导读:Transformer源自于AI自然语言处理任务;在计算机视觉领域,近年来Transformer逐渐替代CNN成为一个热门的研究方向。此外,Transformer在文本、语音、视频等多模态领域也在崭露头角。本文对Transformer从诞生到逐渐壮大为AI各领域主流模型的发展过程以及目前研究进展进行梳理,见证Transformer的过人之处。
一、Transformer的诞生
1、Transformers的前身:RNN Encoder-Decoder
早在2014年,seq2seq问题是通过两个循环神经网络组合成一个编码器-解码器模型来解决的。通过机器翻译任务中的一个简单示例来演示它的架构,以法语-英语句子对为例,输入是“je suis étudiant”,输出是“I am a student”。首先,“je”通常伴随着一个可以学习或固定的常量向量hE0,被送入RNN编码器。之后输出向量hE1(隐藏状态1),与输入序列中的第二个元素“suis”一起作为RNN编码器的下一个输入,此操作的输出hE2和“étudiant”再次输入编码器,为该训练样本生成最后一个编码隐藏状态hE3。hE3向量依赖于输入序列中的所有标记,因此它应该代表整个短语的含义。出于这个原因,它也被称为上下文向量。上下文向量是RNN解码器的第一个输入,它应该生成输出序列的第一个元素“I”(实际上,解码器的最后一层通常是softmax,但为了简单起见,只保留每个解码器步骤的结果)。此外,RNN解码器会产生隐藏状态hD1。将hD1和之前的输出“I”送回解码器,希望将“am”作为第二个输出。这个生成输出并将其反馈回解码器的过程一直持续到我们生成EOS(句子标记的结尾),表示我们的工作已经完成。
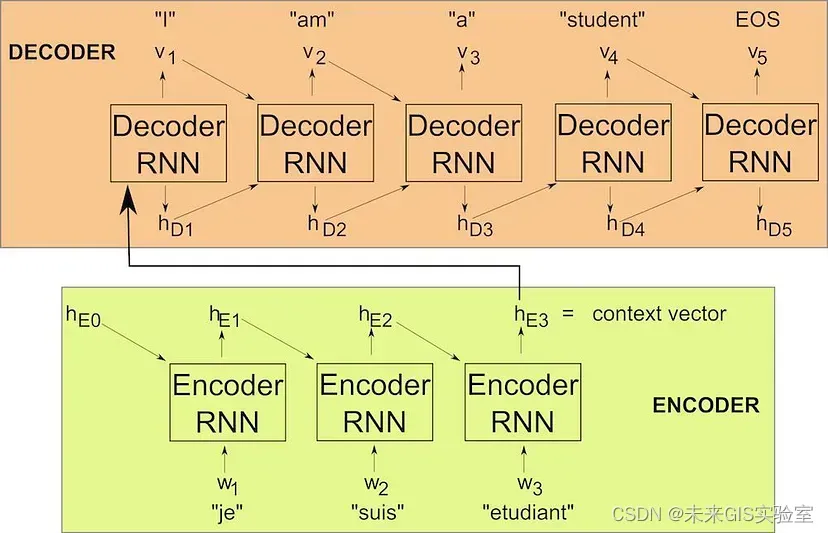
图1 RNN Encoder-Decoder示意图
这种RNN编码器-解码器的结构可能看起来很简单,但事实证明它对许多NLP任务非常有效。事实上,谷歌翻译自2016年以来一直在使用它。然而,RNN编码器-解码器模型确实存在很多缺点。
2、RNN存在的问题1:长序列的向量表示
如上所述的RNN方法对于较长的句子效果不是特别好。试想一下,整个输入序列的含义由一个固定维度的上下文向量来表示,这对于“Je suis étudiant”这种短句来说已经足够好了,但是如果输入是一些非常长的句子,包含几十个甚至几百个单词,那将其编码为上下文向量是很困难的。能有效的解决这个问题的方案就是Attention——注意力机制。
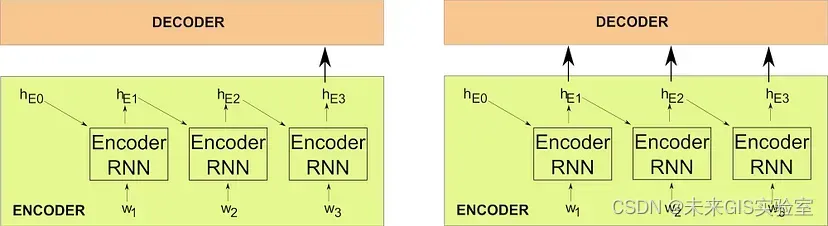
图2 传统RNN编码器-解码器(左)和带注意力的RNN编码器-解码器(右)示意图
Attention背后的基本思想很简单:我们不是只将最后一个隐藏状态(上下文向量)传递给解码器,而是将来自编码器的所有隐藏状态都传递给解码器。在之前示例中,Attention会将hE1、hE2和hE3都传给解码器。解码器将通过softmax层确定它们中的哪些被关注。除了添加这个额外的结构之外,基本的RNN编码器-解码器架构保持不变,但是当涉及到更长的输入序列时,加入Attention的模型表现得更好。
3、RNN存在的问题2:并行能力
困扰RNN的另一个问题与名称中的R有关。根据定义,循环神经网络中的计算是顺序的。模型必须等待上一步完成才能继续下一步,这意味着RNN只能顺序计算而无法并行化,所以模型训练时间和运行推理时间都显著增加。
用CNN来替代RNN用于文本处理是解决RNN无法并行化问题的一个不错的方案,主要优势在于减少文本时序的计算。然而CNN的每个卷积核只能看到其中一段文本的内容,对于长文本任务,需要堆叠很多层才能看到文本全局的内容,这样一来模型需要做得更大。
4、Transformers诞生:Attention is All You Need
Transformer最初出现在谷歌团队2017年的论文《Attention Is All You Need》中,从字面上理解Transformer采用了带有注意力的编码器-解码器模型。它的出现解决了RNN和CNN在处理序列时的各种问题。那么它是如何运作的?首先,输入序列wi经过预处理的元素都作为输入提供给编码器。与RNN不同的是,它是并行完成的。编码器有多个层(例如,在原始的Transformer论文中,它们的数量是六层)。之后使用hi来标记每个wi的最后一个编码器层的最终隐藏状态。解码器通常也包含多个层,层数与编码器的层数相同。所有隐藏状态hi将作为输入送到解码器的六层中的每一层,这就是Transformer的Encoder-Decoder Attention,它在本质上与我们上面讨论的Attention机制非常相似。(如图3,具有两层的编码器,并行处理三元素输入序列(w1、w2和w3)。每个输入元素的编码器还通过其自注意力子层接收有关其他元素的信息,从而捕获句子中单词之间的关系)
