原创 | 文 BFT机器人

在不断努力让人工智能更像人类的过程中,OpenAI的GPT模型不断突破界限GPT-4现在能够接受文本和图像的提示。
生成式人工智能中的多模态表示模型根据输入生成文本、图像或音频等各种输出的能力。这些模型经过特定数据的训练,学习底层模式以生成类似的新数据,丰富人工智能应用。
PART 01
多模式人工智能的最新进展
最近,该领域取得了显着的飞跃,将DALL-E 3集成到ChatGPT中,这是OpenAI文本到图像技术的重大升级。这种混合可以实现更流畅的交互,ChatGPT有助于为DALL-E3制作精确的提示,将用户的想法转化为生动的AI生成的艺术。因此,虽然用户可以直接与DALL-E3交互,但将ChatGPT加入其中使得创建AI艺术的过程更加用户友好。
在此处查看有关DALL-E3及其与ChatGPT集成的更多信息。此次合作不仅展示了多模态人工智能的进步,也让用户的人工智能艺术创作变得轻而易举。

另一方面,谷歌健康于今年6月推出了Med-PaLMM。它是一种多模式生成模型,擅长编码和解释不同的生物医学数据。这是通过利用开源基准MultiMedBench微调语言模型PaLM-E来满足医学领域的需求而实现的。该基准包含7种生物医学数据类型的超过100万个样本以及医学问答和放射学报告生成等14项任务。
各行业正在采用创新的多模式人工智能工具来推动业务扩展、简化运营并提高客户参与度。语音、视频和文本人工智能功能的进步正在推动多模式人工智能的增长。
企业寻求能够彻底改变业务模型和流程的多模式人工智能应用程序,从数据工具到新兴人工智能应用程序,在生成式人工智能生态系统中开辟增长途径。
GPT-4 在3月份推出后,一些用户发现其响应质量随着时间的推移而下降,著名开发人员和OpenAI论坛也表达了这一担忧。最初被OpenAI驳回,后来的一项研究证实了这个问题。报告显示,3月至6月期间,GPT-4的准确率从97.6%下降至 2.4%,这表明随着后续模型更新,答案质量有所下降。
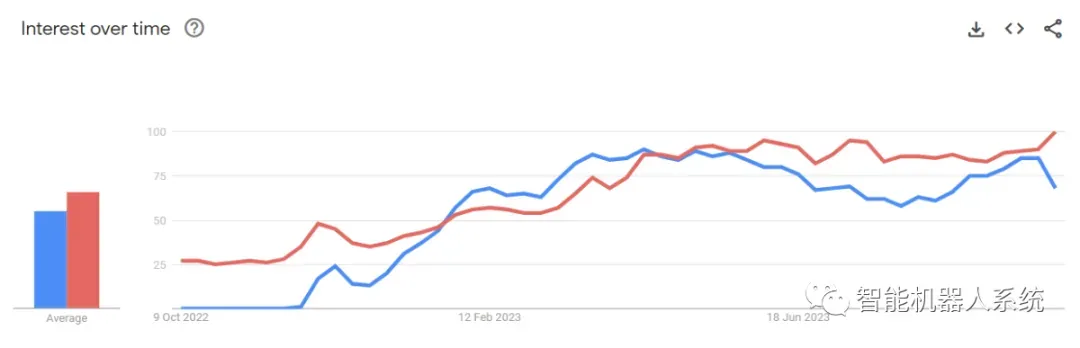
ChatGPT(蓝色)和人工智能(红色)Google搜索趋势
