目录
Part 1 前言
Python 教程系列前两期文章中,我们向大家介绍了数据分析库 Pandas 中的数据类型以及读写表格文件的方法,大家阅读后应该对 Pandas 有了一个初步的了解。在数据处理中,导入数据-分析处理数据-导出结果数据是一个十分常见的处理流程,上一期文章已经向大家详细介绍了 Pandas 如何导入导出数据,那么接下来的技术文章我们将会把重点指向如何分析处理数据。作为 Python 语言中当下最受欢迎的数据处理框架,Pandas 功能强大、完备,函数如云,所以我们打算根据数据处理不同的需求,使用多期文章来详细介绍 Pandas 的主要功能,本期要介绍的是 Pandas 的数据选取(也称数据切片)功能。
什么是数据选取?简而言之,就是根据表格的行列顺序或行列索引获取表中某位置或某区域的数据值。如果是在 Excel 软件中完成简单的数据选取,只需要动动鼠标即可,可使用 Pandas 做数据选取却需要先学会使用两个晦涩难懂的函数。非是弃易求难,虽然在编程语言中人与数据的直接交互比不上 office 软件,可 Pandas 数据选取的具体功能和代替人力处理大数据这方面,也不是 Excel 能够替代的,所以数据选取绝对是学习 Python 数据处理的必要一步。
本教程基于 pandas 1.5.3 版本书写
本文中所有 Python 代码均在集成开发环境 Visual Studio Code (VScode) 中使用交互式开发环境 Jupyter Notebook 中编写,本文分享的代码请使用 VScode 打开。
Part 2 表格数据的索引
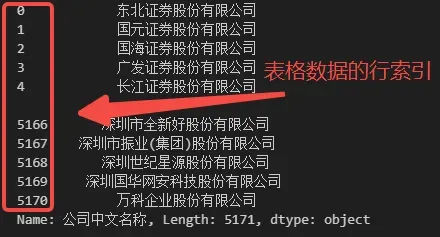
日常使用表格数据时,经常需要查看表格中的某处数据,这种时候不可避免地需要根据表格的字段名和行序号进行定位,例如在 Excel / WPS 这类办公软件中显示表格数据时,软件左侧和上方自带行编号和列编号,我们可以根据行编号和列编号(或字段名)来定位数据,如下图所示。
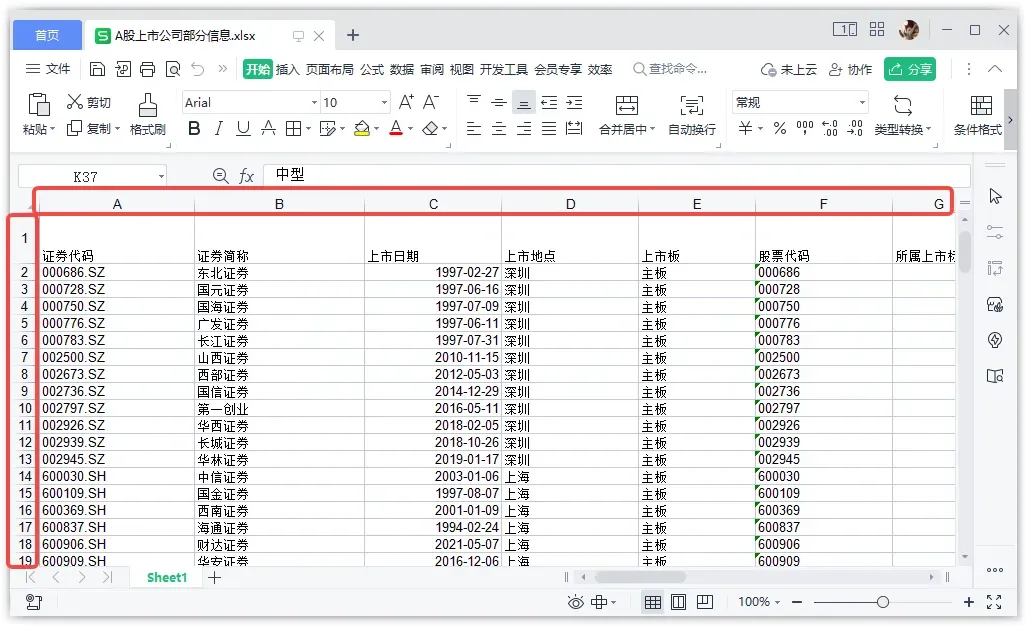
在 Python 中, Pandas 是一个专门用来处理表格数据的 Python 第三方库,在 Pandas 中,表示表格数据的数据类型是 DataFrame。为了能够像 Excel 一样方便地定位数据,DataFrame也具备行编号和列编号属性,下面我们读取一个表格数据以作演示。
#导入 pandas 库
