授权声明: 本文基于九天Hector的原创课程资料创作,已获得其正式授权。
原课程出处:九天Hector的B站主页,感谢九天Hector为学习者带来的宝贵知识。
请尊重原创,转载或引用时,请标明来源。
全文共5000余字,预计阅读时间约30~50分钟 | 满满干货(附代码),建议收藏!
本文目标:基于之前的AI应用开发流程,尝试在Few-Shot提示下实现外部功能函数的自动生成,大幅提升敏捷开发的效率

代码下载点这里
一、介绍
写本文的目的,是想总结和反思一下之前在OpenAI开发系列(四)至(十四)的内容,并且进一步优化基于大模型的敏捷开发流程。
对于企业而言,大语言模型如何在实际应用中产生价值是至关重要的。OpenAI通过引入Function Calling功能,赋予了开发者利用大模型来构建应用程序和插件的能力。这个新范式对于开发者来说,就像是一个高度优化的机器学习流程,具有显著的通用性和灵活性,但是需要思考的是,不仅是编程任务,这种新范式还适用于整个开发流程。其关键优势在于大模型的强大的通用计算能力和涌现性,这使得其在应用开发中成本效益极高。因此,一个高效的实践方式应该是通过高度自动化和智能提示,让这些大模型尽可能多地参与到应用开发的各个环节。这是完全可行的,因为大模型具备实现这一目标的能力。
1.1 基于大模型开发的初级阶段
在初级阶段,借助大模型进行应用开发的流程我认为是这样的:
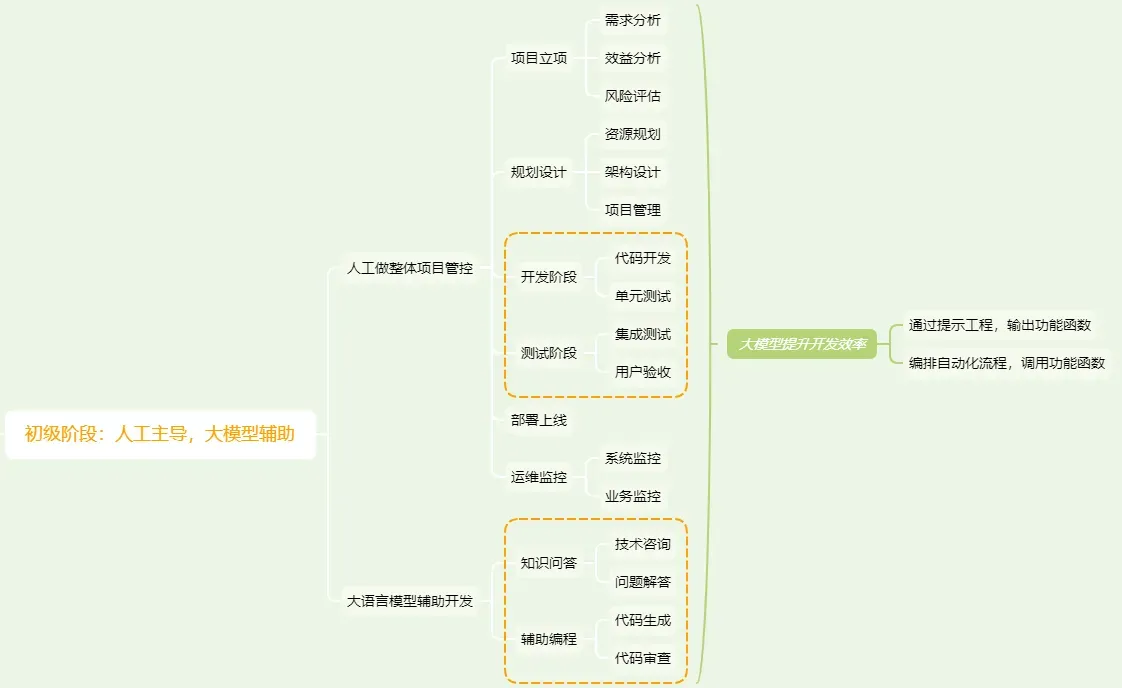
就目前而言,大多数人已经进入了一个初级阶段,即借助大模型来辅助应用开发。这个阶段可以类比为“查百度”的过程:遇到不懂的问题就直接询问大模型。在这个阶段上,开发人员只需要掌握大模型的基本调用方式。对于不熟悉编程的人来说,甚至可以直接使用Web端的ChatGPT来获取实时的建议和解答。
如果熟悉编程,可以通过代码直接调用大模型的API,就像在OpenAI的开发系列中这三篇文章所提到的内容:
OpenAI开发系列(四):掌握OpenAI API调用方法
OpenAI开发系列(五):实现Jupyter本地环境下的OpenAI API调用
OpenAI开发系列(六):Completions模型的工作原理及应用实例(开发多轮对话机器人)
以一个基于大模型的AI聊天机器人为例,其整个业务流程大致如下:
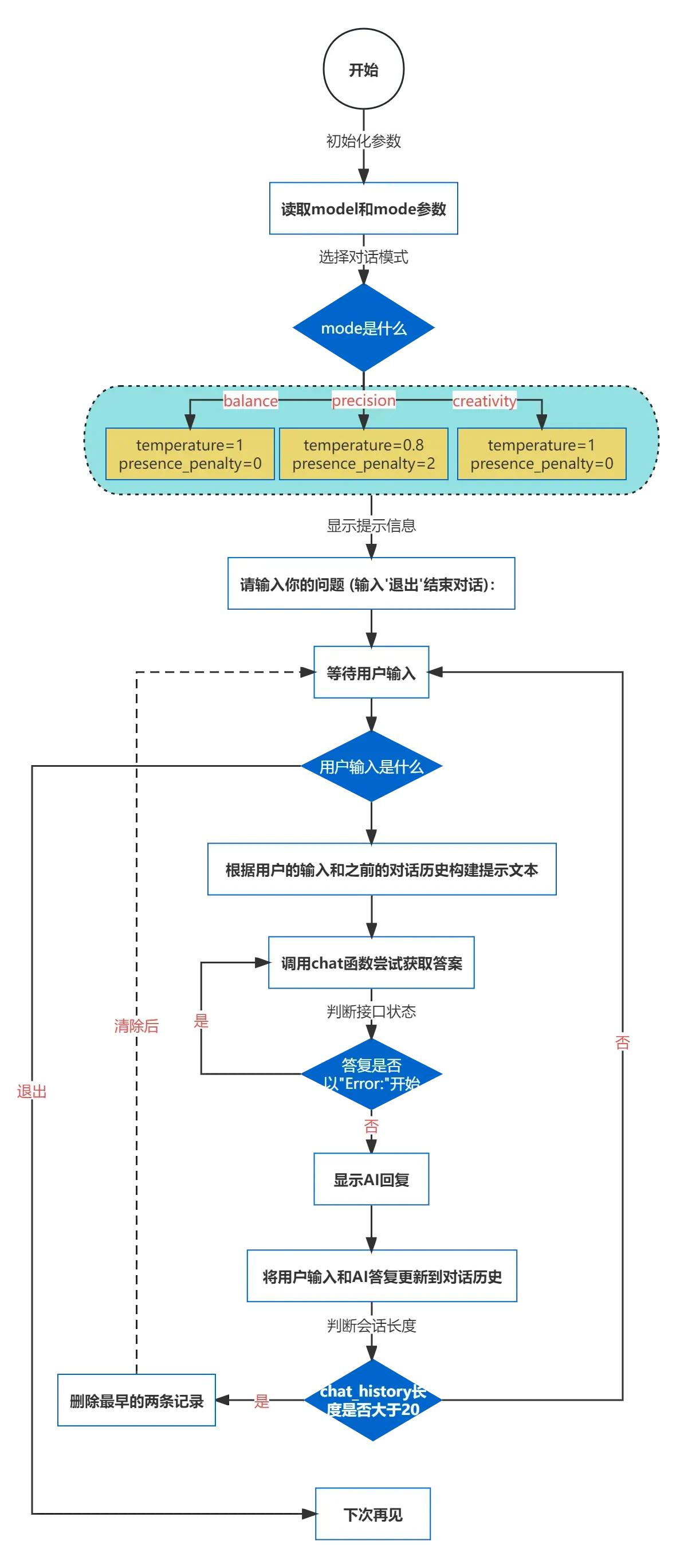
在这个初级阶段,大模型其实只是被用作了一个强有力的辅助工具集成到应用中,它没有被完全整合到敏捷开发流程中。也就是说,这一阶段的开发更多地是人工主导,大模型起到的主要作用还是信息检索和简单的任务自动化,而不是全面地推动开发进程。
1.2 基于大模型开发的中级阶段
