目录图解机制原理
简介
Xgboost预测精度
实验一(回归)
实验二(分类)
Xgboost的数学机制原理
图解Xgboost运行机制原理
决策树
决策树结构图
Xgboost
Xgboost的机制原理
贪心算法
Xgboost总结
数据格式需求
Xgboost运行代码
Xgboost时间序列预测及代码
Xgboost分类任务及代码
Xgboost运行资源下载地址
Xgboost总结
其它时间序列预测模型的讲解!
简介
在本次实战案例中,我们将使用Xgboost算法进行时间序列预测。Xgboost是一种强大的梯度提升树算法,适用于各种机器学习任务,它最初主要用于解决分类问题,在此基础上也可以应用于时间序列预测。
时间序列预测是通过分析过去的数据模式来预测未来的数值趋势。它在许多领域中都有广泛的应用,包括金融、天气预报、股票市场等。我们将使用Python编程语言来实现这个案例。
首先,我们需要准备时间序列数据集。这可以是一个CSV文件,其中包含了按时间顺序排列的数据点。我们将使用Pandas库来读取和处理数据。然后,我们将使用matplolib库对数据进行可视化,以便更好地了解其模式和趋势。
接下来,我们将使用Xgboost库来构建时间序列预测模型。我们将使用已知的过去数据来训练模型,并使用该模型来预测未来的数值。Xgboost算法通过逐步迭代地添加树模型,不断学习和优化模型的性能。
一旦我们完成了模型的训练,我们可以使用它来进行预测。我们将选择合适的输入特征,并根据模型的预测结果来生成未来的数值序列。最后,我们会将预测结果与实际观测值进行对比,评估模型的准确性和性能。
Xgboost预测精度
实验一(回归)
图示为Xgboost模型在回归任务当中预测值和真实值的对比图,
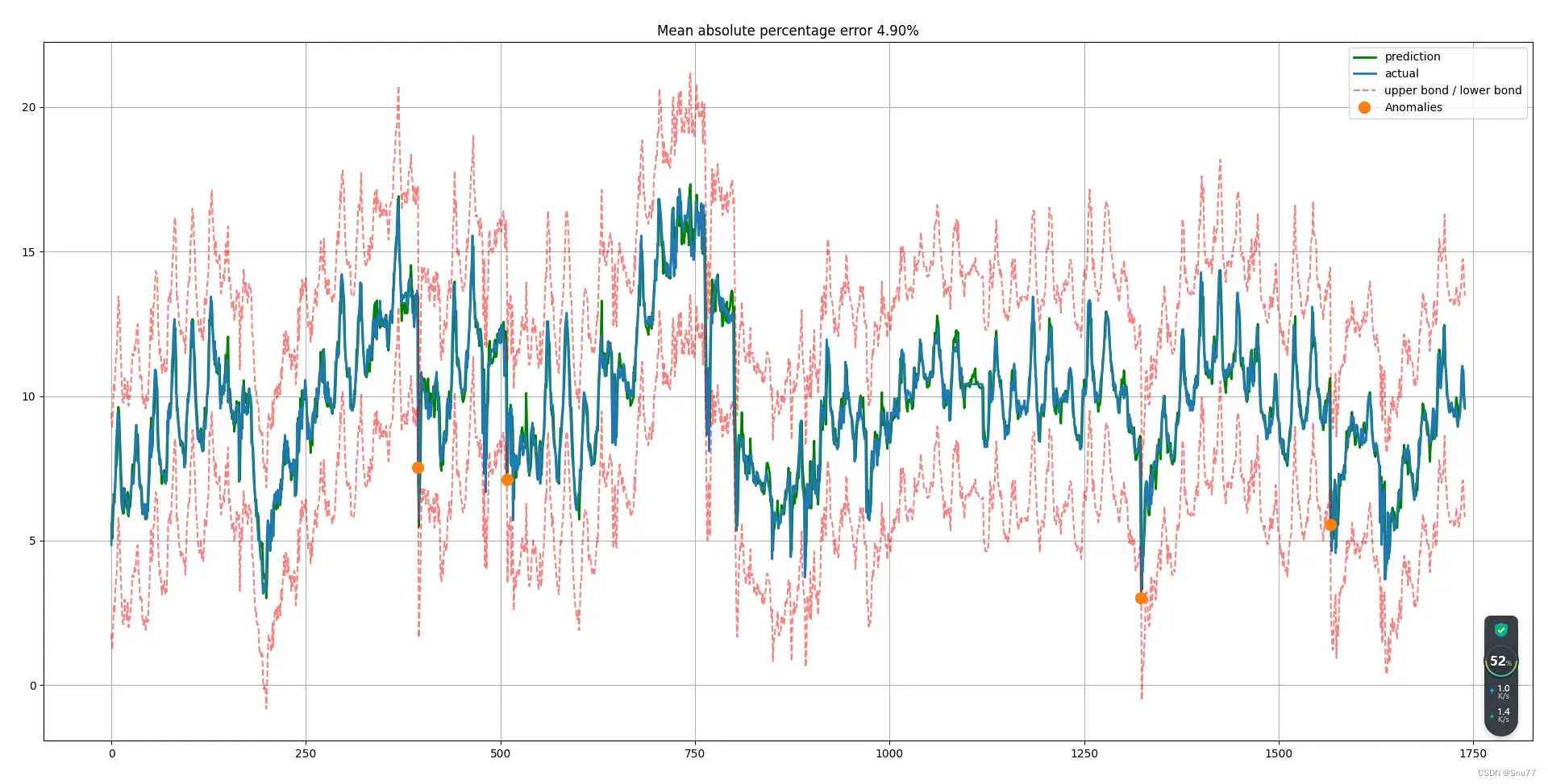
实验二(分类)
下图为Xgboost在分类问题当中的表现
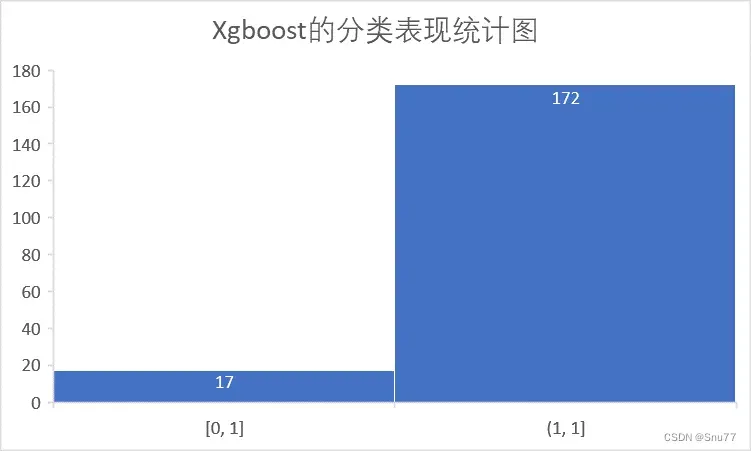
在一个四分类的任务当中Xgboost的预测表现为图所示,其中0-1表示为预测错误,1-1表示为预测正确,可以看出准确率大概为91%
Xgboost的数学机制原理
XGBoost(Extreme Gradient Boosting)是一种基于决策树的集成学习算法,它通过串行地训练多个弱分类器,并将它们组合成一个强分类器,以提高预测性能。下面来详细介绍XGBoost的机制原理。
- 初始化
我们先定义一个模型,假设其初始化为
:
其中,
是样本的特征向量,而
是初始预测值,通常可以选择样本标签的平均值。
- 迭代训练
接下来,我们进行迭代训练。每一次迭代都会添加一个弱分类器
到模型中,并更新预测值
其中,
表示第
