目录
- 1. 数据集
- 2. 数据预处理
- 3. 构建模型
- 4. 模型测试&效果评估
- 4.1 准确率、精确率、召回率、F1值、混淆矩阵
- 4.2 学习曲线
- 4.3 ROC曲线、AUC值
- 5. 总结
- 6. 附录代码
1. 数据集
本次采用sklearn自带的Iris数据集
Iris数据集是一个经典的机器学习数据集,常用于分类算法的评估和比较。数据集包含了3种不同种类的鸢尾花 (setosa、versicolor和virginica) 的4个特征 (花萼长度、花萼宽度、花瓣长度和花瓣宽度) ,每种鸢尾花有50个样本。
Iris数据集中的4个特征分别是:
- 花萼长度(sepal length):鸢尾花的花萼长度,以厘米(cm)为单位。
- 花萼宽度(sepal width):鸢尾花的花萼宽度,以厘米(cm)为单位。
- 花瓣长度(petal length):鸢尾花的花瓣长度,以厘米(cm)为单位。
- 花瓣宽度(petal width):鸢尾花的花瓣宽度,以厘米(cm)为单位。
Iris数据集中的类别标签为:
- setosa:山鸢尾(target = 0)
- versicolor:杂色鸢尾(target = 1)
- virginica:维吉尼亚鸢尾(target = 2)
每个样本都包含4个特征和1个类别标签。Iris数据集的总体大小为150个样本,其中每个类别都有50个样本。
from sklearn import datasets
# 读取iris数据集
iris = datasets.load_iris()
x = iris.data
y = iris.target
这里得到的x、y为两个数组:
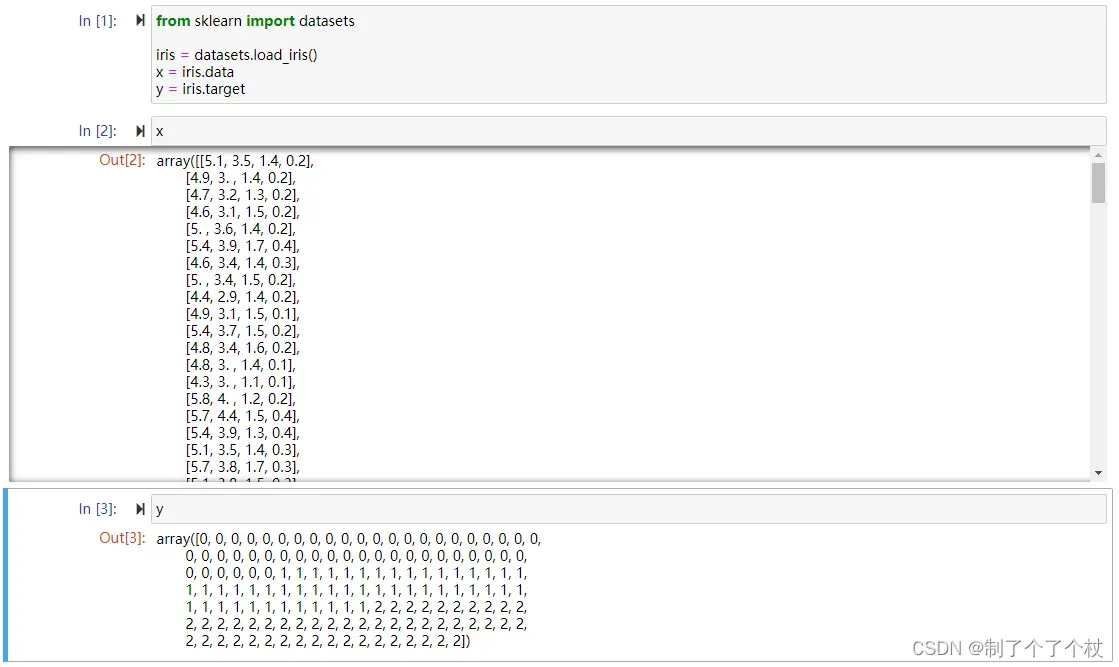
2. 数据预处理
由于iris数据集中没有明显的脏数据,这里可以跳过数据清洗过程
from sklearn.model_selection import train_test_split
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=0)
train_test_split()参数说明
- x 表示特征数据
- y 表示目标变量
- test_size 表示测试集的大小,如0.3表示30%的数据用于测试,在这个案例中,总样本150个,则其中有45个将用于测试
- random_state 表示随机参数种子,用于控制数据集的随机划分过程,保证每次划分的结果都一样
train_test_split函数的返回值包括:训练集的特征数据x_train、测试集的特征数据x_test、训练集的目标变量y_train、测试集的目标变量y_test
为了便于理解随机数种子,这里拓展一下
# 同一个随机数种子生成的随机数,都是从同一个数列中按顺序取出的
# 在不重置随机数种子前,每一次获取的随机数都是紧接数列中上一次获取的最后一个值,并往后取出指定数量的随机数
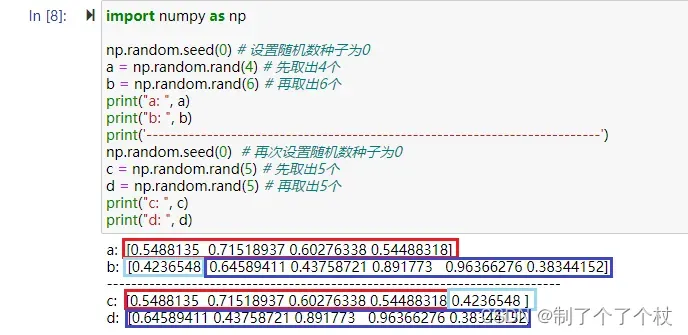
# 示例代码如下:随机数种子都为0时,2次取出的共计10个随机数,是同一组数
import numpy as np
np.random.seed(0) # 设置随机数种子为0
a = np.random.rand(4) # 先取出4个
b = np.random.rand(6) # 再取出6个
print("a: ", a)
print("b: ", b)
print(np.concatenate((a, b)))
print('---------------------------------------------------------------------------')
np.random.seed(0) # 再次设置随机数种子为0
c = np.random.rand(5) # 先取出5个
d = np.random.rand(5) # 再取出5个
print("c: ", c)
print("d: ", d)
print(np.concatenate((c, d)))
3. 构建模型
from sklearn.tree import DecisionTreeClassifier
# 构建模型
clf = DecisionTreeClassifier() # 决策树分类器实例化
clf.fit(x_train, y_train) # 训练数据,决策树分类器会根据训练数据的特征和目标变量来构建决策树模型,从而实现对新数据的分类

