前言
DeepFaceLab是一种基于深度学习的人脸合成和转换工具。它使用了深度神经网络来分析和修改图像中的人脸部分,可以实现将一个人的脸部特征应用到另一个人的照片上,或者进行面部表情、年龄、性别等特征的变换。
DeepFaceLab具备一系列核心功能,包括人脸检测、关键点定位、面部表情识别和特征提取。这些功能为其提供了生成高质量合成人脸的能力,并支持多种输入和输出格式。用户可以根据自身需求对其可配置的参数进行调整,以定制模型的训练和处理流程。此外,DeepFaceLab还充分支持GPU加速,从而显著提升处理速度。
然而,需要特别留意的是,DeepFaceLab等工具也存在被滥用的风险,用以制作虚假的图片和视频。因此,在使用这类工具时,必须严格遵守法律法规,同时秉持高度的道德准则。这类技术的滥用可能会引发伦理和法律问题,因此用户在使用时应谨慎考虑,深入了解相关法律规定,并严守道德操守。
一、DeepFaceLab安装
可以从官方网站得软件下载地址,找到对应自己GPU的版本就可以了,GPU不是RTX30头的选RTX2080Ti版本,RTX30xx以上选RTX3000这个版本。
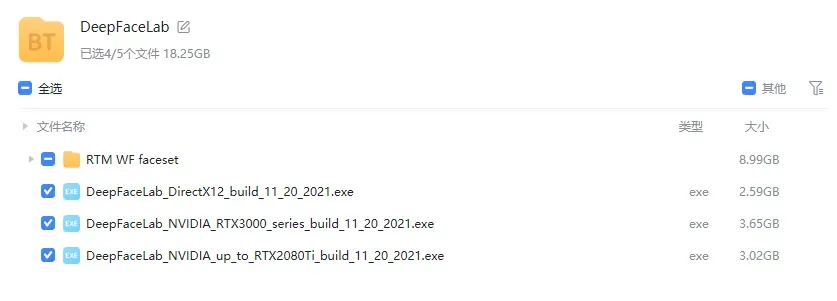
下载之后直接解压到使用目录就可以了,解压完成之后像下面这样,不过有几个中文是我后加的。
二、数据准备
1.源视频
源视频就是用来训练模型的视频,源视频选择合适的素材是关键。要确保素材清晰、高质量,以获得最佳效果。可以使用高分辨率的相机来拍摄或选择高质量的库存视频。
- 不同角度:拍摄素材时,考虑使用不同的角度,如近景、远景、正脸和侧脸,以提供多样性和视觉吸引力。
- 不同视角:例如低视角或仰视角。
- 不同光线:根据需要选择适当的时间和光线条件,以便拍摄白天和黑夜的素材。
- 不同表情:使用面部表情、姿势和背景来传达喜怒哀乐,选择不同的情感表达。
- 时长:源视频的时长越长越好,最短也要几分钟以上。
2.目标视频
目标视频就是最终要进行换脸的视频,⽬标视频处理⽐较简单些,正常的视角就可以了,但为了换脸丝滑,源视频和目标视频尽可能选择脸型、表情、⾓度、光源接近的。
3.数据重命名
把源视频和目标视频放到项目workspace下,源视频重新命名成data_src,目标视频重新命名成data_dst,如下图结果:

三、模型训练
1.源视频拆分
运行 2) extract images from video data_src.bat文件,对源视频进行拆帧:
一秒保存多少帧:
Enter FPS 一秒保存多少帧,一般保存10到15帧
保存图像的格式:
Output image format
图像格式选择:
PNG:PNG格式提供无损图像质量,适合保持图像的清晰度和细节,但文件大小较大。如果您需要高质量的图像,可以选择PNG格式
JPG:JPG格式文件大小较小,适合处理不需要极高图像质量的任务。如果对图像质量要求不高,可以选择JPG格式,以便减小文件大小。

2.目标视频切图
对目标视频进行拆分,运行 3) extract images from video data_dst FULL FPS.bat,选择跟源视频一样。拆分完成之后在工作目录就多了两个拆分成图像的目录。
3.源视频切脸
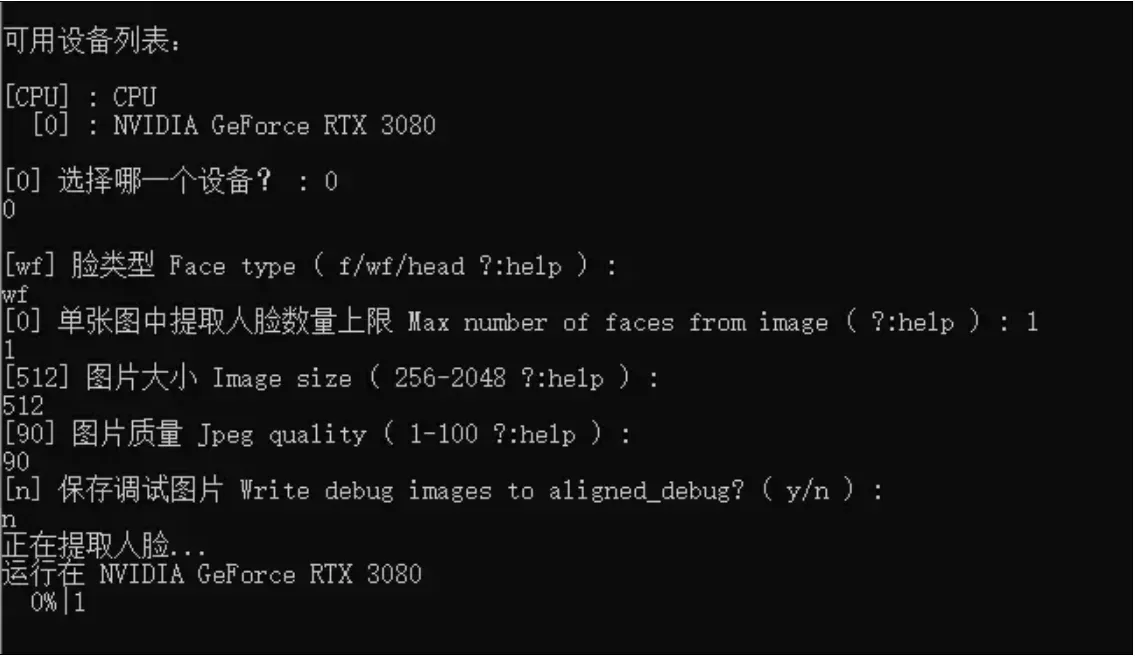
点击运⾏ 4) data_src faceset extract.bat 会有参数需要设置,如图:
-
选择脸型:
有三个选项可供选择:全脸(f)、整脸(wf)和头(head)。根据您的需求,一般情况下选择默认的wf即可,因为它覆盖的面积更大,包括额头和胡子。如果只需要替换脸部到眉毛上方一点点的区域,您可以选择f。 -
设置最多识别的人数:
如果视频大部分时间只有一个人,选择1;如果视频中有两个人同时出现,而且都需要处理,选择2。 -
设置图像大小:
一般情况下,选择256足够了。较高的分辨率会提高图像质量,但也会增加计算资源的消耗。如果原始视频质量不高,即使选择512也不会有很大帮助。 -
图像质量:
默认的图像质量设置为90,通常足够了。根据需要,您可以微调这个设置。 -
调试图像:
如果出现错误或不满意的结果,可以随时删除不符合要求的图像。
6.运行脚本:
完成设置后,运行脚本。根据您的硬件,3080显卡切脸速度大概为2张/秒。
5.源视频人脸整理
运行 4.2)data_src sort.bat 脚本以对源图像进行排序。需要对源图像进行排序、筛选和处理,以获得高质量的训练素材。
-
源头像排序:
选择 “5-颜色直方图排序” 以帮助识别相似的图像。 -
筛选图像:
- 删除模糊的图像,这些通常不适合用于训练。
- 删除因旋转而变形的图像,因为它们通常是由于识别失败导致的。
- 删除残缺的图像,如部分遮挡或损坏的图像。
- 删除有遮挡或黑边裁切的图像。
- 删除刘海太大或与人物无关的图像。
- 删除光照差异较大的图像,因为这些图像可能对训练产生不良影响。
- 如果某些图像是常见的遮挡物,但资源稀缺,可以保留它们用于遮罩训练。
-
手动修复识别不准确的图像:
- 如果某些图像非常宝贵,并且识别不准确,您可以手动删除 “debug” 目录中相应的错误图像,并运行 “data_src faceset extract MANUAL.bat” 脚本再次提取素材。
-
可选的模糊程度排序:
- 可以运行排序脚本,将图像按照模糊程度进行排序。然后,您可以删除模糊度过高的图像。不过,有些人认为适度模糊的图像也可以用于训练,这取决于您的需求。
-
处理多个人脸:
- 如果 “aligned” 目录中包含多个人脸,建议使用颜色直方图排序,然后将不同的人脸归类到不同的文件夹中以备用。或者,删除不需要进行人脸替换的人脸。您还可以使用人脸筛选工具来帮助进行分类和处理。
这些步骤有助于准备高质量的训练素材,提高DeepFaceLab的换脸效果。请根据您的具体需求和素材情况进行适当的筛选和整理。
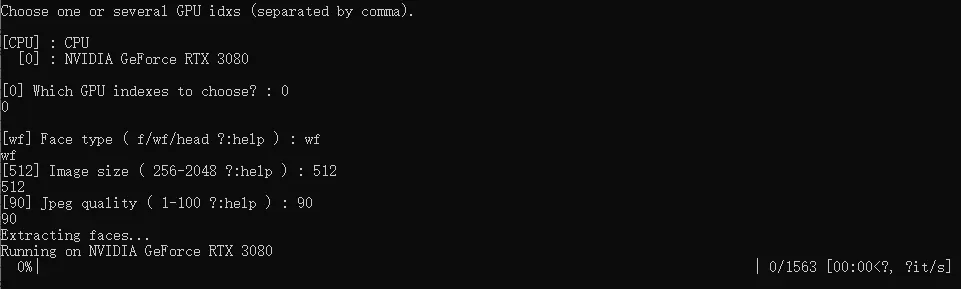
6.目标视频切脸
运⾏ 5) data_dst faceset extract.bat 对目标视频进行切脸,参数与源视频切脸差不多。
7.目标视频图像整理
执行 5.2) data_dst sort 脚本对目标视频头像进行整理
-
推荐使用颜色直方图排序:
- 在提取素材时,建议选择 “5-颜色直方图排序” 以帮助识别相似的图像。这有助于归类不同的人脸到不同的文件夹,或删除您不想进行人脸替换的图像,特别是模糊或无法清晰辨认的图像。
-
处理难以识别的图像:
- 如果源图像包含极端仰脸、侧脸或其他难以识别的情况,可以考虑删除这些图像。您还可以复制一份到 “src” 的 “aligned” 目录,用于个人训练或尝试补充极端角度的素材。
-
处理有遮挡的图像:
- 对于有遮挡的图像,不要立即删除它们,因为它们可能需要用于人脸替换。这些图像可以用于训练模型以处理遮挡情况。
-
修复脸部轮廓识别错误的图像:
- 如果某些图像的脸部轮廓识别错误,您可以手动进行修复。首先,在 “Debug” 目录中删除相应的图像,然后运行 “data_dst extract faces MANUAL RE-EXTRACT DELETED RESULTS DEBUG.bat” 脚本。此脚本会提示进行区域调整,以修复脸部识别错误的问题。
-
注意关于”aligned”目录的重要性:
- 请记住,“aligned” 目录下的所有人脸最终都将用于替换 “src” 目录中的人脸。如果您保留了多个人脸,可能会导致生成多胞胎效果。
三、模型训练
1. 快速训练
初学者或配置有限,可以使用轻量级训练脚本 “train Quick96.bat”。这个脚本通常不需要进行复杂的参数设置。以这个脚本通常使用默认的训练参数,适合初学者或那些希望快速进行训练的人。
如果希望进行更高级的训练,需要进行更多的参数设置和调整。对于初学者,使用 “train Quick96.bat” 是一个不错的起点,可以帮助快速了解DeepFaceLab的工作流程,但在更高级的项目中可能需要更多的自定义设置和调整。
但train Quick96.bat训练出来的模型不能导出模型应用到Deepfacelive直播换脸上。
2. SAEHD和AMP
这两种训练方式需要设置的参数很多,训练过程很缓慢,但效果是最好的。
3.迁移学习
但通常的做法是,找一个效果不错的预训练模型进行训练,以减少训练的时间与更快更好的获取训练效果,但预训练模型的缺点是不能更改分辨率。
-
预训练模型:
- 初始阶段,建议使用预训练模型,以减少训练时间并提高效果。
-
batch_size:
- batch_size 参数控制每个训练批次的图像数量。可以根据硬件性能和需求来调整它,例如从默认值4更改为16。
-
模型架构选择:
- 可以选择不同的模型架构,如DF(DeepFace)五官结构、LIAE(Light Image Augmentation Enhancement)等。每个架构有其特点,可以根据需要选择适合的。
-
输入的宽度:
- 可以配置不同层的宽度,例如设置中间瓶颈层为256、编码解码层为64。遮罩层的宽度通常是解码层宽度的三分之一。
-
Eyes and mouth priority:
- 如果有闭眼或张嘴的素材,可以启用 “Eyes and mouth priority” 以提高生成的准确性。
-
学习率丢弃:
- 在训练停滞时,可以开启 “Use learning rate dropout” 以帮助模型再次学习。
-
Enable random warp of samples:
- 在训练的早期阶段,可以启用 “Enable random warp of samples” 以增加训练的难度,后期可以关闭。
-
GAN设置:
- 可以调整配置参数,如 “GAN power” 和 “GAN dimensions” 来控制生成器对抗网络的性能。
-
颜色处理:
- 使用 “color transfer” 来改善光影变化不足。您还可以考虑收集更多具有不同光影下的SRC素材。
-
梯度裁剪:
- 必须开启 “Enable gradient clipping” 以防止梯度爆炸问题。
-
Loss参数:
- 调整 “src/dst loss” 参数以控制损失的权重。预览图中的蓝色和黄色分别代表SRC和DST。
-
Masked training:
- “masked_training” 设置为 True 意味着只学习蒙板内的区域。
这些设置将影响训练的结果和速度,可以根据您的具体需求进行调整。
当设置完成之后,下面开始跑出时间,就代表已在训练了:
在训练过程中,会显示训练的结果,按P键可以看到下一迭代的效果。
文章出处登录后可见!