个弱分类器对样本
- 计算损失函数
每次添加新分类器后,我们需要计算模型的损失函数
,以便选择最优的弱分类器。这里我们可以使用平方误差作为损失函数:
其中,
是样本的数量,
是样本的标签。
- 计算正则化项
为了避免过拟合,我们需要添加正则化项来限制模型的复杂度。XGBoost采用L1和L2正则化项,分别对应于lasso和ridge回归。下面是L2正则化项的公式:
其中,
表示决策树的节点权重,
是决策树的叶子节点数,
是正则化系数。
- 计算目标函数
综合考虑损失函数和正则化项,我们得到了XGBoost的目标函数:
- 选择最优弱分类器
接下来,我们需要选择最优的弱分类器
- 计算叶子权重
通过上述过程,我们找到了最优的分裂节点,并创建了两个新的叶子节点。接下来,我们需要计算叶子节点的权重
其中,
表示样本
和
表示损失函数的一阶和二阶导数。
通过对
进行求导,我们可以得到最优的叶子权重:
其中,
表示叶子节点$j$对应的样本集合。
- 更新模型
最后,我们使用最优的弱分类器
来更新模型:
其中,
是学习率,它控制每个弱分类器对模型的影响程度。
重复上述过程,直到达到设定的迭代次数或目标函数的变化量达到阈值为止。这样,我们就得到了一个基于决策树的集成模型,它可以用于分类、回归等机器学习任务。
图解Xgboost运行机制原理
XGBoost(eXtreme Gradient Boosting)是一种基于决策树的集成学习算法,它通过多个弱分类器的集成来提高模型的准确性和鲁棒性。XGBoost的核心原理是梯度提升。
(PS:我门可以将Xgboot理解为由多个决策树构成的模型)
要理解Xgboost我门需要先明白一个基础的概念:什么是决策树?
决策树
决策树就是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。它可以通过对数据集的划分来进行分类、回归等任务。在决策树中,我们通常使用熵、基尼系数等度量来选择最优的划分属性。通过递归地构建决策树,我们可以得到一个简单、直观的模型,可以对新的数据进行分类或预测。
决策树在机器学习中有着广泛的应用,例如在医学诊断、金融风险评估、推荐系统等领域中,决策树都可以发挥重要作用。除了传统的决策树算法(如ID3、C4.5、C5.0等),还有一些基于决策树的集成学习算法,如随机森林、XGBoost(本文所讲)等,通过组合多个决策树来提高模型的准确性和鲁棒性。
总之,决策树是一种非常重要和实用的机器学习算法,它具有直观、易解释、易扩展等优点,是机器学习领域中的重要组成部分。
决策树结构图
下面用一个图来让大家清楚的理解决策树的结构
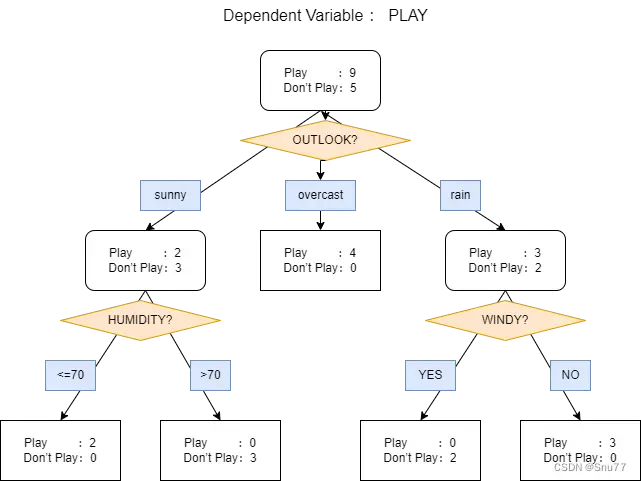
