🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 – 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
根据这些评估指标检查机器学习模型的准确性和性能。
构建机器学习模型不是一次性的。您可能不知道构建的模型是否有效,或者如果有效,它是否按预期工作。构建此类模型的工作原理是从指标中获取反馈,实施正确的改进,然后重建以达到理想的准确度。
然而,选择正确的指标来评估模型的性能和准确性本身就是一项任务。因此,在完成预测、分类或回归模型后,这里有一个评估指标列表,可以帮助您测试模型的准确性和具体性。
混淆矩阵
简单来说,它是一个用于二元分类的 2×2 大小的矩阵,一个轴由实际值组成,另一个轴由预测值组成。矩阵的大小可以根据预测的类别数量增加。 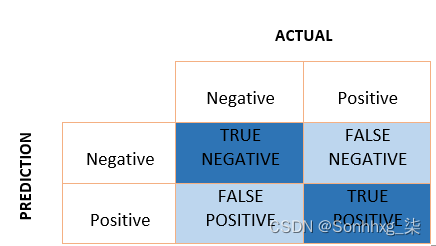
True Positive 是模型正确的阳性预测。
True Negative是模型正确的负预测。
False Positive是模型对阳性的错误预测。
False Negative是模型对阴性的错误预测。
使用这些值,我们可以通过一个简单的方程式计算每个预测类别的比率。
分类准确率
最简单的指标,它是通过将正确预测的数量除以预测总数,再乘以 100来计算的。
![]()
精密度/特异性
如果类分布不平衡,分类准确率就不是模型性能的最佳指标。为了解决特定于类别的问题,我们需要一个精度指标,该指标由真阳性除以真阳性和假阳性之和计算得出。
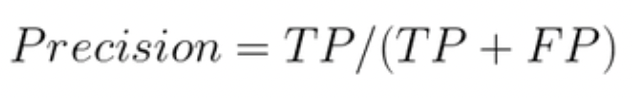
召回/灵敏度
召回率是模型正确预测的一类样本的分数。它的计算方法是真阳性除以真阳性和假阴性之和。
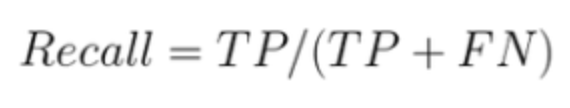
F1分数
现在我们知道分类问题的准确率和召回率是什么,同时计算两者——F1,两者的调和平均值,它在不平衡数据集上也表现良好。
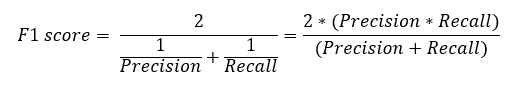
如上面的等式所示,F1 分数对召回率和准确率都给予了同样的重视。如果我们想给其中一个赋予更多的权重,可以通过将一个值附加到召回率或精度上来计算 F1 分数,具体取决于该值的重要性倍数。在下面的等式中,β 是权重。
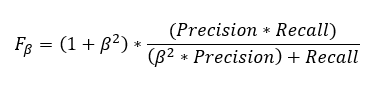
AUC-ROC
曲线下面积 (AUC) 与响应者比例的变化无关。当我们得到一个混淆矩阵,它为概率模型中的每个指标产生不同的值时,即,当每次召回(灵敏度)时,我们得到不同的精度(特异性)值——我们可以绘制接受者操作特征(ROC)曲线和找到曲线下的区域,如下所示。 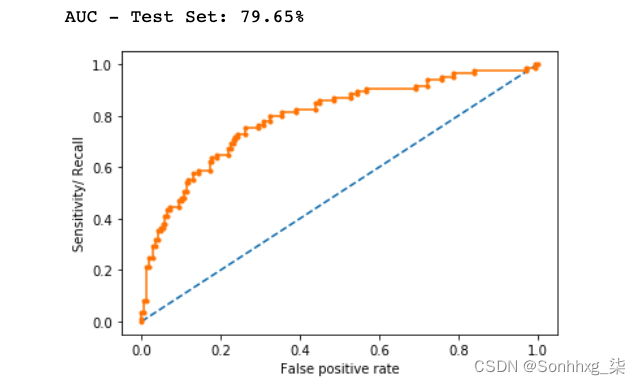
由于面积是在轴之间计算的,因此它总是介于 0 和 1 之间。它越接近 1,模型越好。
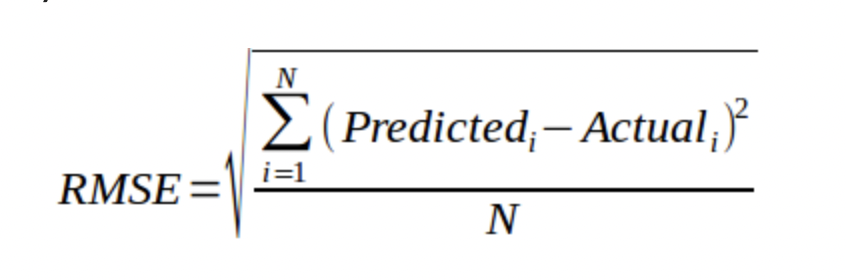
均方根误差 (RMSE)
作为回归问题中最常用的指标之一,RMSE 假设发生的错误是无偏的并且服从正态分布。样本数量越多,通过 RMSE 重构误差分布就越可靠。度量的方程由下式给出:
交叉熵损失
也称为“对数损失”,交叉熵损失在深度神经网络中很有名,因为它克服了梯度消失问题。它是通过对错误分类的数据点的预测概率分布的对数求和来计算的。
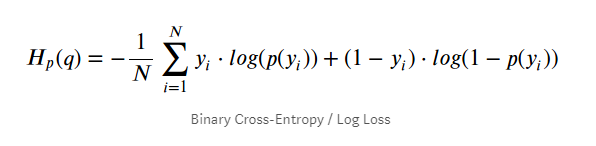
基尼系数
用于分类问题,基尼系数源自 AUC – ROC 数。它是 ROC 曲线与对角线之间的比率。如果基尼系数高于 60%,则该模型被认为是好的。用于此的公式是:
Gini = 2*AUC – 1
杰卡分数
Jaccard 分数是衡量两组数据之间的相似性指标。分数是在 0 和 1 之间计算的,1 是最好的。为了计算 Jaccard 分数,我们找到两个集合中的观察总数,然后除以任一集合中的观察总数。
J(A, B) = |A∩B| / |A∪B|
文章出处登录后可见!