import pandas as pd
# 读取演示用的数据
DATA = pd.read_excel('./A股上市公司部分信息.xlsx')
# 处理字段名,并做简化处理,这一步不必在意
DATA.columns = [COL.split('\n')[0] for COL in list(DATA.columns)]
# 展示数据
DATA
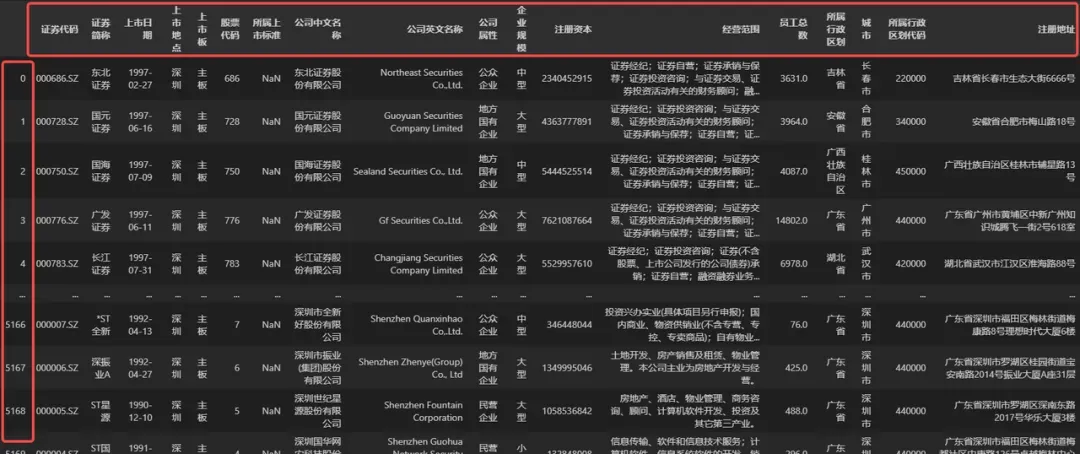
如上图所示,Pandas 中表格数据类型 DataFrame 同样具有行编号和列编号属性,DataFrame 类型行列编号和 Excel 表的行列编号看起来有几分类似,实际他们之间存在不小的差异,笔者将它们之间的主要差异罗列在下方。
-
在 Excel 表格中,表格不一定有字段名,所以才一定会有上方的列编号(A、B、C……);而在 Pandas 中,表格类型必须具有字段名,并使用字段名作为列编号(列索引或字段名:column),如果读取一份数据时发现表格没有字段名,Pandas 默认会将首行内容作为字段名,当然这可能不合理,不过我们可以在读取数据时设置参数
header=None,表示表格没有字段名,这时 Pandas 会将表格的字段名设置为自然数(从左向右依次为 0,1,2……) -
Excel 表中的行编号实际上是表格中行的序号,从上往下,从 1 开始,最多到 1048576,因为 Excel 表的数据存储上限为 1048576 (2 的 20 次方)行。且行编号是固定的,不会随着数据行的删除、隐藏而变化。而在 Pandas 中,数据行编号被称为
行索引(index),读取数据时,Pandas 会自动为表格数据赋予行索引(如上图所示),行索引默认从 0 开始,向下递增。行索引就是一行数据的编号,随着数据行的删除、添加,行索引也会跟着变化,例如索引为 1 的这一行数据被删除后,数据行索引就变为 0,2,3……所以 Pandas 中的行索引不是连续且不变的,这是为了让数据的定位更加稳定,不受数据量变化的影响。 -
Excel 表的行列编号是固定不变的,行索引是从 1 到 1048576 的正整数,列编号是由 26 个大写英文字母组成的编号。Pandas 中的表格(DataFrame)的行索引默认是递增的自然数,但可以根据编程者的需要自行定义索引值,且行索引也可以是字符串类型。在数据处理的任何阶段,使用者都可以改变某(几)行数据的索引,也可以在任何时候重置数据行索引,让其变为默认的连续自然数。