下面来解释这个图,帮助大家来理解决策树的机制原理,
其中在最上端有Dependent Variable:Play这是指在模型中作为因变量(被预测变量)的变量,即我们想要通过模型预测的结果。在这种情况下,”Play” 是依赖变量,即我们想要预测其状态(Play或者Don‘t Play)的变量 ,
其中橘色的菱形代表着一个判断,蓝色的直角矩形代表着一个状态,黑色的直角矩形代表着决策树的输出结果,
从图片中我们可以看到我门当前决策树的初始状态为Play:9 Don’t Play:5 这可以理解我们的初始值,
当经过橘色的菱形进行一个状态的判断(OUTLOOK代表外面天气的判断) ,有三种结果分别为:
- 当外部天气属性为Sunny时候我们的会更新状态为Play:2 Don‘t Play:3,
- 当外部天气为overcast(阴天)直接输出模型结果Play:4 Don’t Play:0 ,
- 当外部天气为rain(下雨天)我们就更新当前状态为Play:3 Don’t Play:2,
当状态被更新以后我们就会往下执行
当判断为外部天气为Sunny时进行状态判断Humidity(湿度)
- 当Humidity<=70 更新状态并输出模型结果: Play:2 Don‘t Play:0,
- 当Humidity>70 更新状态并输出模型结果: Play:0 Don‘t Play:3,
当判断为外部天气为rain时进行状态判断Windy(刮风)
- 当Windy为True时代表外部刮风,更新当前状态为: Play:0 Don‘t Play:2,
- 当Windy为False时代表外部刮风,更新当前状态为: Play:3 Don‘t Play:0,
到此我们对该决策树的所有结果都进行了模拟输出,到这里我门对决策树的概念有了一个大致的了解,本文讲到的模型Xgboost就是由多个决策树构成而来同时配合多种算法从而形成一个完整的模型 。
Xgboost
上面我们大致讲了一下Xgboost的基本结构单元为决策树,我们可以将Xgboost模型理解为一个强分类器,那么决策树就是构成他的弱分类器,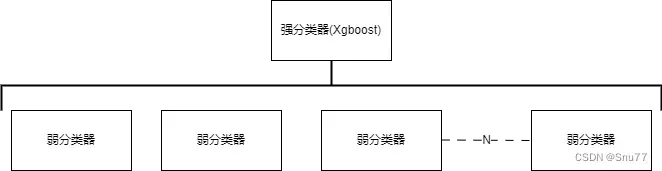
与传统的决策树不同,XGBoost采用了梯度提升算法,通过多次迭代的方式逐步提高模型的准确性。在每一次迭代中,XGBoost会计算出模型的负梯度,然后将其作为新的训练数据来训练下一个弱分类器。
(我们需要注意的是在XGBoost中,每个节点都是一个决策树,但不是每个节点都是单独的决策树。XGBoost采用的是梯度提升算法,每一次迭代都训练一个新的决策树模型,并将其加入到当前模型中。在训练过程中,每个节点都会分裂成两个子节点,每个子节点都对应一个新的决策树模型。因此,XGBoost中的每个节点都是一个决策树模型的一部分,而不是单独的决策树。这种方式可以有效地利用已有的决策树模型,加快模型的训练速度,提高模型的准确性和鲁棒性。)