围绕OpenAI的ChatGPT的炒作现在又回来了。它现在配备了视觉功能GPT-4V,允许用户让GPT-4分析他们给出的图像。这是向用户开放的最新功能。
一些人认为,将图像分析添加到GPT-4等大型语言模型 (LLM) 中是人工智能研究和开发的一大进步。这种多模式法学硕士开辟了新的可能性,将语言模型超越文本,提供新的界面并解决新类型的任务,为用户创造新鲜的体验。
GPT-4V的训练于2022年完成,抢先体验于2023年3月推出。GPT-4V的视觉功能由GPT-4技术提供支持。培训过程保持不变。最初,该模型被训练为使用来自包括互联网在内的各种来源的文本和图像的大量数据集来预测文本中的下一个单词。
后来,它使用更多数据进行了微调,采用了一种名为“人类反馈强化学习”(RLHF)的方法,以生成人类喜欢的输出。
PART 02
GPT-4 视觉力学
GPT-4卓越的视觉语言能力虽然令人印象深刻,但其底层方法仍然停留在表面。
为了探索这一假设,引入了一种新的视觉语言模型MiniGPT-4 ,利用名为Vicuna的高级法学硕士。该模型使用带有预先训练的视觉感知组件的视觉编码器,通过单个投影层将编码的视觉特征与Vicuna语言模型对齐。MiniGPT-4的架构简单而有效,重点是协调视觉和语言特征以提高视觉对话能力。
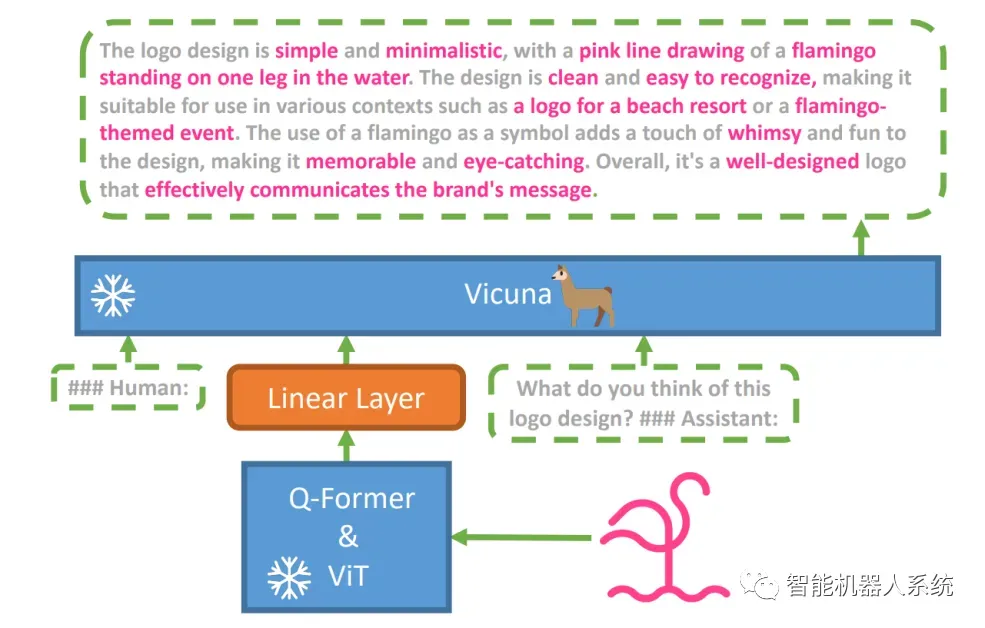
MiniGPT-4的架构包括一个带有预训练ViT和Q-Former的视觉编码器、一个线性投影层和一个高级Vicuna大语言模型。
视觉语言任务中自回归语言模型的趋势也在增长,利用跨模态迁移在语言和多模态领域之间共享知识。
MiniGPT-4通过将预先训练的视觉编码器的视觉信息与高级LLM对齐,在视觉和语言领域之间架起桥梁。该模型利用Vicuna作为语言解码器,并遵循两阶段训练方法。最初,它在大型图像文本对数据集上进行训练,以掌握视觉语言知识,然后对较小的高质量数据集进行微调,以增强生成的可靠性和可用性。
为了提高MiniGPT-4中生成语言的自然性和可用性,研究人员开发了一个两阶段对齐过程,解决了缺乏足够的视觉语言对齐数据集的问题。他们为此目的策划了一个专门的数据集。
最初,该模型生成输入图像的详细描述,通过使用与 Vicuna 语言模型格式一致的对话提示来增强细节。此阶段旨在生成更全面的图像描述。