当迈过了初级阶段进入中级阶段,借助大模型进行应用开发的流程我认为是这样的:
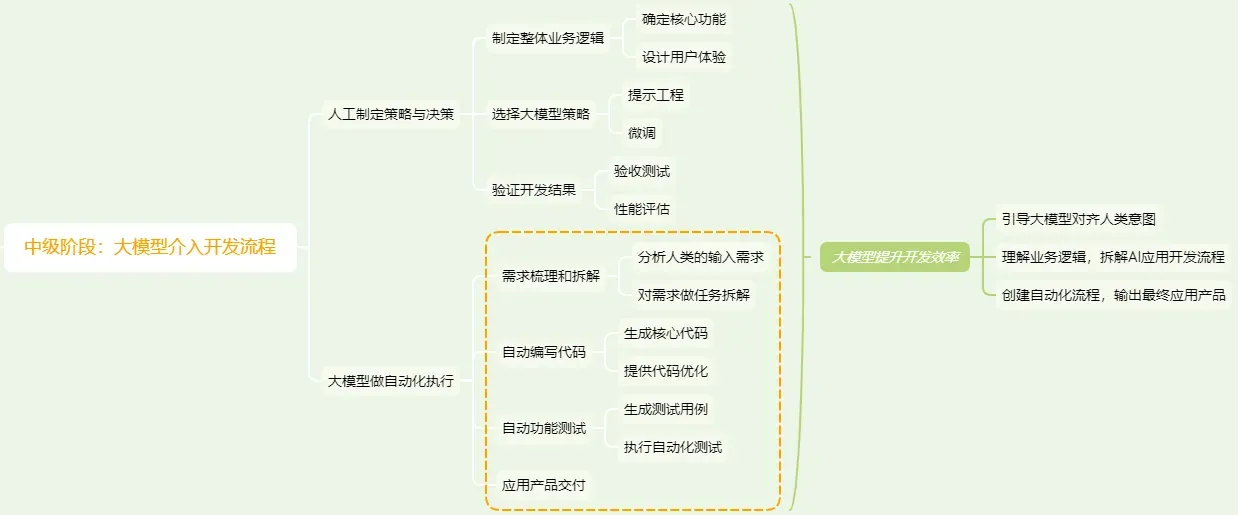
在这个中级阶段,大模型不再仅是一个辅助工具,而是转变为一个强力的合作伙伴。借助其出色的人类意图理解和代码编写能力,开发者的角色是通过提示工程或微调等手段来充分激发大模型的涌现能力,从而让大模型更积极地参与AI应用的开发流程。
OpenAI开发系列(十一):Function calling功能的实际应用流程与案例解析
OpenAI开发系列(十二):Function calling功能的流程优化与多轮对话实现
一个工业级的AI应用开发流程应该是这样的:
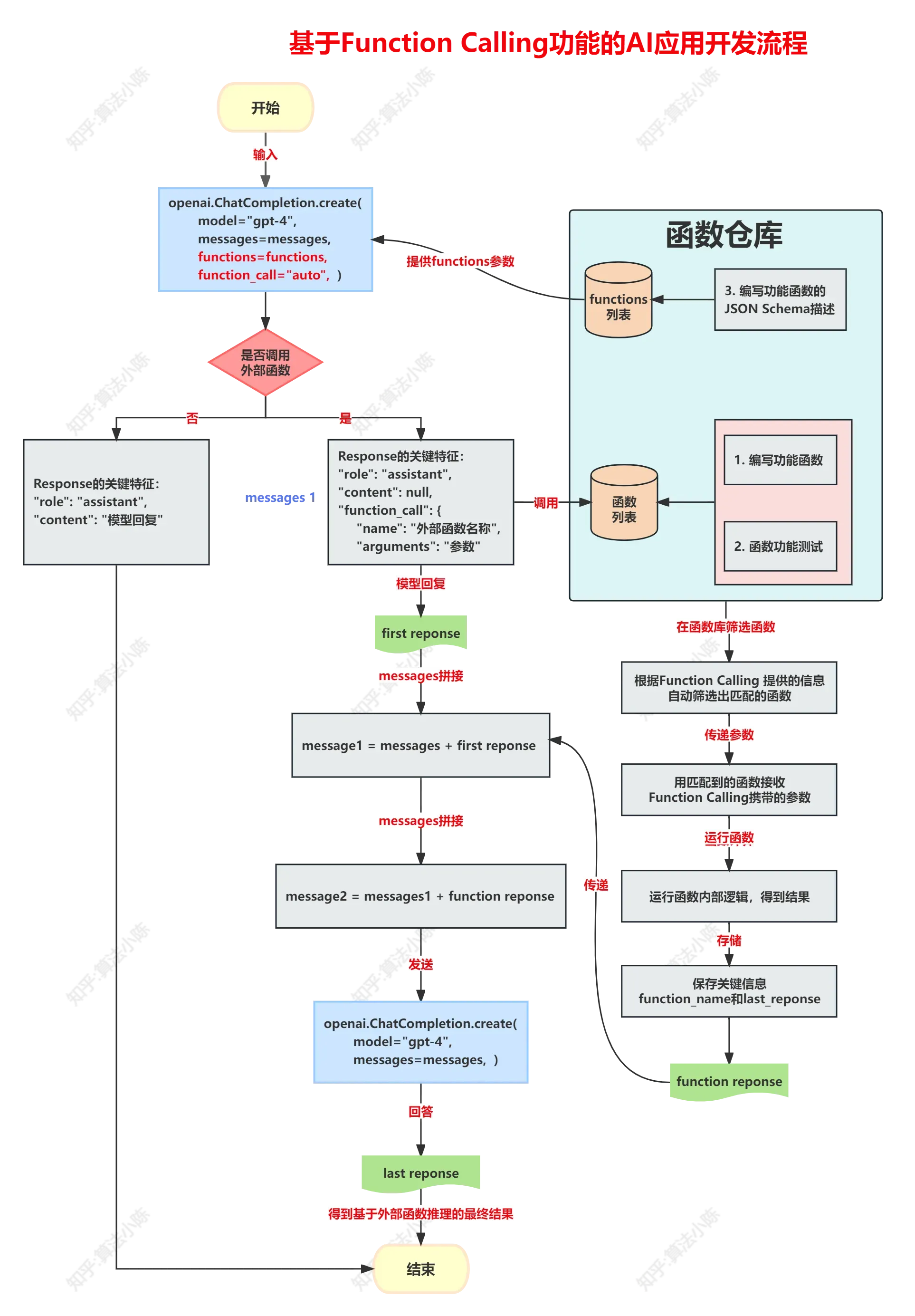
在这一阶段,人工主要负责构建整体的AI应用逻辑。与此同时,通过高级提示工程,赋予大模型自动编码并运行代码的能力。这实际上赋予了大模型一种“掌舵主”的角色,使其能接管从人工手中逐步转移过来的职责。这才是所期待看到的新AI开发范式,比如之前做的两点优化:
AutoFunctionGenerator类,自动生成一系列功能函数的 JSON Schema 描述
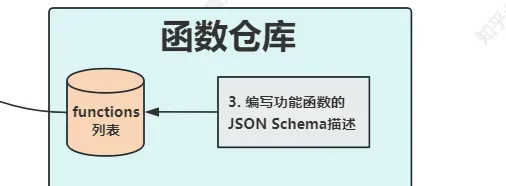
ChatConversation类,可选地调用外部功能函数,自动完成与大模型的对话过程
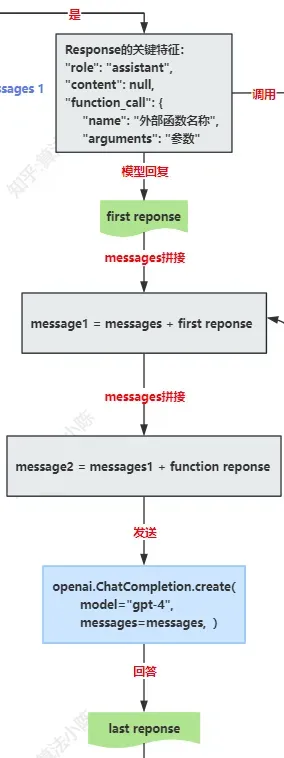
但其实我想说的是:大模型还可以介入更多流程中。
二、自动化生成外部功能函数
外部功能函数是设计用来激活大模型中的Function Calling功能的,它能自动识别这些函数并根据预定义的逻辑生成相应的输出。上面提到的开发流程拆解来看,主要包括三个步骤:
- 根据业务逻辑手动编写功能函数。
- 为每一个功能函数生成相应的JSON Schema对象描述,以启用大模型的Function Calling功能。
- 等待模型返回相应的执行结果。
后两步已经可以由大模型自动完成。这意味着,一旦人工确定了应用的整体业务逻辑,如果大模型就能自动拆解这些逻辑并生成相应的功能函数,这样的自动化流程让大模型在应用开发中起到了更加主动和核心的角色,从而更好地释放了人力资源,使其能更专注于高层次的策略和决策。所以,如何引导Chat Completion模型完成功能函数的编写,是需要考虑的问题。
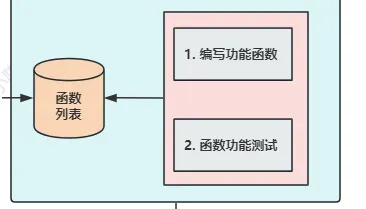
幸运的是,通过一系列的测试,我发现大模型可以通过精心设计的提示工程成功地自动完成这一流程。具体来说有两个细节需要注意:
- 如何设计合适的输入提示来引导模型
- 如何从模型输出的字符串中提取出有效的代码
