文章目录
1. 写在前面
为了研究机器人是否能够比人类更好地解决基于图像的验证码问题,我们构建了一套真正的验证码识别解决方案,请先看下面视频与截图:
Google验证码突防
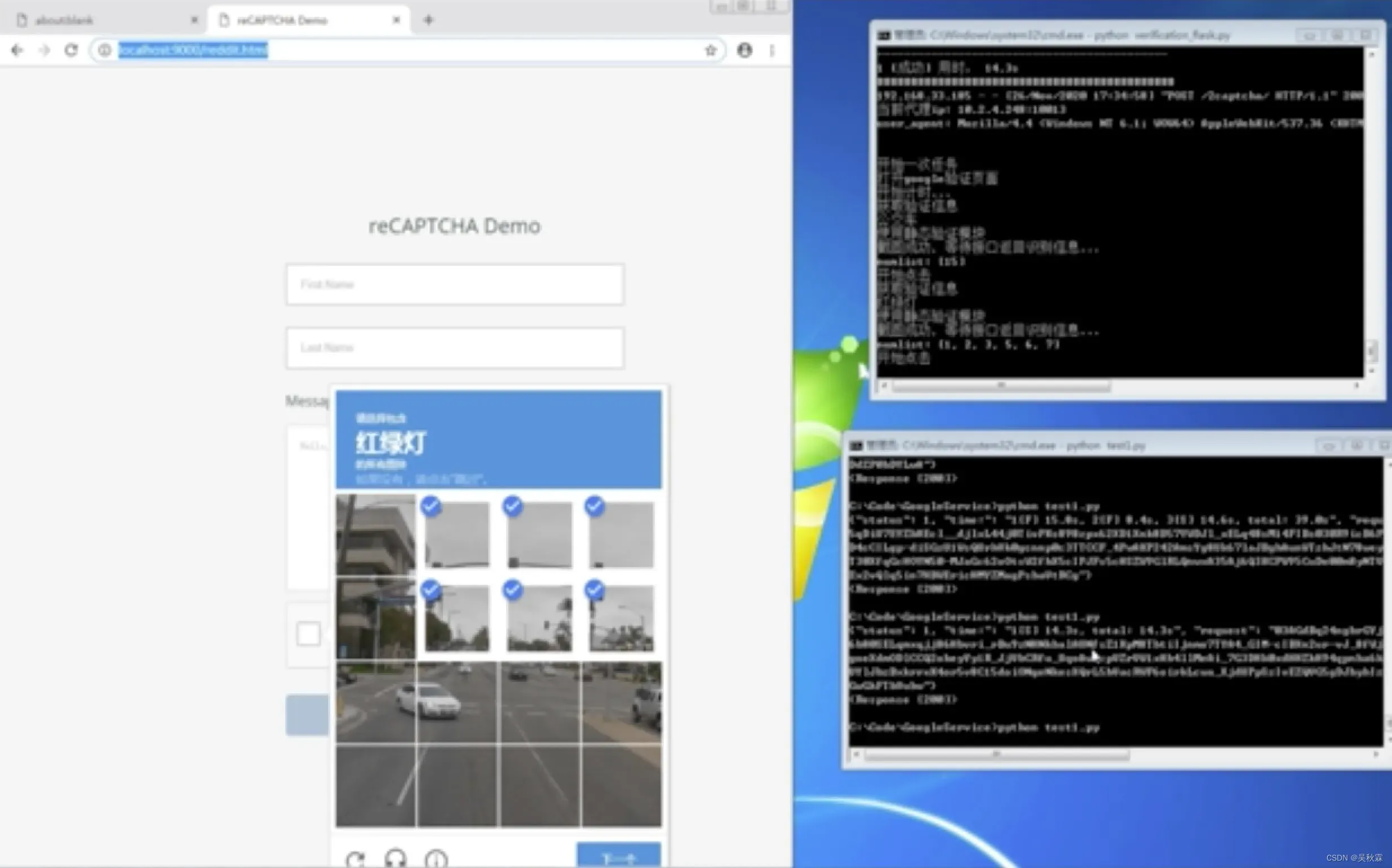
主要由2个模块组成:突破模块和算法模块。这些模块相互作用,形成一个完全在线和完全自动化的系统,打破谷歌基于图像的验证码服务reCAPTCHAV2
这篇文章主要是对Google验证码突防软件的功能和作用进行一个描述以及Google验证码突防系统的结构,还有接口规格说明和算法细节设计
如下是模块交互的工作流程:
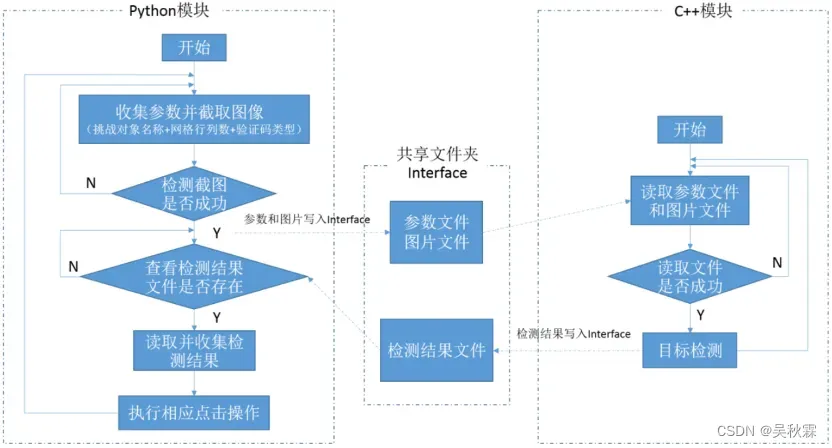
2. CSCI级设计决策
2.1. Google验证码突防关联
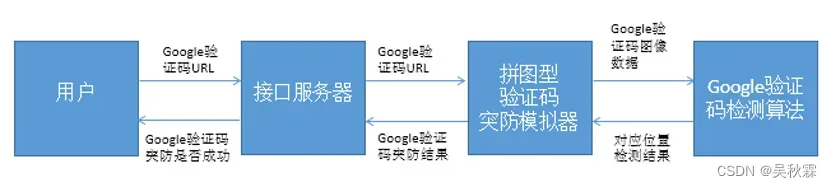
1、用户:Google验证码突防软件使用者
2、接口服务器:接收用户数据并返回突防结果
3、Google验证码突防模拟器:获取待检测数据,根据检测结果进行突防,并将突防结果返回
4、Google验证码检测算法:对待检测Google验证码进行检测
2.2. Google验证码突防行为设计决策
Google验证码接口服务器主要完成数据传输任务,在用户和Google验证码突防模拟器之间传输Google验证码的网址和突防结果
Google验证码突防模拟器主要工作为:
- 据接口服务器提供的url获取Google验证码图像数据及图像数据对应的标签、模式、类型
- 获取算法模块的检测结果,然后模拟人工做相应点击操作
- 获取Google验证码突防状态码,并将结果返回到接口服务器
Google验证码检测算法主要功能主要是对突防模拟器提供的Google验证码图像数据进行识别检测,并将检测结果返回突防模拟器,突防用例如下如所示:

3. Google验证码突防体系结构设计
3.1. Google验证码突防部件
3.1.2. Google验证码突防组成
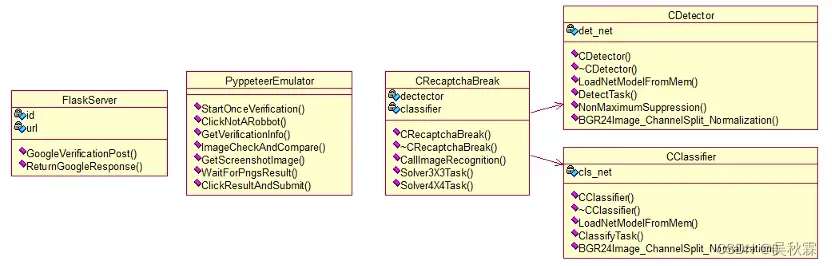
