关于AI
自有计算机以来,人们就想让计算机具有人的感知、意识、概念、思维、行为,代替人的工作。AI (Artificial Interligence)是计算机科学的一个分支,专注研究、开发、模拟、扩展人的智能的理论、方法、技术及应用。
从研究领域和方法上, AI分为 模式识别、自然语言处理、专家系统、机器人等。
模式识别研究人的视觉、听觉等,分析、识别声音、图形、图像中有意义的事物,神经网络 /深度学习是模式识别的主要技术方法。如今,声音识别、人脸识别等已具有较高水平。
自然语言处理研究人类的语言,分析、理解语言的含义,存储知识,回答问题。 ChatGPT采用神经网络技术进行自然语言处理,技术上采用了大参数级别的语言大模型,取得惊人的效果。
专家系统研究人的逻辑、推理,用知识、事实、规则、逻辑、推理表达世界。
机器人是带有感官、动作装置(眼睛、手、脚等)的AI,目前各种各样的机器人已大量应用在工厂、办公、军事、家庭中,逐步取代越来越多工作。预言称,未来的人,将变为一半是生物人、一半是机器人的融合体。
虽然 AI 有几十年的历史,但当前的AI仍处于弱人工智能水平, 就是说,AI只在有限领域、有限环境上能超过人。未来某一天,强人工智能、通用人工智能(AGI)可能出现, 将在所有领域超过人,那是人类时代的一个奇点,人类将进入人+智能机器混合体的新时代。
在国内,百度AI是领先的,且提供了免费试用。我们先从学习使用百度AI开始吧。
一、首先,注册一个百度云开发帐号,开通免费资源
1, 登录 https://cloud.baidu.com/ , 点右上角“注册”
按屏幕提示操作完成。 注册是免费的,过程中要登录手机。
2,注册、登录后,在右上角 帐号 点进去,完成 个人实名登记。(不实名,领不了AI免费资源)
3, 实名完成后,点左上角,点“产品服务”, 看到百度云有众多云服务,其中右侧是人工智能。
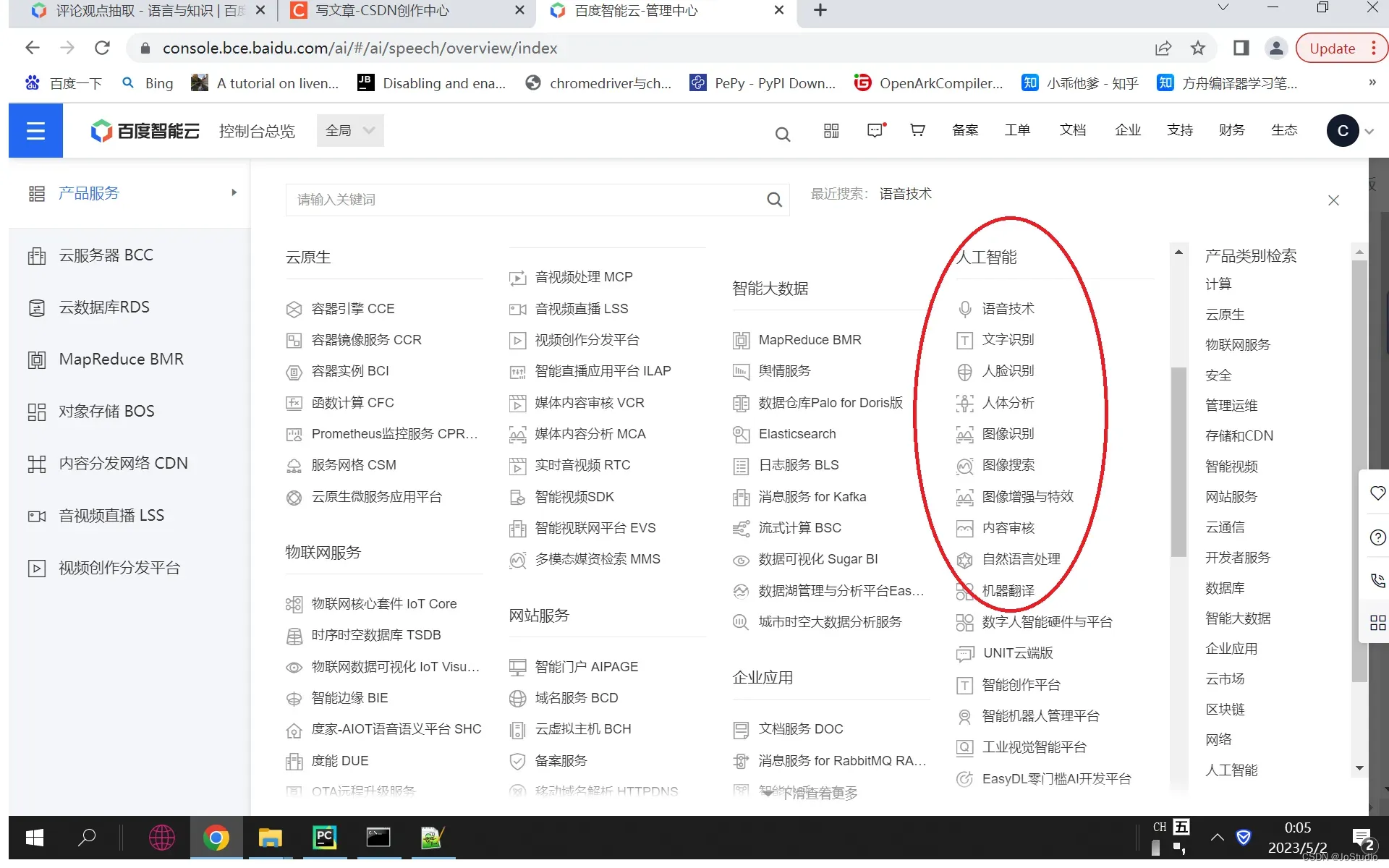
4, 点击 产品服务 ”人工智能” 下的 “语音技术“,进入,则看到以下界面
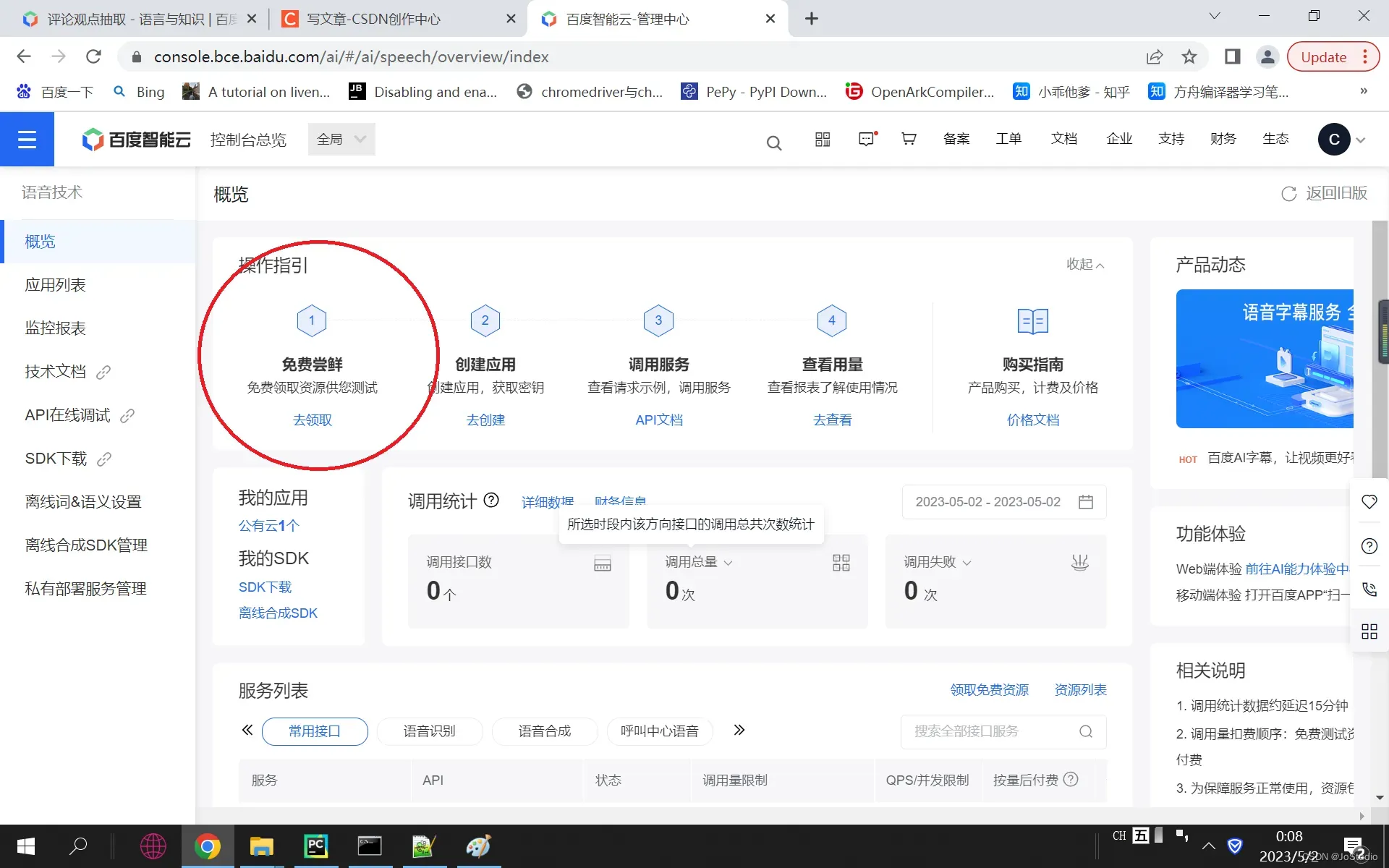
点击 ”免费尝鲜” 下的 “去领取”, 进入后,在“待领接口”中选择全部, 再点最下方的 “0元领取”.