简单来说,除了需要精心构造的提示以引导模型之外,因为Chat Completion模型的输入和输出都是字符串格式,还需要开发一种机制,用于解析模型输出字符串中的代码,并将其转化为实际可运行的功能函数。
2.1 如何设计合适的提示词
首先需要验证模型是否具备相应的能力,即它是否可以生成完整的函数,一个简单的测试示例如下:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[{"role": "system", "content": "你是一个专门的Python代码编辑器。你的任务是生成准确、高质量的Python代码。请仅输出纯Python代码,不要包含任何其他类型的文本或解释。"},
{"role": "user", "content": "请为我创建一个Python函数,该函数的作用是输出'Hello, World!'字符串。在函数的实现过程中,请添加详细的中文注释和函数说明以解释函数的工作原理。"}
]
)
response.choices[0].message['content']
看下输出:

2.2 存储可执行代码
- Step 1:提取代码片段
想实现直接在本地调用,经过多次尝试,一种比较高效的解决问题的方法是直接在上述字符串中通过正则表达式提取出只包含Python代码的字符串,代码如下:
def extract_executable_python_code(markdown_str):
"""
提取包含在Markdown格式字符串中的Python代码。
若输入字符串是Markdown格式且包含Python代码块,此函数将提取出代码块。
否则,返回原字符串。
参数:
markdown_str: 待检查的Markdown格式字符串。
返回:
提取出的Python代码块或None。
"""
import re
# 判断字符串是否是Markdown格式
if re.search(r'```(?:python|Python|PYTHON)', markdown_str):
# 找到代码块的开始和结束位置
code_start = markdown_str.find('def')
code_end = markdown_str.find('```\n', code_start)
# 提取代码部分
code = markdown_str[code_start:code_end]
else:
# 如果字符串不是Markdown格式,返回原字符串
code = markdown_str
return code
测试一下执行结果:
python_code = extract_executable_python_code(response.choices[0].message['content'])

