目录
1.数据来源
本次所分析的数据是通过爬虫抓取的微博数据。选取新浪微博为数据平台,选取我国34个省的旅游政务官方微博为研究对象,利用爬虫软件Gooseeker爬取微博信息,包括用户名、粉丝数、开博日期、当月原创微博总数No、当月总微博数N、单条博文的转发数、单条博文的评论数、条博文的点赞数。爬取的数据存在表格 test.xlsx 中。
#百度网盘提取链接:https://pan.baidu.com/s/1BmgteLqpv2u6uQFZTauAZw?pwd=7890
提取码:7890
2.对于All表:
(1)取出有用字段。
#-*- coding=utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from numpy.random import randn
from pandas import Series
from datetime import datetime
import xlrd,openpyxlAll=pd.read_excel("D:/test1.xlsx","All")
All.head()# 删掉表格中的无用列,保留有用列
d1 = All.drop(All.columns[:11], axis=1, inplace = False)
All = d1.drop(d1.columns[-1], axis=1, inplace = False)# 显示表格前五行
All.head()
# 查看去重未处理前表中记录长度
len(All)# 获取到重复的行的行号的前20个
All[All.duplicated()==True].index[:20]# 删除掉重复的行,在原值上直接修改
All.drop_duplicates(inplace=True)
len(All)#通过运行结果,可以发现确实删掉了,当前记录条数为6159条(2)处理缺失值。
#(2)处理缺失值
# 处理缺失值,先获取该列,将列中的"转发”、"评论"、"赞"替换掉
# 如果一开始就设置替换,会导致整张表中的"转发”、"评论"、"赞"均会被替换掉,造成信息损失
All[u'转发数'][All[u'转发数']==u'转发'] = '0'
All[u'评论数'][All[u'评论数']==u'评论'] = '0'
All[u'点赞数'][All[u'点赞数']==u'赞'] = '0' #等价于# All[u'点赞数'].replace(u'赞','0')
All.head()
(3)数据透视
#(3)数据透视
All.describe()#数据类型非数值型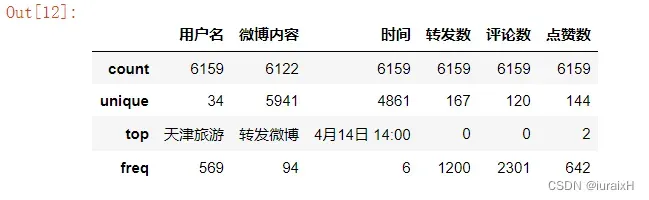
#查看表中各个列的数据类型
All.dtypes# 为了能进行数据透视,需要将对应列的数据类型转换成数值型
# 将DataFrame表中的某列数据进行转换类型
All[u'转发数']=All[u'转发数'].astype('int64')
All[u'评论数'] = All[u'评论数'].astype('int64')
All[u'点赞数'] = All[u'点赞数'].astype('int64')
All.describe()# 查看表中各个列的数据类型
All.dtypes#将预处理过的表保存到All.xlsx中
All.to_excel('All.xlsx',index=False)# 数据透视表
All_pivot= All.pivot_table(values=[u'转发数',u'评论数',u'点赞数',u'微博内容'],index=[u'用户名'],\
aggfunc={u'转发数':np.sum,u'评论数':np.sum,u'点赞数':np.sum,u'微博内容':np.size})
# 给该列换名称
All_pivot.rename(columns={u'微博内容':u'当月总微博数'},inplace=True)