-
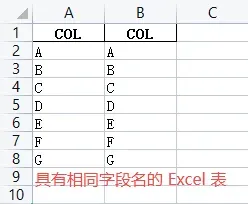
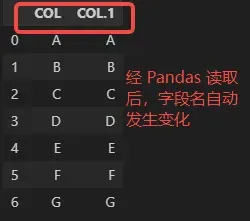
Excel 其实没有严格的字段名概念,只是大家习惯把字段名写在第一行,所以在 Excel 中,字段名的值是随意的,可以重复的。而在 Pandas 中,虽然也支持相同的字段名或行索引,但它不建议这么做,在读取表格数据、匹配表格数据时,如果发现至少两个字段的名称一样,Pandas 会自动做出区分,如下图所示。
以上就是 Excel 软件中行列编号与 Pandas 中表格数据类型 DataFrame 的行索引、字段名的主要差异。相信此刻大家对 DataFrame 的索引有了一个比较全面的认识,下面我们将以默认的数据索引为例,向大家演示 Pandas 是如何进行数据选取的。
Part 3 Pandas 数据选取
本节演示用的数据表为 A 股上市公司的部分信息(截至2023年5月12日),读取数据的代码和数据预览请查看上一节【表格数据的索引】。
1、选取数据字段
许多时候表格的字段太多,我们筛选出自己需要的即可。在 Pandas 中,我们可以根据字段名来选取需要的数据字段,示例代码如下(代码中的DATA是上一节读取数据得到的变量)。
## 如果只需要选出一个字段,可以使用这样的代码:<变量名>[<字段名>],示例如下
DATA['公司中文名称'] # 此时选取的结果是一个 Series,这里不再放图展示
## 如果需要选取若干个字段,且所得结果仍是表格
## 可以使用:<变量名>[<字段名列表>],示例如下
DATA[['公司中文名称', '公司英文名称']]
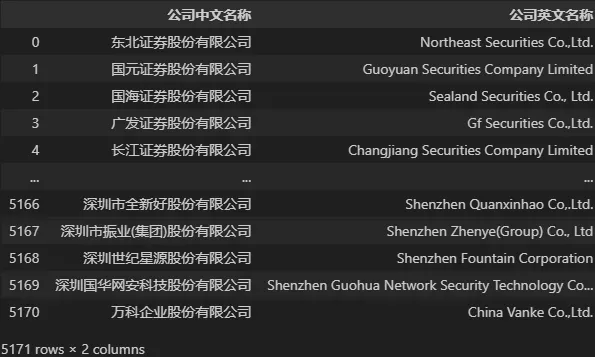
2、选取数据行
Pandas 中有一种简单选取数据行的功能,可以选取某一连续范围的数据行,例如可以选取第 m 行(包含 m)到第 n 行(不包含 n)之间的所有数据。不过这里的序号 m、n 不是数据的行索引值,而是数据行的数字序号,这个行数字序号和 Excel 中的行序号几乎一样,唯一的区别是 Excel 中行序号是从 1 开始算起的,而 Pandas 中的行序号是从 0 开始算起的(如上图所示)。示例代码如下。
## 选取数据 DATA 中的第 10 到 第 15 行数据(这里所说的行序号是从 1 开始计算的)
# 由于 DataaFrame 的行序号从 0 开始,且是左闭右开区间,所以正确的代码如下
DATA[9:15] # 注意行序号