同时,在Xgboost当中我们初始的是一个目标函数,也可以称之为核函数,我们需要做到的就是求其最优解的一个过程, 根据前面的章节(Xgboost的机制原理)假设我们的目标函数为:
其实我们整个模型的根本目的就是其其最优解 ,
那么Xgboost的是如何求得目标函数的最优解问题呢?这里就运用到了前面讲的决策树和高效的产生一棵决策树的方法,
Xgboost的机制原理
在XGBoost中,目标函数和损失函数的概念是紧密相关的。目标函数是XGBoost通过训练要最小化的函数,而损失函数是用于衡量模型预测结果与真实结果之间差异的函数。
XGBoost通过最小化目标函数来达到最小化损失函数的目的。目标函数通常由损失函数和正则化项组成。损失函数在训练过程中用于衡量模型预测结果与真实结果之间的差异,而正则化项用于控制模型的复杂度,防止过拟合。
在训练过程中,XGBoost通过迭代地添加新的弱学习器来优化目标函数。在每一步迭代中,XGBoost根据目标函数的梯度信息来选择最优的切分点来分裂节点,从而构建决策树。这个过程一直重复,直到达到停止条件(如最大迭代次数、目标函数的收敛等)。
最终,XGBoost通过将所有弱学习器的预测结果进行加权求和,得到最终的预测结果。这个预测结果可以使目标函数或损失函数达到最小值。因此,可以说XGBoost的目标是找到使目标函数最小的参数,而这通常是通过最小化损失函数来实现的。
下面的图表述了数据从输入到得到最终的预测结果的过程
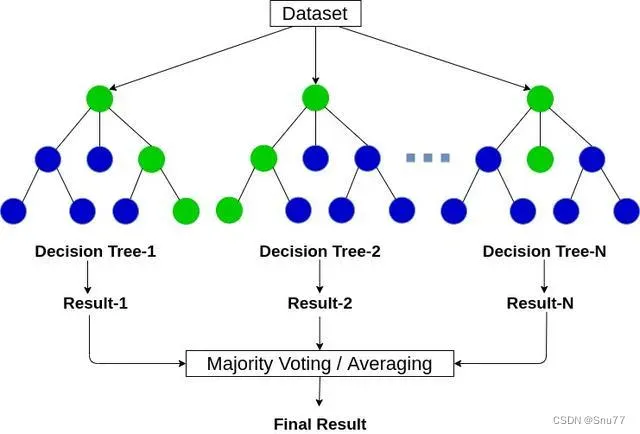
那么如何最小化损失函数来找到使目标函数最小的参数呢?
XGBoost中的决策树生成是通过贪心算法来进行的。
贪心算法
贪心算法是一种在每一步选择中都采取在当前状态下最好或最优(即最有利)的选择,从而希望导致结果是全局最好或最优的算法。贪心算法的基本思路是从问题的某一个初始解出发一步一步地进行,根据某个优化测度,每一步都要确保能获得局部最优解。
下面是一个例子帮助大家来简单理解贪心算法
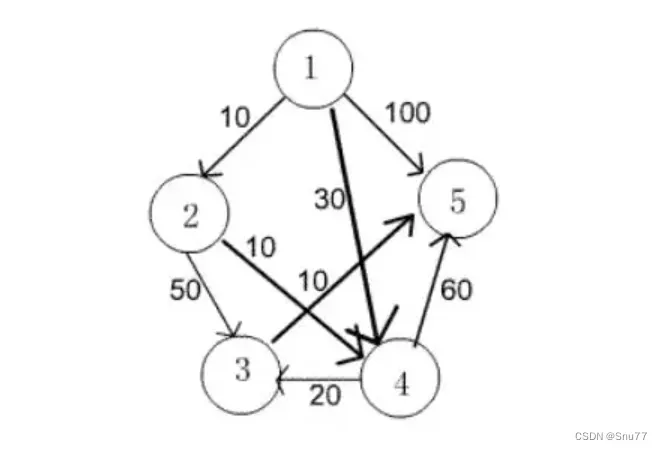
假设我们从1进行出发,想要走到5,想要得到一个最优解,
那么我们的路径应该是 1→2→4→3→5
损失应该是10 +10 + 20 +10 = 40
这就是一个简单的贪心算法案例,由局部最优解→全局最优解。
在XGBoost中,决策树的生成包括两个主要步骤:分裂节点和剪枝。