All_pivot# 将完成的透视表保存
All_pivot.to_excel('All_pivot.xlsx')3.对于sf 和sfweibo 表:
(1)以省份名做数据连接成sf_sfweibo。
# step3
#(1)以省份名做数据连接成sf_sfweibo
# 读取test1.xlsx 中的sf表
sf=pd.read_excel("D:/test1.xlsx","sf")
sf.head()
#读取test1.xlsx中的sfweibo表
sfweibo = pd.read_excel("D:/test1.xlsx","sfweibo")
sfweibo.head()
#名称中肯定包含省份中的前两个字,为此,需要对两个表格切割后,进行连接
sf[u'省份前两字'] = np.nan
for i in range(len(sf[u'省份名'])):
sf[u'省份前两字'][i] = sf[u'省份名'][i][:2]
sfweibo[u'省份前两字'] = np.nan
for i in range(len(sfweibo[u'省份名'])):
sfweibo[u'省份前两字'][i] = sfweibo[u'省份名'][i][:2]# 显示表格的前五行
sf.head()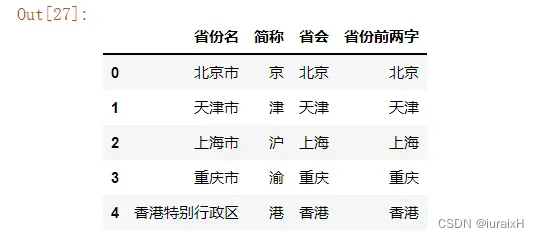
# 显示表格的前五行
sfweibo.head()
# 保存数据
sf.to_excel('sf.xlsx',index=False)
sfweibo.to_excel('sfweibo.xlsx',index=False)# 连接两表
sf_sfweibo = sf.merge(sfweibo,on=u'省份前两字')
sf_sfweibo.head()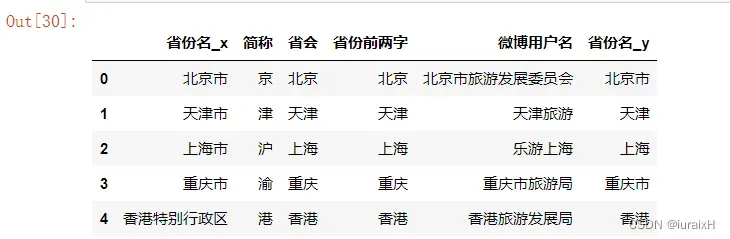
# 获取连接后表格中需要的字段名,并重新排列
sf_sfweibo1 = sf_sfweibo.iloc[:,[4,1,2]]
sf_sfweibo1.head()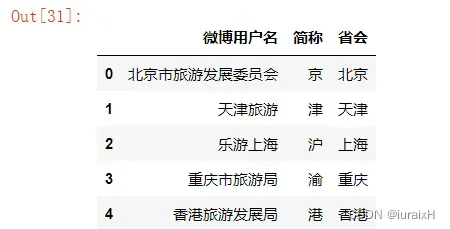
# 存储连接后的表
sf_sfweibo1.to_excel('sf_sfweibo.xlsx',index=False)(2)并与All表做数据连接sf_sfweibo_All。
#(2)并与All表做数据连接sf_sfweibo_All
#连接sf_sfweibo和All_pivot两表
sf_sfweibo = sf_sfweibo1
sf_sfweibo_All_pivot =pd.merge(sf_sfweibo,All_pivot,left_on=u'微博用户名',right_on=u'用户名',right_index=True)
#显示连接后的表格的前五行
sf_sfweibo_All_pivot.head()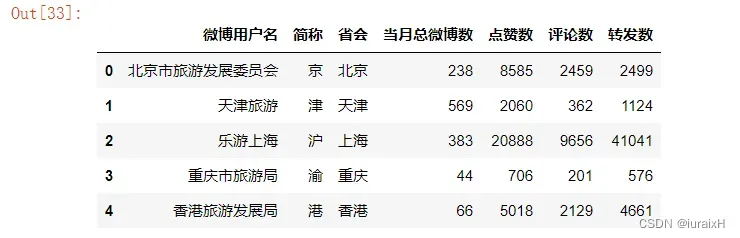
# 将连接后的表进行存储
sf_sfweibo_All_pivot.to_excel('sf_sfweibo_All_pivot.xlsx',index=False)4. 对于base_info表:
(1)与sf_sfweibo_All做数据连接
# step4:
#(1)与sf_sfweibo_All做数据连接
# 处理爬取的用户的基本信息表base_info
base = pd.read_excel("D:/test1.xlsx","base_info")
base.head() 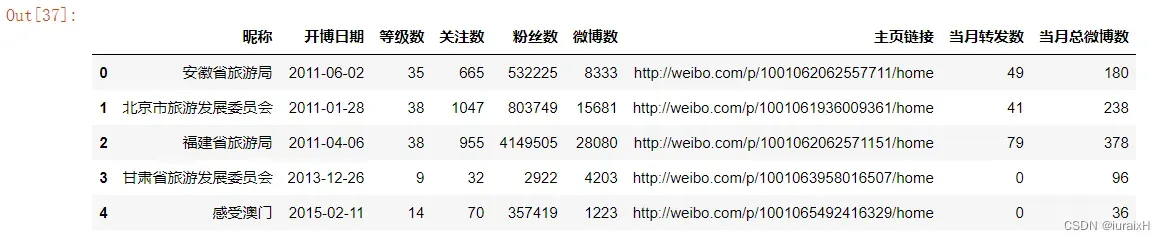
#将base表与sf_sfweibo_All_pivot进行连接
sf_sfweibo_All_pivot_base = base.merge(sf_sfweibo_All_pivot,left_on=u'昵称',right_on=u'微博用户名')