构成Google验证码突防的所有部件如下图所示:
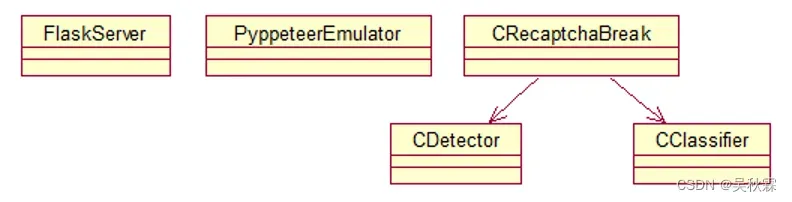
- FlaskServer
该模块接收用户输入的url及id返回验证突防结果 - PyppeteerEmulator
该模块对需要突防验证的网站进行突防,并将突防结果返回给FlaskServer服务 - CReaptchaBreak
根据PyppeteerEmulator模块提供的参数文件和图片数据进行目标检测,将检测结果返回给PyppeteerEmulator模块 - CDetector
该模块主要实现对于实体目标进行位置和大小的检测,采用 512×512 Single Shot MultiBox Detector 深度学习算法,为了加强检测成功率,通过金字塔模式增强其检测成功率 - CClassifier
该模块由多个分类器组成,分别针对于不同的认知目标进行判别,采用类ResNet 多个网络结构的深度学习算法,该算法在特别针对于每种目标进行了优化
3.2. Google验证码突防软件
3.2.1. Google验证码突防软件体系结构
Google验证码突防软件体系结构图如下所示:
3.2.2. Google验证码突防软件开放的公用类
-
FlaskServer
该模块主要包括两部分,一部分接受用户输入的url及id,以此判断进行验证的类型,另一部分调用PyppeteerEmulator
模块进行验证,并将验证突防结果返回给用户 -
PyppeteerEmulator
该模块对需要突防验证的网站进行获取验证图像、获取图像检测返回结果、根据返回结果对网页进行相应点击操作等一系列行为,对网站进行验证突防,并将突防结果返回给FlaskServer服务 -
CReaptchaBreak
该模块会等待PyppeteerEmulator模块提供参数文件和图片数据,若参数文件存在,则根据参数文件中的信息,对图片文件进行目标检测,并将检测结果返回给PyppeteerEmulator模块 -
CDetector