- 决策树的生成(分裂):基于训练数据集生成决策树,生成的决策树要尽量大。在每个节点,XGBoost会计算出所有可能的切分,并选择最优的切分来分裂节点。这个最优的切分是通过计算每个切分对应的损失函数来找到的。具体而言,XGBoost会计算出每个切分对应的增益,然后选择增益最大的切分来分裂节点。这个过程一直重复,直到满足停止条件(如最大深度、最小样本分裂数等)。
- 决策树的剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,这时损失函数最小作为剪枝的标准。在剪枝的过程中,XGBoost会尝试将树中的一些叶子节点合并成新的内部节点,从而减少模型的复杂度。这个过程也是通过贪心算法进行的:在每个节点,XGBoost会计算出将该节点作为叶子节点或继续分裂所产生的损失函数,然后选择损失函数最小的方案作为该节点的最终方案。
为了提高决策树生成的效率,XGBoost还采用了一些其他的策略。例如,XGBoost会缓存之前生成的计算结果,以便在后续迭代中直接使用这些结果,避免重复计算。此外,XGBoost还使用了树结构的压缩技术,将树中的一些叶子节点合并成新的内部节点,从而减少模型的复杂度,并加速后续的预测过程。
下面的图表述了树的节点分裂的过程
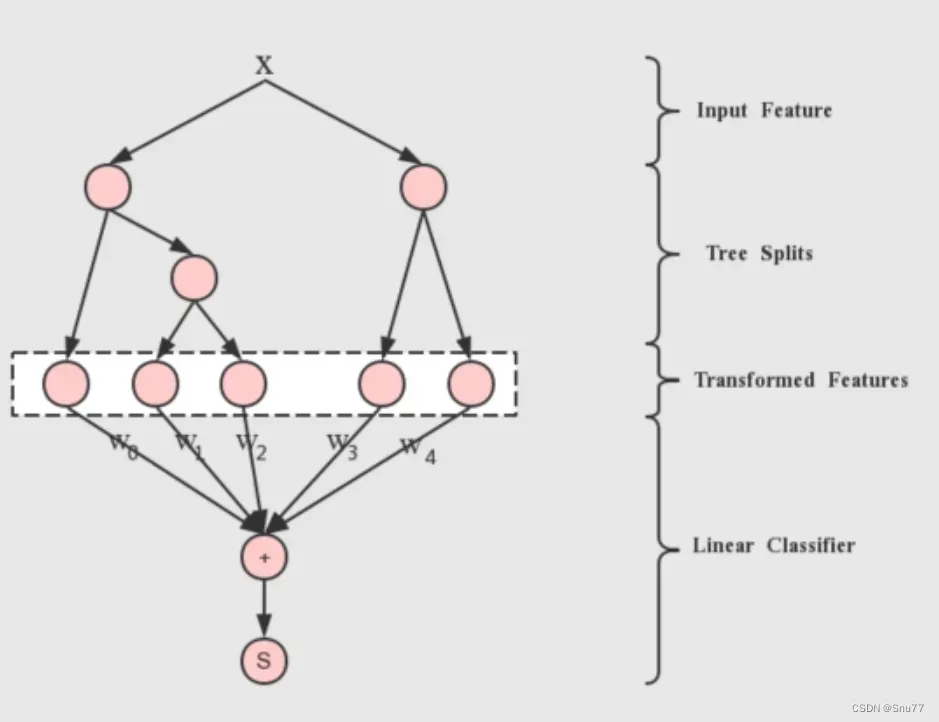
贪心算法的基本原理可以概括为以下几点:
- 将问题分解为若干个子问题。
- 对于每个子问题,确定一个贪心策略,即在当前状态下选择最优的决策。
- 将所有子问题的最优解组合成原问题的解。
Xgboost总结
到此,我们已经知道了一棵完整的树是怎么生成的了,下面进行一个小的总结。
它的主要思想是通过不断迭代的方式训练多个决策树,将它们组合成一个强大的集成模型。在每一轮迭代中,XGBoost会根据前一轮的训练结果调整样本的权重,以使得模型更加关注那些被错误分类的样本。同时,XGBoost通过引入正则化项来控制模型的复杂度,防止过拟合。
XGBoost的优点主要体现在以下几个方面:
-
优秀的泛化能力:XGBoost采用了一系列的正则化技术,可以有效地避免过拟合,从而提高模型的泛化能力。
-
高效的训练速度:XGBoost采用了一些优化技术,如缓存访问、数据压缩等,可以加速训练过程,同时还支持并行计算,可以利用多核CPU进行加速。
-
准确的预测能力:XGBoost采用了一些特殊的技术,如缺失值处理、特征分桶等,可以有效地提高模型的预测能力。
总的来说,XGBoost是一种非常强大的机器学习算法,如果你需要解决一些复杂的分类或回归问题,XGBoost是一个非常值得尝试的算法。
数据格式需求
数据格式为8列,其中时间格式要对应,OT列为预测值。
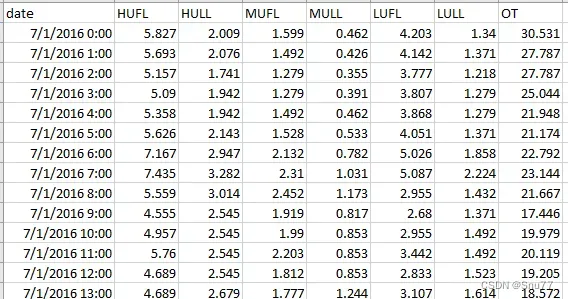