ssapb = sf_sfweibo_All_pivot_base # 名称太长,换个名称
ssapb.head()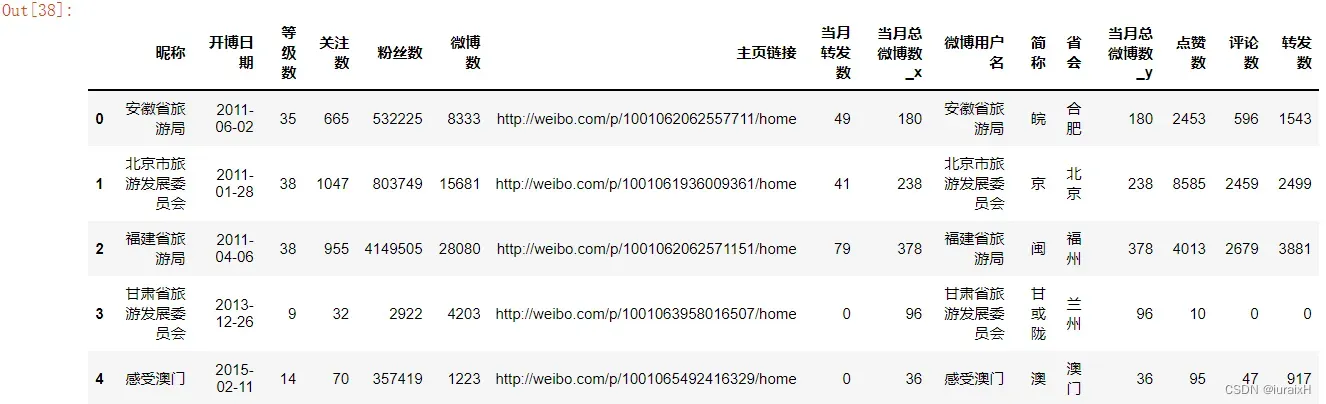
# 替换某列的名字
ssapb.rename(columns={u'当月总微博数_x':u'当月总微博数'},inplace=True)# 删除其中的多余列
ssapb = ssapb.drop([u'昵称',u'当月总微博数_y'],axis=1)# 读取第一行的数
ssapb.iloc[0]# 添加一列(当月原创数= 当月总微博数-当月转发数)
ssapb[u'当月原创数'] = ssapb[u'当月总微博数']-ssapb[u'当月转发数']#将某列同时与某段字符串连接,通过观察网页可以发现这是网址的特点
linkfix = "?is_ori=1&is_forward=1&is_text=1&is_pic=1&is_video=1&is_music=1&is_\
article=1&key_word=&start_time=2017-05-01&end_time=2017-05-31&is_search=1&is_searchadv=1#_0"
ssapb[u'当月博文网址'] = ssapb[u'主页链接']+linkfix
allfix = "?profile_ftype=1&is_all=1#_0"
ssapb[u'全部博文网址'] = ssapb[u'主页链接']+allfix#计算出篇均转发/点赞/评论,并添加列
ssapb[u'篇均点赞'] = ssapb[u'点赞数']/ssapb[u'当月总微博数']
ssapb[u'篇均转发'] = ssapb[u'转发数']/ssapb[u'当月总微博数']
ssapb[u'篇均评论'] = ssapb[u'评论数']/ssapb[u'当月总微博数']# 读取表中的第一行数据
ssapb.iloc[0]# 存储表格
ssapb.to_excel('ssapb.xlsx',index=False)(2)计算h值
# (2)计算h值
# 将All表分组,获取表格的index值
gb = All.groupby(u'用户名')
gb1 = gb.size()
gbindex = gb1.index
print(gbindex,gb1)#根据h指数的定义,分别计算转发/评论/点赞h指数
# 再记录下每个“用户名的最大互动度max(转发+评论+点赞)”
sortAllf = All.sort_values(by=[u'用户名',u'转发数'],ascending=[True,False])
sortAllc = All.sort_values(by=[u'用户名',u'评论数'],ascending=[True,False])
sortAlll = All.sort_values(by=[u'用户名',u'点赞数'],ascending=[True,False])
mm = (sortAllf,sortAllc,sortAlll)# 将计算得到的结果重新存储到一个新的DataFrame中
All_h =pd.DataFrame(np.arange(136).reshape(34,4),
columns=['fh','ch','lh','max_hdd'],
index=gbindex)
fh=[]
ch=[]
lh=[]
max_hdd = []
for j in range(len(mm)):
for i in gbindex:
tempdf =mm[j][mm[j][u'用户名']==i]
tempdf['hdd'] = tempdf[u'转发数']+tempdf[u'评论数']+tempdf[u'点赞数']
max_hdd.append(tempdf['hdd'].max())
