《Causal Inference in Python: Applying Causal Inference in the Tech Industry》因果推断啃书系列
第1章 因果推断导论
第2章 随机实验与统计学回顾
第3章 图形化因果模型
第4章 线性回归的不合理有效性
第5章 倾向分
第6章 效果异质性
第7章 元学习器
第8章 双重差分
持续更新中:
第9章 综合控制
第10章 Geo实验与Switchback实验
第11章 不依从性与工具
第12章 后续行动
《Causal Inference in Python》第6章 效果异质性
- 第6章 效果异质性(Effect Heterogeneity)
- 6.1 从ATE到CATE
- 6.2 为什么预测不是答案
- 6.3 使用回归计算CATE
- 6.4 评估CATE预测结果
- 6.5 模型分位数的效果
- 6.6 累积效果(Cumulative Effect)
- 6.7 累积增益(Cumulative Gain)
- 6.8 目标转化(Target Transformation)
- 6.9 当预测模型对效果排序有益
- 6.9.1 边际递减收益(Marginal Decreasing Returns)
- 6.9.2 二元结果
- 6.10 CATE用于决策
- 6.11 要点总结
第6章 效果异质性(Effect Heterogeneity)
本章将介绍因果推断应用于工业领域的最有趣的进展:效果异质性(Effect Heterogeneity)。到目前为止,你了解了干预的一般影响。现在,你将专注于发现它如何对人们产生不同的影响。干预效果不是恒定不变的,这个想法很简单,但却非常强大。知道哪些单元对某种干预的反应更好是决定谁接受干预的关键。效果异质性为实现人们重视的个性化理念提供了一种因果推断方法。
我们先从理论上理解效果异质性,了解在估算效果异质性方面存在哪些挑战,以及如何扩展已经学到的知识来应对这些挑战。接下来,你将看到估算异质性效果与数据科学家已经非常熟悉的预测问题密切相关。因此,你将看到交叉验证和模型选择的思想仍然适用于干预异质性模型。然而,验证您的效果估算比评估一个简单的预测模型更具挑战性,所以我们需要一些新想法来解决这个问题。
本章最后会介绍一些使用效果异质性指导决策制定的方法和案例。虽然不是详尽的,但这些示例将告诉你如何在自己的业务问题上使用这些想法。
6.1 从ATE到CATE
到目前为止,每次你估算一种干预的因果影响时,大多是平均治疗效果:
或者是连续干预:
其中 是干预反馈公式的衍生,干预反馈公式是在前面章节介绍的揭示干预的一般有效性的技术。ATE估算是因果推断的基础,是超级有用的决策问题工具,用于解决这样的问题:是否应该将一种干预推广到所有人群。
现在,是时候学习另一种类型的决策:你应该干预哪个单元?为此,干预决策应该在各单元之前是可迁移的。例如,提供折扣券对一个客户可能会产生有益的影响,但对另一个客户可能没有影响,因为不同客户对折扣的敏感度不同。或者,优先为一个群体接种疫苗而不是另一个群体,这样的优先级设定可能是有意义的,因为被选择的群体将从这种干预中受益更多。在这种情况下,个性化(personalization)是关键。
实现这种个性化的一种方法是考虑效果异质性,这涉及到估算条件平均处理效果(CATE)。通过考虑每个单元的独特特征,可以确定针对特定情况的最有效干预方法:
对 设置条件意味着你现在允许干预效果会根据每个单元的协变量
定义的特征而有所不同。也就是说,我们相信并不是所有实体对干预的反应都是一样的,可以利用这种异质性。我们希望只对正确的单元进行干预(二元干预情况)或计算出每个单元的最佳干预程度(连续干预情况)。
例如,对于一家银行,必须决定每个客户是否有资格获得贷款,你可以肯定,给每个人都贷款不是一个好主意,尽管这对一些人来说可能是合理的。还有,你需要确定有资格获得贷款的人的贷款金额,也许根据客户的信用评分,你可以计算出适当的贷款金额是多少。应用个性化的例子很多:应该在一年中的哪几天做销售?应该对一件产品收取多少费用?对每个人来说,多少运动量算过度运动?
6.2 为什么预测不是答案
这样想吧,你有一群客户,需要对他们进行一种干预(价格、折扣、贷款······),你希望个性化这种干预——例如,为不同的客户提供不同的折扣。并假设你可以按照以下干预-结果关系图来安排你的客户:
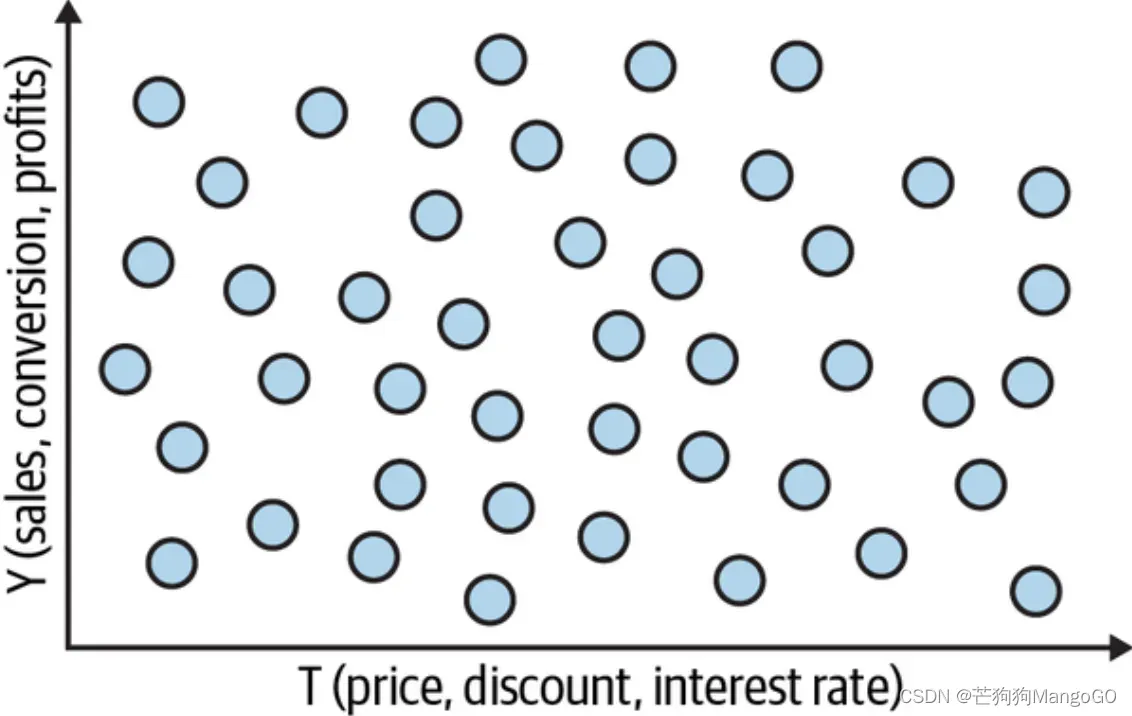
你可以把个性化任务看作是客户细分的问题,你希望根据客户对干预的反应对客户进行分群。例如,假设你想找到对折扣反应良好的客户和对折扣反应不佳的客户,顾客对干预的反应是由条件干预效果 给出的。所以,如果你能以某种方式对每个顾客的条件干预效果进行估算,你就能将那些对干预反应好的人(高干预效果)和那些反应不太好的人进行分组。如果你这样做了,分割的客户空间有点像下图:
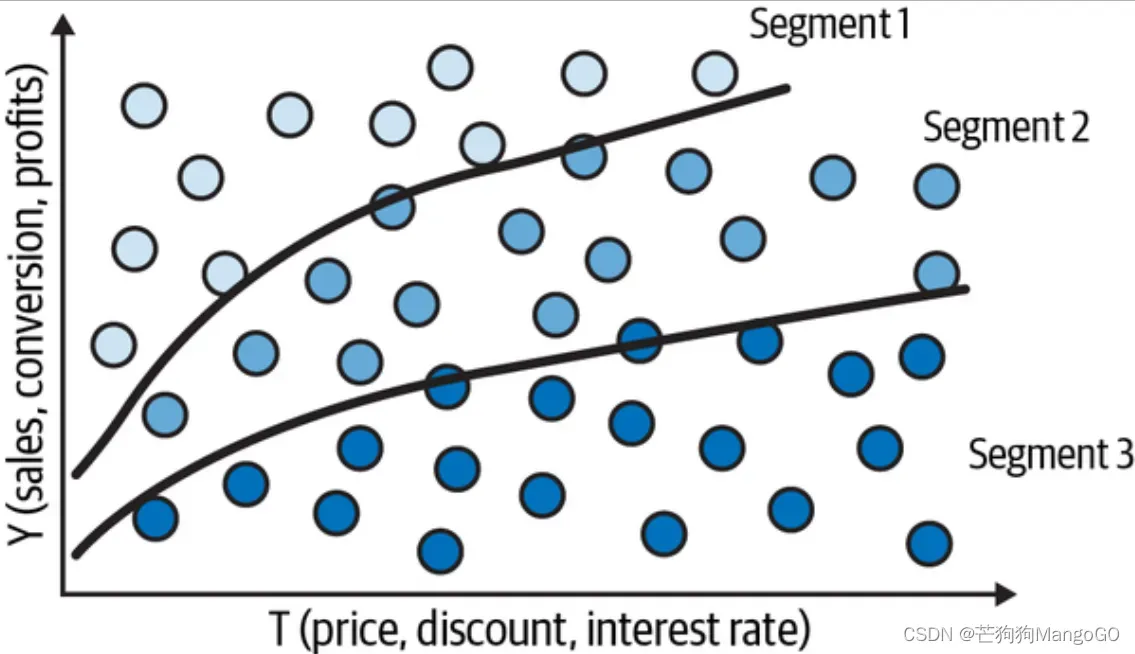
这就太好了,因为这样你就能估算每组的不同干预效果了。同样,由于效果只是干预响应函数的斜率,如果你可以生成斜率不同的组,那么这些分区上的实体将对干预有不同的响应:
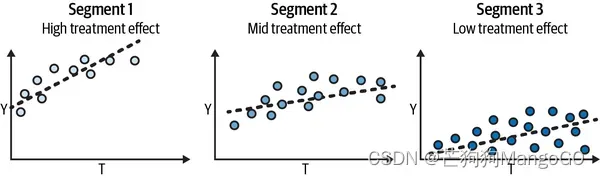
现在,对比一下传统机器学习方法得到的结果。传统机器学习方法中你可能会尝试预测 ,而不是每个单元的导数
,这将在y轴上划分空间,前提是预测模型能够很好地逼近目标。然而,这并不一定会产生具有不同干预效果的群体。这就是为什么简单地预测结果并不总是对决策有用:
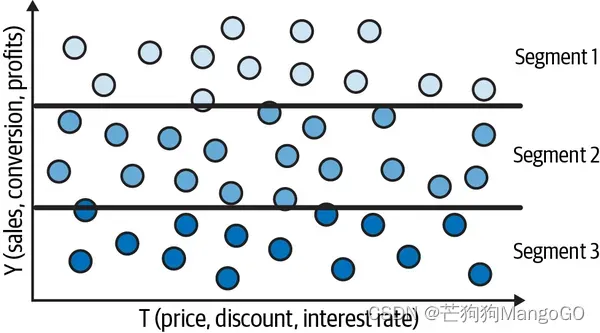
你可能会说,我知道我必须估算效果,而不是预测结果,但这有点棘手。如果看不到斜率,我怎么能预测 呢?
问得很好。与明面上的结果 不同,斜率(或变化率)在每个单元本身基本上是不可观察的。要看到各个斜率,你必须观察不同干预水平下的每个单元,并计算这些干预的结果如何变化:
这又是因果推断的基本问题。你不可能在相同的单元上看到不同的干预。那么,你能做些什么呢?
CATE与ITE
请记住,CATE不同于个体干预效果(ITE)。例如,假设你有两组,
和
