LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation (SIGIR’20)
论文链接:https://dl.acm.org/doi/pdf/10.1145/3397271.3401063
论文背景/动机
图卷积网络(Graph Convolution Network,GCN)已经被广泛地应用于推荐系统。然而先前基于GCN进行协同过滤的工作(例如NGCF)缺少对GCN的消融研究。作者指出GCN最初被设计用于图上的节点分类任务,并且GCN的特征转换与非线性激活过程并不适用于协同过滤。基于此,作者在标准的GCN的基础上针对推荐任务进行了简化,提出了轻量级图卷积网络(LightGCN)。
方法
LightGCN是一个端到端的图推荐模型,其模型框架图如下图所示(该图中输入部分被忽略)。具体来说,与先前的工作类似,LightGCN可以分为三个部分,即嵌入层、轻量级嵌入传播层和预测层。

嵌入层
嵌入层的主要作用是构造用户和物品的低维嵌入表示(embedding representation),这样的向量通常包含了用户和物品的信息,再没有先验知识输入的情况下通常以随机初始化的方式构造。给定用户u和物品i,其对应的嵌入表示分别为![]() 和
和![]() 。这样的嵌入表示通常具有
。这样的嵌入表示通常具有![]() 维,并且以端到端的方式进行优化。在一个名
维,并且以端到端的方式进行优化。在一个名![]() 用户和
用户和![]() 个物品的推荐场景中,完整的嵌入表被定义为:
个物品的推荐场景中,完整的嵌入表被定义为:

轻量级嵌入传播层
GCN的基本思想是通过平滑节点的特征来学习节点的嵌入表现,这一过程通过迭代地执行图卷积操作来实现。每一次迭代过程中,中心节点聚合来自所有邻域节点的特征,以此更新中心节点的嵌入表示,即:

其中每个嵌入表示的上标表示该嵌入是通过第几个嵌入传播层得到的。作者认为传统的GCN中的特征转换和非线性激活过程对于协同过滤而言是不必要的。为了验证这一点,作者进行了一系列的消融实验,作者提出了NGCF的三个变体,即分别移除了NGCF模型中的特征转换矩阵(命名为NGCF-n)、非线性激活函数(命名为NGCF-f)和将特征转换和非线性激活过程一起移除(命名为NGCF-fn),随后在两个推荐数据集Gowalla和Amazon-Book上进行了对比实验:

从图中可以看出移除特征转换矩阵和非线性激活函数后,NGCF的性能和训练效率有个明显的提升。基于此,作者指出GCN最初应用于半监督的节点分类任务,该类任务中的节点具有丰富的语义特征信息,然而在协同过滤任务中,用户-物品交互二部图中的用户和物品节点只有id编码信息。在这种情况下,执行非线性转换不仅不能提供更好的训练效果,而且会严重阻碍推荐模型想训练。NGCF的次优表现源于训练的困难,而不是过拟合。
基于这一启发,作者提出了轻量级图卷积(Light Graph Convolution,LGC),其核心思想是只保留图卷积的信息传递与平均聚合过程,而摈弃冗余的特征转换、非线性激活过程,其定义如下:

该公式中的对称归一化项来自于标准的GCN设计,其可以有效地避免嵌入表示的量级随着图卷积运算而变大。需要指出的是,LGC只包含邻居节点向中心节点的信息传递与聚合过程,而不包括节点的自连接,这与大多数图卷积网络的设计都不同。
预测层
通过堆叠多个轻量级嵌入传播层,可以分别得到多个用户和物品的嵌入表示。不同层的嵌入表示携带着不同的语义信息。作者选择带权聚合的方式构造最终的用户和物品嵌入表示:

其中![]() 用于调解每一层嵌入表示对于最终嵌入表示的重要程度。为了减少模型参数,作者将其简单地设为
用于调解每一层嵌入表示对于最终嵌入表示的重要程度。为了减少模型参数,作者将其简单地设为![]() ,即所有层的权重均相同,从而减少了手动调参的次数。同时作者指出,
,即所有层的权重均相同,从而减少了手动调参的次数。同时作者指出,![]() 可以设置专门的注意力机制进行学习。此外,将多层的嵌入表示进行聚合可以有效地缓解过平滑(over-smooth)现象。
可以设置专门的注意力机制进行学习。此外,将多层的嵌入表示进行聚合可以有效地缓解过平滑(over-smooth)现象。
在得到所有用户和物品的嵌入表示之后,作者采用内积构造用户对物品的预测分数:

矩阵形式
为了更清晰地了解LightGCN的训练过程,作者给出了LightGCN的矩阵形式。具体来说,用户-物品的交互矩阵用R表示,则用户-物品交互二部图的邻接矩阵被定义为:

则轻量级图卷积过程的矩阵形式可以被定义为:

其中D是对角度矩阵,其计算邻接矩阵A中每一行非零元素的个数。交互矩阵R、邻接矩阵A和对角度矩阵D的关系如下图所示:

考虑到图卷积的迭代特性,最终嵌入表示的构造过程可以展开:

其中

模型训练
与先前的工作保持一致,LightGCN采用贝叶斯个性化排序损失(Bayesian Personalized Ranking,BPR)优化模型:

其中![]() 用于控制正则化强度。BPR是一种成对化损失,其假设正样本的预测分数应该大于负样本。LightGCN使用Adam优化器,并采用mini-batch的方式进行训练(即每个epoch中将所有训练数据划分为多个batch,随后依次在每个batch上进行训练和反向更新)。考虑到LightGCN的简易性,作者没有为其引用额外的dropout机制。
用于控制正则化强度。BPR是一种成对化损失,其假设正样本的预测分数应该大于负样本。LightGCN使用Adam优化器,并采用mini-batch的方式进行训练(即每个epoch中将所有训练数据划分为多个batch,随后依次在每个batch上进行训练和反向更新)。考虑到LightGCN的简易性,作者没有为其引用额外的dropout机制。
实验
为了验证所提出的LightGCN的有效性,作者在以下三个大规模数据集上进行对比实验:
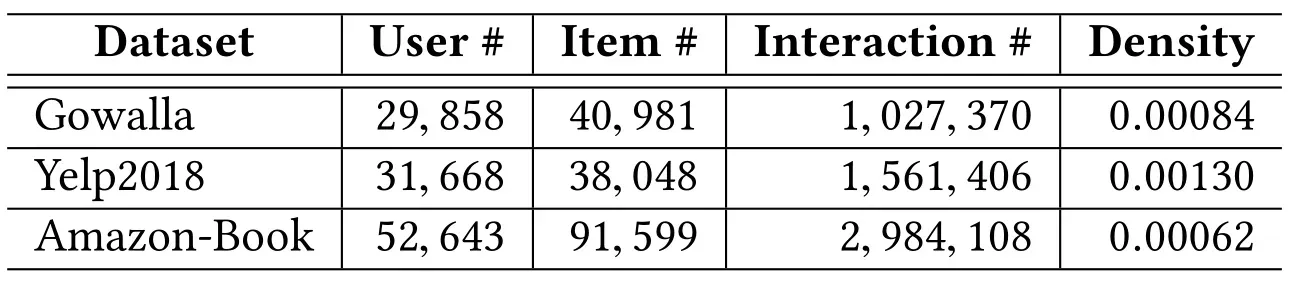
LightGCN主要与NGCF进行对比,从下表可以看出LightGCN的性能有了明显的提升,这也验证了作者的设想,即特征转换和非线性激活对于推荐任务是冗余的。

另一个值得关注的实验是层结合(Layer Combination),在该实验中,作者设置了一个变体,LightGCN-single,该模型只将最后一个图卷积层的嵌入表示作为用户和物品的最终嵌入表示,实验结果如下图所示:

一个有趣的现象是并非所有情况下LightGCN的性能都优于LightGCN-single,这一现象在Amazon-Book和Yelp2018数据集上尤为明显,这表明带权求和的层结合机制并不是最优方案。
代码实现
LightGCN的官方开源代码链接如下:
TensorFlow 1版本:https://github.com/kuandeng/LightGCN
Pytorch版本:https://github.com/gusye1234/pytorch-light-gcn
以Pytorch版本为例,简要介绍LightGCN的具体实现中的核心部分:
邻接矩阵构造
LightGCN的核心操作即轻量级图卷积(LGC)操作,该操作依赖输入图的邻接矩阵以及进一步计算得到的图拉普拉斯矩阵,相关代码如下:
adjacency_matrix = sp.dok_matrix((self.num_nodes, self.num_nodes), dtype=np.float32)
adjacency_matrix = adjacency_matrix.tolil()
R = self.user_item_net.todok()
adjacency_matrix[:self.num_users, self.num_users:] = R
adjacency_matrix[self.num_users:, :self.num_users] = R.T
'''
[ 0 R]
[R.T 0]
'''
adjacency_matrix = adjacency_matrix.todok()
row_sum = np.array(adjacency_matrix.sum(axis=1))
d_inv = np.power(row_sum, -0.5).flatten()
d_inv[np.isinf(d_inv)] = 0.
degree_matrix = sp.diags(d_inv)
# D^(-1/2) A D^(-1/2)
norm_adjacency = degree_matrix.dot(adjacency_matrix).dot(degree_matrix).tocsr()
sp.save_npz(self.path + '/pre_adj_mat.npz', norm_adjacency)以上代码完整地描述了邻接矩阵以及对应的图拉普拉斯矩阵的计算过程。具体来说,self.num_nodes表示用户-物品交互图中的所有节点数(用户节点数+物品节点数),邻接矩阵A以字典形式的dok_matrix进行构造,随后将用户-物品交互矩阵置入邻接矩阵对应的位置(参见7~9行的注释)。
构造完成邻接矩阵后,随后开始计算对角度矩阵D(第13行)。根据GCN的公式,我们需要将矩阵D中的每个元素变成-0.5次方(第14行),随后需要对特殊情况进行处理,以防止将0值放置在分母造成无穷大(第15行),随后需要将矩阵D变为对角矩阵(第16行)。
得到邻接矩阵和对角度矩阵后,就可以通过GCN的公式计算图拉普拉斯矩阵(第19行)。考虑到图拉普拉斯矩阵在LGC运算中是不变值,故该矩阵可以以文件形式进行保存,在随后的应用读取即可,从而显著降低时间复杂度。计算得到的图拉普拉斯矩阵以csr_matrix矩阵的形式进行存储(第20行)。
(上述关于Python中Scipy稀疏矩阵库的介绍可以参见https://blog.csdn.net/jeffery0207/article/details/100064602)
在需要使用该图拉普拉斯矩阵时,只需读取该文件,并将其转换为torch的稀疏张量即可,相关代码如下:
self.Graph = sp.load_npz(self.path + '/pre_adj_mat.npz') # sparse matrix
self.Graph = self.convert_sp_mat_to_sp_tensor(self.Graph) # sparse tensor
self.Graph = self.Graph.coalesce().to(self.device)
def convert_sp_mat_to_sp_tensor(self, sp_mat):
"""
coo.row: x in user-item graph
coo.col: y in user-item graph
coo.data: [value(x,y)]
"""
coo = sp_mat.tocoo().astype(np.float32)
row = torch.Tensor(coo.row).long()
col = torch.Tensor(coo.col).long()
index = torch.stack([row, col])
value = torch.FloatTensor(coo.data)
# from a sparse matrix to a sparse float tensor
sp_tensor = torch.sparse.FloatTensor(index, value, torch.Size(coo.shape))
return sp_tensor在实际应用中,为了增快训练速度,需要将该稀疏张量放置对应显卡进行矩阵计算(第3行)。
轻量级图卷积LGC
轻量级图卷积(LGC)是LightGCN的核心部分,该过程主要通过稀疏矩阵乘法实现,相关代码如下:
def aggregate(self):
# [user + item, emb_dim]
all_embedding = torch.cat([self.user_embedding.weight, self.item_embedding.weight])
# no dropout
embeddings = [all_embedding]
for layer in range(self.config.GCNLayer):
all_embedding = torch.sparse.mm(self.Graph, all_embedding)
embeddings.append(all_embedding)
final_embeddings = torch.stack(embeddings, dim=1)
final_embeddings = torch.mean(final_embeddings, dim=1)
users_emb, items_emb = torch.split(final_embeddings, [self.dataset.num_users, self.dataset.num_items])
return users_emb, items_emb其中emb_dim表示嵌入维度。LGC的计算过程首先需要将用户嵌入和物品嵌入拼接为统一的嵌入矩阵(第3行),随后进行迭代地进行图卷积(第8-10行)。轻量级图卷积过程通过稀疏矩阵乘法实现(第9行),随后将更新的嵌入加入嵌入列表。执行完多层图卷积后,需要将多层嵌入取平均聚合(第12-13行),再将其划分为用户嵌入和物品嵌入(第15行)。
aggregate()方法为LightGCN的核心部分,模型训练阶段计算BPR损失和测试阶段计算预测分数前据需调用aggregate()更新用户和物品的嵌入表示。
总结
作者通过大量消融实验证明了GCN的特征转换与非线性激活过程对于协同过滤任务而言是不必要的,并在此基础上提出了LightGCN,其只保留了GCN的核心信息传递和聚合过程。此外,作者在文中指出设计推荐模型时,设计严格的消融研究来明确每个操作的影响是非常重要的。否则,包含不太有用的操作会不必要地使模型复杂化,增加训练难度,甚至是降低模型的有效性。
LightGCN由于其优秀的性能表现、良好的泛化性和易实现的特性,已经广泛地成为现在图推荐系统的底层设计之一,在后续的工作中得到了更为深入的研究。
文章出处登录后可见!