3、选取单个数据值
在上文【字段选取】一小节中,我们使用了选取一个字段的代码DATA['公司中文名称'],笔者在注释中有提到,使用这样的代码选取的数据字段为一维 Series 类型,在上上一期介绍 Pandas 数据类型的文章中>>>Python 教学 | 数据处理必备工具之 Pandas(基础篇),我们已经介绍过 Series 类型,这是一种具有索引的一维数据类型,如果是从 DataFrame 中得到的 Series,那么得到的 Series 还具有与 DataFrame 一样的索引值,例如:
DATA['公司中文名称']
所以选取单个数据值的常用方法就是先选取一列数据,再使用行索引取出目标值即可,例如需要取出表中公司中文名称字段中行索引值为 2 的数据值,就可以使用下面的代码。
DATA['公司中文名称'][2]
# 得到:'国海证券股份有限公司' 可以参考上图
对于初学 Pandas 的同学来说,这是一种定位具体某一数据值最常用的方式,经常在批量处理数据的循环代码中使用。
4、选取任意数据
上文几个小节中,我们介绍了 Pandas 中选取行、列、值的几种方法,但是这些还无法满足更加多样的数据需求。在 Pandas 中,存在两个函数 loc 与 iloc,使用他们能够根据表格的行列索引或行列序号获取任意区域或满足某种条件的数据,下面我们来详细介绍这两个函数的用法。
(1)根据索引选取:loc 函数
Pandas 中表格数据类型 DataFrame 中存在一个loc函数,函数用法如下:
DataFrame.loc[row_label, column_label]
loc函数中共有两个参数 row_label 和 column_label ,分别对应着所选取区域的行索引和字段名。众所周知,表格数据是二维数据,我们通过表格数据的行列编号就可以找到对应的数据,loc 函数正是通过这个原理来选取数据的,即loc函数是根据数据的索引值来选取数据的。为了使用方便,loc函数内置的参数形式有很多种,下面我们根据参数的形式来介绍loc函数的用法。
① 参数为单个索引值
使用loc函数时可以将参数设置为单个行索引和列索引(列索引即字段名称),可以用这种方式来获取表中某个位置的具体值,示例代码如下。
## 目的:选取‘证券简称’字段中,行索引为 3 的数据值
DATA.loc[3, '证券简称'] # 注意行索引在前,字段名在后,中间用逗号隔开