- Step 2:本地存储
本地存储不仅是应用的一个关键功能,还充当着代码仓库的角色,便于大模型进行选择和调用。当使用自然语言指导大模型自动生成函数后,下一步是将这些函数保存到本地存储中。这样做的目的是确保大模型在执行Function Calling操作时能够无缝地访问并调用这些预先存储的函数。
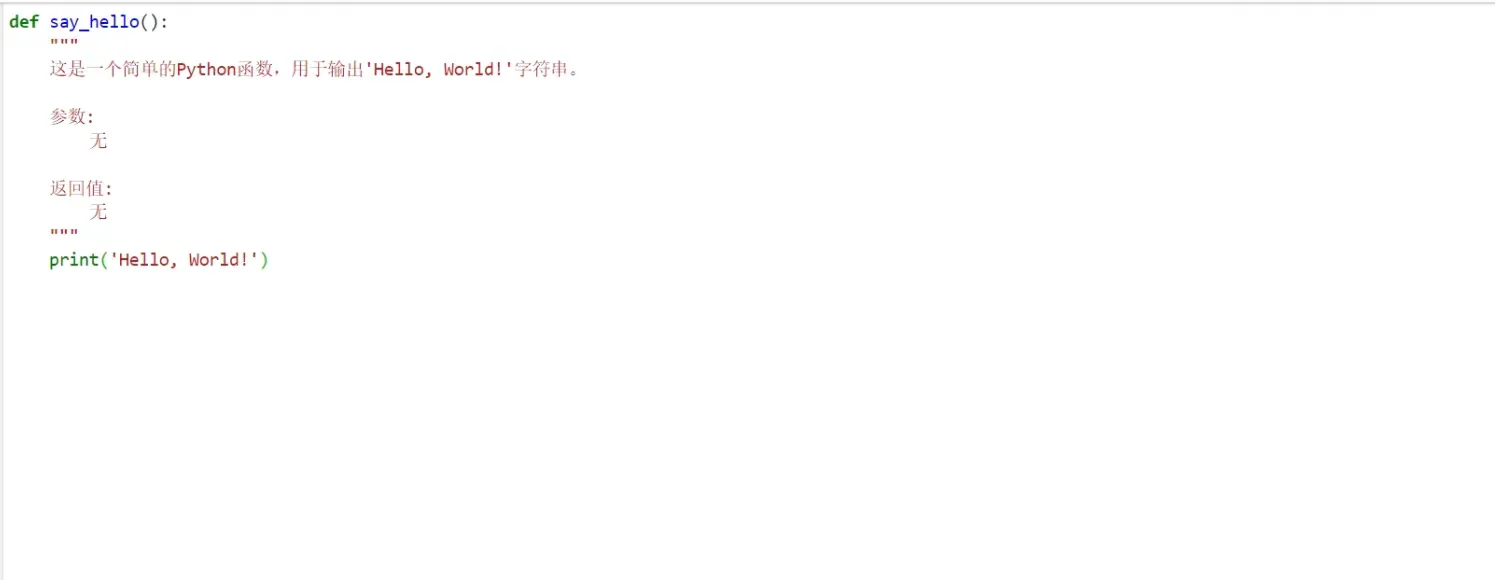
让大模型在执行Chat模型输出的字符串是一个markdown格式对象,将其保存为md格式,看看格式化的代码是什么样的,代码如下:
with open('helloworld.py', 'w', encoding='utf-8') as f:
f.write(python_code)
看下helloworld.py中的内容:
- Step 3:封装函数
所以综上一个流程化的封装类是这样的:
import re
import os
class PythonCodeExtractor:
"""
PythonCodeExtractor 类用于从 Markdown 格式的字符串中提取 Python 代码,
并将其保存到指定的目录。
属性:
working_directory: 用于存储 Python 代码文件的目录路径。
方法:
extract_executable_python_code: 从 Markdown 字符串中提取可执行的 Python 代码。
extract_and_save: 提取代码并保存到本地。
"""
def __init__(self, working_directory="./"):
"""
初始化 PythonCodeExtractor 类。
参数:
working_directory (str): 存储 Python 代码文件的目录路径。
"""
self.working_directory = working_directory
def extract_executable_python_code(self, markdown_str):
"""
从 Markdown 格式的字符串中提取可执行的 Python 代码。
参数:
markdown_str (str): 包含 Python 代码的 Markdown 字符串。
返回:
str: 提取出的 Python 代码或原字符串。
"""
# 使用正则表达式查找 Python 代码块
if re.search(r'```(?:python|Python|PYTHON)', markdown_str):
code_start = markdown_str.find('def')
code_end = markdown_str.find('```\n', code_start)