,每组有4个单元。你想知道一种新药对一种疾病的效果,这种疾病通常会导致50%的患者死亡。对于分组
6.3 使用回归计算CATE
我想你可能已经预见到了:与应用因果推断中的大多数事情一样,答案往往从线性回归开始。但在走这条路之前,让我们让事情变得更加具体。假设你为一家全国经营的连锁餐厅工作,这项业务的一个关键组成部分是了解什么时候应该给客户折扣。出于这个原因,该公司在全国范围内进行了为期三年的试验,在该连锁店的六家不同餐厅中随机分配折扣。数据存储在以下数据框中:
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
import matplotlib
from cycler import cycler
color=['0.0', '0.4', '0.8']
default_cycler = (cycler(color=color))
linestyle=['-', '--', ':', '-.']
marker=['o', 'v', 'd', 'p']
plt.rc('axes', prop_cycle=default_cycler)
matplotlib.rcParams.update({'font.size': 18})
data = pd.read_csv("./data/daily_restaurant_sales.csv")
data.head()
| rest_id | day | month | weekday | weekend | is_holiday | is_dec | is_nov | competitors_price | discounts | sales | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 2016-01-01 | 1 | 4 | False | True | False | False | 2.88 | 0 | 79.0 |
| 1 | 0 | 2016-01-02 | 1 | 5 | True | False | False | False | 2.64 | 0 | 57.0 |
| 2 | 0 | 2016-01-03 | 1 | 6 | True | False | False | False | 2.08 | 5 | 294.0 |
| 3 | 0 | 2016-01-04 | 1 | 0 | False | False | False | False | 3.37 | 15 | 676.5 |
| 4 | 0 | 2016-01-05 | 1 | 1 | False | False | False | False | 3.79 | 0 | 66.0 |
你的目标是了解什么时候是提供折扣的最佳时机。在该数据中,每个餐厅和日期组合确定一行数据。这与本书中使用的大多数例子略有不同,在那些例子中分析单元是客户,现在分析单元是日期-餐厅的组合。即使如此,你仍然可以应用之前的推理,只是你要”干预“(给予折扣)的是日期,而不是客户。你可以设定每个餐厅每天有不同的价格,但让我们简化这个问题,不同餐厅的价格保持一致。
你可以将这个业务问题框定为一个CATE估算问题。如果你可以创建一个模型,输出每天的折扣和协变量的销售敏感性,即:
然后,你可以使用该模型来决定何时给予折扣以及给予多少折扣。
CATE识别
本章不必过于担心识别,因为干预在评估集中是随机的。然而,整个估算CATE的想法是基于使得
成立。
现在你已经有了一些更具体的东西可以用了,让我们看看回归是如何起到作用的。回想一下,你的处境很复杂,你需要预测 ,不幸的是,这是不可观测的。因此,你不能简单地使用ML算法并将其作为目标。但也许你不需要观测
就能预测。
例如,假设你拟合数据的线性模型如下:
如果你在干预上对其求微分,你会得到以下结果:
即ATE,在随机干预的情况下。
既然你可以估算这个模型获得 ,你甚至可以说你可以预测斜率,即使你不能观测到它们。在这个例子中,这是一个相当简单的预测。你是在预测每个人的常量
。这很不错,但不是你想要的。获得的是ATE,而不是CATE。这并不能帮助你确定应该何时给予折扣,因为每个单元(日期和餐厅组合)都得到了相同的斜率预测。
为了改进它,你可以做以下简单的修改:
这将给你带来以下斜率预测:
式中 为特征
的向量系数。现在你已经有所进展了!由不同的
定义的每个实体将有不同的斜率预测,也就是斜率预测会随着
变化而变化。直观地说,将干预和协变量之间的相互作用包含进来可以让模型了解效果是如何随着这些相同的协变量产生变化。这就是回归估计CATE的方法,即使你不能直接预测CATE。
理论就说到这里吧,让我们看看如何编写代码。首先,你需要定义协变量。在这个例子中,协变量基本上是特定日期的特征,比如月份、一周中的哪一天,以及是否为假期。我还包括了竞争对手的平均价格,因为这可能会影响顾客对每家餐厅的折扣的反应。
只要有协变量,你就需要将它们与干预相互作用,* 操作符做的就是这样的事情。它为左右两边创造了一个相加项加上一个交互项。例如,a*b 将在你的回归中包括 a、b 和 a*b 项。在你的例子中,这将导致以下结果:
import statsmodels.formula.api as smf
X = ["C(month)", "C(weekday)", "is_holiday", "competitors_price"]
regr_cate = smf.ols(f"sales ~ discounts*({'+'.join(X)})",
data=data).fit()
*运算符与 :运算符
如果你只需要乘法项,你可以在公式中使用 :运算符。
对这个模型进行估算,就可以从参数估算值中提取预测斜率:
式中 为折扣系数,
为交互系数向量。你可以从拟合后的模型中提取这些参数,但更容易得到斜率预测的方法是使用导数的定义:
其中 趋近于0。你可以用1替换
来近似这个定义:
其中 由你的模型预测给定。因为这是一个线性模型,所以近似是精确的。
换句话说,将使用你的模型进行两次预测:一次计算原始干预对应的结果,第二次计算干预增加一个单位后对应的结果,两次预测之间的差值就是CATE的预测。下面是这个计算过程的代码:
ols_cate_pred = (