# 得到:'广发证券'
上述代码DATA.loc[3, '证券简称']的含义就是获取数据DATA 中'证券简称'这一字段行索引为 3 的值。对应到表中便是:’广发证券’。
② 参数为索引列表
如果想要获取指定几行几列数据,我们还可以将索引参数设置为包含索引值的列表,示例代码如下。
## 选取‘公司中文名称’、‘员工总数’ 这两个字段,行索引是 1、3、4、7 的数据
DATA.loc[[1,3,4,7], ['公司中文名称', '员工总数']]

选中的数据仍是二维数据,所以选取的结果仍是一个 DataFrame。
③ 参数为索引范围
当需要选取某一个数值范围的数据时,例如需要选取行索引值从 100 到 200 (含200)的数据时,我们可以直接使用类似于字符串切片的范围参数100:200来充当loc函数的参数(字符串切片的用法请移步此文:Python教学 | Python 中的循环结构(上))。同样地,字段名称(列索引)也可以使用范围参数,示例代码如下。
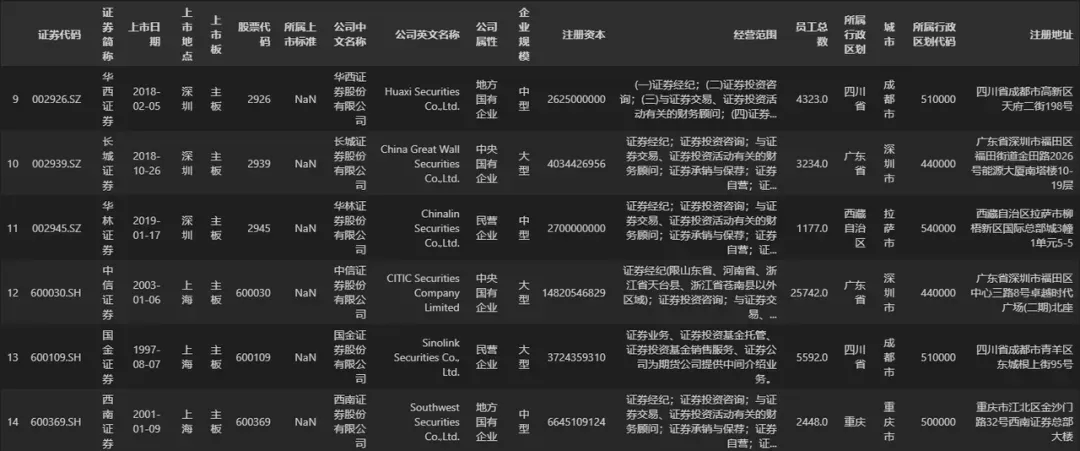
## 选取从‘证券代码’字段到‘公司属性’字段,行索引值从 100 到 200 的所有数据
DATA.loc[100:200, '证券代码':'公司属性']
使用切片范围作为loc函数时,有以下几点需要注意。
-
使用行索引切片时,需要保证数据的行索引是连续的,且切片范围是合理的,右侧索引值须大于等于左侧索引值;
-
同样的,字段名切片是按字段顺序选取的,也需保证顺序的逻辑性;
-
在 Python 中,一般的切片都是左闭右开区间,即包含切片左侧的值,不包含切片右侧的值。但
loc函数是个例外,其内的切片参数是一个左闭右闭区间,同时包含切片两侧的索引值,例如上例中,切片100:200的选取结果实际上包含了行索引是 200 的数据行,所以选取结果的数据量才是 101 行。 -
参数为索引范围切片时,切片两侧的值可以省略,省略左侧代表从最小的行索引值(或最左侧的字段名)开始计算,省略右侧代表到最大的行索引值(或最右侧的字段名)结束,切片两侧的值虽然可以省略,但是切片中间的冒号(:)必须保留。
下面是loc函数使用范围切片作为参数时的另一个示例代码。
## 选取行索引从 0 到 5 ;字段名从‘公司中文名称’一直到最后的数据
DATA.loc[:5, '公司中文名称':] # 这里省略了切片中的部分值

④ 参数为简单条件