预处理层存在于编码器和解码器中,预处理分为两部分:首先,是熟悉的词嵌入,这是大多数NLP模型的主要内容。这些词嵌入可以在训练期间学习,或者可以使用现有的预训练模型嵌入。第二,在没有顺序RNN架构的情况下如何确定每个输入序列的位置?预处理层的第二个作用就是将位置信息编码到向量中,就像我们用词嵌入嵌入词标记的含义一样。生成的后处理向量携带有关单词的含义及其在句子中位置的信息,被传递到编码器和解码器层。
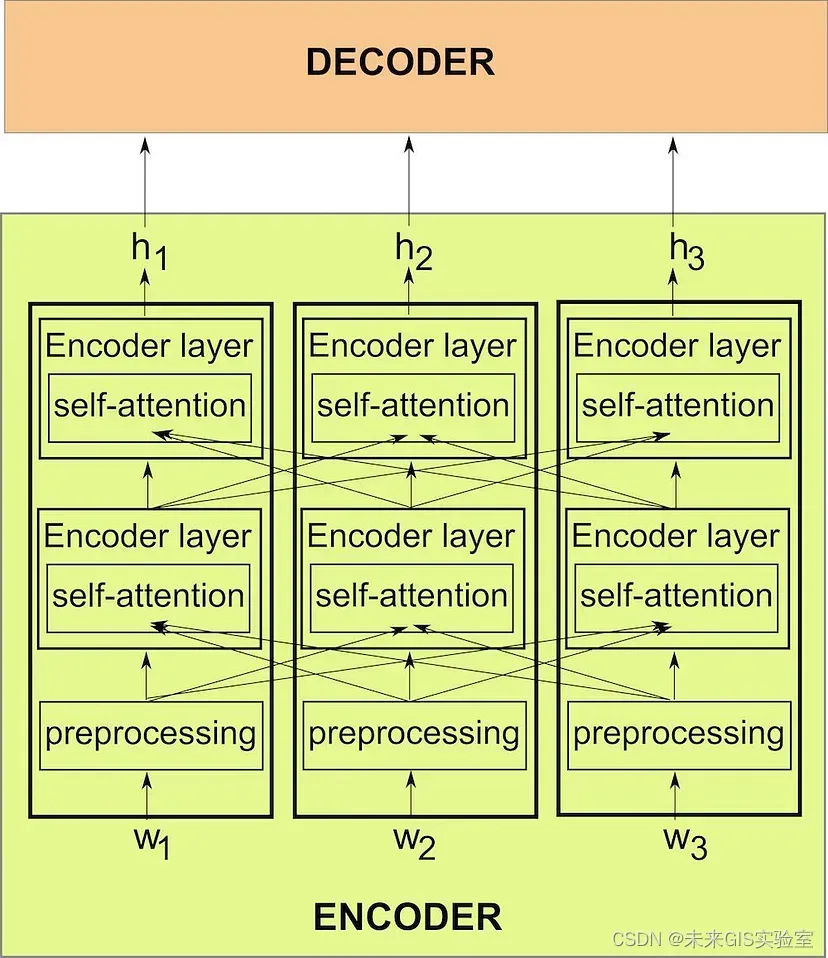
图3 具有两层编码器的Transformer-Encoder结构示意图
引入self-attention的目的是为了学习句子中不同词之间的关系,通俗讲,就是它允许序列中的每个元素相互交互,并找出他们应该更关注谁。Self-Attention层包括Encoder Self-Attention和Decoder Self-Attention。如何计算注意力呢?由线性代数相关的知识我们可以知道,对于相同维度的两个向量,可以通过点积的方法来获得其相关性。其中,用X标记注意力层输入的向量空间。有三个来自于编码器或解码器的向量QKV。Q是一个查询向量,即我们指定我们想要关注的信息类型;V是类似于向量X的线性组合(与X维度不一样);K索引由值Vⁿ捕获的信息类型。我们在训练期间想要学习的是三个嵌入矩阵,Wᴷ,WV和Wᴬ。
K=XWᴷ
V=XWⱽ
Q=XWᴬ
为了确定哪些值应该得到最多的关注,采用解码器的查询Q与编码器的所有键K的点积。结果的softmax会给出各个值V的权重(权重越大,attention越大)。这种机制称为点积注意力,由以下公式计算:
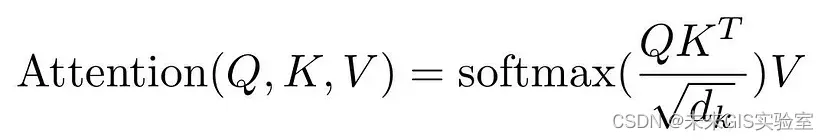
编码器自注意力的计算在每个编码器层内进行,较低编码器层的值V将最接近原始输入标记,而较深层的自注意力将涉及更多抽象结构。
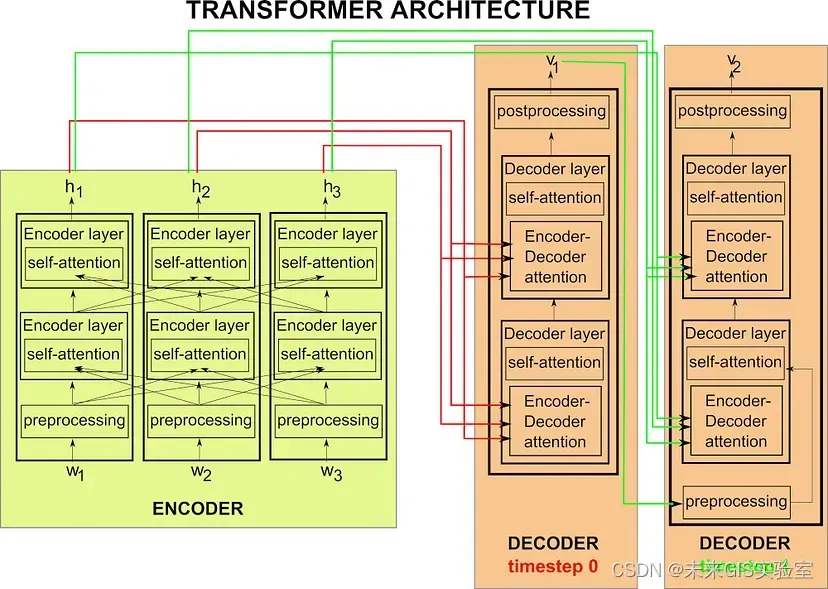
图4 Transformer结构示意图
二、Transformer强在何处
1、在NLP领域
在上一节中,介绍了RNN在处理长文本序列中的两个问题:顺序结构导致无法捕捉长序列上下文信息、并行处理序列困难。Transformer的出现为RNN的Encoder-Decoder结构加入了注意力机制,抛弃RNN顺序结构,实现长序列的并行处理,完美的解决了这两个问题。在AI领域。我们都想要一个通用模型来准确、快速地解决不同的任务,而Transformer模型就是目前序列到序列任务的通用模型。
2、在CV领域
近几年,Transformer也替代CNN成为计算机视觉领域中一个热门的研究方向,那么来自NLP领域的Transformer是如何实现在视觉领域超越CNN结构呢?我们知道Transformer总是对序列进行操作,因此将图像拆分为很多个“小块”并将每个“小块”展平为向量就能得到图像的序列表示,那么用Transformer来处理图像也成为可能。
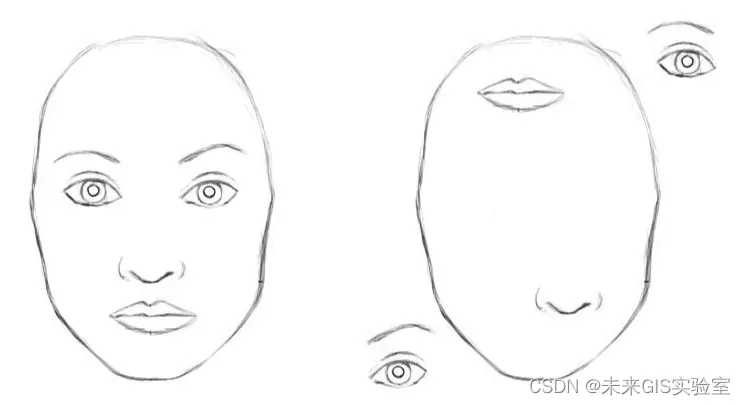
图5 示例图
CNN非常擅长特征提取,但是对于CNN,上面这两张图片几乎是一样的。CNN不会编码不同特征的相对位置。要想编码这些特征的组合就需要大型滤波器。例如:编码“眼睛高于鼻子和嘴巴”的信息就需要更大的滤波器。
为了捕捉图像中的远距离依赖,CNN需要大的感受野,也就需要更大的卷积核。增加卷积核的大小可以增加网络的表示能力,但这样做也会损失使用局部卷积结构获得的特征和统计效率。
Transformer相较于CNN最大的优势就是注意力机制,注意力机制在某些方面与CNN相似。注意力机制在每个位置都会进行一次计算,把这个位置的信息和其他位置的信息结合起来,同时还能忽略周围大多数不相关的信息。但与CNN不同的是,“其他信息”不需要在附近。(注意力机制不是“局部的”。)而且注意力机制的当前位置不是预定义的,也不是固定的(不像CNN具有固定的“windows”,尺寸规定为3×3或其他)。它们是基于所有输入进行动态计算。以为图片添加标题为例,只有专注于图像的相关部分才能生成有意义的标题,这就是注意力机制所做的事情。它允许捕获序列元素之间的“长期”信息和依赖关系,有助于对跨图像区域的长距离、多级依赖性进行建模。在图6中可以看到一个自注意力模块取代了卷积层,模型能够与远离其位置的像素进行交互。因此Transformer的自注意力机制有效解决CNN卷积结构的一些局限性。
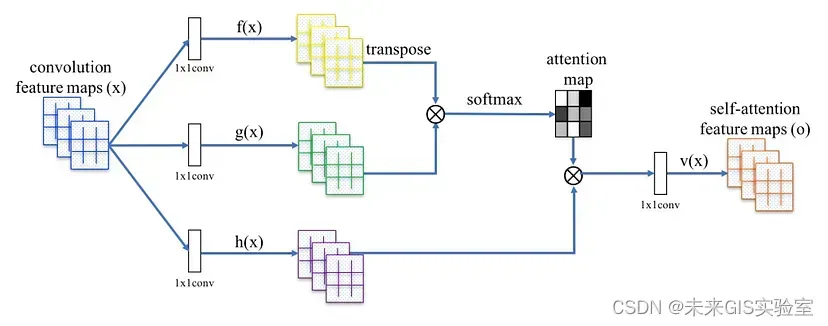
图6 用于SAGAN的自注意力模块(图源:《Self-Attention Generative Adversarial Networks》)
三、Transformer在NLP领域的发展
1、Transformer诞生之前的NLP领域
NLP是将机器理解到的信息,转化并表达成语言传递给人的过程。这个过程面临着生成语句的语法结构、语义表达是否准确,信息是否重复等挑战。
