爬虫时遇到很多数据并不在访问网址的返回包里,而是随着用户下拉逐步加载的,也就是用到了Ajax,那么这时我们该如何爬取我们想要的数据呢?这里用爬取b站评论区相关数据为例,练习一下python爬虫异步爬取数据的相关流程,完整程序实例在最后面:
准备工作
用到的包:
import requests
import time
爬虫相关主要还是requests包,练习用脚本本身也并不复杂。
根据写一个爬虫脚本的一般流程,第一步显然是找到含有我们需要信息的相关网页链接,这里我们的目标是b站的评论区。随便点开一个视频。
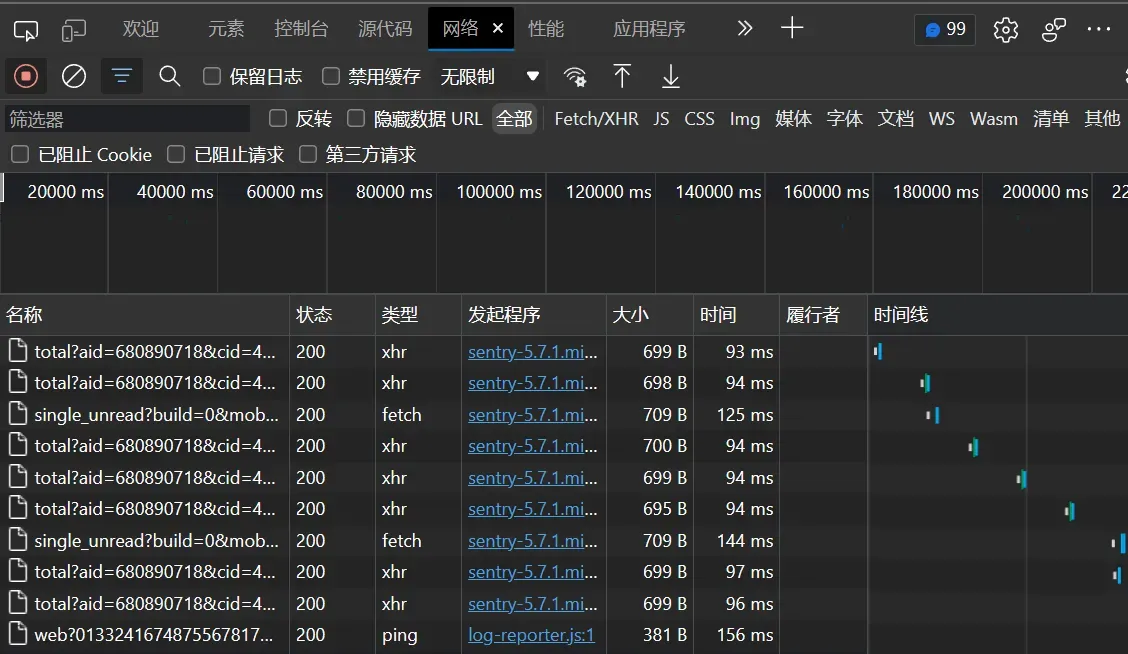
评论区下拉的过程中会发现下面列表多出来很多条目,这些就是网页向服务器请求的资源。找一找评论相关的那条,如下,对应的响应内容就是我们需要的信息,其中对应的这个链接也是我们待会写爬虫时要用到的链接:
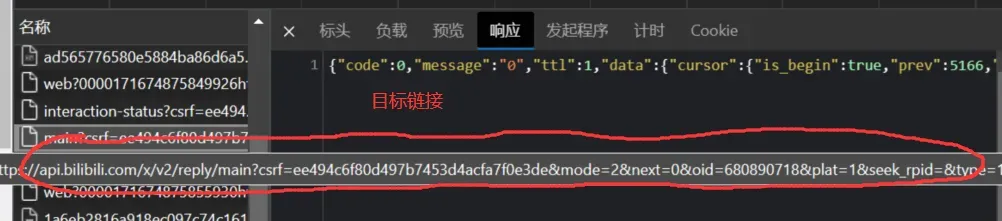
这个响应是JSON格式的,JSON是一种数据格式。我们可以把它alt+a全选之后放到JSON解析器里,这样就能清晰的看到它的结构,类似的解析器百度就可以搜到:
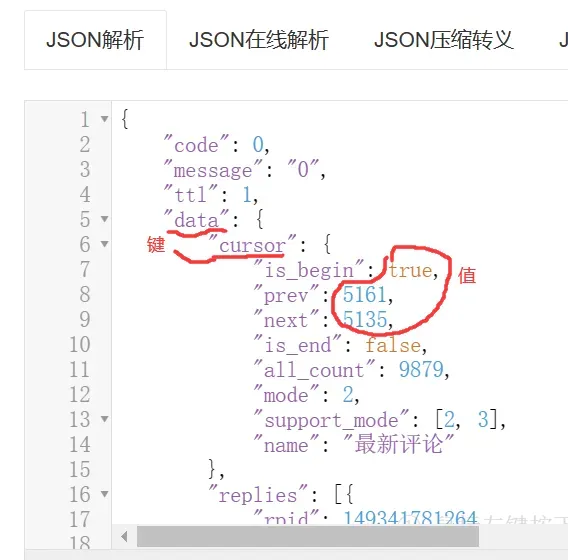
可以看到信息主要都是由一个个键值对组成,前面双引号里的是它的标签,后面是这个条目具体的值,也就是评论内容,用户名等等信息都在这里。可以看到评论内容等信息,说明这就是我们要找的:

定位到需要的数据之后就可以正式开始写爬虫脚本了:
爬虫连接资源
第一步当然是连接目标地址,这里的url用的就是上面网络里请求资源的那个链接,记得加上请求头:
url = f'https://api.bilibili.com/x/v2/reply/main?csrf=ee494c6f80d497b7453d4acfa7f0e3de&mode=2&next=0&oid=680890718&plat=1&seek_rpid=&type=1'#资源对应链接
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0',
}#请求头
response = requests.get(url=url, headers=headers)#连接
response.encoding = 'utf-8'#设置编码方式
printf(response.json)#试试看抓不抓得到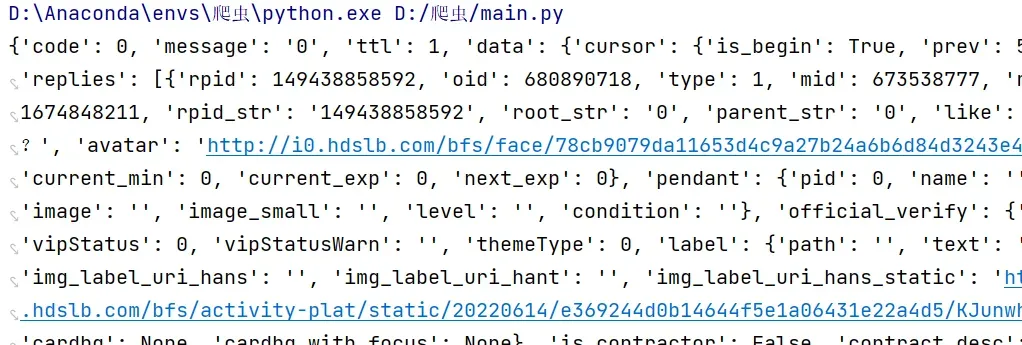
可以看到抓到了对应的数据,接下来就对抓到的数据进行处理,找到我们想要的相关信息:
数据处理
先准备一个空的list来存放想要的数据:
result = []然后在那一堆JSON数据中找到我们想要的数据对应的键值,例如我需要评论区用户的昵称。按照如下顺序找到对应标签:

于是通过以下语句就可以将抓到的信息保存到result中:
for j in response.json()['data']['replies']:
result.append(j['member']['uname'])
print(result)
类似的比如评论内容就是data->replies->content->message
for j in response.json()['data']['replies']:
result.append(j['content']['message'])
print(result)
还可以把多个元素接到一起,就像这样,接在一起的元素可以通过split分割成多维数组,方便后面保存。:
for j in response.json()['data']['replies']:
result.append(j['member']['uname']+','+str(j['member']['level_info']['current_level']))
result = [i.split(',') for i in result]爬取异步数据
通过上面方式得到的数据实际上只是一次请求的数据,在我们往下拉的时候不断有新评论传过来,下面来实现异步抓取评论信息。
观察链接:
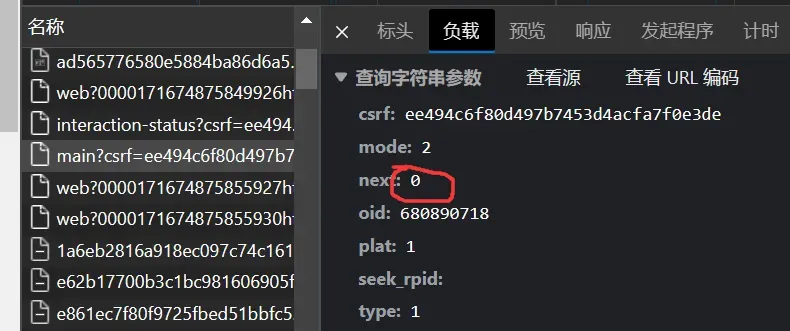
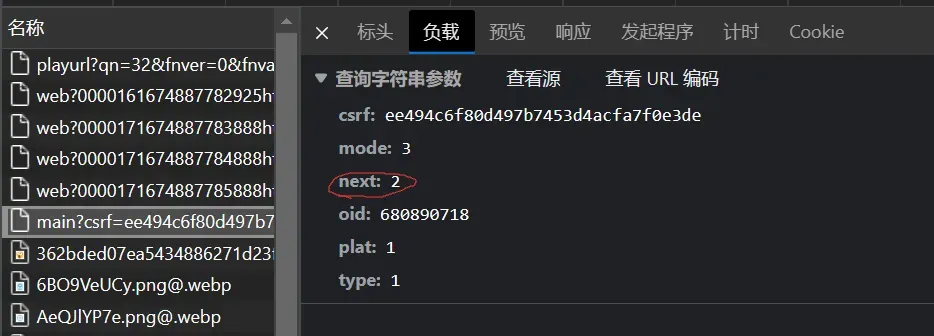
发现在异步请求数据的过程中next的值改变了,也就是说我们只要改变链接中next的值哦,就可以爬取到后续的信息,于是改变url如下,注意多次请求时中间停一会,不要对网站造成影响,最后爬下来数据可能会有重复,可以用set方法去重后再做后续处理::
for i in range(0,10):
time.sleep(1)
url = f'https://api.bilibili.com/x/v2/reply/main?csrf=ee494c6f80d497b7453d4acfa7f0e3de&mode=2&next={i}&oid=680890718&plat=1&seek_rpid=&type=1'
......
result = list(set(result))保存数据(.csv格式)
爬到之后自然要存起来,这里以爬取b站 id+等级两个元素为例介绍怎么把得到的结果存到.csv文件里,首先需要把爬到的用逗号分隔的两个元素组成的裂变变成二维列表,然后用withopen写入.csv文件中。
for j in response.json()['data']['replies']:
result.append(j['member']['uname']+','+str(j['member']['level_info']['current_level']))
result = list(set(result))
result = [i.split(',') for i in result]
with open('bili.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
# 写入数据
writer.writerows(result)
print("Writing complete")这样操作之后就会在当前根目录文件夹生成一个.csv文件:
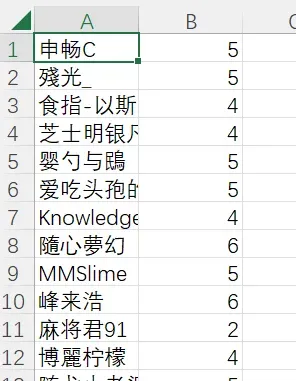
里面存着数据:
示例代码
代码示例如下:
import requests
import time
import csv
result = []
for i in range(0,10):
time.sleep(1)
url = f'https://api.bilibili.com/x/v2/reply/main?csrf=ee494c6f80d497b7453d4acfa7f0e3de&mode=2&next={i}&oid=680890718&plat=1&seek_rpid=&type=1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0',
}
response = requests.get(url=url, headers=headers)
response.encoding = 'utf-8'
# print(response.json())
for j in response.json()['data']['replies']:
result.append(j['member']['uname']+','+str(j['member']['level_info']['current_level']))
result = list(set(result))
result = [i.split(',') for i in result]
# print(result)
with open('bili.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
# 写入数据
writer.writerows(result)
print("Writing complete")注意进行爬虫相关操作时遵守法律法规,不要爬取隐私信息,代码仅供参考。
文章出处登录后可见!