除了可以像以上几种情况那样直接根据索引值来选取数据之外,loc函数还可以间接地根据索引值来获取指定的数据,这里的“间接”指的是什么呢?在 Pandas 中,使用条件表达式也可以生成数据索引值,根据条件间接获取索引值的示例代码如下。
## 获取 DATA 中‘员工总数’不少于 10000 的所有数据的行索引
DATA['员工总数'] >= 10000
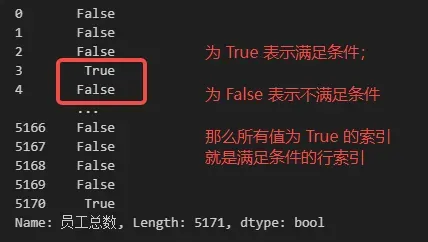
所以我们就可以根据上述条件完成相应的数据筛选。对应的选取代码如下。
## 选取数据 DATA 中员工总数不少于 10000 的所有字段数据
DATA.loc[DATA['员工总数'] >= 10000, :] # 这里的行索引参数用的是简单条件,列索引用了范围切片,
# 并省略了切片前后的值,表示所有列

上述代码中行索引参数用的是简单条件,列索引用了范围切片,实际上列索引参数也可以使用判断条件,但是在我们日常使用数据的习惯中,大多是根据数据行进行筛选数据的,根据字段名筛选字段的场景少之又少。下面笔者只介绍一个根据字段名条件表达式来筛选数据的示例。
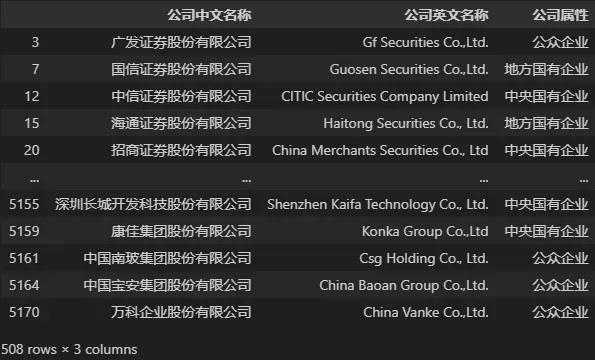
## 选取数据 DATA 中员工总数不少于 10000 , 且字段名中包含‘公司’二字的所有数据
DATA.loc[DATA['员工总数'] >= 10000, DATA.columns.str.contains('公司')]
最后,有一点需要明确说明,在介绍loc函数的参数类型时,上文中笔者都会把行索引参数和列索引参数设置为相同的类型,这是为了方便大家学习行列索引参数的使用。实际上,loc函数是一个非常灵活的数据选取函数,其中行索引值参数和列索引值参数(即字段名参数)是相互独立的,也就是说它们的类型是随意的,没必要保持类型一致,可以随意搭配,且除了以上介绍的四种常用参数类型,还可以有其他的参数类型,其中的无穷用法需要大家自行学习探索。
(2)根据顺序选取:iloc 函数
与loc函数功能和用法十分相似的另一个数据选取函数是iloc函数,用法如下。
DataFrame.iloc[row_label, column_label]