2017年,Salesforce的BryanMcCann等人发表了一篇文章Learned in Translation:Contextualized Word Vectors,提出了seq2seq NMT模型CoVe。论文首先用一个Encoder-Decoder框架在机器翻译的训练语料上进行预训练(如下图a),而后用训练好的模型,只取其中的Embedding层和Encoder层,同时在一个新的任务上设计一个task-specific模型,再将原先预训练好的Embedding层和Encoder层的输出作为这个task-specific模型的输入,最终在新的任务场景下进行训练(如下图b)。
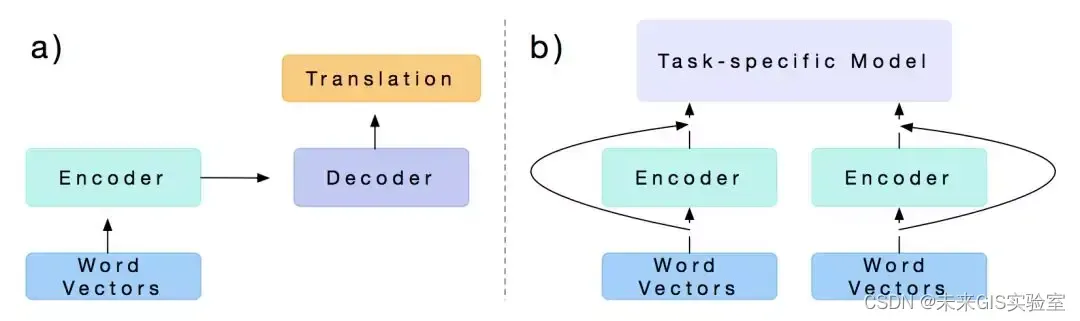
图7 CoVe训练方式(图源:《Learned in Translation: Contextualized Word Vectors》)
但是CoVe的局限性也很明显:预训练受限于有监督翻译任务能得到哪些数据集;同时CoVe对最终效果的贡献受制于任务模型。
2018年的早些时候,AllenNLP的MatthewE.Peters等人在论文Deep contextualized word representations中首次提出了ELMo,它的全称是Embeddings from Language Models。严格意义上来说之前的CoVe并不是一个语言模型,CoVe利用的是Encoder+Decoder的机器翻译模型进行预训练。Elmo和他的区别是他仅仅利用的是seq2seq的Encoder,并且是一个自监督训练,是一个严格意义上的语言模型。在EMLo中,他们使用的是一个双向的LSTM语言模型,由一个前向和一个后向语言模型构成,这里的模型目标是预测对应位置的下一个单词(也就是T1的向量应该预测出E2的单词)。ELMo语言模型的预训练是无监督式的,而且鉴于无标注文本语料之丰富,理论上预训练规模可以尽可能的大些。但它还是得依赖特定任务模型,所以改善只是渐进式的,给每个任务找个好模型架构仍然很重要。
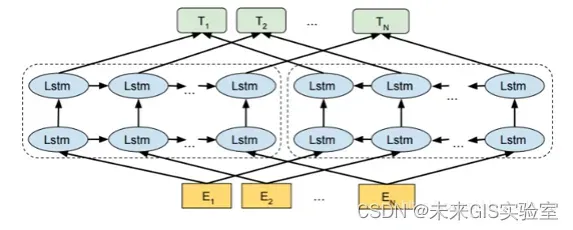
图8 ELMo结构(图源:《Deep contextualized word representations》)
在ELMo之后,FastAI提出ULMFit,ULMFit同样使用了语言模型,并且预训练的模型主要也是LSTM,基本思路也是预训练完成后在具体任务上进行finetune,但不同之处也有很多。首先,ULMFit的预训练和finetune过程主要分为三个阶段,分别是在大规模语料集上(比如Wikitext103,有103million个词)先预训练,然后再将预训练好的模型在具体任务的数据上利用语言模型来finetune(第一次finetune,叫做LMfinetune),再根据具体任务设计的模型上,将预训练好的模型作为这个任务模型的多层,再一次finetune(第二次finetune,如果是分类问题的话可以叫做Classifier finetune),整个过程如下所示:
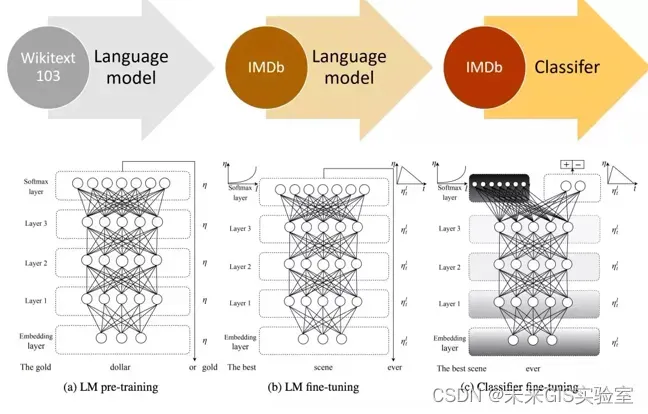
图9 ULMFit训练过程(图源:《Universal Language Model Fine-tuning for Text Classification》)
2、Transformer诞生之后的NLP领域
2017年谷歌Transformer的提出完美的解决了RNN与CNN在处理长序列文本时的缺陷。Transformer是第一个完全使用self-attention的encoder-decoder模型,可以满足并行计算的需求,替代了RNN的时序结构。另外参考CNN采取多个卷积核输出得到多种特征的优点,Transformer也提出了multi-head attention的结构,从而获得多个不同的文本特征(见图10)。
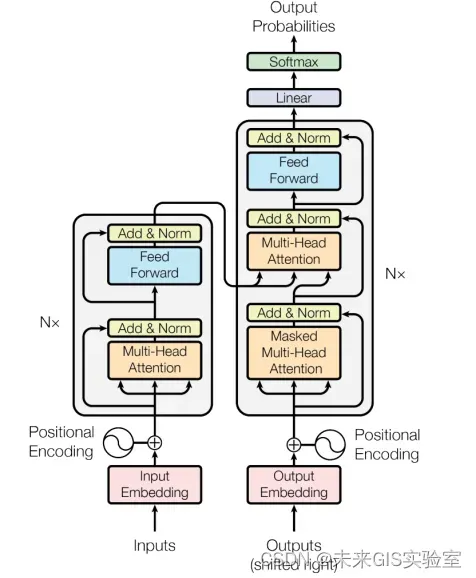
图10 Transformer模型结构(图源:《Attention Is All You Need》)
Transformer提出之后的2018年,OpenAI提出首个GPT系列模型GPT,作为第一个基于Transformer的预训练模型,采取了预训练+FineTuning两个阶段,以Transformer的decoder作为特征抽取器,共堆叠12层,拥有1.1亿参数,预训练阶段则采用单向语言模型作为训练任务。与ELMo当成特征的做法不同,OpenAI GPT不需要再重新对任务构建新的模型结构,而是直接在transformer这个语言模型上的最后一层接上softmax作为任务输出层,然后再对这整个模型进行微调。
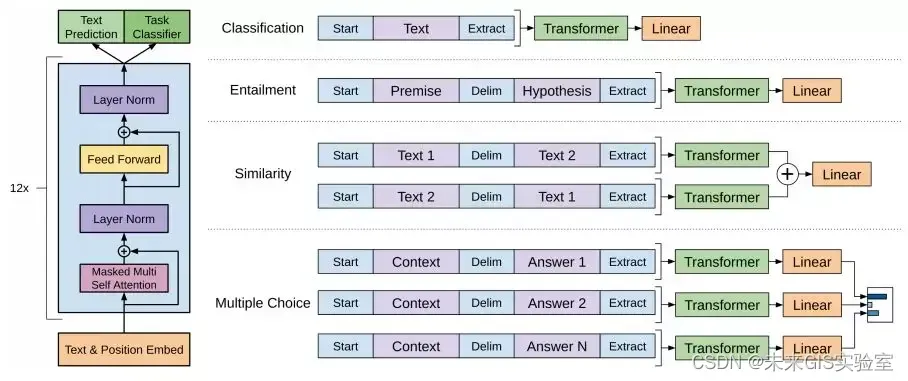
图11 GPT模型结构(图源:《Improving Language Understanding by Generative Pre-Training》)