regr_cate.predict(data.assign(discounts=data["discounts"]+1))
-regr_cate.predict(data)
)
现在你有了CATE模型和它的预测,但仍有一个潜在的问题:这个模型怎么样?换句话说,如何评估这个模型?正如你可能知道的那样,在这里比较实际值和预测值是不可行的,因为在单元颗粒度上没有观察到实际干预效果。
价格歧视(price discrimination)
在微观经济学文献中,本章使用的例子是所谓的价格歧视。尽管这个名字听起来很糟糕,但它只是意味着企业可以识别那些愿意支付更多费用和收取更多费用的人。一个非常著名的价格歧视例子是,航空公司根据提前购买机票的时间来改变机票价格:需要预订下周机票的客户预计将比预订明年机票的客户支付更多的钱。这被称为跨期价格歧视,因为公司设法根据时间区分客户的价格敏感性。这与你在本章中看到的餐厅例子非常相似。
一个更臭名昭著的例子是,一家葡萄酒公司出售两瓶完全相同的葡萄酒,一瓶以更高的价格销售,另一瓶以更低的价格销售。第三种价格歧视是给学生提供半价门票。在这种情况下,该公司知道学生平均赚的钱更少,这意味着他们可以花的钱更少。
6.4 评估CATE预测结果
如果你有传统的数据科学背景,你可能会发现这种 CATE 预测看起来很像常规的机器学习预测,但是它有一个不可观测的隐蔽目标。这意味着许多传统机器学习中使用的模型评估技术——如交叉验证——在这里仍然适用,而其他技术则需要进行一些调整。
因此,为了保持传统,让我们将数据分成训练集和测试集,就使用时间维度来分割。训练集将包含2016年和2017年的数据,而测试集将包含2018年以后的数据。
train = data.query("day<'2018-01-01'")
test = data.query("day>='2018-01-01'")
现在,让我们使用之前数据重新拟合CATE回归模型,但仅使用训练数据创建估算器,并对测试集进行预测:
X = ["C(month)", "C(weekday)", "is_holiday", "competitors_price"]
regr_model = smf.ols(f"sales ~ discounts*({'+'.join(X)})",
data=train).fit()
cate_pred = (
regr_model.predict(test.assign(discounts=test["discounts"]+1))
-regr_model.predict(test)
)
我们想要比较两个模型的性能:一个是基于因果推断的回归模型,另一个则是纯粹的预测性机器学习模型。通过比较这两个模型的预测结果,我们可以更深入地了解因果推断模型的优势和局限性,以及它们在实际应用中的表现。
from sklearn.ensemble import GradientBoostingRegressor
X = ["month", "weekday", "is_holiday", "competitors_price", "discounts"]
y = "sales"
np.random.seed(1)
ml_model = GradientBoostingRegressor(n_estimators=50).fit(train[X],
train[y])
ml_pred = ml_model.predict(test[X])
最后,我们在模型对比中也引入一个非常糟糕的模型,即一个完全随机生成-1到1之间的随机数的预测结果的模型,这样可以更直观地看出其他模型的性能是否优于随机猜测。
同时,为了方便后续的数据处理和分析,将所有的预测结果存储在一个名为 test_pred 的数据框中。
np.random.seed(123)
test_pred = test.assign(
ml_pred=ml_pred,
cate_pred=cate_pred,
rand_m_pred=np.random.uniform(-1, 1, len(test)),
)
test_pred[["rest_id", "day", "sales",
"ml_pred", "cate_pred", "rand_m_pred"]].head()
| rest_id | day | sales | ml_pred | cate_pred | rand_m_pred | |
|---|---|---|---|---|---|---|
| 731 | 0 | 2018-01-01 | 251.5 | 236.313 | 41.3558 | 0.392938 |
| 732 | 0 | 2018-01-02 | 541.0 | 470.218 | 44.7439 | -0.427721 |
| 733 | 0 | 2018-01-03 | 431.0 | 429.181 | 39.7838 | -0.546297 |
| 734 | 0 | 2018-01-04 | 760.0 | 769.159 | 40.7703 | 0.10263 |
| 735 | 0 | 2018-01-05 | 78.0 | 83.4261 | 40.6669 | 0.438938 |
一旦你构建好模型,接下来的挑战就在于如何估算和比较它们的表现。这需要我们面对一个现实,那就是真实情况是无法直接观察的。然而,有一个技巧可以帮助我们解决这个问题:尽管我们无法测量单个个体的干预效果,但可以在非常小的群体中进行估算。因此,要想基于CATE评估模型,我们必须依赖群体级别的度量指标。这样,我们便能够更准确地了解和比较不同模型的表现。
6.5 模型分位数的效果
CATE模型的诞生,背后是出于一个核心需求:我们希望找出哪些单位对干预更为敏感,以便更高效地分配干预资源。简而言之,它反映了对个性化的追求。那么,如果我们能够根据敏感程度对单位进行排序,这将大大有助于实现这一目标。既然CATE已经给出了预测值,那么我们自然可以依据这一预测值来对单位排序,期待它同时也能按照真实的CATE值来排序。然而,遗憾的是,我们无法在个体单位层面上评估这种排序的准确性。但有没有其他的评估方式呢?比如说,我们是否可以评估由这种排序所定义的群体?