code = markdown_str[code_start:code_end]
else:
code = markdown_str
return code
def extract_and_save(self, markdown_input, verbosity_level=0):
"""
提取 Python 代码并保存到本地。
参数:
markdown_input (str): 输入的 Markdown 字符串。
verbosity_level (int): 控制输出的详细程度。0 为默认值,不输出额外信息;1 为输出函数详细信息。
"""
# 使用辅助函数提取代码
code = self.extract_executable_python_code(markdown_input)
# 使用正则表达式查找函数名
match = re.search(r'def (\w+)', code)
if match is None:
print("没有找到相关的函数")
return
function_name = match.group(1)
# 确保工作目录存在
folder_path = self.working_directory
if not os.path.exists(folder_path):
os.makedirs(folder_path)
# 完整的文件路径
file_path = os.path.join(folder_path, f"{function_name}.py")
# 将代码写入文件
with open(file_path, 'w', encoding='utf-8') as f:
f.write(code)
# 如果 verbosity_level 设置为 1,则输出函数的详细信息
if verbosity_level == 1:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
print("函数详细信息如下:")
print(content)
调用示例:
extractor = PythonCodeExtractor(working_directory="./function_dir")
extractor.extract_and_save(response.choices[0].message['content'], verbosity_level=1)
看下效果:
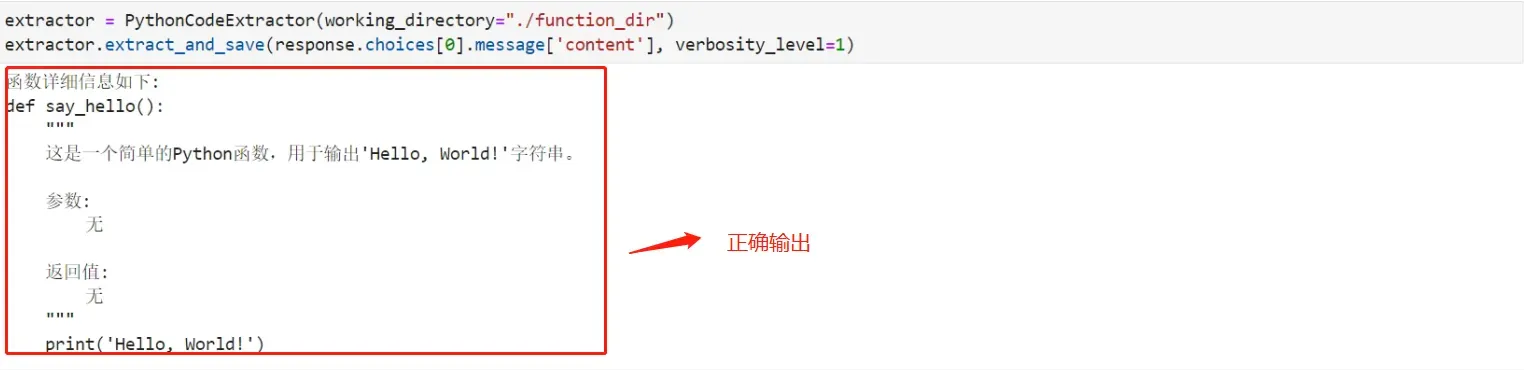
使用该类,即可便捷的将Chat Completion模型输出结果一键进行函数提取、保存和运行。
三、实践测试
在这个流程基础之上,实际测试一下代码流程的可用性。