训练完成后,fit方法返回的是训练好的决策树分类器实例,也就是clf本身,因此输出的内容是“DecisionTreeClassifier()”
到这里,模型的初步训练就完成了,接下来进行测试以及分析模型的效果
4. 模型测试&效果评估
# 在测试集上进行预测
y_pred = clf.predict(x_test)
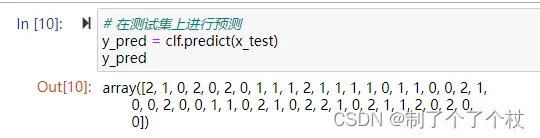
x_test是测试集的特征数据,y_pred是预测结果,我们可以利用准确率、精确率、召回率、F1值、混淆矩阵等指标来评估模型的效果
在使用指标之前,先熟悉以下几个变量的定义:
- TP:表示真正例(True Positive),即被分类器正确预测为正例的样本数;
- TN:表示真反例(True Negative),即被分类器正确预测为反例的样本数;
- FP:表示假正例(False Positive),即被分类器错误地预测为正例的样本数;
- FN:表示假反例(False Negative),即被分类器错误地预测为反例的样本数。
这几个变量会运用到下面指标的计算公式中
4.1 准确率、精确率、召回率、F1值、混淆矩阵
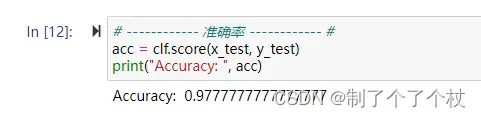
- 准确率(Accuracy) 表示正确分类的样本数占总样本数的比例,公式:
# ------------ 1. 准确率 ------------ #
acc = clf.score(x_test, y_test)
print("Accuracy: ", acc)
- 精确率(Precision) 表示被分类器预测为正类的样本中,真正为正类的样本所占的比例,公式:
- 召回率(Recall) 表示真正为正类的样本中,被分类器预测为正类的样本所占的比例,公式:
- F1值(F1-score) 表示综合考虑精确率和召回率,是精确率和召回率的调和平均数,公式:
# ------------ 精确率、召回率、F1值 ------------ #
from sklearn.metrics import classification_report
report = classification_report(y_test, y_pred)
print(report)
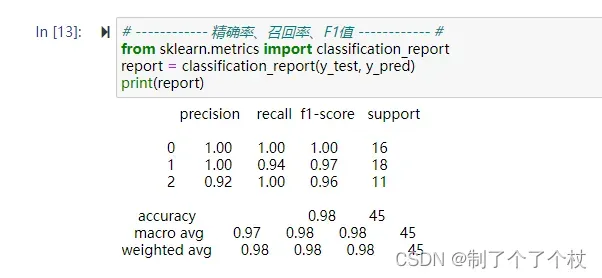
从report结果中可以看到:
- 在预测setosa类别 (target = 0) 的16个样本时,精确率、召回率、F1值均为1;
- 在预测versicolor类别 (target = 1) 的18个样本时,精确率为1、召回率为0.94、F1值为0.97;
- 在预测virginica类别 (target = 2) 的11个样本时,精确率为0.92、召回率为1、F1值为0.96;
- 综合3个类别的宏平均 (macro avg) 也即算术平均,得到整体精确率0.97、召回率0.98、F1值0.98;
- 综合3个类别的加权平均 (weighted avg) ,得到整体精确率、召回率、F1值均为0.98;
从当前已有的指标结果来看,已经能够说明当前分类器在测试集上的性能很好了,不过我们还可以继续往下看其他的指标
- 混淆矩阵(Confusion Matrix):用于描述分类器在不同类别上的分类情况,其中行表示真实标签,列表示预测标签
# ------------ 混淆矩阵 ------------ #
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print(cm)
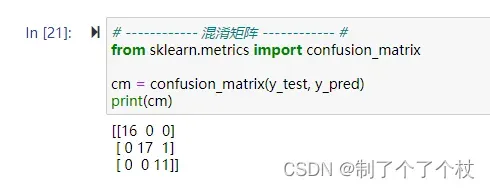
- 第一行表示真实标签为0的样本,共有16个。其中,预测标签也为0的样本有16个,预测正确。
- 第二行表示真实标签为1的样本,共有18个。其中,预测标签为1的样本有17个,预测正确;预测标签为2的样本有1个,预测错误。
- 第三行表示真实标签为2的样本,共有11个。其中,预测标签也为2的样本有11个,预测正确。
除以上指标外,还可以通过绘制学习曲线来观察模型的过拟合和欠拟合情况,以及绘制ROC曲线和计算AUC值来辅助判断模型性能
4.2 学习曲线
- 学习曲线(Learning Curve) 是一种用于评估机器学习算法性能的图表。学习曲线通常用于分析模型的训练误差和测试误差随着训练数据量的变化而变化的情况,以帮助我们判断模型是否存在过拟合或欠拟合等问题。