首先,请回忆一下,当干预是随机分配的,我们其实不必担心混淆偏差。在这种情境下,要估算一个分组的单元的效果是相对简单的。具体而言,我们只需要对比处理组与未处理组的结果即可。更一般的方法是在该群体内运行一个简单的 对
的回归:
根据简单线性回归的理论,你知道:
其中 是分组的干预的简单平均,
是分组的结果的简单平均。
curry装饰器
curry装饰器可以创建套用函数:
@curry def addN(x, N): return x+N ad5 = addN(N=5) ad13 = addN(N=13)print(ad5(5))
>>> 10print(ad13(5))
>>> 18
要对估算一元回归的斜率参数的过程进行编码,你可以使用curry装饰器。当你需要创建只接受数据框作为唯一参数的函数时,它非常有用:
from toolz import curry
@curry
def effect(data, y, t):
return (np.sum((data[t] - data[t].mean())*data[y]) /
np.sum((data[t] - data[t].mean())**2))
将此函数应用于整个测试集将得到ATE:
effect(test, "sales", "discounts")
32.16196368039615
但是,这并不是你真正想要的。你真正想要知道的是,你刚刚拟合的模型是否能在数据中创建分区,将单元区分为对干预更敏感的和不那么敏感的。为此,你可以根据模型的预测分位数来分段数据,并估算每个分位数的效果。如果每个分位数的估算效果是有序的,你就知道模型也能很好地对真实的CATE进行排序。
响应曲线的形状
在这里,效果被定义为
对
回归的估算斜率。如果你认为这不是一个好的效果指标,你可以选择其他的。例如,如果你认为响应函数是凸的(concave),你可以将效果定义为
或
的回归斜率。如果你的结果是二元的,那么使用逻辑回归的参数估算可能比线性回归更有意义。这里的关键在于,如果
让我们编写一个函数来计算分位数的效果。首先使用pd.qcut将数据按照q个分位数(默认为10)进行分段。我使用pd.IntervalIndex来包装它,以提取pd.qcut返回的每个组的中点。四舍五入只是为了让结果看起来更整洁。
然后,我在数据中创建了一个包含这些组的列,将它们作为分区对数据进行划分,并估算每个分区的效果。在这最后一步中,我使用了pandas的.apply(…)方法。这个方法需要输入一个以数据框为输入并输出一个数字的函数:f(DataFrame) -> float。这就是你之前创建的effect函数发挥作用的地方。你可以只传递outcome和treatment参数来调用它。这将返回一个套用的effect函数,其中数据框是唯一缺失的参数。.apply(…)方法就是需要这样的函数。
在test_pred数据框中使用这个函数的结果是一个列,其中的索引是你模型预测的分位数,而值则是该分位数上的干预效果:
def effect_by_quantile(df, pred, y, t, q=10):
# makes quantile partitions
groups = np.round(pd.IntervalIndex(pd.qcut(df[pred], q=q)).mid, 2)
return (df
.assign(**{f"{pred}_quantile": groups})
.groupby(f"{pred}_quantile")
# estimate the effect on each quantile
.apply(effect(y=y, t=t)))
effect_by_quantile(test_pred, "cate_pred", y="sales", t="discounts")
cate_pred_quantile
17.50 20.494153
23.93 24.782101
26.85 27.494156
28.95 28.833993
30.81 29.604257
32.68 32.216500
34.65 35.889459
36.75 36.846889
39.40 39.125449
47.36 44.272549
dtype: float64
请注意,第一个分位数上的估算效果低于第二个分位数的估算效果,第二个分位数上的估算效果又低于第三个分位数的估算效果,以此类推。这证明了你的CATE预测确实是对效果进行了排序:预测值较低的日期对折扣的敏感度也较低,反之亦然。此外,每个分位数的中点预测值(前一列中的指数)与同一分位数的估算效果非常接近。这意味着你的CATE模型不仅很好地对真实的CATE进行了排序,而且还成功地对其进行了预测。换句话说,你有一个针对CATE的校准模型。
接下来,为了与其他模型进行比较,你可以应用相同的函数,但传入预测性ML模型和随机模型。下面的图表显示了之前定义的三个模型按分位数的效果:
import warnings
warnings.filterwarnings("ignore")
fig, axs = plt.subplots(1, 3, sharey=True, figsize=(15, 4))
for m, ax in zip(["rand_m_pred", "ml_pred", "cate_pred"], axs):
effect_by_quantile(test_pred, m, "sales", "discounts").plot.bar(ax=ax)
ax.set_ylabel("Effect")

首先,来看随机模型(rand_m_pred)。在其每个分区中,它的估算效果大致相同。仅仅通过观察图表,你就可以发现它无法帮助你进行个性化处理,因为它无法区分高折扣敏感度和低折扣敏感度的日期。其所有分区的效果只是ATE。接下来,考虑ML预测模型ml_pred。这个模型更有趣一些。看起来高销售预测和低销售预测的分组都对折扣更敏感。不过,它并没有产生一个排序分数,但你可以利用它进行个性化处理,当销售预测非常高或非常低时,可以提供更多的折扣,因为这些预测值表明处理敏感度很高。
最后,来看看通过回归得到的CATE模型cate_pred。CATE预测值低的分组的确比CATE预测值高的分组有更低的CATE。看起来这个模型能很好地区分高效果和低效果。你可以通过分位数图表的阶梯形状来观察其效果。总的来说,阶梯形状越陡峭,模型在排序CATE方面的表现就越好。
在这个例子中,哪个模型在排序折扣敏感度方面表现更好是一目了然的。但如果你有两个不错的模型,比较可能就不那么明确了。同时,视觉验证虽然不错,但如果你想进行模型选择(如超参数调整或特征选择),就不是理想的方式了。理想情况下,你应该能够用一个数字来概括你的模型的质量。我们会讲到这一点,但在此之前,你首先需要了解累积效果曲线。
6.6 累积效果(Cumulative Effect)
如果你通过分位数图理解了效果,那么接下来这个将非常简单。再一次,我们的想法是利用你的模型来定义分组并估算这些分组内的效果。然而,不同于按组估算效果,你将把一个组累积到另一个组上。
首先,你需要按分数对你的数据进行排序,通常是一个CATE模型,但实际上可以是任何模型。然后,你将根据该排序估算前1%的效果。接下来,你将添加下一个1%,并计算前2%的效果,然后计算前3%的效果,以此类推。结果将是一条按累积样本划分的效果曲线。下面是使用一段简单的代码来实现这一点:
np.set_printoptions(linewidth=80, threshold=10)
def cumulative_effect_curve(dataset, prediction, y, t,
ascending=False, steps=100):
size = len(dataset)
ordered_df = (dataset
.sort_values(prediction, ascending=ascending)
.reset_index(drop=True))
steps = np.linspace(size/steps, size, steps).round(0)
return np.array([effect(ordered_df.query(f"index<={row}"), t=t, y=y)
for row in steps])
cumulative_effect_curve(test_pred, "cate_pred", "sales", "discounts")
array([49.65116279, 49.37712454, 46.20360341, ..., 32.46981935, 32.33428884,
32.16196368])
如果用于排序数据的分数也适用于对真实的CATE进行排序,那么得到的曲线将从非常高的位置开始,逐渐下降到ATE。相比之下,一个糟糕的模型将很快收敛到ATE,或者始终在其周围波动。为了更好地理解这一点,这里是你创建的三个模型的累积效果曲线:
plt.figure(figsize=(10,4))
for m in ["rand_m_pred", "ml_pred", "cate_pred"]:
cumu_effect = cumulative_effect_curve(test_pred, m, "sales", "discounts", steps=100)
x = np.array(range(len(cumu_effect)))
plt.plot(100*(x/x.max()), cumu_effect, label=m)
plt.hlines(effect(test_pred, "sales", "discounts"), 0, 100, linestyles="--", color="black", label="Avg. Effect.")