该算法模块主要实现对于实体目标进行位置和大小的检测,采用 512×512 Single Shot MultiBox Detector 深度学习算法,为了确定目标的存在及其在图像中的位置,目标检测模型从一组带标签的训练图像中学习。检测对象的目标位置通常用边界框来描述。边界框是一个矩形框,通常由左上角的 x 轴和y 轴坐标以及矩形右下角的x 轴和 y 轴坐标定义。在SSD目标检测网络中,我们虽然采用多尺度特征图的方式来保证能够检测到不同大小的物体,但是有些目标在图像中因为过大或者过小,会造成目标漏检,因此为进一步加强检测成功率,我们还对图像通过“金字塔模式”进行不同尺度的缩放后拼成一张 512×512 大图送入目标检测网络,该策略主要用于动态验证码。在我们的实验中,我们发现 SSD与其他检测系统相比,在保持几乎相似的检测性能的同时,速度较快。SSD提取了不同尺度的特征图来做检测,CNN网络一般前面的特征图比较大,后面逐渐采用 stride=2 的卷积或者pooling 层来降低特征图大小。一个比较大的特征图和比较小的特征图都用来做检测,这样做的好处就是比较大的特征图用来检测相对比较小的的目标,而小的特征图负责用来检测大的物体 -
CClassifier
该算法有多个分类器,采用类 ResNet网络结构的深度学习算法组成,分别针对不同的认知目标进行判别。我们通过实验统计发现,reCaptcha突破还有几个出现频率较高的对象,如:人行横道、楼梯、烟囱、山,为弥补SSD目标检测算法在目标类别丰富度上的缺陷,并且针对小轿车、自行车和公交车等较小目标机器无法识别但肉眼可见的情况,我们再特别针对这 7 种目标进行优化
3.3. Google验证码突防软件对象交互
3.3.1. Google验证码突防软件交互
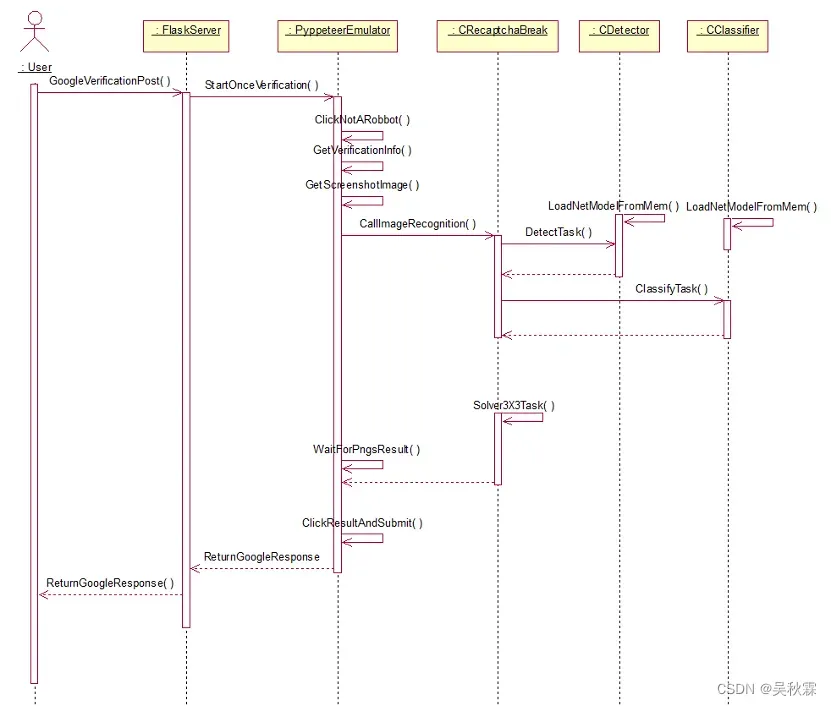
开启一次突破,PyppeteerEmolator勾选我不是机器人选框后对出现的验证码页面进行数据获取,并把数据发送给CRecapthaBreak模块,该模块会根据验证码的类型(3X3和4X4)执行对应的目标检测。最后将验证突破结果层级返回到用户
Google验证码3X3交互图如下所示:
Google验证码4X4交互图如下所示:
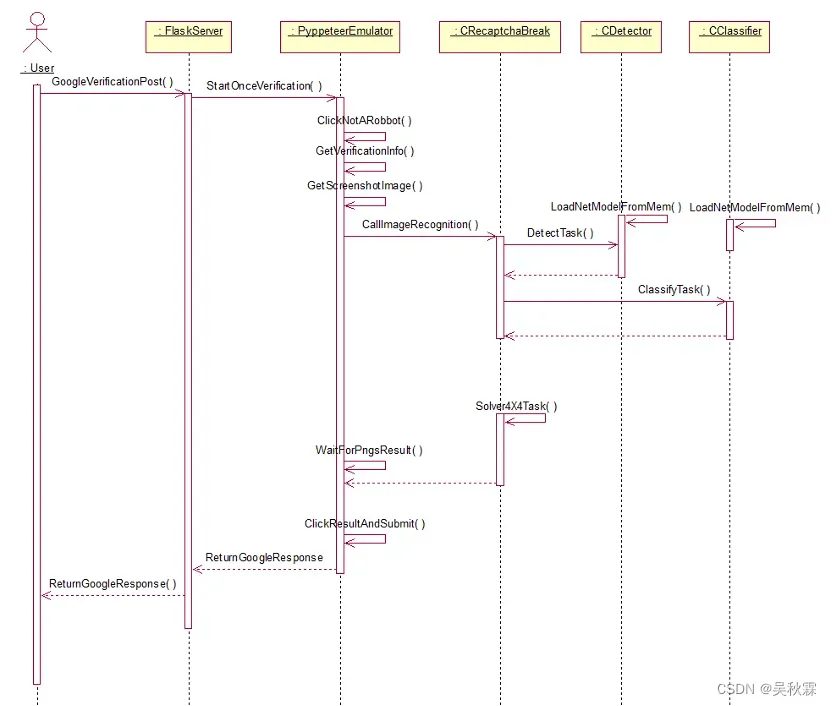
Google验证码突防软件接收到用户传输的信息后,突防软件交互模块根据PyppeteerEmulator获取到的URL截取图片及图片信息,将其传递给CReaptchaBreak模块进行目标检测,并返回结果通过PyppeteerEmulator进行模拟点击和验证,最后将验证结果返回给用户
| 对象 | 类 |
|---|---|
| Google验证服务 | FlaskServer |
| 模拟浏览器 | PyppeteerEmulator |
| 验证码破防器 | CReaptchaBreak |
4. 核心算法设计细节
4.1. 算法目标
验证码从诞生之日起,就被广泛地运用在阻止攻击者的不合法操作上。尽管验证码能在一定程度上拦截攻击者,但是在经济利益的驱动下,各种针对验证码的自动化攻击方式层出不穷,验证码服务也相应地做出改进。然而最近,出现了一种针对文本验证码的通用攻击方式。Google也适时地公布了reCaptcha的最新版本。最新版本有双重目标:一是减少合法用户通过验证码认证的成本,二是提供了对计算机来说,比文本识别更具挑战性的验证码。ReCaptcha是由一个“高级的风险分析系统”驱动的,这种系统能分析收到的请求,并挑出适合难度的验证码返回给用户。用户可能需要勾选一个checkbox,或者需要挑出描述相同内容的一组图片。Google提供的reCaptcha服务是使用最广泛的验证码服务,许多主流网站都用它来拦截自动化机器的不合法攻击。我们的目标就是让机器模拟人的模式去突破Google的reCaptcha验证码
我们首先对reCaptcha v2进行了整体性的研究。通过分析,我们整个验证流程分解为多次图像问答的模式, 这样使得图灵验证问题转化为图像的识别问题。在此基础上, 我们再通过场景, 将问题进行分类, 分而治之。 我们通过大量的人工实测实验,评估了reCAPTCHAV2的图像问答问题中图像的形式和类别以及辨识的难度。