- 过拟合(Overfitting):模型在训练集上表现很好,但在测试集上表现较差,可能是因为模型过于复杂,过拟合了训练数据。
- 欠拟合(Underfitting):模型在训练集和测试集上表现都较差,可能是因为模型过于简单,欠拟合了训练数据。
# ------------ 学习曲线 ------------ #
from sklearn.model_selection import learning_curve
train_sizes, train_scores, test_scores = learning_curve( # learning_curve函数可以用于生成学习曲线,帮助评估模型在不同训练集大小下的性能
clf, # 训练好的分类器
iris.data, # 训练数据
iris.target, # 训练标签
cv = 5, # 交叉验证的折数,这里指将原始数据集划分为5个互不重叠的子集,其中一个子集作为验证集,其余的4个子集作为训练集
n_jobs = -1, # 指定使用的CPU数量,-1表示使用所有可用的CPU
train_sizes = np.linspace(0.1, 1.0, 10), # 指定训练集的大小,这里使用了10个不同的训练集大小,从10%到100%
scoring = 'accuracy' # 指定评估指标,这里使用了准确率
)
运行完这段代码后,会得到一个包含训练集大小、训练集准确率和交叉验证集准确率的元组 (train_sizes, train_scores, test_scores)
# 计算平均值和标准差
train_mean = np.mean(train_scores, axis=1) # 训练集准确率均值
train_std = np.std(train_scores, axis=1) # 训练集准确率标准差
test_mean = np.mean(test_scores, axis=1) # 测试集准确率均值
test_std = np.std(test_scores, axis=1) # 测试集准确率标准差
import matplotlib.pyplot as plt
# 绘制学习曲线图形
plt.plot(train_sizes, train_mean, label='Training score') # 绘制训练集准确率曲线
plt.plot(train_sizes, test_mean, label='Cross-validation score') # 绘制测试集准确率(交叉验证得分)曲线
# 绘制标准差区域
plt.fill_between(train_sizes, train_mean - train_std,
train_mean + train_std, alpha=0.1) # 绘制训练集准确率标准差区域
plt.fill_between(train_sizes, test_mean - test_std,
test_mean + test_std, alpha=0.1) # 绘制测试集准确率标准差区域
# 添加图例和标签
plt.legend() # 添加图例
plt.xlabel('Number of training samples') # 设置x轴标签
plt.ylabel('Accuracy') # 设置y轴标签
plt.show()
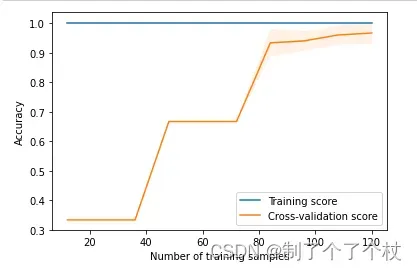
- 训练集得分一直都是1,同时看不到训练集的标准差区间,说明模型在训练集上表现很好,可以完美拟合训练数据;
- 测试集交叉验证得分随样本量增加而阶梯式提升,说明模型的泛化能力随着训练样本量的增加而提高;
- 测试集交叉验证得分的前半段曲线中看不到标准差,是因为在样本数量较少的情况下,测试集的表现可能会受到随机因素的影响,导致测试集的准确率波动较大,难以准确地计算标准差;随着样本数量的增加,模型的泛化能力逐渐提高,测试集的表现变得更加稳定,标准差区间逐渐增大;当样本数量达到一定程度时,模型的泛化能力已经达到一定的水平,此时标准差区间达到最大值;随着样本数量的进一步增加,模型的泛化能力继续提高,测试集的表现变得更加稳定,标准差区间逐渐缩小并保持稳定;
- 整体来说模型没有过拟合或欠拟合的情况,不过本次总体样本量不大,结论的说服力有限。
4.3 ROC曲线、AUC值
-
ROC曲线:ROC曲线是描述分类器性能的一种常用方法,它是以假正例率(False Positive Rate,FPR)为横轴,真正例率(True Positive Rate,TPR)为纵轴,绘制出的曲线。ROC曲线越靠近左上角,表示分类器的性能越好。