plt.xlabel("Top %")
plt.ylabel("Cumulative Effect")
plt.title("Cumulative Effect Curve")
plt.legend(fontsize=14)
<matplotlib.legend.Legend at 0x7fcb7b4a8c50>
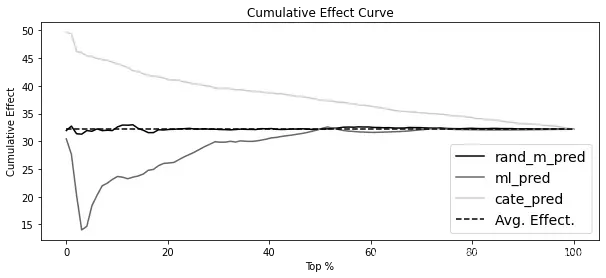
首先,注意到CATE回归模型开始时非常高,并逐渐收敛到ATE。例如,如果你按照这个模型对数据进行排序,前20%的ATE将约为42,前50%的ATE将约为37,而前100%的ATE将是干预的全局效果(ATE)。相比之下,一个只输出随机数的模型将围绕ATE进行变动,而一个逆序排列效果的模型将从低于ATE的地方开始。
排序的不对称性
需要提及的重要一点是,这种排序不是对称的。也就是说,采用一个分数并将其颠倒过来不会简单地使曲线围绕ATE线翻转。
累积效果曲线比按分位数划分的效果曲线更直观一些,因为它可以将效果汇总为一个单一的数字。例如,你可以计算曲线与ATE之间的面积,并用它来比较不同的模型。面积越大,模型就越好。但这样做仍然存在一个缺点。如果你这样做,曲线的起始部分将具有最大的面积。然而,正是由于样本量较小,起始部分的不确定性也最大。幸运的是,有一个非常简单的解决方法:累积增益曲线。
6.7 累积增益(Cumulative Gain)
如果你从累积效果曲线中采用完全相同的逻辑,但是将每个点乘以累积样本 ,就会得到累积增益曲线。现在,尽管曲线的起始部分将具有最高的效果(对于一个好的模型来说),但是它将被较小的相对尺寸所缩小。
从代码的角度来看,所发生的变化是,我现在将效果乘以(row/size)每次迭代。此外,我可以选择通过ATE来标准化这条曲线,这就是为什么我也要从每次迭代的效果中减去一个归一化因子的原因:
def cumulative_gain_curve(df, prediction, y, t,
ascending=False, normalize=False, steps=100):
effect_fn = effect(t=t, y=y)
normalizer = effect_fn(df) if normalize else 0
size = len(df)
ordered_df = (df
.sort_values(prediction, ascending=ascending)
.reset_index(drop=True))
steps = np.linspace(size/steps, size, steps).round(0)
effects = [(effect_fn(ordered_df.query(f"index<={row}"))
-normalizer)*(row/size)
for row in steps]
return np.array([0] + effects)
cumulative_gain_curve(test_pred, "cate_pred", "sales", "discounts")
array([ 0. , 0.50387597, 0.982917 , ..., 31.82346463, 32.00615008,
32.16196368])
另请参阅
如果你不想费心实现所有这些功能,我和我的一些同事一直在开发一个Python库来为你处理这些问题。你可以简单地从fklearn causal模块导入所有的曲线和它们的AUC:
from fklearn.causal.validation.auc import * from fklearn.causal.validation.curves import *
以下图像展示了三个模型的累积增益和标准化累积增益。在这里,就CATE的排序而言,更好的模型是曲线和代表ATE的虚线之间的面积最大的模型:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15,5))
for m in ["rand_m_pred", "ml_pred", "cate_pred"]:
cumu_gain = cumulative_gain_curve(test_pred, m, "sales", "discounts")
x = np.array(range(len(cumu_gain)))
ax1.plot(100*(x/x.max()), cumu_gain, label=m)
ax1.plot([0, 100], [0, effect(test_pred, "sales", "discounts")], linestyle="--", label="Random Model", color="black")
ax1.set_xlabel("Top %")
ax1.set_ylabel("Cumulative Gain")
ax1.set_title("Cumulative Gain Curve")
ax1.legend()
for m in ["rand_m_pred", "ml_pred", "cate_pred"]:
cumu_gain = cumulative_gain_curve(test_pred, m, "sales", "discounts", normalize=True)
x = np.array(range(len(cumu_gain)))
ax2.plot(100*(x/x.max()), cumu_gain, label=m)
ax2.hlines(0, 0, 100, linestyle="--", label="Random Model", color="black")
ax2.set_xlabel("Top %")
ax2.set_ylabel("Cumulative Gain")
ax2.set_title("Cumulative Gain Curve (Normalized)")
Text(0.5, 1.0, 'Cumulative Gain Curve (Normalized)')
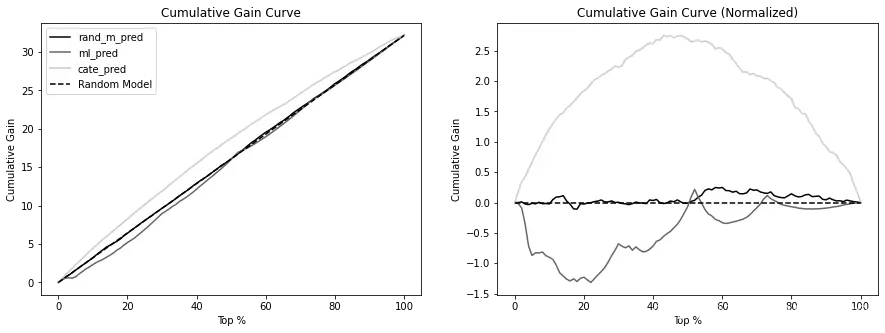
为了将模型性能总结为一个数字,你可以简单地对标准化累积增益曲线的值进行求和。在排序CATE方面,值最大的模型将是最好的模型。以下是到目前为止你评估的三个模型的曲线下面积(AUC)。请注意,ML模型的面积为负,因为它反转了CATE的顺序:
for m in ["rand_m_pred", "ml_pred", "cate_pred"]:
gain = cumulative_gain_curve(test_pred, m,
"sales", "discounts", normalize=True)
print(f"AUC for {m}:", sum(gain))
AUC for rand_m_pred: 6.0745233598544495
AUC for ml_pred: -45.44063124684
AUC for cate_pred: 181.74573239200615
同样地,将模型性能浓缩为一个数字是非常有用的,因为它允许自动化模型选择。然而,尽管我很喜欢这条最后的曲线,但在使用它们时还是需要注意一些问题。
首先,在你看到的所有曲线中,重要的是要记住这条曲线上的每一个点都是一个估算值,而不是真实值。它是对特定组(有时是非常小的组)的回归斜率的估计。既然是回归估算,它就取决于T和Y之间的关系是否被正确指定。即使采用随机化方法,如果处理与结果之间的关系是一个对数函数,那么将效应估计为线性函数就会导致错误的结果。如果你知道处理响应函数的形状,你可以将你的效应函数调整为ylog(t)的斜率,而不是yt。但你需要知道正确的形状才能做到这一点。
其次,这些曲线并不真正关心你是否得到了正确的CATE。它们只关心排序是否正确。例如,如果你从你的模型中取出任何一个,并从它们的预测中减去1000,它们的累积增益曲线将保持不变。因此,即使你对CATE的估计有偏,这种偏差也不会出现在这些曲线中。现在,这可能不是问题,如果你只关心优先处理的话。在这种情况下,排序就足够了。但如果你确实关心精确估算CATE,这些曲线可能会产生误导。如果你来自数据科学背景,你可以在累积增益曲线和ROC曲线之间画一条平行线。同样,具有良好ROC-AUC的模型也不一定会被校准。
另请参阅