在GPT诞生不久,同年10月,BERT模型横空出世,并横扫NLP领域11项任务的最佳成绩!而在BERT中发挥重要作用的结构就是Transformer,它采用了Transformer的Encoder结构,在自然语言理解任务(NLU)上表现优异。之后又相继出现XLNET,roBERT等模型击败了BERT,但是他们的核心没有变,仍然是Transformer,至此Transformer逐渐巩固了NLP主流模型的地位。
BERT提出之后的第二年又出现了稳健优化版BERT:RoBERTa、精简版BERT:ALBERT。RoBERTa作者发现原BERT模型明显训练不足。因此用更大的batchsize进行更多步的训练;删掉下一句预测任务;训练数据格式上用更长的序列。动态调整mask模式。原BERT就在预训练时用了一次mask,导致训练时都是一个静态mask。RoBERTa在40轮训练中用了10种不同的mask方式。ALBERT是BERT的简化版,相似的配置下参数减少18倍,训练速度提升1.7倍。ALBERT所作的改进有三点:排前两位的当然是减少了参数,降低了内存开销从而提升了训练速度,而第三点则是用一个更有挑战性的训练任务替换掉了下一句预测(NSP)任务。
同年谷歌又推出了T5模型,T5采用“全能自然语言”框架,许多常见NLP任务被转换成针对上下文的问答形式。相较于显式的QA格式,T5用较短的任务前缀区分任务意图,并分别对每个任务做了模型微调。文本到文本架构用同样的模型解决不同的任务,极大简化了迁移学习的评估过程。模型在2019年4月搜集的网络语料上做训练,用上了各种过滤器。模型借助“适配器层”(多加一层做训练)或“逐步解封”分别对各下游任务做微调。两个微调方法都是只更新部分参数,同时大部分模型参数不变。T5-11B在许多NLP任务上取得了SOTA结果。
2020年OpenAI又提出GPT系列的第三代GPT-3。GPT-3和GPT-2架构相同但有175B个参数,比GPT-2(1.5B)大10多倍。为了把这么大的模型塞到GPU集群里,GPT-3采用了沿深度和宽度方向的分区训练方式。训练数据是CommonCrawl,还额外混合了少数高品质数据集。为了防止下游任务出现在训练数据里造成污染,作者试着从训练集里删掉了所有基准数据集间的重叠部分。不幸的是因为有bug过滤过程并不完美。
对于所有下游任务的评估,GPT-3只是在少样本环境下做了测试,没用任何基于梯度的微调,这里的少数样本算是给了部分提示。相比于微调过的BERT模型,GPT-3在很多NLP数据集上取得了亮眼表现。
表1 NLP模型总结
NLP模型 | 基础模型 | 预训练 | 下游任务 | 下游模型 | 微调 |
CoVe | seq2seq NMT模型 | 有监督 | 基于特征 | 看任务定 | / |
ELMo | 双层biLSTM | 无监督 | 基于特征 | 看任务定 | / |
ULMFiT | AWD-LSTM | 无监督 | 基于模型 | 与任务无关 | 所有层;各种训练技巧 |
GPT | Transformer解码器 | 无监督 | 基于模型 | 与任务无关 |
预训练层+顶部任务层 |
BERT | Transformer编码器 | 无监督 | 与任务无关 | 与任务无关 |
预训练层+顶部任务层 |
RoBERTa | Transformer编码器 | 无监督 | 与任务无关 | 与任务无关 | 预训练层+顶部任务层 |
T5 | Transformer | 无监督 | 与任务无关 | 与任务无关 | 分别对每个下游任务微调 |
GPT-3 | Transformer解码器 | 无监督 | 与任务无关 | 与任务无关 | 没有微调 |
3、Transformer在NLP领域的研究现状
最近,距离第一代GPT模型推出仅仅4年之后,基于GPT3.5的聊天机器人Chatgpt横空出世,它可以在数千亿规模的数据集上训练并持续生成语义可读的新文本,他强大的语言生成能力代表着Transformer在语言大模型上的无限可能。
在ChatGPT推出不久,谷歌发布了聊天机器人Bard,它使用的是谷歌在两年前发布的LaMDA模型。和停留在2021年的ChatGPT不同的是,Bard接受的信息来自于最新的互联网,因此Bard能够为当下所发生的事情提供解答,对比两者能够检索的信息量的话,Bard比ChatGPT大了一个量级。
国内基于Transformer的自然语言处理的中文大模型也在蓬勃发展。具有代表性的如:
2021年4月,阿里巴巴达摩院发布中文社区最大规模预训练语言模型PLUG,该模型参数规模达到270亿,集语言理解与生成能力与一身。
2021年4月,华为云发布千亿级生成与理解中文NLP大模型盘古,在中文语言理解评测基准 CLUE 榜单中,刷新三项榜单世界历史纪录;
2021年6月,由北京智源人工智能研究院发布了全球最大的超大规模智能模型“悟道2.0”,实现了“大而聪明”,具备大规模、高精度、高效率的特点。
2021年11月,阿里达摩院联合清华大学研发,中国首个万亿参数的超大规模多模态预训练Transformer模型M6。
2021年12月,百度推出拥有2600亿参数的百度文心大模型,使用编码器-解码器参数共享的Transformer作为自回归生成的主干网络。在国际权威的复杂语言理解任务评测SuperGLUE上超越谷歌的T5、OpenAI的GPT-3等大模型。
