文章目录
- 一、ViT & ViT变种
- 1.1 ViT的介绍
- 1.2 ViT 的变种
- 二、bbox(边界框)
- 三、边界框的绘制
一、ViT & ViT变种
1.1 ViT的介绍
ViT,全称为Vision Transformer,是一种基于Transformer架构的视觉处理模型。传统的计算机视觉任务通常使用卷积神经网络(CNN)来提取图像的特征。而ViT的目标是将Transformer模型应用于计算机视觉任务,通过全局性的注意力机制来捕捉图像中的长程依赖关系。
传统的Transformer模型在自然语言处理领域中取得了巨大的成功,但直接将其应用于图像处理任务面临一些挑战,因为图像数据的结构和特征与文本数据不同。ViT通过将图像数据划分为一系列的图像块(或称为图像补丁),并将这些图像块作为序列输入Transformer模型中,来处理图像数据。
ViT模型的基本组成包括:
- 输入编码:输入图像被划分为一系列的图像块,每个图像块经过线性映射(通常使用一个卷积层)后,被表示为一个向量序列。
- Transformer编码器:ViT使用多个Transformer编码器层来处理输入的图像块序列。每个Transformer编码器层由自注意力机制(self-attention)和前馈神经网络(feed-forward network)组成。自注意力机制能够捕捉图像块之间的关联性,并对图像块进行上下文感知的特征表示。
- 分类头部:ViT模型的输出是通过一个额外的线性层进行分类预测。通常在最后一个Transformer编码器层的输出上应用全局平均池化操作,将图像块序列的特征聚合成一个全局特征向量,然后通过线性层进行分类。
ViT模型的训练通常使用有标签的图像数据和监督学习任务,如图像分类。然而,ViT也可以通过预训练和微调的方式在无标签数据上进行学习,以提取丰富的图像特征,然后用于特定的计算机视觉任务。
ViT在一些图像分类、目标检测、语义分割等计算机视觉任务上表现出色,并在一些领域挑战中取得了竞赛水平的结果。它的优点之一是能够处理全局上下文信息,而不仅仅是局部特征,使其在处理大尺寸图像或具有长程依赖关系的任务上具有优势。然而,对于像素级细节或空间信息的精细处理,ViT可能需要更大的模型规模或其他辅助技术来提升性能。
1.2 ViT 的变种
ViT-H,ViT-L和ViT-B是指不同规模和复杂度的Vision Transformer模型变体。
- ViT-H(High resolution):ViT-H是Vision Transformer模型中的高分辨率变体。它通常适用于处理高分辨率图像或更具挑战性的视觉任务。由于处理高分辨率图像可能需要更多的计算资源和内存,因此ViT-H模型可能更庞大和复杂。
- ViT-L(Low resolution):ViT-L是Vision Transformer模型中的低分辨率变体。它通常用于处理低分辨率图像或资源受限的环境。ViT-L模型可能比ViT-H模型更小、更轻量级,适合在资源受限的设备或场景中部署。
- ViT-B(Base resolution):ViT-B是Vision Transformer模型中的基准分辨率变体。它可以被视为ViT模型的中间规模。ViT-B通常是指在资源充足但不需要处理过高或过低分辨率图像时使用的模型。
需要注意的是,具体的ViT-H、ViT-L和ViT-B模型的规模和特征可以因不同的研究论文、实现和应用而有所不同。这些命名约定通常是为了区分不同规模和复杂度的模型变体,并在不同的视觉任务和计算资源约束下选择合适的模型。
二、bbox(边界框)
在目标检测中,bbox(边界框)是一种常用的表示方式,用于标记和定位目标物体的位置。
边界框(bbox)是一个矩形框,通常由四个坐标值表示,分别是左上角的x和y坐标,以及框的宽度和高度。常用的表示形式可以是(x_min, y_min, x_max, y_max)或者(x, y, w, h),其中(x_min, y_min)表示框的左上角坐标,(x_max, y_max)表示框的右下角坐标,(x, y)表示框的中心点坐标,w表示宽度,h表示高度。