-
AUC值:AUC(Area Under Curve)是ROC曲线下的面积,它可以用来衡量分类器的性能,AUC值越大,表示分类器的性能越好。
# ------------ ROC曲线&AUC值 ------------ #
from sklearn.metrics import roc_curve, auc
# 预测测试集中每个样本的概率分布
y_score = clf.predict_proba(x_test)
# 计算每个类别的ROC曲线和AUC值
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(3):
fpr[i], tpr[i], _ = roc_curve(y_test, y_score[:, i], pos_label=i)
roc_auc[i] = auc(fpr[i], tpr[i])
# 绘制每个类别的ROC曲线
plt.figure()
plt.plot(fpr[0], tpr[0], label='ROC curve (area = %0.2f)' % roc_auc[0])
plt.plot(fpr[1], tpr[1], label='ROC curve (area = %0.2f)' % roc_auc[1])
plt.plot(fpr[2], tpr[2], label='ROC curve (area = %0.2f)' % roc_auc[2])
plt.plot([0, 1], [0, 1], 'k--') # 绘制对角线
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC curve')
plt.legend(loc = "lower right")
plt.show()
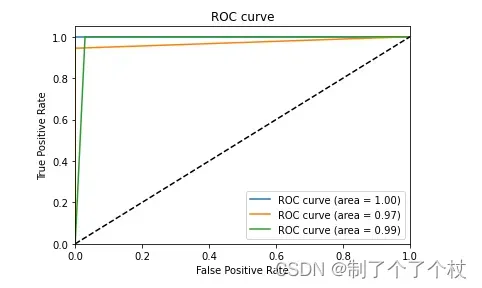
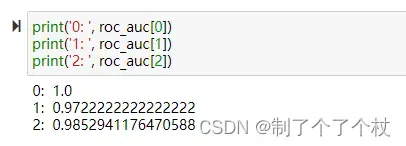
由于是多分类问题,这里是针对每个类别(0, 1, 2)分别绘制的一共3条ROC曲线,对应AUC值分别为:1、0.972、0.985;
这里也能看出来当前模型对0、1、2三个类别的分类性能都非常高了。
5. 总结
本文以iris数据集为例,利用Python的决策树分类算法对鸢尾花进行分类实战,主要环节是数据预处理、模型训练及效果评估。
- 预处理主要是对数据集进行拆分,得到训练数据和测试数据
- 模型训练是利用拆分得到的训练集来训练模型;
- 效果评估主要用到了准确率、精确率、召回率、F1值、混淆矩阵的指标,还用到了学习曲线进行过拟合、欠拟合评估,以及用到ROC曲线结合AUC值分析的方法。
为了便于新手入门,大部分过程都写得比较细,希望能够对读者在学习和应用机器学习算法时有所帮助,若有不对的地方也请评论指正~
6. 附录代码
由于文章是分步拆写,工具包都是在实际用到时才导入,这里写个汇总版
from sklearn import datasets
from sklearn.model_selection import train_test_split, learning_curve
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report, confusion_matrix, roc_curve, auc
import matplotlib.pyplot as plt
import numpy as np
# 读取数据集
iris = datasets.load_iris()
x = iris.data
y = iris.target
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=0)
# 构建模型
clf = DecisionTreeClassifier() # 决策树分类器实例化
clf.fit(x_train, y_train) # 训练数据,决策树分类器会根据训练数据的特征和目标变量来构建决策树模型,从而实现对新数据的分类
# 在测试集上进行预测
y_pred = clf.predict(x_test)
# 模型评估
# ------------ 准确率 ------------ #
acc = clf.score(x_test, y_test)
print("Accuracy: ", acc)