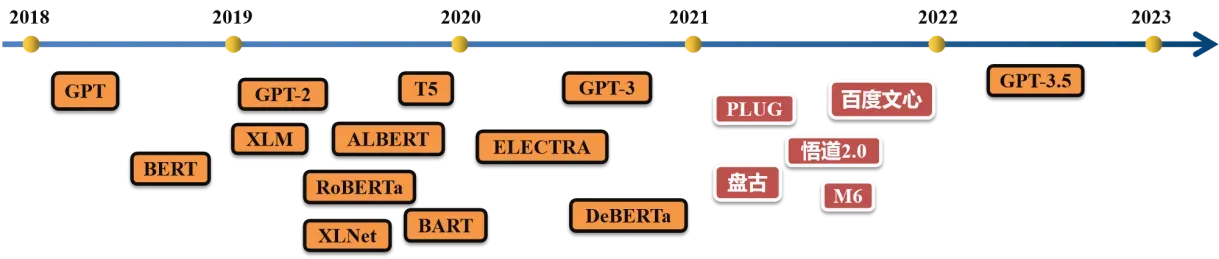
图12 基于Transformer的NLP模型发展梳理
四、Transformer在CV领域的发展
目前,Transformer已经成功应用于计算机视觉任务当中,除三大视觉任务之外,在识别任务、图像增强、图像生成、视频处理等任务上,Transformer模型都表现优秀。
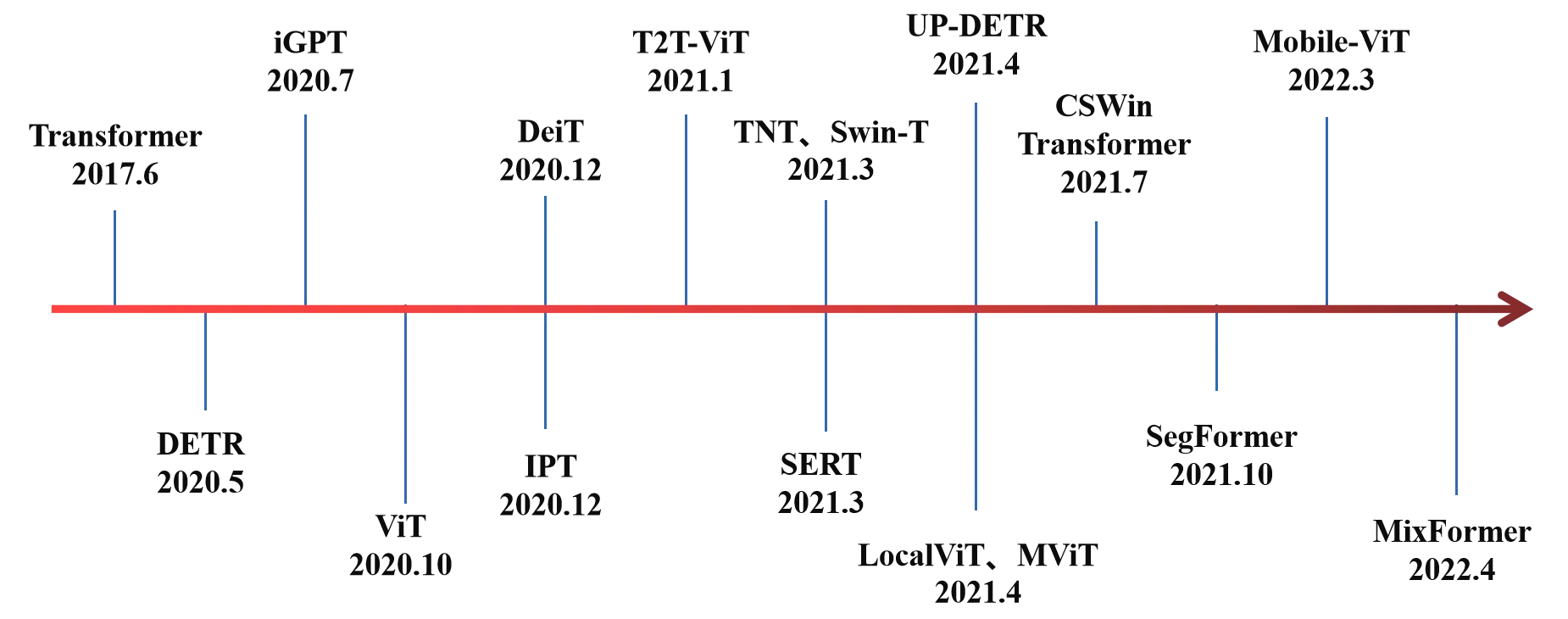
图13 视觉Transformer发展历程
1、Transformer诞生之前的CV领域
在CV领域中,很长一段时间的主导网络是卷积神经网络(CNN)。LeNet模型(1998年)是最早提出的卷积神经网络模型,包含3个卷积层、2个池化层和2个全连接层,每个卷积层和全连接层均有可训练的参数,为深度卷积神经网络的发展奠定了基础。
2012年提出的AlexNet网络包含5个卷积层和3个全连接层,该网络通过使用ReLU作为激活函数,引入局部响应归一化缓解梯度消失问题,使用数据增强和Dropout技术大大缓解了过拟合问题,也是从这之后进入了深度神经网络的时代。
2015年提出的GoogLeNet采用了Inception-v1模块,该模块采用稀疏连接降低模型参数量的同时,保证了计算资源的使用效率,在深度达到22层的情况下提升了网络的性能。
2016年的ResNet系列又是一个具有重大意义的工作,引入残差连接极大地提升了网络深度,最深做到了152层。ResNet的各种变体在之后很长一段时间内作为预训练模型参与下游视觉任务,在多个视觉比赛中取得了冠军,一度成为CNN的主流模型。
除之之外还有一些轻量级网络也在频繁使用,例如SqueezeNet、Xception、MobileNet系列和ShuffleNet系列等。
2、Transformer出现之后的CV领域
到2020年,CNN在CV领域中遇到了瓶颈,仅仅通过加深网络深度与调整卷积核并不能取得更好的效果。而Transformer在NLP领域的优异表现让计算机视觉领域的研究人员受到了启发,Transformer可以尝试通过处理文字的方式处理图片。
2.1 图像分类
2020年10月,用Transformer结构替代标准卷积的第一个CV领域模型出现,名为Vision Transformer(ViT)。该模型的架构与2017年提出的第一个Transformer的架构几乎相同,只有微小的变化,即将图像离散化,处理成类似NLP中输入token序列的形式,这让它能够做到分析图像,而不只是文字。ViT是一种完全基于自注意力机制的纯Transformer结构,网络结构中不包含CNN。该模型在推出之后就在ImageNet图像分类任务上取得了88.55%Top-1的准确率,超越了ResNet系列模型,打破了CNN在视觉任务上的垄断,相较于CNN具有更强泛化能力。
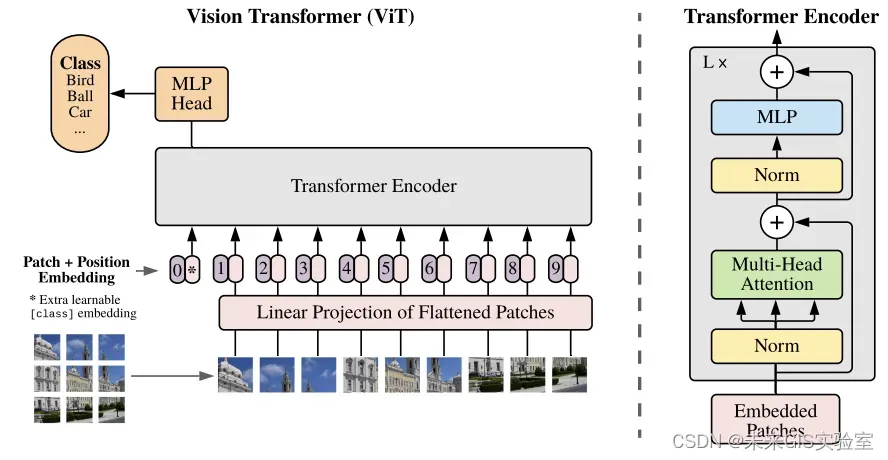
图14 VIT结构(图源:《VIT: An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale》)
虽然在图像分类上,ViT取得了突破性的进展,但同时也存在一些缺陷使得ViT能解决的图像问题有限:(1)ViT输入的token是固定长度的,然而图像尺度变化非常大;(2)ViT的计算复杂度非常高。
针对这些问题,2021年Swin Transformer出现了。通过应用与CNN相似的分层结构来处理图像(见图7),使Transformer模型能够灵活处理不同尺度的图片。同时采用了窗口注意力机制,只对窗口内的像素区域执行注意力计算,将ViTtoken数量平方关系的计算复杂度降低至线性关系。
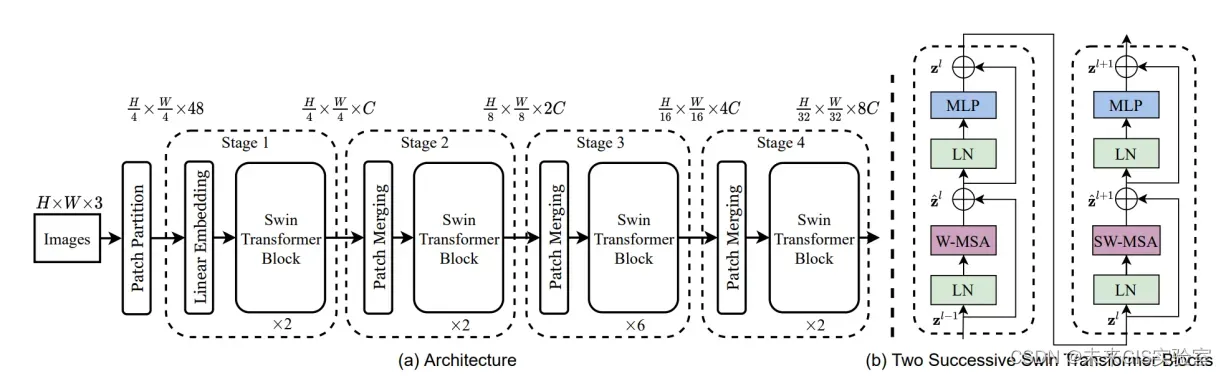
图15 SwinTransformer结构(图源:《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》)
Swin Transformer强大的建模能力使它可以作为通用的视觉骨干网络来完成众多视觉任务,如图片分类、目标检测、图像分割、图像复原、行人Re-ID、视频动作识别、视觉自监督学习等,并且一经推出就在这些任务中取得了优异的成绩,一度超越了以CNN为骨干网络的模型(见图16)。
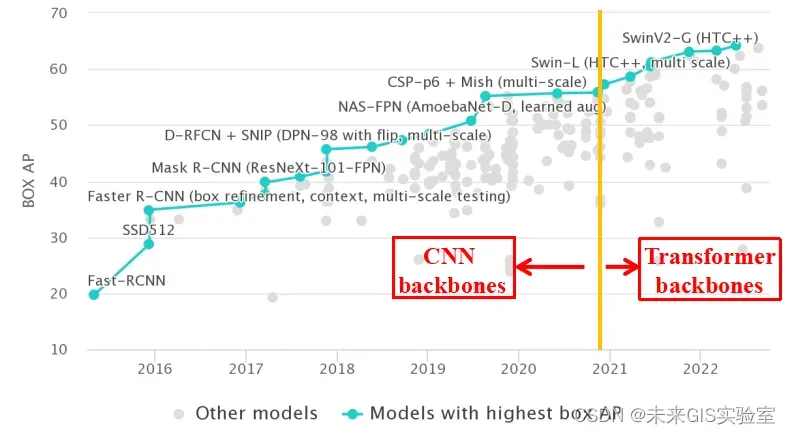
图16 SwinTransformer在视觉任务中表现优异(图源:https://paperswithcode.com/)
2.2目标检测
2020年5月提出的DERT模型,首次引入Transformer完成目标检测任务。采用CNN+Transformer Encoder+Transformer Decoder的模型架构。DETR将目标检测任务视为一个直观的集合预测问题,简化了目标检测的整体流程,摆脱了传统的手工制作组件,例如锚点生成和非最大抑制(NMS)后处理。