这里展示的所有曲线都是试图将传统上用于uplift建模的曲线进行推广,其中干预是二元的。如果想要查阅相关文献,我推荐Pierre Gutierrez和Jean-Yves Gérardy的论文《因果推断和Uplift建模:文献综述》(Causal Inference and Uplift Modeling a Review of the Literature),以及Divyat Mahajan等人的论文《异质因果效应估算的模型选择的实证分析》(Empirical Analysis of Model Selection for Heterogeneous Causal Effect Estimation)。
因果模型的评估是一个仍在发展中的研究领域。因此,它仍然存在许多盲点。例如,到目前为止,所呈现的曲线只能告诉你模型在排序CATE方面的优劣。我还没有找到一个好的解决方案来检查你的模型是否正确预测了CATE。我喜欢做的一件事是使用分位数图的效果与累积增益曲线一起,因为第一个给了我一些关于模型校准程度的想法,而第二个给了我一些关于它如何对CATE进行排序的想法。至于归一化累积增益,它只是一个缩放,使可视化更容易。
但我必须承认,这并不理想。如果你正在寻找像 或MSE这样的汇总指标(这两者都常用于预测模型),我很遗憾地说,在因果建模世界中,我还没有找到与它们相匹配的良好并行指标。然而,我确实找到了目标转化这一方法。
6.8 目标转化(Target Transformation)
结果表明,尽管你不能观测到真正的干预效果 ,但你可以创建一个目标变量,期望值近似干预效果:
其中 是结果的模型,
是处理的模型。这个目标很有趣,因为
。注意,它看起来很像回归系数的公式,分子是
和
之间的协方差,分母是
的方差。然而,它不是使用期望值来定义它们,而是在单元级别进行计算。
由于这个目标接近真正的处理效果,你可以使用它来计算偏差度量,如均方误差(MSE)。如果你的 CATE 模型在预测个体水平效应 方面表现良好,那么这个目标预测的均方误差应该很小。
然而,这里有一个问题。当接近处理平均值时,这个目标会非常嘈杂,分母将趋于零。为了解决这个问题,你可以应用权重,分配低重要性的点到 较小的地方。例如,你可以通过
对单元进行加权。
R损失伏笔
使用这些权重有一个很好的理论原因。当我们在第七章讨论非参数双重去偏机器学习/去偏机器学习时,你会学到更多关于它的知识。现在,你只能顺着我的思路走。
要对这个目标进行编码,可以简单地将结果和干预模型的残差相除:
X = ["C(month)", "C(weekday)", "is_holiday", "competitors_price"]
y_res = smf.ols(f"sales ~ {'+'.join(X)}", data=test).fit().resid
t_res = smf.ols(f"discounts ~ {'+'.join(X)}", data=test).fit().resid
tau_hat = y_res/t_res
接下来,你可以使用它来计算所有模型的MSE。注意我是如何像前面讨论的那样使用权重的:
from sklearn.metrics import mean_squared_error
for m in ["rand_m_pred", "ml_pred", "cate_pred"]:
wmse = mean_squared_error(tau_hat, test_pred[m],
sample_weight=t_res**2)
print(f"MSE for {m}:", wmse)
MSE for rand_m_pred: 1115.803515760459
MSE for ml_pred: 576256.7425385397
MSE for cate_pred: 42.90447405550281
根据这个加权的均方误差,再次证明,用于估算CATE的回归模型比其他两个模型表现更好。同时,这里还有一个有趣的现象。ML模型的表现比随机模型更差。这并不奇怪,因为ML模型试图预测的是 而不是
。
另请参阅
就像我之前说的,评估因果模型的文献仍然处于起步阶段。这是一个相当令人兴奋的问题,新的方法正在不断被提出。例如,在论文“基于因果推断的智能消费贷款信用限额管理”中,来自蚂蚁金服集团的科学家们提出了将单元分组,每组具有相似的协变量(他们使用了超过6000组!),假设结果是处理效应加上一些高斯随机噪声 $\widehat {y_i}=\widehat {\tau}(x_i) +e_i,计算每个组的结果均方误差 $N^{-1}\sum{(y_i-\widehat {y_i})},并使用每组的样本量平均结果。
只有当效应与结果相关时,预测 在排序或预测
方面才会表现良好。这通常不会发生,但有些情况下可能会发生。其中一些情况在商业中相当常见,因此值得一看。
6.9 当预测模型对效果排序有益
就像我之前所说,要让一个预测 的模型也能很好地对CATE进行排序,就必须是
和CATE
之间也存在相关性的情况。例如,在寻找顾客对餐厅折扣更敏感的日期的背景下,如果销售高的日期与人们对折扣更敏感的日期相吻合,那么一个预测
的模型也将能够很好地对
对
的效果进行排序。更一般地说,当干预响应函数是非线性时,这种情况就可能发生。
6.9.1 边际递减收益(Marginal Decreasing Returns)
当干预响应函数是凸函数时,干预每增加一个单位将产生越来越小的影响。这是商业中非常常见的现象,因为事物往往有一个饱和点。例如,即使你将折扣设置为100%,销售量也只能达到这么高,因为有各种因素限制了你的生产量。或者,你的营销预算的效果最终将趋于平稳,因为你只能向这么多顾客做广告。
一个边际递减的干预响应函数看起来像这样:
np.random.seed(123)
n = 1000
t = np.random.uniform(1, 30, size=n)
y = np.random.normal(10+3*np.log(t), size=n)
plt.figure(figsize=(10,4))
plt.scatter(t, y)
plt.ylabel("Y")
plt.xlabel("T")
Text(0.5, 0, 'T')
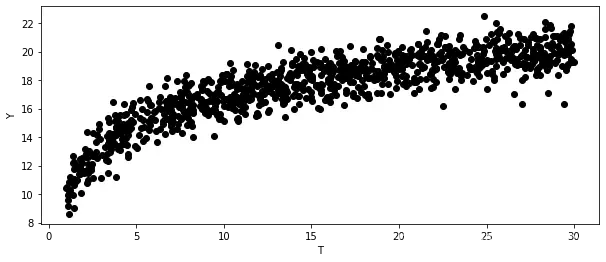
在这种情况下,很容易明白为什么一个擅长预测结果 的模型也会擅长排列CATE:结果越高,效果越低。因此,如果你采用这个预测
的模型,并按照这些预测的倒序来排列你的单元,你很可能会得到一个不错的CATE排序。
6.9.2 二元结果
当结果是二元的时候,预测 的模型同样适用于排序CATE,这是另一种常见的情况。在这种情况下,
呈现出S形状,在0和1之间趋于平稳:
np.random.seed(123)
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(15, 5))
n = 10000
t = np.random.uniform(1, 30, size=n).round(1)
y = (np.random.normal(t, 5, size=n) > 15).astype(int)
df_sim = pd.DataFrame(dict(t=t, y=y)).groupby("t")["y"].mean().reset_index()
df_sim
ax1.scatter(df_sim["t"], df_sim["y"])
ax1.set_ylabel("Y")
ax1.set_xlabel("T")
n = 10000
t = np.random.exponential(1, n).round(1).clip(0, 8)
y = (np.random.normal(t, 2, size=n) > 6).astype(int)
df_sim = (pd.DataFrame(dict(t=t, y=y, size=1))
.query("t<6")
.groupby("t")
.agg({"y":"mean", "size":"sum"})
.reset_index())
sns.scatterplot(data=df_sim, y="y", x="t", size="size", ax=ax2, sizes=(5,100))
ax2.set_ylabel("Default Prob.")
