix of the restored faces. Default: None')
parser.add_argument('--save_video_fps', type=float, default=None, help='Frame rate for saving video. Default: None')
args = parser.parse_args()
# ------------------------ input & output ------------------------
w = args.fidelity_weight
input_video = False
if args.input_path.endswith(('jpg', 'jpeg', 'png', 'JPG', 'JPEG', 'PNG')): # input single img path
input_img_list = [args.input_path]
result_root = f'results/test_img_{w}'
# elif args.input_path.endswith(('mp4', 'mov', 'avi', 'MP4', 'MOV', 'AVI')): # input video path
# from basicsr.utils.video_util import VideoReader, VideoWriter
# input_img_list = []
# vidreader = VideoReader(args.input_path)
# image = vidreader.get_frame()
# while image is not None:
# input_img_list.append(image)
# image = vidreader.get_frame()
# audio = vidreader.get_audio()
# fps = vidreader.get_fps() if args.save_video_fps is None else args.save_video_fps
# video_name = os.path.basename(args.input_path)[:-4]
# result_root = f'results/{video_name}_{w}'
# input_video = True
# vidreader.close()
# else: # input img folder
# if args.input_path.endswith('/'): # solve when path ends with /
# args.input_path = args.input_path[:-1]
# # scan all the jpg and png images
# input_img_list = sorted(glob.glob(os.path.join(args.input_path, '*.[jpJP][pnPN]*[gG]')))
# result_root = f'results/{os.path.basename(args.input_path)}_{w}'
else:
raise ValueError("wtf???")
if not args.output_path is None: # set output path
result_root = args.output_path
test_img_num = len(input_img_list)
if test_img_num == 0:
raise FileNotFoundError('No input image/video is found...\n'
'\tNote that --input_path for video should end with .mp4|.mov|.avi')
# # ------------------ set up background upsampler ------------------
# if args.bg_upsampler == 'realesrgan':
# bg_upsampler = set_realesrgan()
# else:
# bg_upsampler = None
# # ------------------ set up face upsampler ------------------
# if args.face_upsample:
# if bg_upsampler is not None:
# face_upsampler = bg_upsampler
# else:
# face_upsampler = set_realesrgan()
# else:
# face_upsampler = None
# ------------------ set up CodeFormer restorer -------------------
net = ARCH_REGISTRY.get('CodeFormer')(dim_embd=512, codebook_size=1024, n_head=8, n_layers=9,
connect_list=['32', '64', '128', '256']).to(device)
# ckpt_path = 'weights/CodeFormer/codeformer.pth'
ckpt_path = load_file_from_url(url=pretrain_model_url['restoration'],
model_dir='weights/CodeFormer', progress=True, file_name=None)
checkpoint = torch.load(ckpt_path)['params_ema']
net.load_state_dict(checkpoint)
net.eval()
# # ------------------ set up FaceRestoreHelper -------------------
# # large det_model: 'YOLOv5l', 'retinaface_resnet50'
# # small det_model: 'YOLOv5n', 'retinaface_mobile0.25'
# if not args.has_aligned:
# print(f'Face detection model: {args.detection_model}')
# # if bg_upsampler is not None:
# # print(f'Background upsampling: True, Face upsampling: {args.face_upsample}')
# # else:
# # print(f'Background upsampling: False, Face upsampling: {args.face_upsample}')
# else:
# raise ValueError("wtf???")
face_helper = FaceRestoreHelper(
args.upscale,
face_size=512,
crop_ratio=(1, 1),
# det_model = args.detection_model,
# save_ext='png',
# use_parse=True,
# device=device
)
# -------------------- start to processing ---------------------
for i, img_path in enumerate(input_img_list):
# # clean all the intermediate results to process the next image
# face_helper.clean_all()
if isinstance(img_path, str):
img_name = os.path.basename(img_path)
basename, ext = os.path.splitext(img_name)
print(f'[{i+1}/{test_img_num}] Processing: {img_name}')
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
# else: # for video processing
# basename = str(i).zfill(6)
# img_name = f'{video_name}_{basename}' if input_video else basename
# print(f'[{i+1}/{test_img_num}] Processing: {img_name}')
# img = img_path
if args.has_aligned:
# the input faces are already cropped and aligned
img = cv2.resize(img, (512, 512), interpolation=cv2.INTER_LINEAR)
# face_helper.is_gray = is_gray(img, threshold=10)
# if face_helper.is_gray:
# print('Grayscale input: True')
face_helper.cropped_faces = [img]
# else:
# face_helper.read_image(img)
# # get face landmarks for each face
# num_det_faces = face_helper.get_face_landmarks_5(
# only_center_face=args.only_center_face, resize=640, eye_dist_threshold=5)
# print(f'\tdetect {num_det_faces} faces')
# # align and warp each face
# face_helper.align_warp_face()
else:
raise ValueError("wtf???")