DERT根据目标和全局上下文之间的关系,直接并行输出最终的预测集,实现了端到端的自动训练和学习。在COCO数据集上,DETR的平均精确度AP为42%,在速度和精度上优于Faster-RCNN。
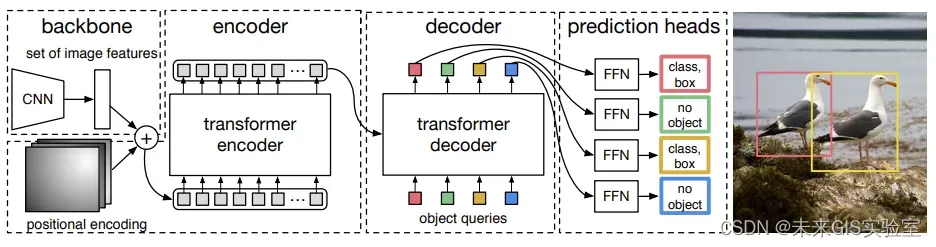
图17 DETR结构(图源:《End-to-End Object Detection with Transformers》)
2.3图像分割
在视觉Transformer介入语义分割之前,基于深度学习的语义分割是被以UNet为代表的CNN模型主导的。基于编解码结构的FCN/UNet模型成为语义分割领域最主流的模型范式。2021年3月份,是由复旦和腾讯优图联合提出的一个基于ViT的新型架构的语义分割模型SETR。
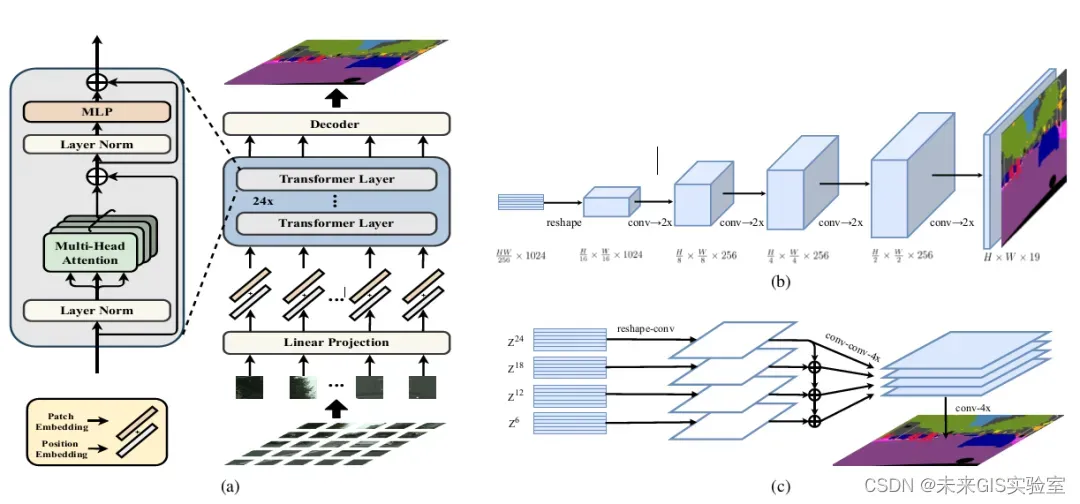
图18 SETR结构(图源:《Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers》)
SETR的核心架构仍然是Encoder-Decoder的结构,只不过相比于传统的以CNN为主导的编码器结构,SETR用Transformer来进行替代。图18中(a)图是SETR的整体架构,可以看到编码器是由纯Transformer层构成。
2.4 Transformer与CNN在CV领域的模型对比
目前,视觉Transformer算法的研究和改进大多基于ViT模型,发展方向大致可以分为四类:部分方法是通过引入局部性计算降低模型的计算复杂度,有的方法是基于层次化结构提取不同尺度的特征,还有方法通过结合CNN和Transformer的优势提高模型性能,同时更深度的视觉Transformer算法也在不断发展。表1对比了视觉Transformer典型算法与CNN模型在ImageNet数据集上的分类性能。
表2 Transformer与CNN在CV领域的模型性能对比
算法 | Params (M) | FLOPs(G) | Top-1Acc. (%) | ||
CNN模型 | ResNet | ResNet-101 | 44.6 | 7.8 | 79.9 |
ResNet-152 | 60.2 | 11.5 | 80.8 | ||
ResNeXt | ResNeXt-101-32×4d | 44.2 | 8.0 | 78.8 | |
ResNeXt-101-64×4d | 83.5 | 15.5 | 79.6 | ||
SENet | SEResNet-101 | 49.3 | 7.8 | 77.6 | |
SEResNet-152 | 66.8 | 11.5 | 78.4 | ||
SENet-154 | 115.1 | 20.7 | 81.3 | ||
RegNetY | RegNetY-8GF | 39.2 | 8.0 | 79.9 | |
RegNetY-32GF | 145.0 | 32.3 | 81.0 | ||
EfficienetNet | EfficienetNet-B4 | 19.0 | 4.2 | 82.9 | |
EfficienetNet-B5 | 30.0 | 9.9 | 83.7 | ||
Transformer 模型 | ViT | ViT-B/16 | 86.4 | 743.0 | 77.9 |
ViT-L/16 | 307.0 | 5172.0 | 76.5 | ||
Swin-Transformer | Swin-S | 50.0 | 8.7 | 83.0 | |
Swin-B | 88.0 | 15.4 | 83.3 | ||
TNT | TNT-S | 23.8 | 5.2 | 81.3 | |
TNT-B | 65.6 | 14.1 | 82.8 | ||
PVT | PVT-Large | 61.4 | 9.8 | 81.7 | |
PVTv2-B5 | 82.0 | 11.8 | 83.3 | ||
PVTv2 | T2T-ViT-24 | 64.1 | 13.2 | 82.2 | |
T2T-ViT | PyramidTNT-S | 32.0 | 3.3 | 82.0 | |
PyramidTNT | PyramidTNT-B | 157.0 | 16.0 | 84.1 | |
CvT | CvT-13 | 81.6 | 4.5 | 20.0 | |
CvT-21 | 82.5 | 7.1 | 32.0 | ||
DeiT | DeiT-S | 22.1 | 4.6 | 79.8 | |
DeiT-B | 86.4 | 17.6 | 81.8 | ||
CaiT | CaiT-S-36 | 68.2 | 13.9 | 83.3 | |
CaiT-M-36 | 270.9 | 53.7 | 83.8 | ||
DeepViT | DeepViT-S | 27.0 | 6.2 | 82.3 | |
DeepViT-L | 55.0 | 12.5 | 83.1 | ||