ax2.set_xlabel("Loan (in 100k)")
n = 10000
t = np.random.beta(2, 2, n).round(2)*10
y = (np.random.normal(5+t, 4, size=n) > 0).astype(int)
df_sim = (pd.DataFrame(dict(t=t, y=y, size=1))
.groupby("t")
.agg({"y":"mean", "size":"sum"})
.reset_index())
sns.scatterplot(data=df_sim, y="y", x="t", size="size", ax=ax3, sizes=(5,100))
ax3.set_ylabel("Conversion")
ax3.set_xlabel("Discount (%)")
plt.tight_layout()
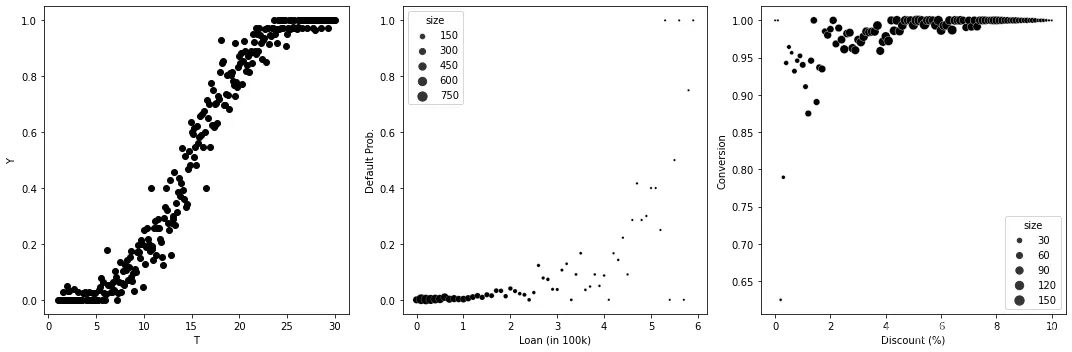
在大多数商业应用中,数据将集中在这个S形函数的左端或右端。例如,在银行业,只有一小部分客户会拖欠贷款,这意味着你的数据大多位于这个曲线的左端,看起来是指数型的。因此,如果你有一个预测客户拖欠贷款的模型,那么预测值较高的客户很有可能对干预更敏感。直观地说,这些客户接近于不拖欠和拖欠之间的临界点。对他们来说,干预的微小变化可能会造成截然不同的结果。
相反,假设你在一家在线购物公司工作,大部分进入你网站的客户都会购买商品(转化)。在这种情况下,你的数据更多位于S形曲线的右端。因此,如果你有一个预测转化率的模型,那么这个模型很有可能也可以用来排序折扣等干预措施的效果。转化率越高,效果大小越低。那是因为在右端,S曲线看起来有点像你之前看到的边际收益递减的情况。
一般来说,当结果是二元的时候,越接近中间,即 ,效果就越高。
疫苗优先性
你看到了二元结果是如何导致干预响应函数非线性的,这允许你利用结果的预测值来分配干预。这一原则的一个非常有趣的应用出现在COVID-19大流行期间。2021年,世界成功地向公众提供了第一批经批准的COVID-19疫苗。当时,一个关键的问题是谁应该先接种疫苗。毫无疑问,这是一个异质性的处理效果问题。政策制定者希望首先给那些受益最大的人接种疫苗。在这种情况下,处理效果是避免死亡或住院。那么,在给了一针疫苗后,谁的死亡或住院率下降得最多?在大多数国家,他们是老年人和那些有既往健康状况(合并症)的人。现在,这些人在感染COVID-19时更有可能死亡。此外,值得庆幸的是,COVID-19的死亡率远低于50%,这使得你处于逻辑函数的左侧。在这个区域,根据我们对违约率的相同背景,治疗那些感染COVID-19时具有高基线死亡概率的人是有意义的,这恰恰是前面提到的群体。这是巧合吗?也许吧。请记住,我不是健康专家,所以我在这里可能是完全错误的。但这个逻辑对我来说很有意义。
当干预响应函数是非线性时,就像在二元结果中或在结果略微减少的情况下,预测模型可能会产生CATE的良好排序。然而,这并不意味着它将是最好的模型,也不意味着它不能被一个旨在直接预测CATE的模型所超越。此外,尽管这样的模型可能对处理效应进行排序,但它并不能预测处理效应。如果你只关心根据单元对处理的敏感性对其进行排序,那么这是可以的。但如果你的决策取决于正确估算CATE,那么就需要进行额外的分组估算。
另请参阅
有时,结果预测可能比CATE预测表现更好,因为CATE往往非常嘈杂。Fernández-Loría和Provost在他们的论文《因果分类:干预效果估算与结果预测》(Causal Classification: Treatment Effect Estimation vs. Outcome Prediction)中进一步讨论了这一点。
说到这个,我认为值得阐明如何使用CATE进行决策。你可能已经有一个很好的方法来做到这一点,但也许我有一些你没有想过的建议。
6.10 CATE用于决策
当干预是二元的时候,决策过程非常直接。你主要关心的是谁对干预有积极反应。如果您的干预供应无限,那么你要做的就是对所有CATE为正的人进行干预。如果你没有一个预测CATE的模型,但是有一个能对其进行排序的模型,就像上一节讨论的预测模型那样,可以使用按模型分位数绘制的效果图。只需按模型的分位数划分你的数据,估算每个分位数上的干预效果,然后对所有人进行干预,直到效果仍然为正。
如果你的干预供应不是无限的,那么需要添加第二条规则。将只对那些有积极效果的人以及CATE最高的人进行干预。例如,如果你只有1000个干预单元,那么你可能想要根据某个CATE排序模型对前1000个单元进行干预,前提是它们都有积极的效果。
如果干预是连续的或有序的,事情就会变得更复杂一些。你现在不仅要决定要干预谁,还要决定要干预多少。这与具体的业务密切相关。每个问题都有自己的干预响应函数需要优化。这意味着我无法为你提供非常详细的指导方针,但我可以带你了解一个典型的例子。
再来考虑决定餐厅连锁店每天打多少折扣的问题。由于决定提供多少折扣只是决定收取多少价格()的另一种方式,让我们将这个问题重新构述为价格优化问题。在所有商业问题中,都存在成本(即使不是货币)和收入函数。假设餐厅的收入由以下方程给出:
第 天的收入只是价格乘以餐厅所提供的餐食数量(需求)。然而,人们愿意在特定一天购买的餐食数量与当天收取的价格成反比。也就是说,它有一个组件
,其中
是客户当天对价格上涨的敏感度(请注意,这取决于日期特定的特征
)。换句话说,这种敏感度是价格对需求的条件平均干预效应。
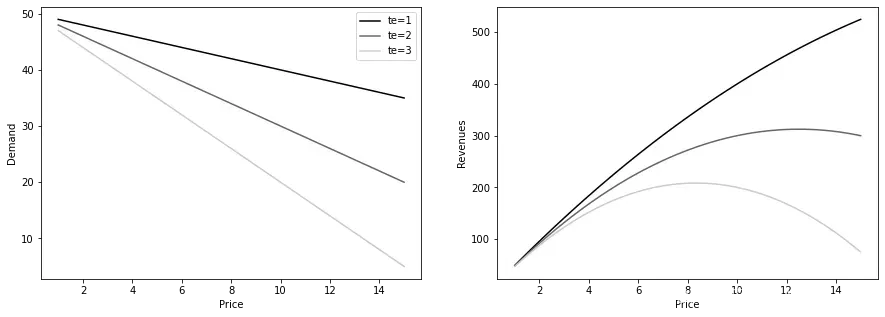
如果你为不同的 值绘制需求曲线,你会看到
只不过是需求曲线的斜率。如果你将需求曲线与收入曲线相乘,你会得到一个二次形状。在这条曲线上,客户对价格敏感度最低的那一天(
)会在后续的价格值上达到峰值:
def demand(price, tau):
return 50-tau*price
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
prices = np.linspace(1, 15)
for i, tau in enumerate([1, 2, 3]):
q = demand(prices, tau)
ax1.plot(prices, q, color=f"C{i}", label=f"te={tau}")