# face restoration for each cropped face
for idx, cropped_face in enumerate(face_helper.cropped_faces):
# prepare data
cropped_face_t = img2tensor(cropped_face / 255., bgr2rgb=True, float32=True)
normalize(cropped_face_t, (0.5, 0.5, 0.5), (0.5, 0.5, 0.5), inplace=True)
cropped_face_t = cropped_face_t.unsqueeze(0).to(device)
try:
with torch.no_grad():
# output = net(cropped_face_t, w=w, adain=True)[0]
# output = net(cropped_face_t)[0]
output = net(cropped_face_t, w)[0]
restored_face = tensor2img(output, rgb2bgr=True, min_max=(-1, 1))
del output
# torch.cuda.empty_cache()
except Exception as error:
print(f'\tFailed inference for CodeFormer: {error}')
restored_face = tensor2img(cropped_face_t, rgb2bgr=True, min_max=(-1, 1))
# now, export the "net" codeformer to onnx
print("Exporting CodeFormer to ONNX...")
torch.onnx.export(net,
# (cropped_face_t,),
(cropped_face_t,w),
"codeformer.onnx",
# verbose=True,
export_params=True,
opset_version=11,
do_constant_folding=True,
input_names = ['x','w'],
output_names = ['y'],
)
# now, try to load the onnx model and run it
print("Loading CodeFormer ONNX...")
ort_session = ort.InferenceSession("codeformer.onnx", providers=['CPUExecutionProvider'])
print("Running CodeFormer ONNX...")
ort_inputs = {
ort_session.get_inputs()[0].name: cropped_face_t.cpu().numpy(),
ort_session.get_inputs()[1].name: torch.tensor(w).double().cpu().numpy(),
}
ort_outs = ort_session.run(None, ort_inputs)
restored_face_onnx = tensor2img(torch.from_numpy(ort_outs[0]), rgb2bgr=True, min_max=(-1, 1))
restored_face_onnx = restored_face_onnx.astype('uint8')
restored_face = restored_face.astype('uint8')
print("Comparing CodeFormer outputs...")
# see how similar the outputs are: flatten and then compute all the differences
diff = (restored_face_onnx.astype('float32') - restored_face.astype('float32')).flatten()
# calculate min, max, mean, and std
min_diff = diff.min()
max_diff = diff.max()
mean_diff = diff.mean()
std_diff = diff.std()
print(f"Min diff: {min_diff}, Max diff: {max_diff}, Mean diff: {mean_diff}, Std diff: {std_diff}")
# face_helper.add_restored_face(restored_face, cropped_face)
face_helper.add_restored_face(restored_face_onnx, cropped_face)
# # paste_back
# if not args.has_aligned:
# # upsample the background
# if bg_upsampler is not None:
# # Now only support RealESRGAN for upsampling background
# bg_img = bg_upsampler.enhance(img, outscale=args.upscale)[0]
# else:
# bg_img = None
# face_helper.get_inverse_affine(None)
# # paste each restored face to the input image
# if args.face_upsample and face_upsampler is not None:
# restored_img = face_helper.paste_faces_to_input_image(upsample_img=bg_img, draw_box=args.draw_box, face_upsampler=face_upsampler)
# else:
# restored_img = face_helper.paste_faces_to_input_image(upsample_img=bg_img, draw_box=args.draw_box)
# save faces
for idx, (cropped_face, restored_face) in enumerate(zip(face_helper.cropped_faces, face_helper.restored_faces)):
# save cropped face
if not args.has_aligned:
save_crop_path = os.path.join(result_root, 'cropped_faces', f'{basename}_{idx:02d}.png')
imwrite(cropped_face, save_crop_path)
# save restored face
if args.has_aligned:
save_face_name = f'{basename}.png'
else:
save_face_name = f'{basename}_{idx:02d}.png'
if args.suffix is not None:
save_face_name = f'{save_face_name[:-4]}_{args.suffix}.png'
save_restore_path = os.path.join(result_root, 'restored_faces', save_face_name)
imwrite(restored_face, save_restore_path)
# # save restored img
# if not args.has_aligned and restored_img is not None:
# if args.suffix is not None:
# basename = f'{basename}_{args.suffix}'
# save_restore_path = os.path.join(result_root, 'final_results', f'{basename}.png')
# imwrite(restored_img, save_restore_path)
# # save enhanced video
# if input_video:
# print('Video Saving...')
# # load images
# video_frames = []
# img_list = sorted(glob.glob(os.path.join(result_root, 'final_results', '*.[jp][pn]g')))
# for img_path in img_list:
# img = cv2.imread(img_path)
# video_frames.append(img)
# # write images to video
# height, width = video_frames[0].shape[:2]
# if args.suffix is not None:
# video_name = f'{video_name}_{args.suffix}.png'
# save_restore_path = os.path.join(result_root, f'{video_name}.mp4')
# vidwriter = VideoWriter(save_restore_path, height, width, fps, audio)
# for f in video_frames:
# vidwriter.write_frame(f)
# vidwriter.close()
print(f'\nAll results are saved in {result_root}')
文章出处登录后可见!