3、Transformer在CV领域的研究现状
从最初受到NLP中Transformer的启发推出VIT、DERT,再到后来的Swin Transformer横空出世,不过仅仅两年。如今,Transformer已经被广泛的应用于计算机视觉领域中的各个子任务中。
在图像分类任务中,VIT的改进模型DeiT、CaiT已经在准确率上领先ResNet和EfficientNet;
在目标检测任务上,UP-DETR对DETR 中的Transformer进行无监督预训练提升了AP值;ACT端到端的目标检测方法降低了计算量。
在图像分割任务上,Segmenter使用类掩码Transformer解码器进一步提高了0.2%~1.22% mIoU;SegFormer将Transformer与轻量级多层感知器(MLP)解码器相结合,在不同的数据集上都要优于最新的CNN网络模型。
在移动端模型上,2022年提出了一种用于移动设备的轻量级通用视觉transformer—Mobile-ViT。该网络在ImageNet-1k数据集上实现了78.4%的最佳精度,比MobileNetv3还要高3.2%,而且训练方法简单,满足在移动端上视觉模型的使用。
表3 视觉Transformer典型模型
任务类别 | 典型模型 | 设计重点 | 发表情况 |
图像分类 | ViT | 输入图像序列化、纯Transformer架构 | ICLR2020 |
Swin-T | 跨窗口注意力计算机制 | ICCV2021 | |
TNT | 嵌套结构、局部注意力计算机制 | NIPS2021 | |
PVT | 金字塔结构、纯Transformer架构 | ICCV2021 | |
T2T-ViT | 渐进式Tokens-to-Token机制 | ICCV2021 | |
DeiT | 蒸馏学习、数据增强、正则化训练机制 | ICML2021 | |
CvT | CNN替代位置编码 | ICCV2021 | |
CaiT | 分类注意力机制、深层网络结构 | ICCV2021 | |
目标检测 | DETR | 二分匹配、集合预测 | ECCV2020 |
TSP | 匹配蒸馏法 | ICCV2021 | |
UP-DETR | 可形变卷积、多尺度可形变注意力机制 | CVPR2021 | |
FPT | 跨空间和跨尺度的非局部交互编码 | ECCV2020 | |
图像分割 | SETR | 3种不同复杂度的解码器结构 | CVPR2021 |
SegFormer | 层级结构编码器、轻量级MLP解码器 | NIPS2021 | |
Segmenter | 逐点线性解码器、掩码Transformer解码器 | ICCV2021 |
从目前的研究趋势看来,未来基于Transformer的图像分类方法的研究将会集中在如何更好的引入局部性和层次化结构,从而达到和Transformer的全局性形成互补以提高模型的性能。此外,同时结合Transformer和CNN优点的模型也已经出现,例如TransCNN网络,通过在自注意力块后引入CNN层使网络可以继承Transformer和CNN的优点。因此如何结合二者的优势构建性能更佳的分类算法也是未来的研究热点之一。
五、Transformer在多模态领域的发展
多模态问题是多种不同类型数据的融合问题,凭借自注意力机制,Transformer拥有强大的序列特征提取能力,因此对于不同类型、不同模态的数据,都能够使用Transformer进行数据的转换,将不同模态的信息转换为序列数据进行后续处理,解决多模态数据融合的问题。目前,Transformer在多模态领域中的任务有以下几种:视频-文本检索、文本到图像生成、视频字幕生成、视觉-语音导航等。
1、视频-文本检索
视频-文本检索(Video-Text Retrieval)是视觉和语言领域的一个经典任务,要求根据文本检索视频,或根据视频检索文本。
2021年3月北大、FAIR、自动化所、快手联合推出HiT,称为层次Transformer。跨视频文本模态检索模型基于层次化对比学习,利用Transformer不同网络层的输出具有不同尺度的特性,设计了层次跨模态对比匹配模块,对Transformer底层网络和高层网络信息分别进行对比匹配,从而得到更好的视频文本检索性能。此外基于动量更新机制,设计了动量跨模态对比模块,使跨模对比匹配的过程能充分利用负样本,从而得到更好的视频和文本表征,克服了端到端的方法受显存容量限制的缺点。HiT在多个视频-文本检索数据集上取得了更加高效且精准的结果。
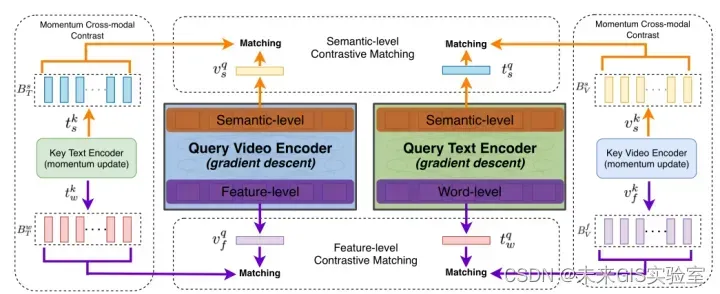
图19 用于视频文本检索的分层Transformer(HiT)的结构(图源:《HiT: Hierarchical Transformer with Momentum Contrast for Video-Text Retrieval》)
2、文本到图像生成
文本生成图像与ChatGPT一样都是最近很热门的方向,具体任务是将一段描述图像的文本输入AI模型中,模型输出符合描述的图像。文本到图像的生成任务是一个开放性的问题,既需要强大的生成模型也需要跨模态的理解能力。