从函数形式可以看出,iloc函数与loc函数的用法可能并无二致,事实上从用法方面来说确实如此,不过由于两个函数选取数据的依据不同,导致两者在参数类型上略有不同。上文中介绍的loc函数是根据数据的行列索引选取数据的,而下面要介绍的iloc函数则是根据数据的行列索引来选取数据的。这与我们口头上第几行第几列的说法十分相似,不同点是 Pandas 中的行列顺序都是从 0 开始,而不是从 1 开始算起的,所以使用时还需注意行列顺序值。下面我们根据不同的参数类型来介绍iloc函数。
①参数为单个序号值
在iloc函数中,行顺序值,列顺序值都是自然数,且与数据的行索引值没有任何关系。
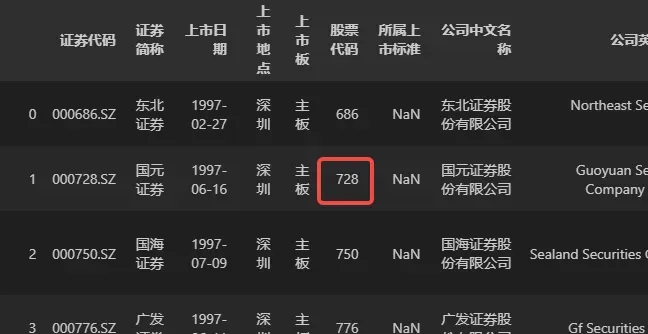
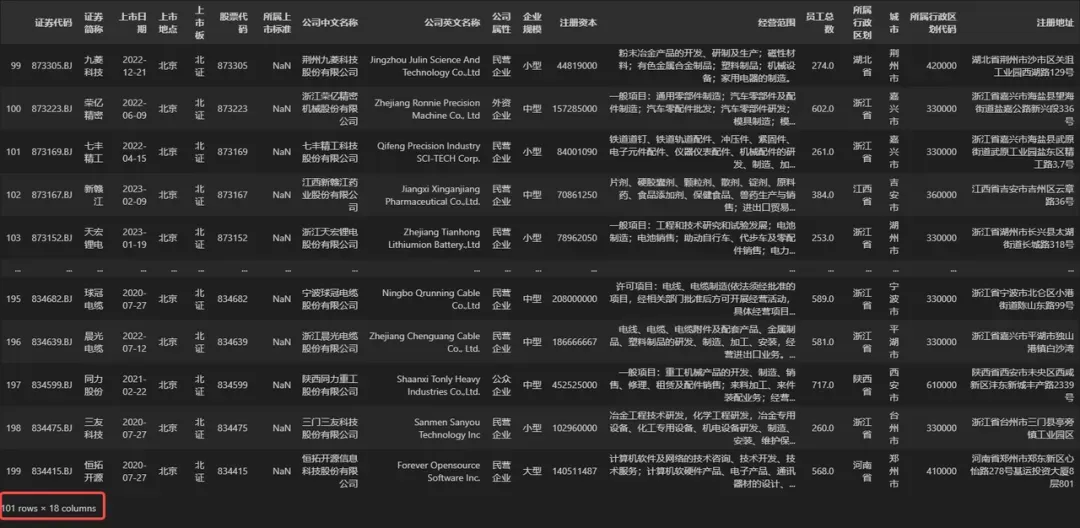
## 选取第 2 行,第 6 列数据
DATA.iloc[1, 5]
# 得到:728
运行以上代码后,输出的值为 728,正是数据DATA中第 2 行,第 6 行的值,该数据所在位置如下图所示。
需要注意的是,由于 Pandas 的行列序号都是从 0 开始算起的,所以代码中的序号值要比描述的顺序小 1。
② 参数为序号列表
同loc函数一样,iloc函数的参数形式可以是列表。在loc函数中,列表中的值是行列索引的值,而在iloc函数中,列表中的值得是行列的序号值才行。示例代码如下。
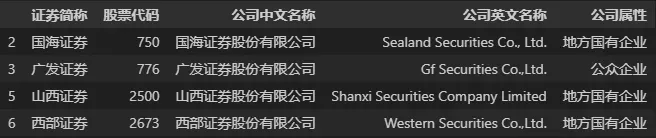
## 选取第 3,4,6,7 行,第 2,6,8,9,10 列的数据
DATA.iloc[[2,3,5,6], [1,5,7,8,9]]
③ 参数为序号范围
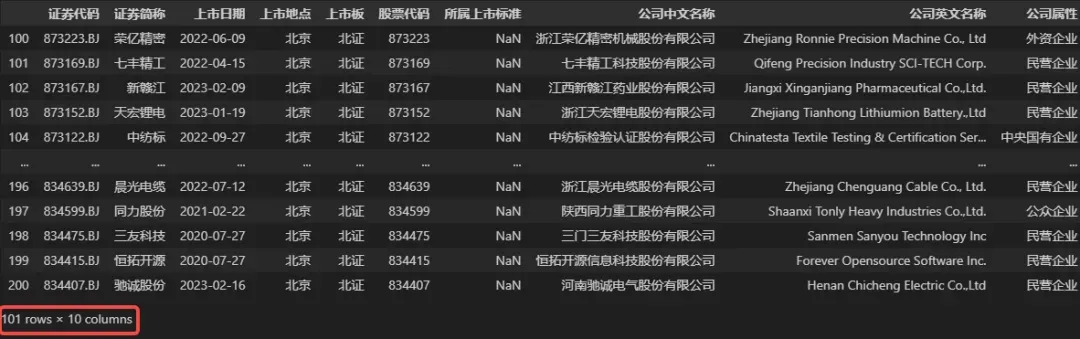
iloc函数也支持传入范围切片作为数据选取的序号值,例如当需要选取第 100 到 200(含200)行数据时,可以设置行序号切片为 99:200,示例代码如下。
## 选取第 100 到 200(含200)行,全部列数据
DATA.iloc[99:200, :]
细心的同学应该已经发现了此处和loc函数不一样的地方,根据行序号的规则,第 100 到 200(含200)行的表示方法不应该是 99:199 才对吗,为什么代码中是99:200呢?这就要说到两个函数在切片规则上的不同之处了。
-
loc函数中的索引值切片对应的是一个左闭右闭的区间,而iloc函数中的序号切片则是一个左闭右开的区间,因此区间右侧的值需要多出 1 才行。 -
使用
iloc函数选取数据时,对数据的行列索引值没有任何要求,即数据的索引可以不连续。
Part 4 数据选取有何用武之地?