至此,“语音技术” 的免费资源就领到了。
5, 操作过程同上,领取其它各类AI的免费资源。
(1)点左上角,点“产品服务” –> “人工智能/文字识别” -> ”免费尝鲜” 下的 “去领取” -> 领取全部。
(2)点左上角,点“产品服务” –> “人工智能/人脸识别” -> ”免费尝鲜” 下的 “去领取” -> 领取全部。
(3)点左上角,点“产品服务” –> “人工智能/人体分析” -> ”免费尝鲜” 下的 “去领取” -> 领取全部。
(4)点左上角,点“产品服务” –> “人工智能/图像识别” -> ”免费尝鲜” 下的 “去领取” -> 领取全部。
(5)点左上角,点“产品服务” –> “人工智能/内容审核” -> ”免费尝鲜” 下的 “去领取” -> 领取全部。
(6)点左上角,点“产品服务” –> “人工智能/自然语言处理” -> ”免费尝鲜” 下的 “去领取” -> 领取全部。
(7)点左上角,点“产品服务” –> “人工智能/机器翻译” -> ”免费尝鲜” 下的 “去领取” -> 领取全部。
至此,把百度AI的主要免费资源都领了。
每一类AI的免费资源赠送量不同,可以在“概览”页找到。如下:
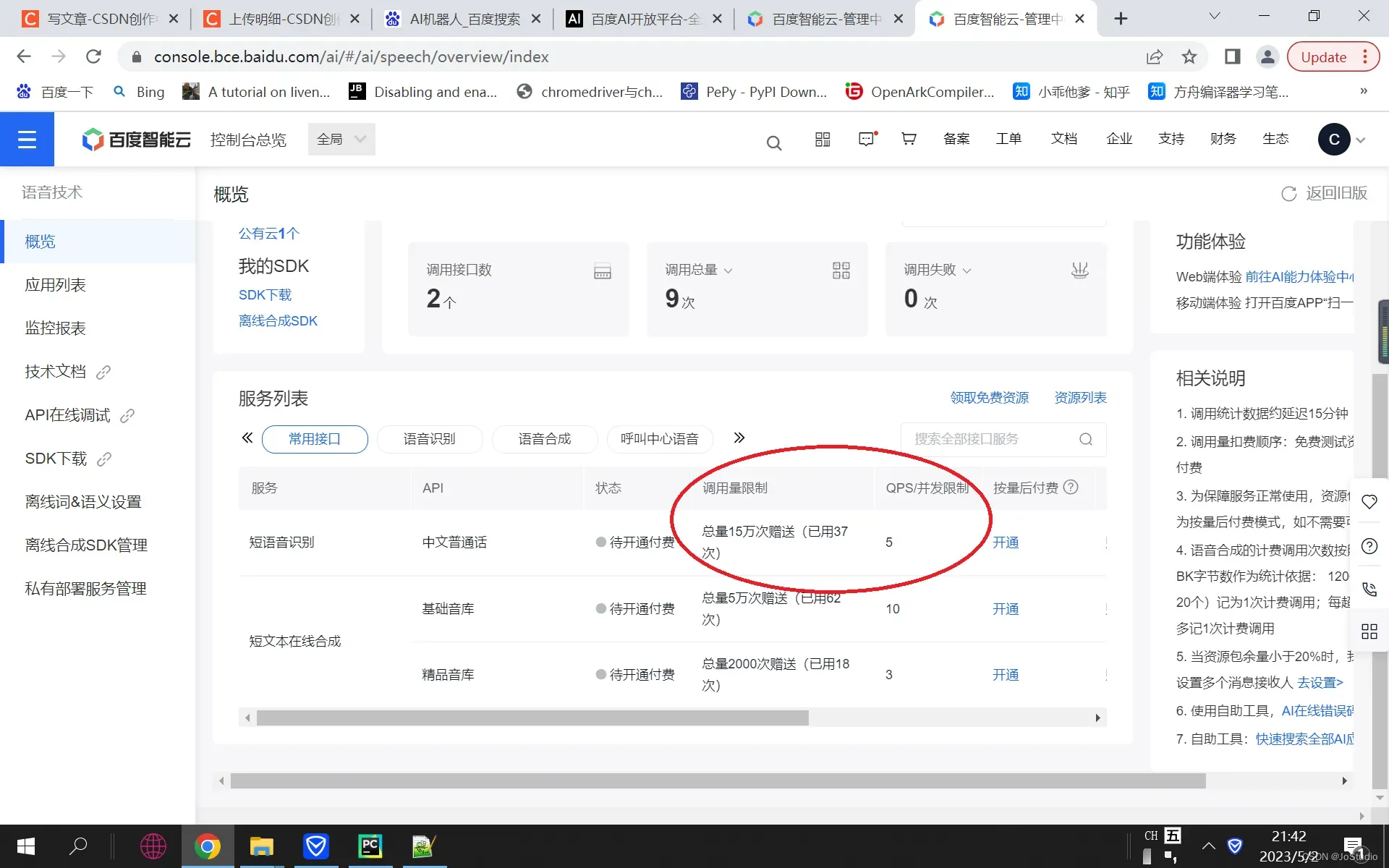
比如:短语音识别免费量达15万次,对于开发学习、小型应用足够用了。各类AI的免费量不同,具体请看各类AI的“概览”页。
说明:百度AI有一个并发限制,QPS ( Query Per Second ), 意思是每秒查询数量, 就是指每秒种可以执行的这一类AI的请求量。
6, 创建一个应用
点左上角,点“产品服务” –> “人工智能/语音技术”,在下面的界面中, 点“创建应用” 下的 “去创建“
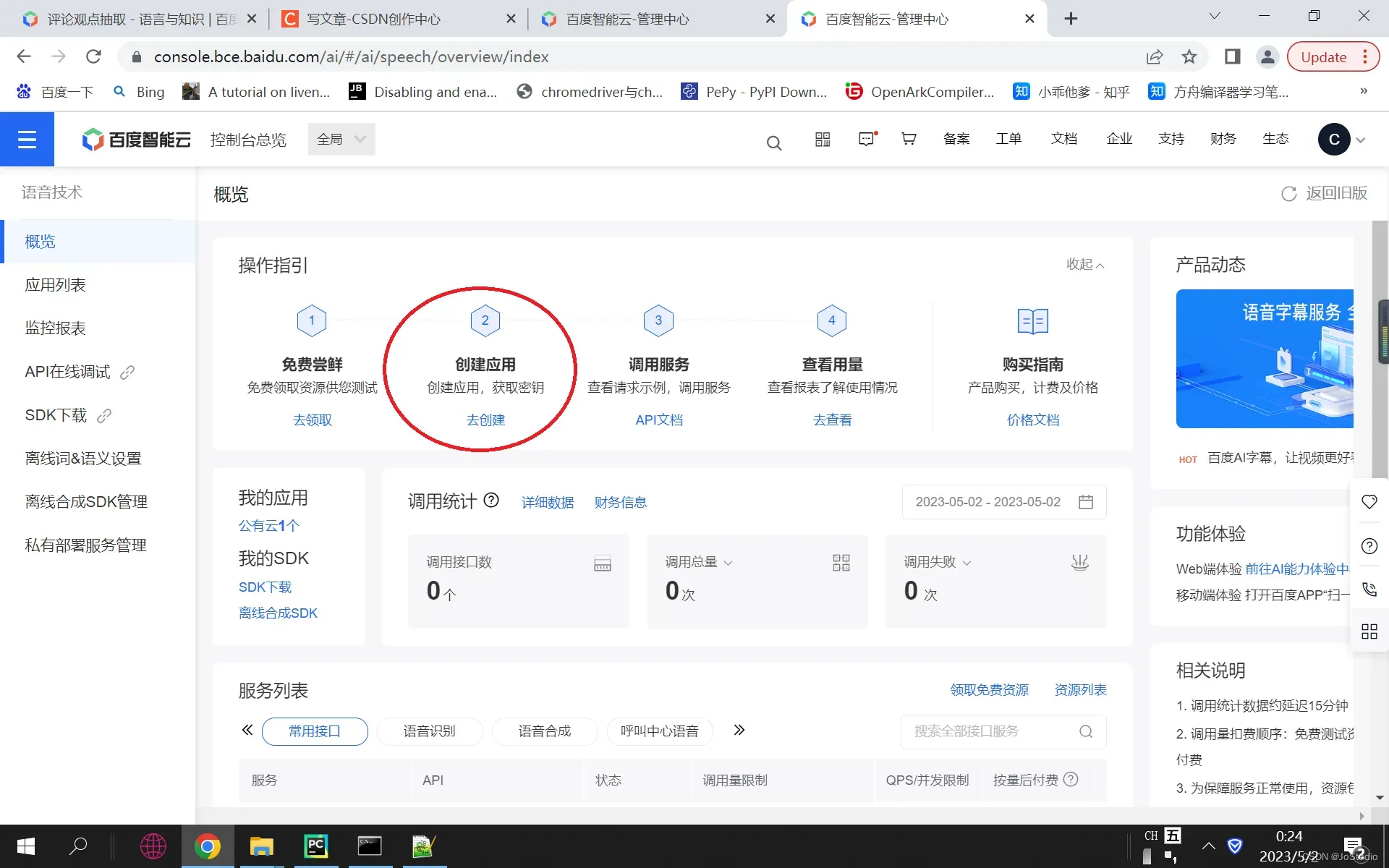
在创建应用页面(如下)中,写应用名称(随便写),点开 “语音技术“, 勾选“全选”。再依次点开 下面的“文字识别”、“人脸识别” 、。。。,全部勾选“全选”,
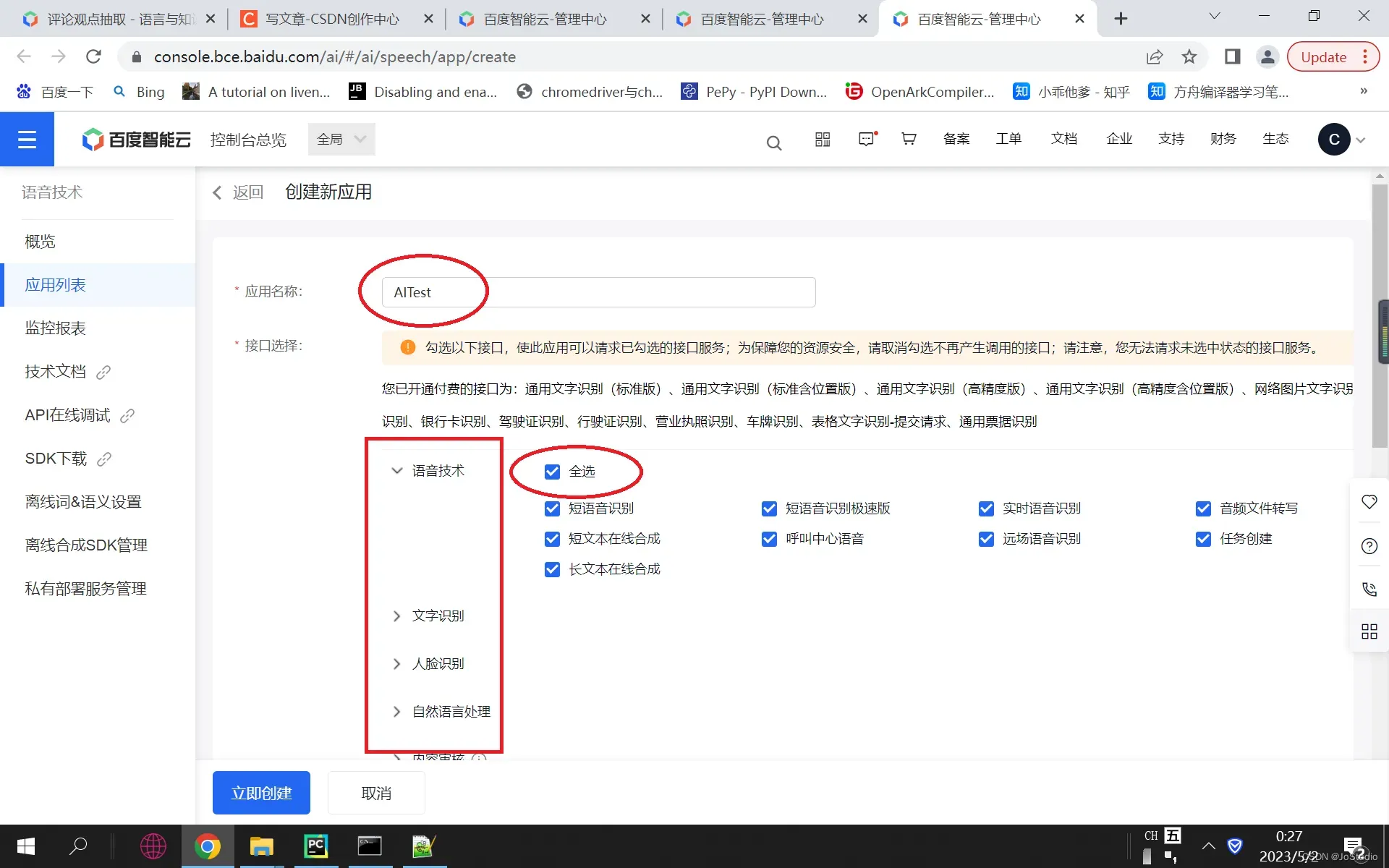
表格往下滚, “应用归属”选“个人”, “应用描述” 填 “学习”
