目录
前言
时至如今Pandas仍然是十分火热的基于Python的数据分析工具,与numpy、matplotlib称为数据分析三大巨头,是学习Python数据分析的必经之路。Pandas提供了大量能使我们快速便捷地处理数据的函数和方法,它是使Python成为强大而高效的数据分析环境的重要因素之一。因此我们做分布式数据分析也同样离不开Pandas的支持。Spark中的PySpark是内嵌有Pandas接口的:
使用方式和直接使用Pandas库是有所不同的,本篇文章将使用pyspark的pandas和pandas两种数据操作方式来展示pyspark的pandas该如何灵活使用来进行数据分析。
文章还是紧接上篇文章:
PySpark数据分析基础:PySpark基础功能及基础语法详解
一、Pandas数据结构
Pandas数据结构是通用了,共有六种数据结构,想要详细了解可以去看我这篇文章:一文速学-数据分析之Pandas数据结构和基本操作代码:
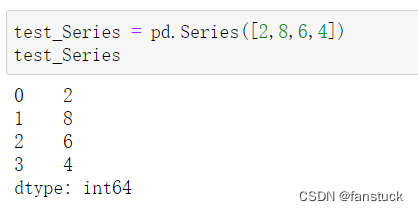
1.Series
Series要理解很简单,就像它的单词为系列的意思。类似与数据结构中的字典有索引和对应值,也可以理解为数组,在Series中的下标1,2,3,…索引对应它的不同值。
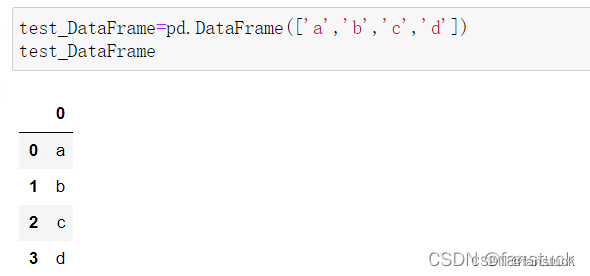
2.DataFrame
刚才从Series转化为DataFrame就可以看出DataFrame的格式就像一张表格,包含行和列索引。通过对应的行列对DataFrame进行操作,更像是对SQL中表格处理,两者有一定的类似之处。因此学过SQL的对DataFrane的操作更容易了解。
3.Time-Series
以时间为索引的Series。

4.Panel
三维的数组,可以理解为DataFrame的容器。
5.Panel4D
像Panel一样的4维数据容器。
6.PanelND
拥有factory集合,可以创建像Panel4D一样N维命名容器的模块。
后面四个用的场景十分少见,Series和DataFrame是最常用的数据类型,掌握这两个数据结构操作方法足够进行数据分析。
二、Pyspark实例创建
1.引入库
import pandas as pd
import numpy as np
import pyspark.pandas as ps
from pyspark.sql import SparkSession
如果运行上述代码有 WARNING:root:‘PYARROW_IGNORE_TIMEZONE‘ environment variable was not set.可以加上:
import os
os.environ["PYARROW_IGNORE_TIMEZONE"] = "1"
2.转换实现
通过传递值列表,在Spark上创建pandas,让pandas API在Spark上创建默认整数索引:
pyspark pandas series创建
和pandas是一样的
s = ps.Series([1, 3, 5, np.nan, 6, 8])
pyspark pandas dataframe创建
和pandas也是一样的:
ps_df=ps.DataFrame(
{'name':['id1','id2','id3','id4'],
'old':[21,23,22,35],
'city':['杭州','北京','南昌','上海']
},
index=[1,2,3,4])
from_pandas转换
我们先用pandas创建一个普通的DataFrame:
pd_df=pd.DataFrame(
{'name':['id1','id2','id3','id4'],
'old':[21,23,22,35],
'city':['杭州','北京','南昌','上海']
},
index=[1,2,3,4])之后直接使用from_pandas开始转换就可以了:
ps_df=ps.from_pandas(pd_df)
type(ps_df) ![]()
Spark DataFrame转换
也可以通过Pandas的DataFrame转换为Spark DataFrame:
spark = SparkSession.builder.getOrCreate()
sp_df=spark.createDataFrame(pd_df)
sp_df.show() 
通过Spark DataFrame转换为PySpark DataFrame:
ps_df=sp_df.pandas_api() 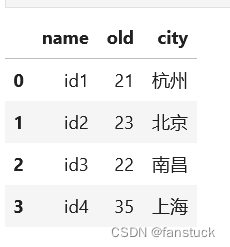
且和pandas一样查看数据类型方法是一样的:
ps_df.dtypes 
Spark DataFrame中的数据在默认情况下并不保持自然顺序。
通过设置compute.ordered_head可以保持自然顺序,但它会导致内部排序的性能开销。
ps_df.head() 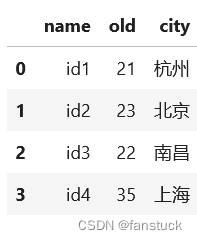
三、PySpark Pandas操作
1.读取行列索引
读取行索引:
ps_df.indexInt64Index([0, 1, 2, 3], dtype='int64')读取列索引:
ps_df.columnsIndex(['name', 'old', 'city'], dtype='object')2.内容转换为数组
ps_df.to_numpy() 
3.DataFrame统计描述
ps_df.describe()描述的数值均为float
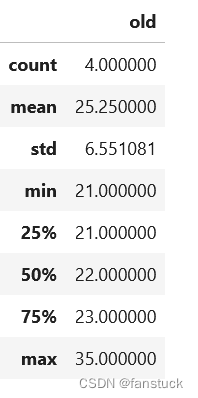
4.转置
ps_df.T转置内容old列为int64,转置会报错,需要先转换为str再进行转置:
ps_df['old']=ps_df['old'].astype(str)
ps_df.T 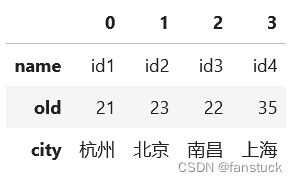
5.排序
按行索引排序
ps_df.sort_index(ascending=False)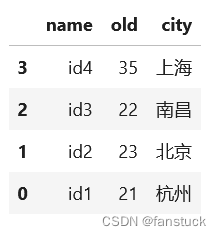
按某列值排序
ps_df.sort_values(by='old')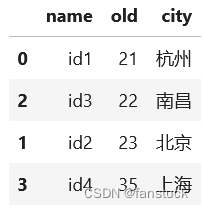
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
文章出处登录后可见!