使用OpenAI开发系列(十四):通过Google API赋能大模型,打造智能邮件助理中手动编写的fetch_latest_gmail_content()函数作为提示示例,引导大模型自动生成一个新的功能函数:获取用户邮箱内的邮件列表。验证过程如下:
- Step 1:选择提示示例
此前定义的get_latest_email函数如下:
def get_latest_email(userId):
"""
查询Gmail邮箱中最后一封邮件信息
:param userId: 必要参数,字符串类型,用于表示需要查询的邮箱ID,\
注意,当查询我的邮箱时,userId需要输入'me';
:return:包含最后一封邮件全部信息的对象,该对象由Gmail API创建得到,且保存为JSON格式
"""
# 从本地文件中加载凭据
creds = Credentials.from_authorized_user_file('token.json')
# 创建 Gmail API 客户端
service = build('gmail', 'v1', credentials=creds)
# 列出用户的一封最新邮件
results = service.users().messages().list(userId=userId, maxResults=1).execute()
messages = results.get('messages', [])
# 遍历邮件
for message in messages:
# 获取邮件的详细信息
msg = service.users().messages().get(userId='me', id=message['id']).execute()
return json.dumps(msg)
- Step 2:标准化格式输出
通过inspect.getsource()方法,读取get_latest_email()函数,将其转化成字符串格式
function_format = inspect.getsource(fetch_latest_gmail_content)
看下输出:

- Step 3:构造Few-Shot提示词
构造system role 的提示词,如下:
system_prompt= "你是一个专门与Gmail API交互的代码生成器。你的任务是生成用于操作Gmail的Python代码。 \
授权已通过本地的token.json文件完成,请确保仅输出与Gmail API相关的有效Python代码,不需要包含授权部分。"
构造Few-Shot提示词,也就是Q为自然语言对想要生成的函数的功能的描述,A为具体生成的函数,如下:
user_prompt_q = "请编写一个python函数,这个函数用于获取我的Gmail邮箱中最后一封邮件信息,函数的编写要求如下:\