最后, 点最下方 ”立即创建“
这个过程的意思是,创建一个应用,该应用有权调用 ”语音技术“全部API, “文字识别“全部API, 。。。。等等全部API.
7, 创建应用后,获得 API Key, Secret Key 两个参数。
创建应用后,点“返回应用列表”, 则得到以下界面
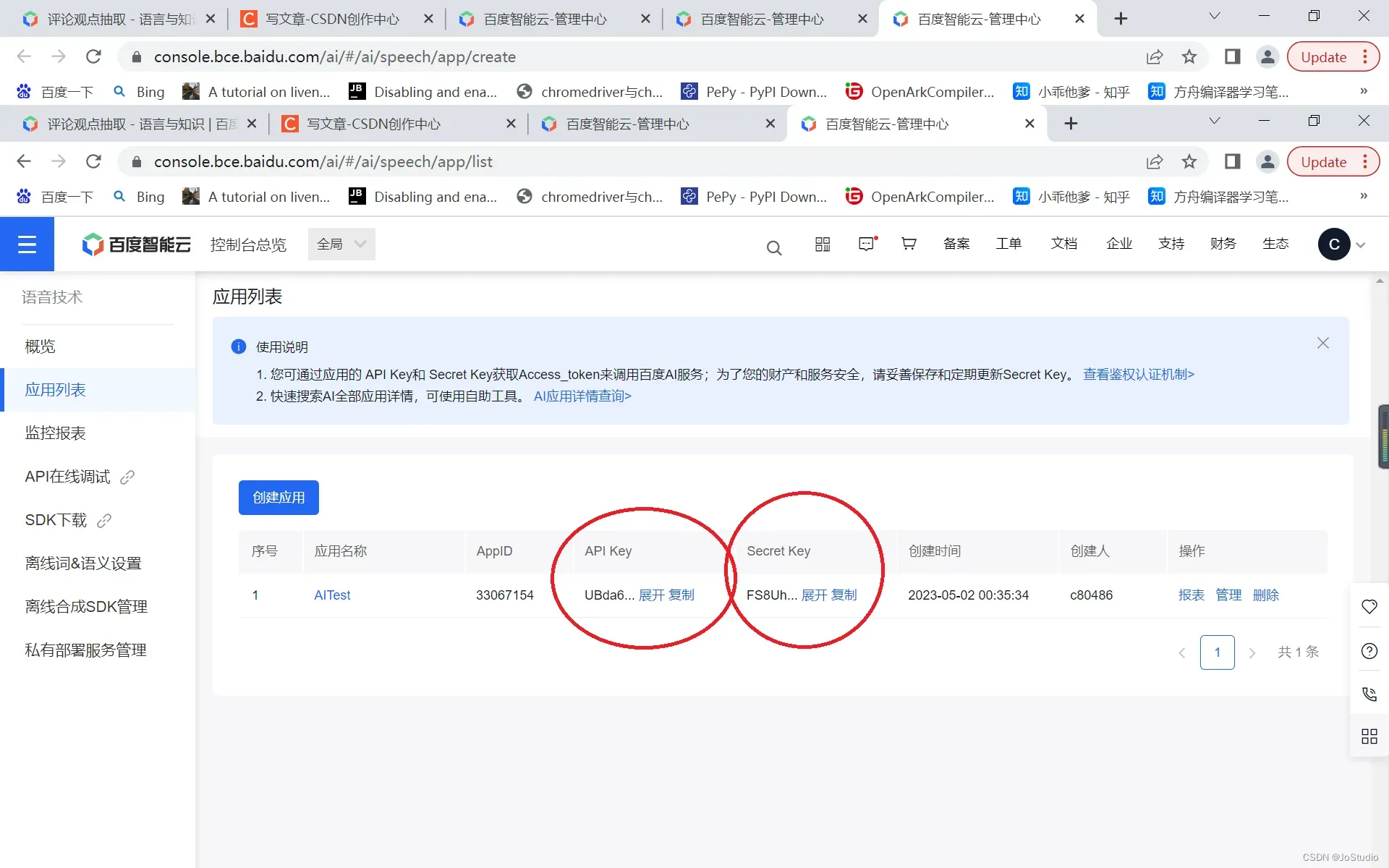
可以看到,我们创建了一个应用名为 “AITest”, 它有一个API Key, 一个 Secret Key.
点击 API Key 下的 “复制”, 把API Key 粘贴到一个文本文件中, 这是一个长的字符串。
再点击 Secret Key 下的 “复制”, 把Secret Key 粘贴到文本文件中,也是一个长串。
API Key 和 Secret Key 是开发时调用 API时必须使用的两个参数。
每一个应用有一对 API Key 和 Secret Key,用于身份认证。
上述过程只要做一次就够了,除非你要产生多对 API Key 和 Secret Key。
二、调用 API的基本原理
API, 全称是 Application Programming Interface 应用编程接口, 是一个平台提供给开发者的接口函数。
不同平台的API提供形式都不太一样。Windows 提供 Win32 API, IOS 提供 IOS API, Andriod 提供 Andriod API. 互联网平台(百度云、阿里云、ChatGPT等等)都提供自己的API.
一般来说, 互联网平台以 HTTP 协议提供API, 称为 Web API。相当于,平台提供一个网页URL, 开发者向该URL发起请求,提交参数,并取得结果。
提供API的平台,也同时会提供 API开发文档。
对于开发者,调用互联网平台提供的API, 可以有以下几种方式:
1, 使用平台提供的SDK包。
2, 按API开发文档说明,使用HTTP,直接读写参数,操作API, 也可形成自己的开发包。
由于百度AI 对于Python的SDK不好用,示范代码也难读。我就写了一个Python库用于 操作百度AI.