ax2.plot(prices, q*prices, color=f"C{i}", label=f"te={tau}")
ax1.set_ylabel("Demand")
ax1.set_xlabel("Price")
ax2.set_ylabel("Revenues")
ax2.set_xlabel("Price")
ax1.legend()
<matplotlib.legend.Legend at 0x7fcb8a3fe490>
接下来,假设你花费3美元来制作你的餐品。这意味着成本仅仅是你生产的数量 乘以3:
请记住,成本方程并不直接取决于干预效果,但如果你回顾一下,生产数量仅仅是客户订单的数量(即需求),那么,价格越高,成本越低,因为客户会需求更少的餐品。
最后,一旦你有了收入和成本,你可以将它们组合起来,将利润作为价格的函数:
如果你根据不同的 值绘制价格与利润的关系图,你会发现每个值都会产生不同的最优价格。
越低,客户对价格上涨的敏感度就越低,这允许餐厅提高价格以获得更多的利润:
def cost(q):
return q*3
def profit(price, tau):
q = demand(price, tau)
return q*price - cost(q)
prices = np.linspace(1, 30)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
for i, tau in enumerate([1, 2, 3]):
profits = profit(prices, tau)
max_price = prices[np.argmax(profits)]
ax1.plot(prices, cost(demand(prices, tau)), label=f"te={tau}")
ax2.plot(prices, profits, color=f"C{i}", label=f"te={tau}")
ax2.vlines(max_price, 0, max(profits), color=f"C{i}", linestyle="--")
ax2.set_ylim(-400, 600)
ax2.hlines(0, 0, max(prices), color="black")
# ax2.legend()
ax2.set_ylabel("Profits")
ax2.set_xlabel("Price");
ax1.legend()
ax1.set_ylabel("Cost")
ax1.set_xlabel("Price")
plt.tight_layout()
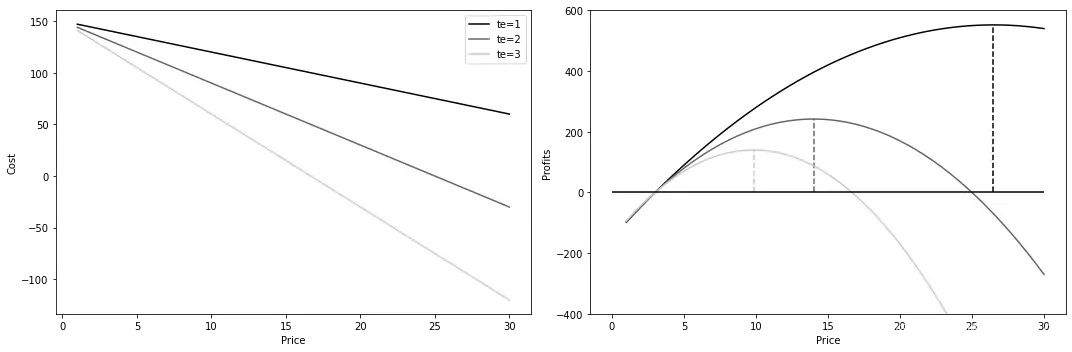
经济学家们很快就会意识到,这就是著名的企业问题。将边际成本设定为等于边际收益,并单独确定价格,就可以得出利润最大化的价格的数值解:
请注意,在这种情况下,唯一未知的是价格对需求的影响,即 。因此,如果你可以使用预测CATE的模型来估计它,你就可以将那个CATE预测转换为最优价格。
同样,这在很大程度上取决于收入和成本曲线的形式,而后者又在很大程度上取决于你的业务。但是,一般来说,几乎任何你想要优化的干预措施都有好的一面——在这个例子中就是收入,也有不利的一面——在这个例子中就是成本。要使用CATE来决定连续干预的水平,你必须了解它如何影响这两个方面。
角解(Corner Solution)
在某些罕见的情况下,优化业务的干预水平根本不存在,或是达到了最大允许水平。例如,假设你所在地的政府为你所销售的产品设定了价格上限,而这个上限低于能够最大化你利润的价格。在这种情况下,最佳价格简直就是政府所允许的最高价格。然而,这种情况很罕见。在大多数情况下,角落解决方案会在隐藏价格未被考虑时出现。举例来说,假如你在尝试优化交叉销售的电子邮件,你可能会认为发送电子邮件的成本微不足道,因此你应该继续发送给所有人。但我会反驳说,你没有考虑到客户注意力方面的成本:如果你向客户发送垃圾邮件,他们最终会对你感到厌倦并取消订阅你的电子邮件,这将使你损失未来通过电子邮件渠道进行的销售。这些隐藏的成本更难考虑,但这并不意味着它们不存在。事实上,为这些成本找到良好的代表往往是一项无价的数据科学任务。
6.11 要点总结
本章介绍了处理异质性的概念。关键在于,每个单元i可能会有不同的处理效应 。如果你知道这个效应,你可以利用它更好地在单元之间分配处理。遗憾的是,由于因果推断的根本问题,这个效应是无法观测的。然而,如果你假设它取决于单元的可观测特征,
,那么你就可以取得一些进展;也就是说,你可以从估算平均处理效应进展到估算条件平均干预效果(CATE):
因此,即使处理效应在单元层面没有被观测到,你仍然可以估算分组效果。一种简单的方法是使用线性回归,包含处理和协变量之间的交互项:
估算这个模型将会得到下述的CATE估算值:
接下来,你看到了一些关于如何将交叉验证与CATE评估技术配对以评估CATE估算值的方法。由于CATE不是针对单个单元定义的,所以你必须依赖特定分组的度量,比如分位数曲线效应或累积增益曲线。如果这还不够,你还可以定义一个目标,它接近个体层面的处理效应,并用它来计算偏差度量,比如均方误差MSE。
最后,值得强调的是,本章所讨论的所有内容都基于一个事实,即CATE(一种因果数量)可以从条件期望(一种可通过数据恢复的统计数量)中识别出来:
如果没有这一点,CATE作为你可以估算的分组效果的想法就不再成立,这就是为什么随机化数据对CATE估算问题如此重要,即使只是为了评估你的干预异质性模型。
系列文章专栏:
使用Python进行因果推断(Causal Inference in Python)
第1章 因果推断导论
第2章 随机实验与统计学回顾
第3章 图形化因果模型
第4章 线性回归的不合理有效性
第5章 倾向分
第6章 效果异质性
第7章 元学习器
第8章 双重差分
持续更新中:
第9章 综合控制
第10章 Geo实验与Switchback实验
第11章 不依从性与工具
第12章 后续行动
【参考】
原版书籍《Causal Inference in Python: Applying Causal Inference in the Tech Industry》
原书github代码
文章出处登录后可见!