2021年5月,清华大学和阿里巴巴达摩院共同研究开发的CogView用Transformer来控制文本生成图像的模型。下图是本文的主要模型框架,通过拼接文本特征和图像token特征进行自回归训练。最终实现只输入文本token特征,模型可以连续生成图像token,这点其实就是GPT的训练方式。
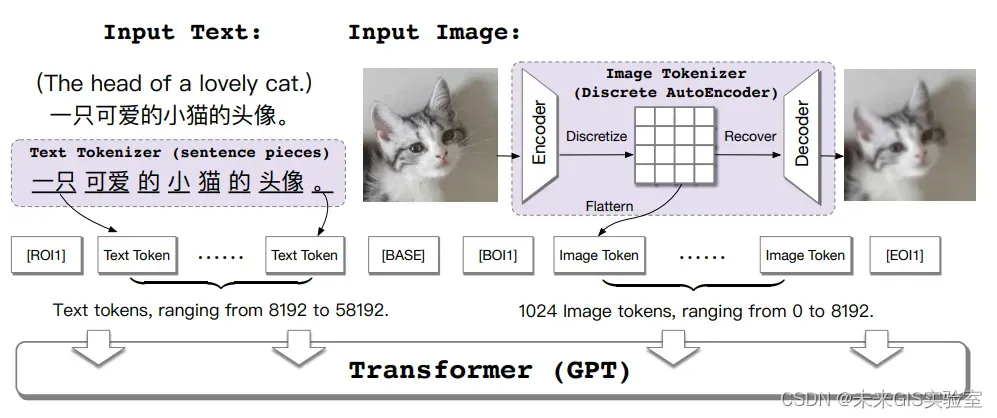
图20 cogview的方案结构示意图(图源:《CogView: Mastering Text-to-Image Generation via Transformers》)
CogView将VQ-VAE框架与Transformer相结合,用于解决文本到图像生成问题。首先利用训练好的编码器将图像压缩到低维离散空间,再通过解码器从隐藏变量中恢复图像,最后采用自回归模型学习拟合隐藏变量的先验。这种离散压缩方法比直接下采样损失更少的保真度,同时保持了像素空间的相关性。CogView在3亿个高质量文本-图像对上进行预训练后再微调。通过提出的精度瓶颈松弛和“三明治”层归一化模块,解决了由于文本-图像数据异质性而导致预训练过程不稳定情况,提高了文本到图像生成的质量。
3、视频字幕生成
2021年11月微软提出第一个端到端的视频字幕生成方法:SWINBERT。之前的方法都是使用其他任务上训练的特征提取器对video进行特征提取,所提取的特征可能与视频描述任务并不是绝对的匹配,即特征提取不参与训练。SwinBERT利用Swin Transformer提取视频帧序列的特征,然后输入至多模态Transformer编码器中,经过处理生成自然语言描述。在多模态编码器中,通过引入可学习的稀疏注意掩码约束解决了视频长序列计算量大的问题。与利用多个2D/3D特征提取器的字幕生成方法相比,SwinBERT可适应不同长度的视频输入,同时在性能上也有了很大的提升。下图展示了本文所提出的模型。
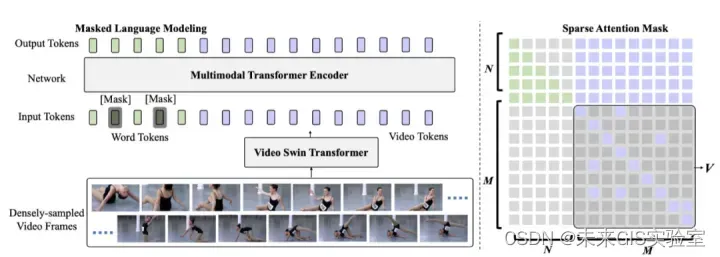
图21 SwinBERT结构(图源:《SWIN BERT: End-to-End Transformers with Sparse Attention for Video Captioning》)
4、视觉-语言导航
视觉-语言导航任务也是CV与NLP领域结合的主要任务。导航是智能体在现实环境中行动的一个基础且关键的能力。传统导航任务主要通过直接给定目的地坐标、目的地或目的物体的图像,或目的物体的类别来指挥智能体进行导航。但是,这种导航目标并不是我们与机器进行交互的最方便的方式。我们更喜欢直接用自然语言进行交互。类似这样一个情景,给定自然语言指令“走出浴室。左转,通过左侧的门离开房间。在那里等待”,希望智能体在虚拟环境中理解语言指令,并遵循该指令,按照给定的路线完成导航,到达规定的目的地。因此,越来越多的研究开始关注于以语音为导航指导的视觉语言导航任务(Vision-and-LanguageNavigation,VLN)。
在基于视觉与语言的导航(VLN)任务中,密歇根州立大学2022年9月提出的LOViS设计了一个拥有显式方向模块和视觉模块的智能体,这些模块学习将语言指令中提及的空间信息、地标信息与视觉环境对齐。另外,为了加强智能体的空间推理能力和视觉感知能力,此外还设计了特定的预训练任务去提升每个模块的性能。并且在R2R和R4R数据集上都达到了SoTA效果。
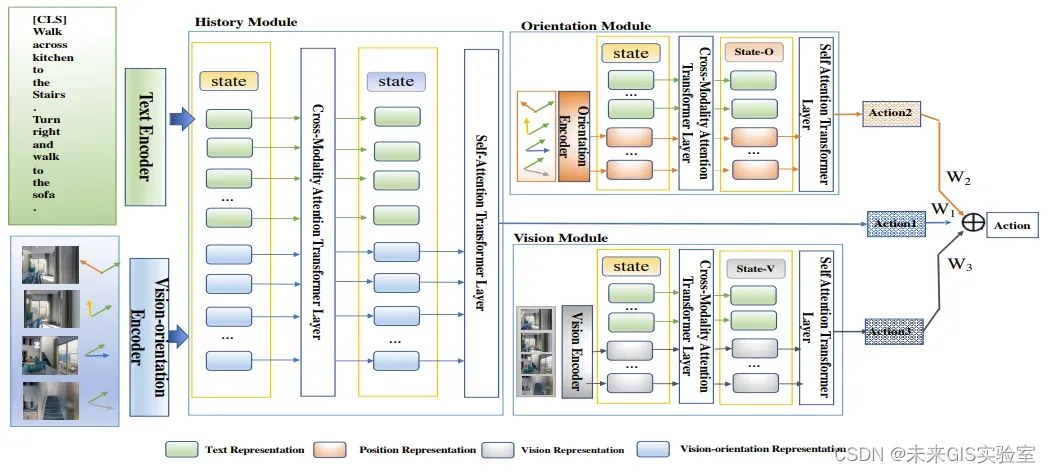
图22 LOViS模型的三个模块,历史模块、方向模块和视觉模块(图源:《LOViS: Learning Orientation and Visual Signals for Vision and Language Navigation》)
六、总结与展望
Transformer凭借强大特征提取能力补齐了传统RNN在NLP领域中的诸多短板,其多种衍生模型在NLP任务上表现出色。此外,随着CNN模型的发展从成熟走向瓶颈,Transformer为CV领域注入了新鲜血液,从分类到分割,从图像到视频,Transformer已逐步代替CNN成为解决CV领域问题新范式。除强大的特征提取能力外,Transformer的自注意力结构在多类型数据模式对齐上也同样表现优秀,为处理文本、语音、图像、视频等多类型数据融合问题提供了新思路。
可以预见,Transformer在未来还有更大的发展潜力。对于不同领域的不同任务类型,Transformer有望成为一个通用框架,实现模型架构的大一统。

技术交流/科研合作/客座实习/联合培养请投递:futuregislab@supermap.com
「未来GIS实验室」作为超图研究院上游科研机构,致力于洞见未来GIS行业发展方向,验证前沿技术落地可行性,以及快速转化最新研究成果到关键产品。部门注重科研和创新功底,团队气氛自由融洽,科研氛围相对浓厚,每个人都有机会深耕自己感兴趣的前沿方向。
文章出处登录后可见!