三、使用PIP 安装 jojo-ai 库
jojo-ai库是笔者写的python库,用于操作AI API, 简单好用。
请在命令行,通过PIP安装:
pip install jojo-ai库的安装名称是 jojo-ai
使用时: import ai 即可。
import aijojo-ai库依赖库包括:requests, 安装时将自动安装完成。
为了播放声音,建议再安装 playsound 库
pip install playsound四、使用jojo-ai 库, 调用 百度AI
1, 使用 jojo-ai 库 调用 百度 AI 很简单, 就两步:
import ai
# 以下请写入百度云中创建应用后提供的API Key、Secret Key
api_key = 'XXXXXXXXXXXXXXXXXXXXXXXXX'
secret_key = 'XXXXXXXXXXXXXXXXXXXXXXXXX'
# 第一步:创建 BaiduAI 对象, 代入 api_key, secret_key 两个参数
b = ai.BaiduAI(api_key, secret_key)
# 第二步:使用 BaiduAI 对象的asr()方法, 即调用 百度语音转文本API
texts = b.asr('images/16k.wav')
print(texts)2, 百度AI提供的主要API, 对应jojo-ai库中BaiduAI对象的方法
| 分类 | API接口 | 功能简述 | jojo-ai库BaiduAI对象的方法 |
| 语音技术 | 语音识别 | 语音转文本 | asr() |
| 语音合成 | 文本转语音 | tts() | |
| 文字识别 | 通用文字识别 | 图像转文本 | ocr() |
| 身份证识别 | 身份证图像转文本 | ocr_id_card() | |
| 银行卡识别 | 银行卡图像转文本 | ocr_bank_card() | |
| 人脸识别 | 人脸检测 | 抓图像中的人脸 | face_detect() |
| 人脸比对 | 比对两张人脸 | face_match() | |
| 人脸融合 | 人像换脸 | face_merge() | |
| 人体分析 | 人流量统计 | 统计图像中的人数 | body_count() |
| 人体检测 | 抓图像中的人体 | body_detect() | |
| 人体关键点识别 | 图像中的人体关键点 | body_anlysis() | |
| 图像识别 | 物体识别 | 分析图像中的物体 | classify() |
| 植物识别 | 识别植物品种 | classify_plant() | |
| 动物识别 | 识别动物品种 | classify_animal() | |
| 车型识别 | 识别车型 | classify_car() | |
| 红酒识别 | 识别红酒 | classify_wine() | |
| 图像主体检测 | 识别主体 | classify_objects() | |
| 菜品识别 | 识别菜式 | classify_dish() | |
| 自然语言处理 | 智能写诗 | 写诗(七言绝句) | nlp_poem() |
| 智能春联 | 写春联 | nlp_couplets() | |
| 节日祝福语 | 生成节日祝福语 | nlp_bless() | |
| 地址分析 | 拆解地址信息 | nlp_address() | |
| 情感倾向分析 | 分析语言中的情绪 | nlp_sentiment() | |
| 评论观点抽取 | 抽取评论中主要观点 | nlp_comment() | |
| 词法分析 | 将一句话拆解为词 | nlp_lexer() | |
| 关键词提取 | 提取一句话中关键词 | nlp_keywords() | |
| 新闻摘要 | 长新闻变短摘要 | nlp_summary() | |
| 文章标签 | 提取文章中的标签词 | nlp_tags() | |
| 文章分类 | 文章自动分类 | nlp_topic() |
还有一些百度API,觉得没啥意思,jojo-ai库暂未封装
附:几个英文缩写的说明
ASR ( Automatic Speech Recognition ) 自动语音识别
TTS ( Text-To-Speech ) 文字转语音
OCR ( Optical Character Recognition ) 文字识别
NLP (Natural Language Processing) 自然语言处理
3, 以下是例程, 例程中所需的图片资源等较多,请在此处下载例程及图片资源
库中每个方法有参数解释,返回值的解释请参考相应百度AI文档。
import ai
from pprint import pprint # pprint() 用于将dict打印得好看些
# 以下请写入百度云中创建应用后提供的API Key、Secret Key
api_key = 'XXXXXXXXXXXXXXXXXXXXXXXXX'
secret_key = 'XXXXXXXXXXXXXXXXXXXXXXXXX'
# 创建 BaiduAI 对象, 代入 api_key, secret_key 两个参数
b = ai.BaiduAI(api_key, secret_key)
# 调用各个API
print('====语音转文本')
texts = b.asr('images/16k.wav')
print(texts)
print('====文本转语音')
b.tts('我是北京人')
print('====文字识别')
print(b.ocr("https://www.baidu.com/img/flexible/logo/pc/result.png"))
print('====身份证识别')
pprint(b.ocr_id_card("images/idcard2.jpg"))
print('====银行卡识别')
pprint(b.ocr_bank_card("images/bank_card.jpg"))
print('====人脸检测')
pprint(b.face_detect("images/face1.jpg", "age,expression"))
print('====人脸比对')
pprint(b.face_match("images/face1.jpg", "images/face2.jpg"))
print('====人脸融合')
pprint(b.face_merge("images/face2.jpg", "images/template.jpg", "images/merge_face.jpg"))
print('====人流量统计')
pprint(b.body_count("images/bodys.jpg"))
print('====人体检测')
pprint(b.body_detect("images/bodys2.jpg"))
print('====人体关键点识别')
pprint(b.body_anlysis("images/body_ana.jpg"))
print('====通用物体和场景识别')
pprint(b.classify("images/notebook.jpg"))
print('====植物识别')
b.classify_plant("images/plant3.jpg")
print('====动物识别')
pprint(b.classify_animal("images/animal3.jpg"))