1.函数应有一个参数:userId (str): 必填参数。表示需要查询的Gmail用户ID。注意,如果查询自己的邮箱,userId需设置为'me' \
2.函数的返回值包含最后一封邮件全部信息的JSON格式字符串,该对象由Gmail API创建并返回。如果查询失败,返回包含错误信息的JSON格式字符串。\
3.在函数内部,务必添加详细的中文注释和函数说明,清楚的说明数的目的、参数以及返回值等详细信息。\
4.请务必将上述提到的所有功能封装在这一个函数内部。"
user_prompt_a = function_format
构造新功能函数的输入描述,假设想让大模型生成一个查询所有邮件标题这一功能的函数,如下:
user_q = "请编写一个python函数,这个函数用于获取我的Gmail邮箱中所有邮件的标题列表,函数的编写要求如下:\
1.函数应有一个参数:userId (str): 必填参数。表示需要查询的Gmail用户ID。注意,如果查询自己的邮箱,userId需设置为'me' \
2.函数的返回值包含最后一封邮件全部信息的JSON格式字符串,该对象由Gmail API创建并返回。如果查询失败,返回包含错误信息的JSON格式字符串。\
3.在函数内部,务必添加详细的中文注释和函数说明,清楚的说明数的目的、参数以及返回值等详细信息。\
4.请务必将上述提到的所有功能封装在这一个函数内部。"
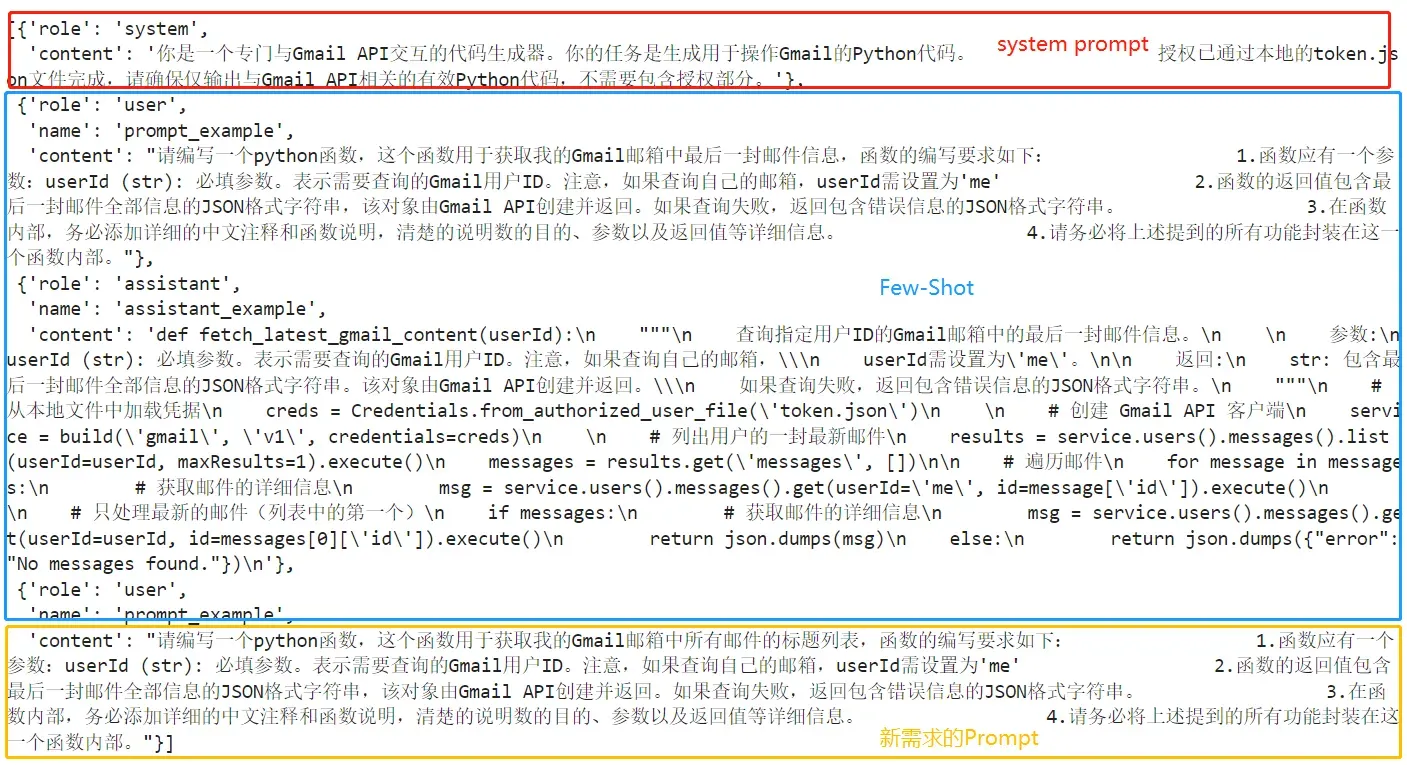
构造messages
messages=[{"role": "system", "content": system_prompt},
{"role": "user", "name":"prompt_example", "content": user_prompt_q},
{"role": "assistant", "name":"assistant_example", "content": user_prompt_a},
{"role": "user", "name":"prompt_example", "content": user_q}]
看下最终要输入大模型的messages
- Step 4:调用模型
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=messages
)
看一下输出结果:
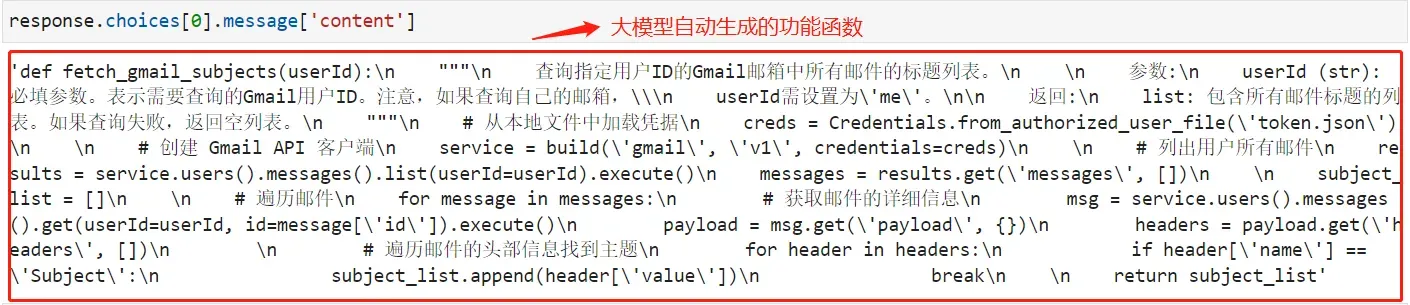
- Step 5:提取代码后写入本地
extractor = PythonCodeExtractor(working_directory="./function_dir")