我们已经在上文中洋洋洒洒把数据选取的两个函数扒得一干二净,那么这两个函数在数据处理中究竟有什么作用,扮演什么角色呢?下面我们来做一个简单说明。
1、查看数据或生成新数据
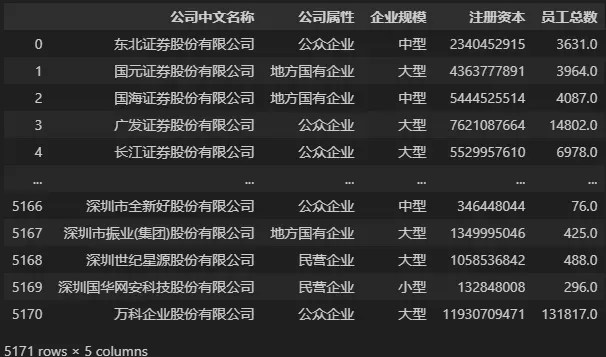
正如介绍数据选取函数时演示的那样,数据选取可以方便我们查看选取的数据,或者当需要对数据进行裁剪操作时,也可使用数据选取函数来生成新的数据对象。例如当我们只需要表格中的某几列数据时,可以将数据选取的结果赋值给新变量,然后再对新变量进行处理分析,示例代码如下。
# 选取数据的公司中文名称、公司属性、企业规模、注册资本、员工总数 这几个字段,生成新数据
DATA_NEW = DATA[['公司中文名称', '公司属性', '企业规模', '注册资本', '员工总数']]
# 或:DATA_NEW = DATA.loc[:, ['公司中文名称', '公司属性', '企业规模', '注册资本', '员工总数']]
DATA_NEW
2、修改数据值
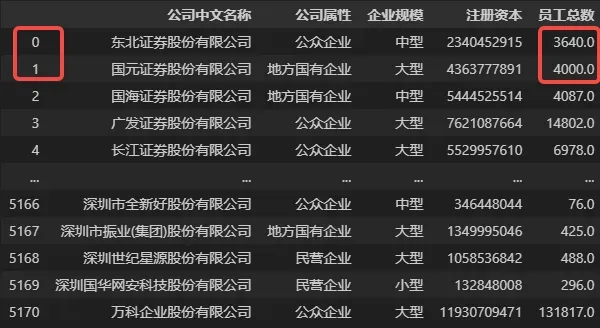
在处理 Excel 表格时,如果需要修改某几处数据值,那么打开 Excel 表格文件,手动修改就可以了。但如果是在 Pandas 中,由于读取后的表格数据位于内存中,我们无法手动修改内存中表格数据的值,这时就需要使用数据选取函数来修改表中的数据值,示例代码如下。
## 假设需要手工更新数据,将前两行的员工总数分别修改为 3640 和 4000
# 方法1
DATA_NEW['员工总数'][0] = 3640
DATA_NEW['员工总数'][1] = 4000
# 方法2
DATA_NEW.loc[0, '员工总数'] = 3640
DATA_NEW.loc[1, '员工总数'] = 4000
# 方法3
DATA_NEW.loc[[0,1], '员工总数'] = (3640, 4000)
# 以上方法使用任意一种即可
修改后发现对应位置数据已经被替换为我们需要的值,如下图所示。
当然这只是手动修改少数几处数据值的方法,在 Pandas 中,真正需要修改数据值的场景大多在处理“大数据”的需求中,而在这些场景中,相当一部分需要借助数据选取的方式来修改数据,所以说本文介绍的内容是 Python 处理大数据的一项重要知识。
Part 5 总结
Padans 中的数据选取非常灵活,尤其是数据选取函数 loc 和 iloc,许多初学者短时间内不能完全搞清楚他们之间的相同和差异,所以笔者在介绍之时,就明确了他们之间的差异。不得不承认的是,两个数据选取函数的参数形式、用法确实存在不易区分的差异,所以想要熟练掌握这两个函数,最好的方法就是多练习,多探索。最后助各位读者朋友们学习顺利,万事大吉。
下期文章我们将学习 Pandas 中的数据筛选,在 Pandas 中,除了能够像 Excel 那样进行基本的数据筛选,还可以借助正则表达式完成一些妙不可言的数据筛选操作,敬请期待下期!
Part 6 Python教程
-
学习 Python 第一步——环境安装与配置
-
Python 基本数据类型
-
Python 字符串操作(上)
-
Python 字符串操作(下)
-
Python 变量与基本运算
-
组合数据类型-列表
-
组合数据类型-集合(内含实例)
-
组合数据类型 – 字典&元组
-
Python 中的分支结构(判断语句)
-
Python 中的循环结构(上)
-
Python 中的循环结构(下)
-
Python教学 | Python函数的定义与调用
-
Python教学 | Python 内置函数
-
Python教学 | 最常用的标准库之一 —— os
-
Python 教学 | “小白”友好型正则表达式教学(一)
-
Python 教学 | “小白”友好型正则表达式教学(二)
-
Python 教学 | “小白”友好型正则表达式教学(三)
-
Python 教学 | 数据处理必备工具之 Pandas(基础篇)
-
Python 教学 | 数据处理必备工具之 Pandas(数据的读取与导出)
-
本期
文章出处登录后可见!