分析表明,当前最新版本的reCaptcha v2在问题图像的变化上会更加多样化, 加入了自动噪音的设计以及包括点击速度, 点击顺序, 以及一些虽然是目标但是通常人类可能不会去选取的一些图像识别以外的参数,使得先前基于分类器的攻击无效, 并且更难以突破。基于我们的测试, 我们设计了一套算法来解决这个问题, 实现我们的新版本reCaptcha验证码突破
分而治之, 首先通过分析我们知道验证码主要分为三种模式:
静态模式3X3, 这是一个简单的基于图像选择的验证码突破,需要用户选择包含目标对象的所在网格,然后单击验证按钮

静态模式4X4, 同样, 这也是基于图像选择的验证码突破,需要用户选择包含目标对象的所在网格,然后单击验证按钮, 由于图像的连续性, 一些不规则的目标(例如人行横道, 楼梯等)会极大地增加突破难度

动态模式3X3, 开始的时候,突破图像所呈现的方式与静态验证码是相同的。但是,一旦用户单击包含目标对象的所在网格后,新的图像就会加载到选定的网格上。它要求用户继续点击所有潜在的网格,直到突破窗口小部件中没有目标对象的图像。最后,用户单击验证按钮。该类型的验证突破由于图像是缓慢载入的, 会使得突破时长变得更长; 当然, 由于九张图像是各自独立的, 避免了不规则目标, 因此突破难度比静态会更低

在分析过程中我们还发现reCaptcha能够自适应应对我们机器人程序突破验证码的行为进行限制, 对于一定时间内累计识别错误的增加, 其提出的图像问题的难度也会随之增加, 会增加更难以辨认的图像, 会对于问题回答的答案要求更加苛刻。在我们的实验中,我们测试到突破图像的具有丰富的多样性。在下面的图中展示了一些背景失真的图像, 一些存在严重噪音的图像。同时我们看到有的目标物体有着不规则的形状, 以及不完整的形状。例如,验证码可能会提出自行车图像选择的问题, 但是实际给的问题图像可能只包括其中的一部分轮胎。其目的是使得问题变得模棱两可,故意混淆自动化程序。对此, 我们专门设计了克服这样问题的模块, 与图像识别模块并行工作, 协同解决这个问题



4.2. 主要算法模块说明