# ------------ 精确率、召回率、F1值 ------------ #
report = classification_report(y_test, y_pred)
print(report)
# ------------ 混淆矩阵 ------------ #
cm = confusion_matrix(y_test, y_pred)
print(cm)
train_sizes, train_scores, test_scores = learning_curve( # learning_curve函数可以用于生成学习曲线,帮助评估模型在不同训练集大小下的性能
clf, # 训练好的分类器
iris.data, # 训练数据
iris.target, # 训练标签
cv = 5, # 交叉验证的折数,这里指将原始数据集划分为5个互不重叠的子集,其中一个子集作为验证集,其余的4个子集作为训练集
n_jobs = -1, # 指定使用的CPU数量,-1表示使用所有可用的CPU
train_sizes = np.linspace(0.1, 1.0, 10), # 指定训练集的大小,这里使用了10个不同的训练集大小,从10%到100%
scoring = 'accuracy' # 指定评估指标,这里使用了准确率
)
# 运行完这段代码后,会得到一个包含训练集大小、训练集准确率和交叉验证集准确率的元组 (train_sizes, train_scores, test_scores)
# 计算平均值和标准差
train_mean = np.mean(train_scores, axis=1) # 训练集准确率均值
train_std = np.std(train_scores, axis=1) # 训练集准确率标准差
test_mean = np.mean(test_scores, axis=1) # 测试集准确率均值
test_std = np.std(test_scores, axis=1) # 测试集准确率标准差
# 绘制学习曲线图形
plt.plot(train_sizes, train_mean, label='Training score') # 绘制训练集准确率曲线
plt.plot(train_sizes, test_mean, label='Cross-validation score') # 绘制测试集集准确率曲线
# 绘制标准差区域
plt.fill_between(train_sizes, train_mean - train_std,
train_mean + train_std, alpha=0.1) # 绘制训练集准确率标准差区域
plt.fill_between(train_sizes, test_mean - test_std,
test_mean + test_std, alpha=0.1) # 绘制测试集准确率标准差区域
# 添加图例和标签
plt.legend() # 添加图例
plt.xlabel('Number of training samples') # 设置x轴标签
plt.ylabel('Accuracy') # 设置y轴标签
plt.show()
# 预测测试集中每个样本的概率分布
y_score = clf.predict_proba(x_test)
# 计算每个类别的ROC曲线和AUC值
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(3):
fpr[i], tpr[i], _ = roc_curve(y_test, y_score[:, i], pos_label=i)
roc_auc[i] = auc(fpr[i], tpr[i])
# 绘制每个类别的ROC曲线
plt.figure()
plt.plot(fpr[0], tpr[0], label='ROC curve (area = %0.2f)' % roc_auc[0])
plt.plot(fpr[1], tpr[1], label='ROC curve (area = %0.2f)' % roc_auc[1])
plt.plot(fpr[2], tpr[2], label='ROC curve (area = %0.2f)' % roc_auc[2])
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC curve')
plt.legend(loc="lower right")
plt.show()
文章出处登录后可见!