在目标检测任务中,边界框用于标注出图像中包含目标的位置和大小,以便进行物体识别和定位。通常,目标检测算法会输出一组边界框,每个框都表示一个检测到的目标物体。
目标检测中的常见方法包括:
- 基于传统机器学习方法的目标检测:这些方法通常使用手工设计的特征和分类器,如Haar特征、HOG特征和SVM分类器等,来检测目标物体。
- 基于深度学习的目标检测:这些方法利用深度神经网络(如卷积神经网络)进行端到端的目标检测。常见的深度学习目标检测算法包括Faster R-CNN、YOLO(You Only Look Once)、SSD(Single Shot MultiBox Detector)等。
目标检测的输出通常包括边界框的位置和类别信息。在一些场景中,还可以输出与边界框相关的其他信息,如目标的置信度、旋转角度、姿态等。
边界框的准确性对目标检测的性能至关重要。通过准确地定位和包围目标物体,可以为后续的目标分类、跟踪和分割等任务提供准确的输入。因此,在目标检测算法的训练和评估过程中,通常会使用各种指标(如IoU、AP等)来度量边界框的准确性和算法的性能。
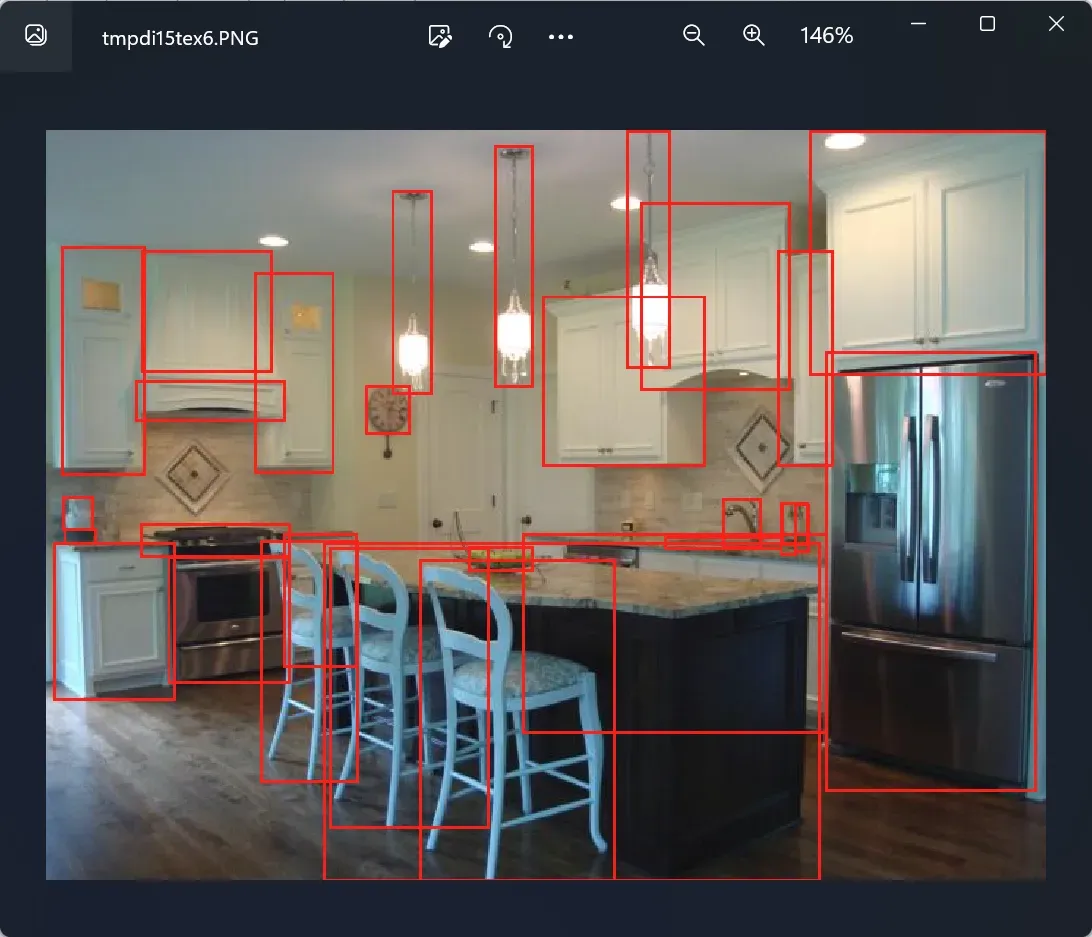
三、边界框的绘制
from PIL import Image, ImageDraw
def draw_bboxes(image, bboxes, color="red", thickness=2):
draw = ImageDraw.Draw(image)
for bbox in bboxes:
bbox = tuple(map(int, bbox)) # 将浮点数类型的坐标转换为整数类型
draw.rectangle(bbox, outline=color, width=thickness)
del draw
# 示例用法
image_path = "D:/CodeProject/CLIP+SAM/datasets/Objects365/Images/train/obj365_train_000000000002.jpg" # 原始图像路径
bboxes = [
(236, 41, 263, 180), (218, 174, 248, 207), (306, 10, 332, 175), (396, 0, 426, 162),
(189, 281, 528, 512), (255, 293, 388, 512), (193, 285, 302, 476),
(146, 280, 213, 445), (339, 113, 450, 229), (406, 49, 508, 177), (499, 82, 537, 229),
(521, 0, 683, 167), (5, 281, 88, 389), (162, 275, 212, 366), (10, 79, 67, 235),
(142, 97, 196, 234), (325, 275, 533, 411), (65, 82, 154, 165), (462, 251, 488, 285),
(422, 277, 502, 286), (501, 254, 512, 290), (511, 255, 521, 288), (532, 151, 676, 451),
(61, 171, 163, 198), (64, 268, 166, 291), (83, 291, 166, 377), (502, 254, 520, 283),
(11, 250, 32, 273), (12, 272, 34, 282), (288, 284, 332, 301)
] # 边界框坐标信息
image = Image.open(image_path).convert("RGB")
draw_bboxes(image, bboxes)
# 显示绘制边界框后的图像
image.show()
原图像为:

打框之后:
文章出处登录后可见!