print('====车型识别')
pprint(b.classify_car("images/car1.jpg"))
print('====红酒识别')
pprint(b.classify_wine("images/wine1.jpg"))
print('====图像主体检测')
pprint(b.classify_objects("images/objects1.jpg"))
print('====菜品识别')
pprint(b.classify_dish("images/dish1.jpg"))
print('====智能写诗(七言绝句)')
pprint(b.nlp_poem("长江望月"))
print('====智能春联')
pprint(b.nlp_couplets("长江"))
print('====节日祝福语生成')
pprint(b.nlp_bless("情人节"))
print('====地址识别')
pprint(b.nlp_address("上海市浦东新区纳贤路701号百度上海研发中心 F4A000 张三"))
print('====情感倾向分析')
pprint(b.nlp_sentiment("实在不怎么样"))
print('====评论观点抽取')
pprint(b.nlp_comment("三星电脑电池不给力", "3C"))
print('====词法分析')
pprint(b.nlp_lexer("百度是一家高科技公司"))
print('====关键词提取')
pprint(b.nlp_keywords("学习书法,就选唐颜真卿《颜勤礼碑》原碑与对临「第1节」"))
print('====新闻摘要')
title = "麻省理工仓库货物管理"
content = '麻省理工学院的研究团队为无人机在仓库中使用RFID技术进行库存查找等工作,创造了一种聪明的新方式。它允许公司使用更小,更安全的无人机在巨型建筑物中找到之前无法找到的东西。使用RFID标签更换仓库中的条形码,将帮助提升自动化并提高库存管理的准确性。与条形码不同,RFID标签不需要对准扫描,标签上包含的信息可以更广泛和更容易地更改。它们也可以很便宜,尽管有优点,但是它具有局限性,对于跟踪商品没有设定RFID标准,“标签冲突”可能会阻止读卡器同时从多个标签上拾取信号。扫描RFID标签的方式也会在大型仓库内引起尴尬的问题。固定的RFID阅读器和阅读器天线只能扫描通过设定阈值的标签,手持式读取器需要人员出去手动扫描物品。'
pprint(b.nlp_summary(title, content, 80))
print('====文章标签')
title = "麻省理工仓库货物管理"
content = '麻省理工学院的研究团队为无人机在仓库中使用RFID技术进行库存查找等工作,创造了一种聪明的新方式。它允许公司使用更小,更安全的无人机在巨型建筑物中找到之前无法找到的东西。使用RFID标签更换仓库中的条形码,将帮助提升自动化并提高库存管理的准确性。与条形码不同,RFID标签不需要对准扫描,标签上包含的信息可以更广泛和更容易地更改。它们也可以很便宜,尽管有优点,但是它具有局限性,对于跟踪商品没有设定RFID标准,“标签冲突”可能会阻止读卡器同时从多个标签上拾取信号。扫描RFID标签的方式也会在大型仓库内引起尴尬的问题。固定的RFID阅读器和阅读器天线只能扫描通过设定阈值的标签,手持式读取器需要人员出去手动扫描物品。'
pprint(b.nlp_tags(title, content))
print('====文章分类')
title = "麻省理工仓库货物管理"
content = '麻省理工学院的研究团队为无人机在仓库中使用RFID技术进行库存查找等工作,创造了一种聪明的新方式。它允许公司使用更小,更安全的无人机在巨型建筑物中找到之前无法找到的东西。使用RFID标签更换仓库中的条形码,将帮助提升自动化并提高库存管理的准确性。与条形码不同,RFID标签不需要对准扫描,标签上包含的信息可以更广泛和更容易地更改。它们也可以很便宜,尽管有优点,但是它具有局限性,对于跟踪商品没有设定RFID标准,“标签冲突”可能会阻止读卡器同时从多个标签上拾取信号。扫描RFID标签的方式也会在大型仓库内引起尴尬的问题。固定的RFID阅读器和阅读器天线只能扫描通过设定阈值的标签,手持式读取器需要人员出去手动扫描物品。'
pprint(b.nlp_topic(title, content))
五、 不采用库,直接采用 HTTP 操作百度API的样例
根据百度云开发文档,操作百度API分两步
第一步, 凭 API Key, Secret Key ,取得 access token.
第二步,凭access token, 按API的文档要求,发起API请求,取得结果
例程如下:
import requests
# 请写入百度云中创建应用后提供的API Key、Secret Key
api_key = 'XXXXXXXXXXXXXXXXXXXXXX'
secret_key = 'XXXXXXXXXXXXXXXXXXXXXX'
# 第一步:凭 API Key, Secret Key ,取得 access token.
# 获取access token的 API 的 URL 在这
url = 'https://aip.baidubce.com/oauth/2.0/token'
# api_key, secret_key 作为请求参数
params = {
'grant_type': 'client_credentials',
'client_id': api_key,
'client_secret': secret_key
}
# 发起请求, 取得 access token.
response = requests.get(url, params=params)
if response:
data = response.json()
access_token = data['access_token'] # 取得 access token.
else:
raise ConnectionError()
# 第二步,凭access token, 访问相应API
# 比如:智能写诗 API 的文档在这: https://ai.baidu.com/ai-doc/NLP/ak53wc3o3
# 智能写诗的API的URL在这
api_url = "https://aip.baidubce.com/rpc/2.0/creation/v1/poem"
# 根据文档, 请求 url 要加上 access token
request_url = api_url + "?access_token=" + access_token
# 根据文档, 请求参数 text 是诗的主题
params = {'text': '长江'}
# 请求头部标明发送json数据
headers = {'content-type': 'application/json'}
# 发送请求 POST
response = requests.post(request_url, json=params, headers=headers)
if response:
print(response.json()) # 响应结果是一个json, 其中包含一首诗
同理,jojo-ai 库就是采取HTTP实现对各个API的访问的, 其 BaiduAI类 将各个百度 AI API封装好,隐藏众多细节,方便大家使用。
文章出处登录后可见!