针对于reCaptcha提出图像问题, 速度和准确度都对于通过存在贡献, 为了提高速度, 我们直接采用截取屏幕图像的方式获得问题图像, 这样可以加快整个突破流程, 在我们测试中这样比采用图像下载的方式提升30%左右的处理速度, 在这里我们采用图像匹配算法以及变化图像稳定性判别算法模块来处理这个问题
4.3. 图像区域位置识别算法
该算法模块主要是实现对于验证码区域的识别,采用经典图像匹配算法,通过模式将验证码区域图像准确获得并按模式进行4X4或3X3矩阵分割。这里主要是对于图像进行一个全局的特征图像搜索并结合一些位置区域特征, 例如特殊的图像, 特殊位置的图像元素等特征进行问题图像的定位, 并在图像显示完成后及时进行图像的截取
4.4. 物体检测算法
该算法模块主要实现对于实体目标进行位置和大小的检测,采用512X512 Single Shot MultiBox Detector深度学习算法,为了确定目标的存在及其在图像中的位置,目标检测模型从一组带标签的训练图像中学习。检测对象的目标位置通常用边界框来描述。边界框是一个矩形框,通常由左上角的x轴和y轴坐标以及矩形右下角的x轴和y轴坐标定义。近年来,随着深度学习技术的发展和GPU等低成本计算设备的普及,一些强大的目标检测系统应运而生。我们尝试了几种先进的目标识别系统,如mask RCNN、Faster RCNN和SSD以及YOLO。我们发现,除了SSD和YOLO之外,大多数模型的计算成本都很高,而YOLO的精度特别是目标物体较小的时候, 精度是低于SSD的 ,即使我们利用了GPU。由于我们提出的系统是完全在线的,并且验证码挑战是时间敏感的,为了同时兼顾速度与精度, 所以我们决定使用SSD。在SSD目标检测网络中,我们虽然采用多尺度特征图的方式来保证能够检测到不同大小的物体,但是有些目标在图像中因为过大或者过小,会造成目标漏检,因此为进一步加强检测成功率,我们还对图像通过“金字塔模式”进行不同尺度的缩放后拼成一张512X512大图送入目标检测网络,如下图片的缩放和拼接方式示例。该策略主要用于动态验证码