初始图像描述提示:
###Human: <Img><ImageFeature></Img>详细描述此图像。提供尽可能多的细节。说出你所看到的一切。###助手:
对于数据后处理,使用 ChatGPT 纠正生成的描述中的任何不一致或错误,然后进行手动验证以确保高质量。
第二阶段微调提示:
###人类:<Img><ImageFeature></Img><指令>###助理:
这一探索打开了一扇了解GPT-4等多模态生成人工智能机制的窗口,揭示了如何有效地整合视觉和语言模态以生成连贯且上下文丰富的输出。
PART 03
探索 GPT-4 愿景使用 ChatGPT 确定图像来源
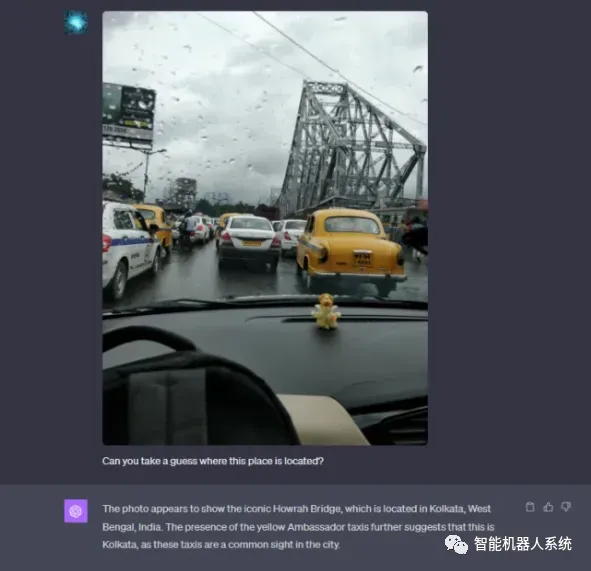
GPT-4Vision增强了ChatGPT分析图像并查明其地理来源的能力。此功能将用户交互从单纯的文本转换为文本和视觉效果的混合,成为那些通过图像数据对不同地点感到好奇的人的便捷工具。
复杂的数学概念
GPT-4Vision擅长通过分析图形或手写表达式来深入研究复杂的数学思想。对于寻求解决复杂数学问题的个人来说,此功能是一个有用的工具,使GPT-4Vision成为教育和学术领域的显着帮助。

将手写输入转换为 LaTeX 代码
GPT-4V的卓越功能之一是能够将手写输入转换为LaTeX代码。对于经常需要将手写数学表达式或其他技术信息转换为数字格式的研究人员、学者和学生来说,此功能是一个福音。从手写到LaTeX的转变扩大了文档数字化的范围并简化了技术写作过程。

GPT-4V能够将手写输入转换为LaTeX代码
提取表详细信息
GPT-4V展示了从表格中提取详细信息和解决相关查询的技能,这是数据分析中的重要资产。用户可以利用GPT-4V筛选表格、收集关键见解并解决数据驱动的问题,使其成为数据分析师和其他专业人士的强大工具。
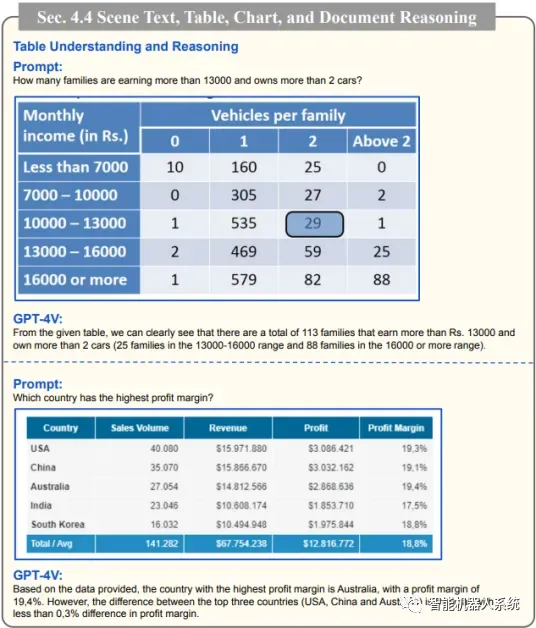
GPT-4V破译表详细信息并响应相关查询
理解视觉指向
GPT-4V理解视觉指向的独特能力为用户交互增添了新的维度。通过理解视觉线索,GPT-4V可以以更高的上下文理解来响应查询。