tempdf['numf'] = range(len(tempdf))
if j==0:
a =len(tempdf[tempdf[u'转发数']>=tempdf['numf']+1])
fh.append(a)
elif j==1:
b =len(tempdf[tempdf[u'评论数']>=tempdf['numf']+1])
ch.append(b)
else:
c = len(tempdf[tempdf[u'点赞数']>=tempdf['numf']+1])
lh.append(c)
All_h['fh']=fh
All_h['ch']=ch
All_h['lh']=lh #因为,前面的循环一共循环了三遍,使得All_h重复了3遍,因此只要获取前34位即可
All_h['max_hdd']=max_hdd[:34]# 插入一个综合h指数,该指数是转发/评论/点赞h指数三个的均值
All_h.insert(3,'HS',All_h.iloc[:,:3].mean(1))#更改列名称
All_h.rename(columns={'fh':u'转发h指数','ch':u'评论h指数',
'lh':u'点赞h指数','HS':u'综合h指数','max_hdd':u'单篇最大互动度'},inplace=True)
All_h.head()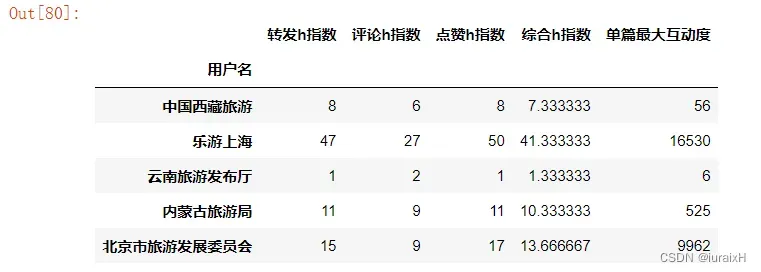
#连接ssapb和All_h表格
ssapb_All_h= pd.merge(ssapb, All_h, left_on=u'微博用户名',right_on=u'用户名',right_index=True)#加一列原创率
ssapb_All_h[u'原创率'] = ssapb_All_h[u'当月原创数']/ssapb_All_h[u'当月总微博数']
ssapb_All_h.iloc[0]# 存档
ssapb_All_h.to_excel('ssapb_All_h.xlsx',index=False)(3)处理数据
# 重新排序列
aa =ssapb_All_h.iloc[:,[8,9,10,5,15,16,0,1,2,3,4,6,14,7,11,12,13,24,20,21,22,23,17,18,19,25]]
aa.to_excel('finally.xlsx')
aa.iloc[0]# 将原创率转成百分比形式
f1 = lambda x :'%.2f%%' % (x*100)
aa[[u'原创率']]= aa[[u'原创率']].applymap(f1)
aa.to_excel('finally1.xlsx',index=False)
aa.iloc[0](4)计算相关性
#(4)计算相关性
# 获取原DataFrame中的几列存储到新的DataFrame中,计算综合h指数与其他分指数之间的相关性
f1 = ssapb_All_h.loc[:,[u'综合h指数',u'转发h指数',u'评论h指数',u'点赞h指数']]
# 计算f1中各列数据的相关性
corr1 = f1.corr()
# 将该相关性结果存档
corr1.to_excel('corr1.xlsx')
corr1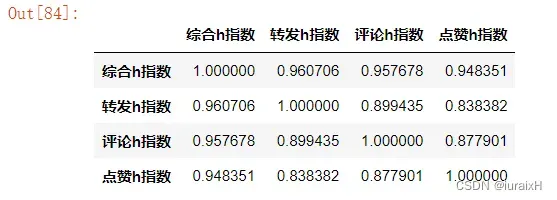
# 获取原DataFrame中的几列存储到新的DataFrame中,计算综合h指数与其他微博信息之间的相关性
f2 = ssapb_All_h.loc[:,[u'综合h指数',u'转发数',u'评论数',u'点赞数',u'篇均转发',u'篇均评论',u'篇均点赞']]
corr2 = f2.corr()
corr2.to_excel('corr2.xlsx')
corr2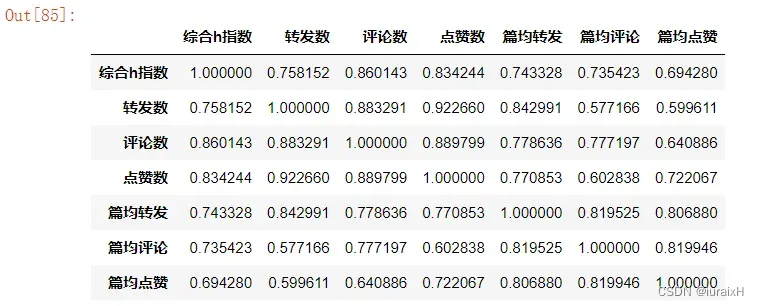
5.导出最后结果到一个Excel文件中,完成数据处理。
文章出处登录后可见!
已经登录?立即刷新