在我们的实验中,我们发现SSD与其他检测系统相比,在保持几乎相似的检测性能的同时,速度较快。基于这些原因,我们在工作中使用了SSD作为基本的目标检测算法,网络结构如下图所示。从网络结构图可以看到,SSD提取了不同尺度的特征图来做检测,CNN网络一般前面的特征图比较大,后面逐渐采用stride=2的卷积或者pooling层来降低特征图大小。一个比较大的特征图和比较小的特征图都用来做检测,这样做的好处就是比较大的特征图用来检测相对比较小的的目标,而小的特征图负责用来检测大的物体
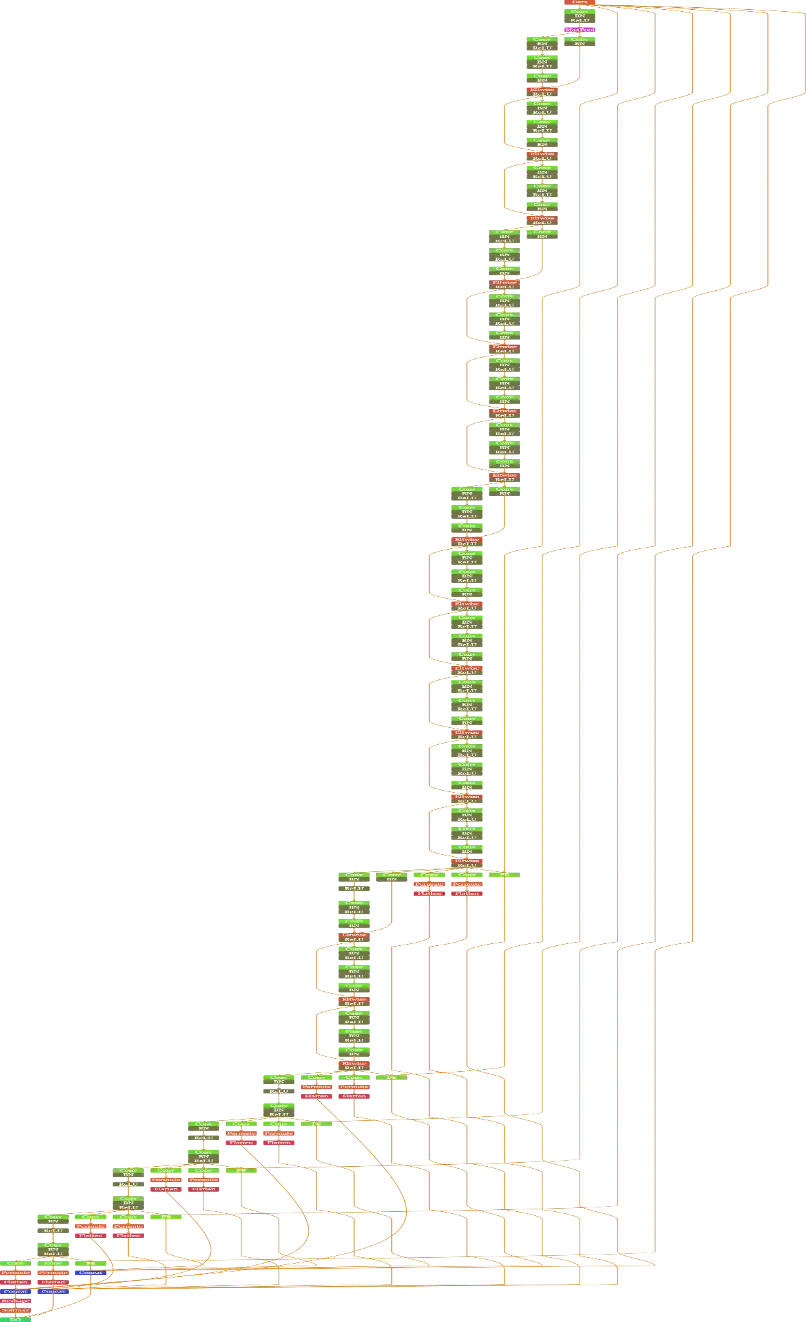
4.5. 特定目标分辨算法
该算法有多个分类器,网络结构如下图所示,采用类ResNet网络结构的深度学习算法组成,分别针对不同的认知目标进行判别。我们通过实验统计发现,reCaptcha突破还有几个出现频率较高的对象,如:人行横道、楼梯和烟囱,它们不存在于MSCOCO数据集的80类。为弥补SSD目标检测算法在目标类别丰富度上的缺陷,并且针对小轿车和公交车等较小目标机器无法识别但肉眼可见的情况,我们再特别针对这7种目标进行优化。算法在几乎所有的模式中都有使用
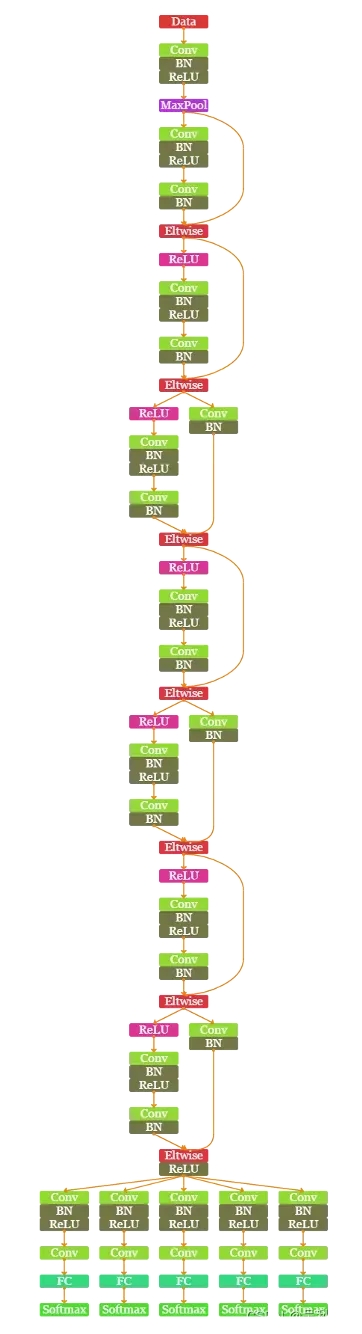
4.6. 目标主区域分类算法
该算法的提出主要为了解决选择框误报问题。该问题产生的原因主要有两个方面:
1、SSD检测算法的缺陷,即:对象的实际形状可能不像边界框那样是矩形。
2、一个对象可能并不总是占据整个边界框。这两个因素可能会导致边界框到网格的映射中出现一些误报。虽然很难完全消除误报,但我们采用目标主体区域分类算法,以尽可能减少影响。
该算法主要学习人类对于目标区域以及主体的关系。我们使用人工标注的5000+图片与机器选择的区域相比较,获得学习模型,让机器理解主体与选择框的关系,从而进一步加强对选框的精确性。算法在静态模式中使用
5. 训练数据说明
我们使用公有ImageNet、MSCOCO和自定义数据集这3个数据集来分别训练检测模型和分类模型,我们首先简要描述数据集,然后简要描述训练过程。
针对SSD目标检测算法,我们首先使用ImageNet+私有数据共计140万张左右标注图片进行模型pre-trained。这样做的好处我们认为有3点:
1、ImageNet囊括了1000类别的数据,这些数据有各种各样浅层和深层的特征,在ImageNet上训练好的权值很好的提取到了这些特征。
2、 不同图片数据之间或多或少都存在共性,包括我们能看到和看不到的,因此在ImageNet上的权值能提取到我的图片数据集上的这些共性特征。
3、 ImageNet上特征在别的数据集上可能是不同的表现形式,用ImageNet上预训练的权值在我的图片数据集上提取到的这些特征刚好有一些特征可以很好地区分数据集中的图片。
为了提高预训练模型的精度,进而进一步提高后续模型的准确率,我们采用了warm-up优化技巧。意义在于,在模型训练的初始阶段,该模型对数据还很陌生,需要使用较小的学习率慢慢学习,不断的修正权重分布;中间阶段,当使用较小的学习率学习了一段时间后,模型已经把每批数据都看了几遍,形成了一些先验知识,这时候就可以使用较大的学习率加速学习,前面学习到的先验知识可以使模型的方向正确;decay阶段,模型训练到一定阶段后,该模型学习到的分布已经大体固定,需要学习的“新知识”较少,这时候如果继续沿用很大的学习率,可能会破坏模型权重分布的稳定性。
然后我们在预训练模型的基础上,在MSCOCO数据集约330000标注图片以一个较小的初始学习率开始进行fine-tuning。在由于MSCOCO包括80个常见对象且已经包含了reCaptcha突破中经常出现的对象,因此我们使用这个数据集来训练我们的对象识别和检测系统。我们考虑到google验证码图片的复杂性,为了增加训练数据的多样性使其能尽量涵盖真实的数据特征,我们在训练过程中对MSCOCO数据集进行了包括颜色变换、裁剪、镜像、缩放、背景失真等一些列数据增强操作。
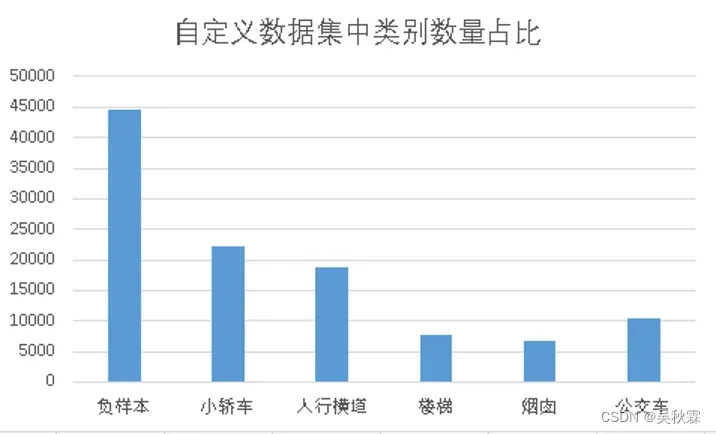
自定义数据集。针对特定目标分类算法,我们特地建立了一个网络爬虫来抓取图像,还使用了一些来自原始的reCaptcha挑战的图像,下载并人工标注了10+万图片(如下图)进行多次训练、优化参数和网络结构。下图显示了我们通过实验统计发现的出现频率较高的5个挑战对象在训练数据中的占比情况
文章出处登录后可见!