extractor.extract_and_save(response.choices[0].message['content'], verbosity_level=1)
看一下生成的本地代码:
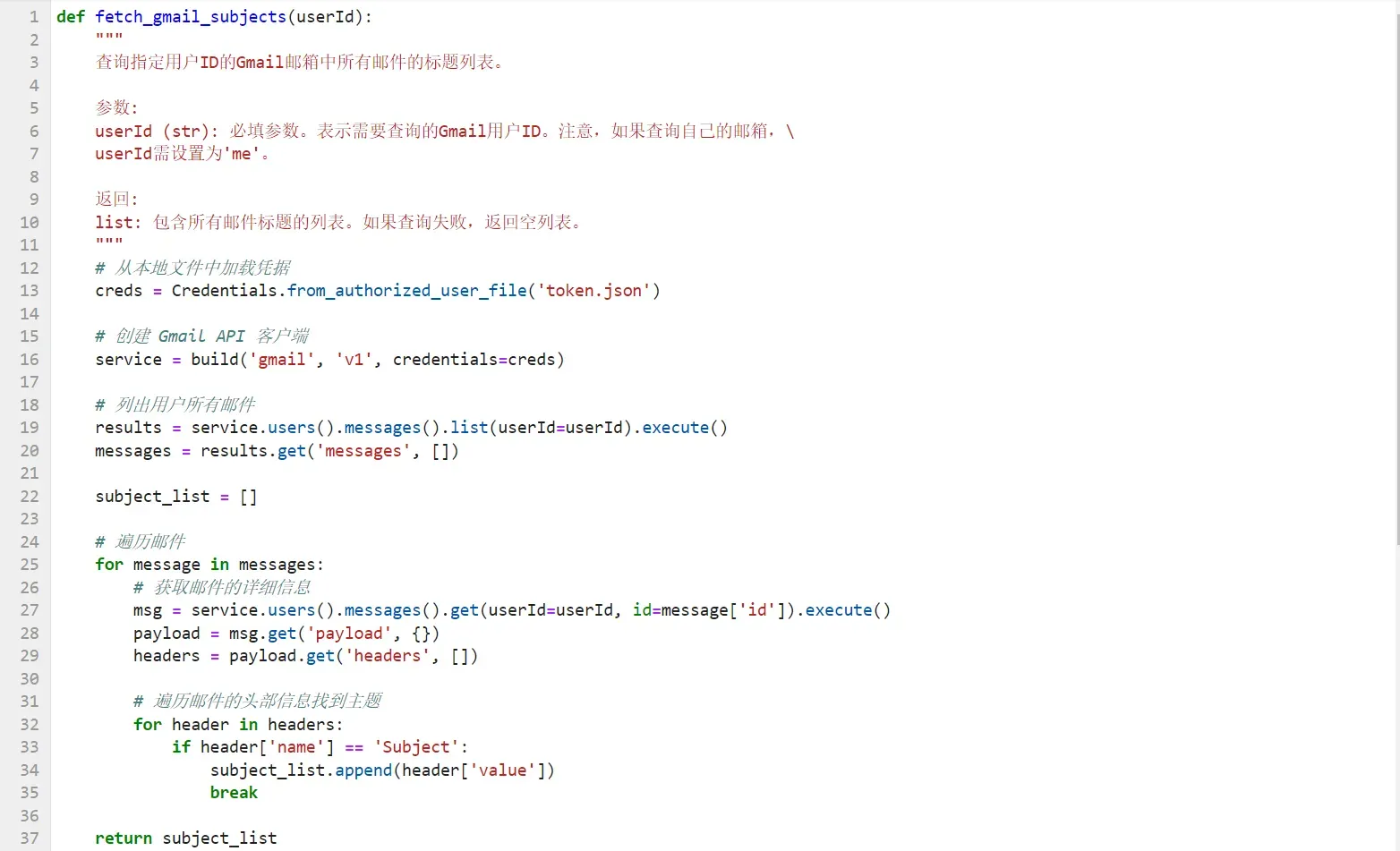
- Step 6:本地运行函数测试
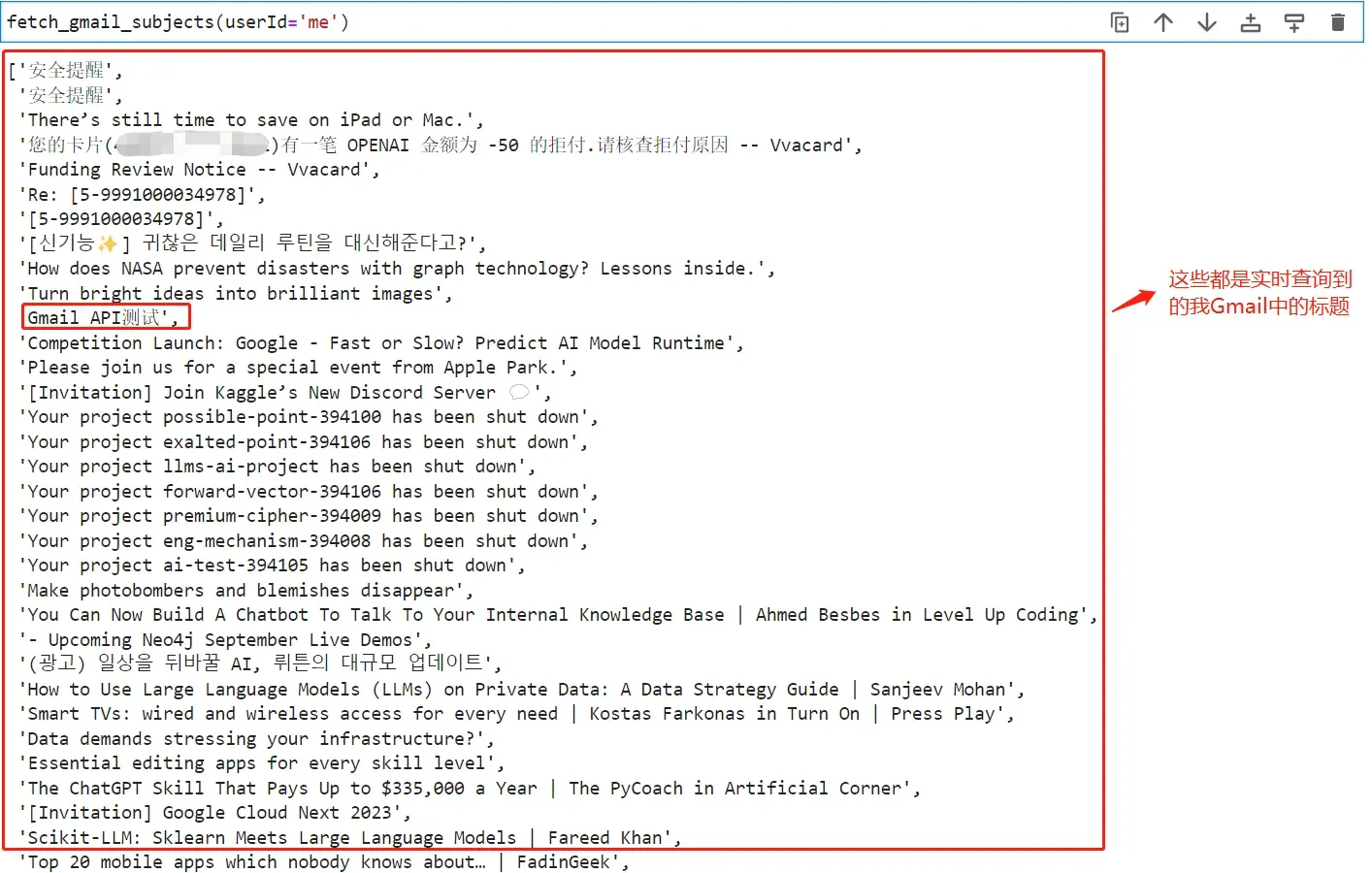
- Step 7:测试该函数能否能被顺利的转化为functions参数
使用AutoFunctionGenerator类:
functions_list = [fetch_gmail_subjects]
generator = AutoFunctionGenerator(functions_list)
function_descriptions = generator.auto_generate()
看下输出结果:
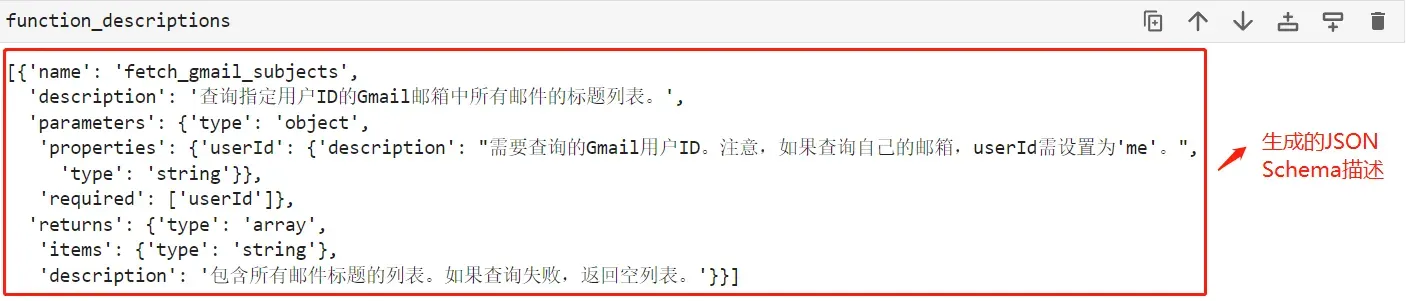
- Step 8:测试functions函数说明能否被Chat模型正确识别
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[{"role": "user", "content": '请帮我列举出我Gmail邮箱中所有邮件的标题'}],
functions=function_descriptions,
function_call="auto",
)
看下输出结果: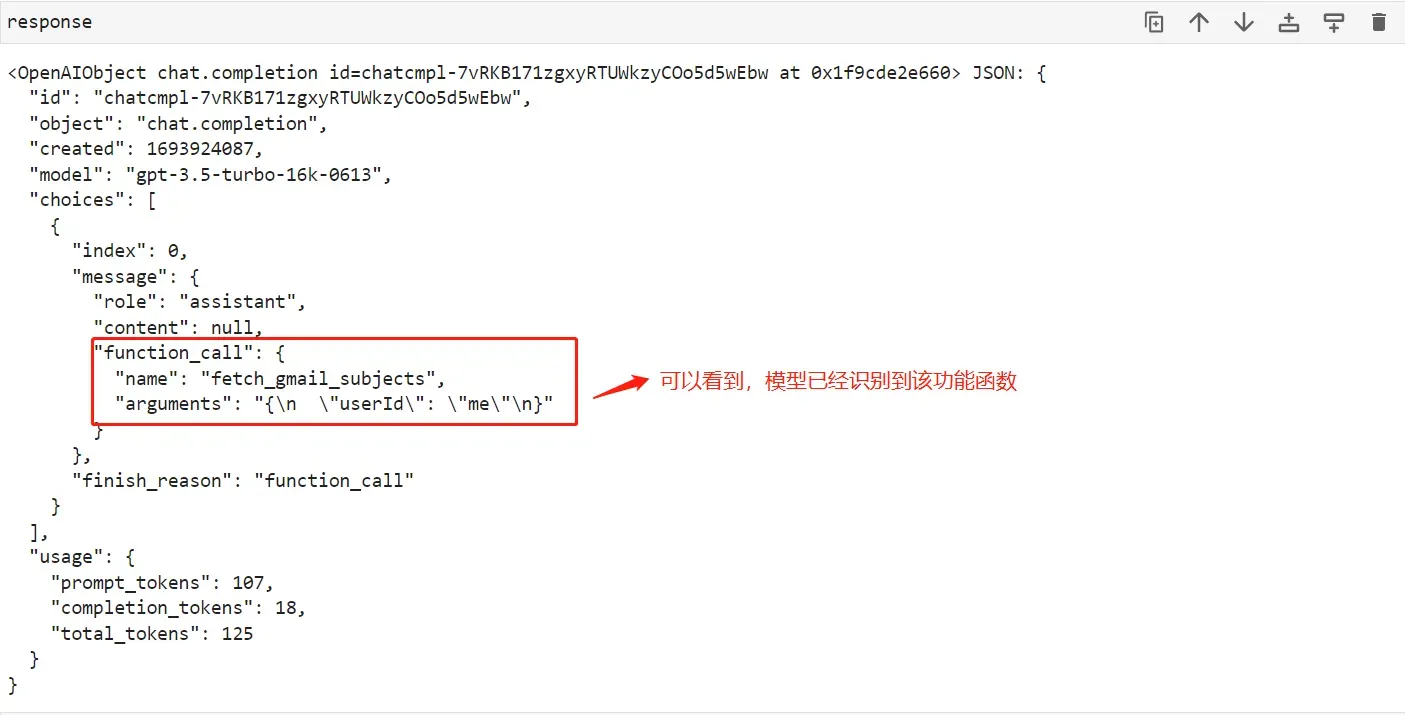
- Step 9:手动查看结果
function_repository = {
"fetch_gmail_subjects": fetch_gmail_subjects,
}
function_name = response["choices"][0]["message"]["function_call"]["name"]
function_args = json.loads(response["choices"][0]["message"]["function_call"]["arguments"])
local_fuction_call = function_repository[function_name]
final_response = local_fuction_call(**function_args)
看下最终结果:
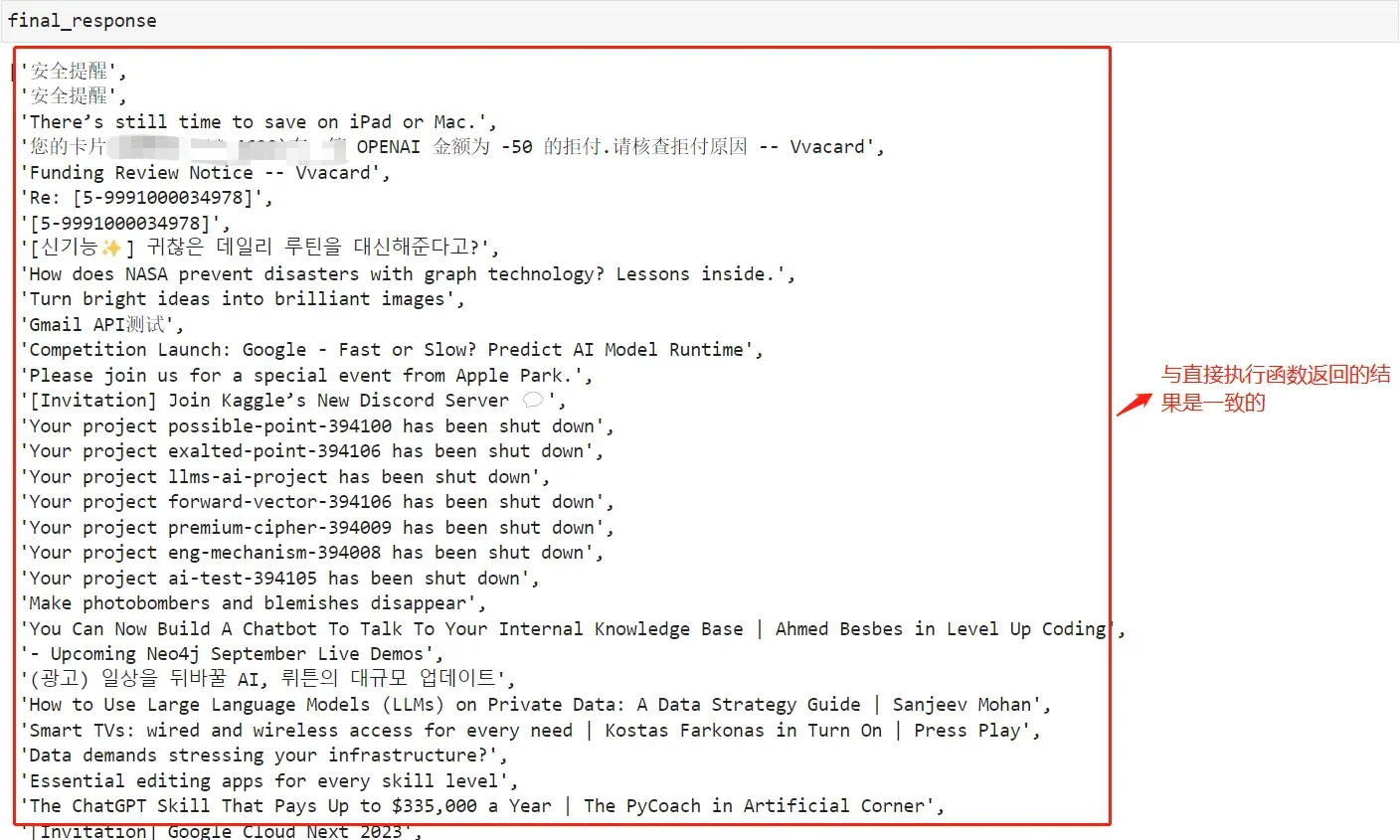
总的来说,本文已通过Few-Shot提示法展示了如何利用大型模型自动开发新功能函数,进一步提高了自动编程的效率。
文章出处登录后可见!