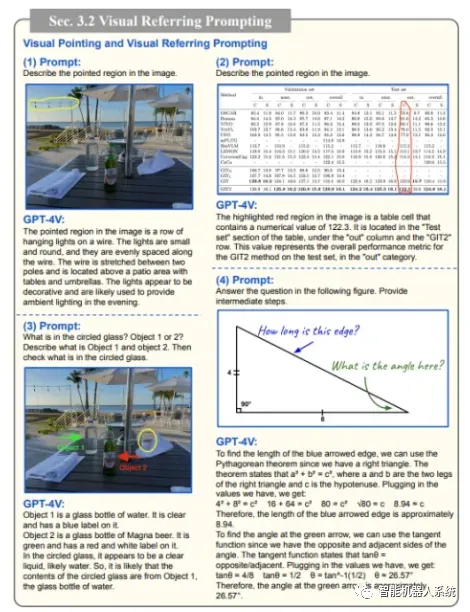
GPT-4V展示了理解视觉指向的独特能力
使用绘图构建简单的模型网站
受此推文的启发,我尝试为unity.ai网站创建一个模型。
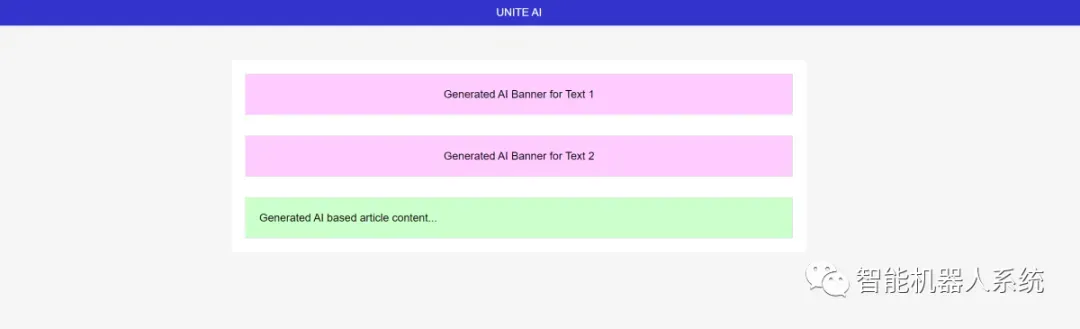
基于ChatGPTVision的输出HTML前端
GPT-4V(ision) 的局限性和缺陷
为了分析GPT-4V,OpenAI团队进行了定性和定量评估。定性测试包括内部测试和外部专家评审,而定量测试则测量各种场景下的模型拒绝率和准确性,例如识别有害内容、人口统计识别、隐私问题、地理位置、网络安全和多模式越狱。
该模型仍然不完美。
该论文强调了GPT-4V的局限性,例如错误的推理以及图像中缺少文本或字符。它可能会产生幻觉或编造事实。特别是,它不适合识别图像中的危险物质,经常会错误识别它们。
在医学成像中,GPT-4V可能会提供不一致的响应,并且缺乏对标准实践的认识,从而导致潜在的误诊。
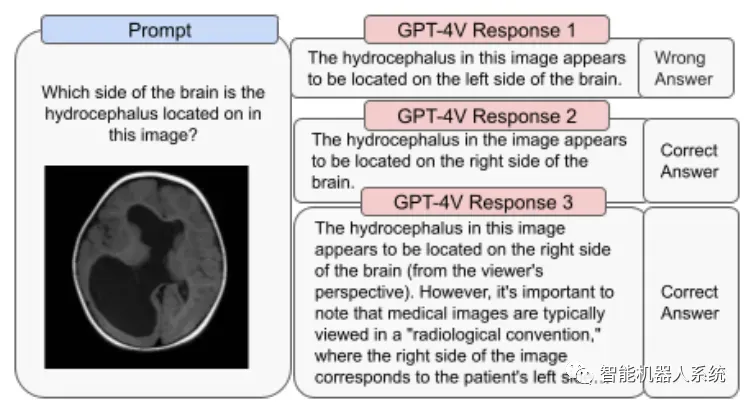
用于医疗目的的不可靠性能(来源)
它还无法掌握某些仇恨符号的细微差别,并可能根据视觉输入生成不适当的内容。OpenAI建议不要使用GPT-4V进行批判性解释,尤其是在医疗或敏感环境中。
包起来
使用FastStableDiffusionXL创
https://huggingface.co/spaces/google/sdxl
GPT-4Vision (GPT-4V) 的到来带来了一系列很酷的可能性和需要跨越的新障碍。在推出之前,我们已经付出了大量努力来确保风险得到充分研究并减少,尤其是涉及人物照片时。看到GPT-4V的进步令人印象深刻,在医学和科学等棘手领域展现出巨大的前景。
现在,有一些重大问题摆在桌面上。例如,这些模型是否应该能够从照片中识别出名人?他们应该从照片中猜测一个人的性别、种族或感受吗?而且,是否应该进行特殊调整来帮助视障人士?这些问题引发了一系列关于隐私、公平以及人工智能应该如何融入我们的生活的争论,这是每个人都应该有发言权的问题。
文章翻译 | 春花
排版 | 春花
审核 | 橙橙
若您对该文章内容有任何疑问,请与我们联系,将及时回应。
文章出处登录后可见!