Xgboost运行代码
Xgboost时间序列预测及代码
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.model_selection import cross_val_score, TimeSeriesSplit
from sklearn.preprocessing import StandardScaler
from xgboost import XGBRegressor
def timeseries_train_test_split(X, y, test_size):
"""
Perform train-test split with respect to time series structure
"""
# get the index after which test set starts
test_index = int(len(X) * (1 - test_size))
X_train = X.iloc[:test_index]
y_train = y.iloc[:test_index]
X_test = X.iloc[test_index:]
y_test = y.iloc[test_index:]
return X_train, X_test, y_train, y_test
def code_mean(data, cat_feature, real_feature):
"""
cat_feature:类别型特征,如星期几;
real_feature:target字段
"""
return dict(data.groupby(cat_feature)[real_feature].mean())
def mean_absolute_percentage_error(y_true, y_pred):
return np.mean(np.abs((y_true - y_pred) / y_true)) * 100
def plotModelResults(model, X_train, X_test, plot_intervals=False, plot_anomalies=False, scale=1.96):
"""
Plots modelled vs fact values, prediction intervals and anomalies
"""
prediction = model.predict(X_test)
plt.figure(figsize=(15, 7))
plt.plot(prediction, "g", label="prediction", linewidth=2.0)
plt.plot(y_test.values, label="actual", linewidth=2.0)
if plot_intervals:
cv = cross_val_score(model, X_train, y_train,
cv=tscv,
scoring="neg_mean_squared_error")
# mae = cv.mean() * (-1)
deviation = np.sqrt(cv.std())
lower = prediction - (scale * deviation)
upper = prediction + (scale * deviation)
plt.plot(lower, "r--", label="upper bond / lower bond", alpha=0.5)
plt.plot(upper, "r--", alpha=0.5)
if plot_anomalies:
anomalies = np.array([np.NaN] * len(y_test))
anomalies[y_test < lower] = y_test[y_test < lower]
anomalies[y_test > upper] = y_test[y_test > upper]
plt.plot(anomalies, "o", markersize=10, label="Anomalies")
error = mean_absolute_percentage_error(prediction, y_test)
plt.title("Mean absolute percentage error {0:.2f}%".format(error))
plt.legend(loc="best")
plt.tight_layout()
plt.grid(True);
plt.show()
def prepareData(series, lag_start, lag_end, test_size, target_encoding=False):
"""
series: pd.DataFrame
dataframe with timeseries
lag_start: int
initial step back in time to slice target variable
example - lag_start = 1 means that the model
will see yesterday's values to predict today
lag_end: int
final step back in time to slice target variable
example - lag_end = 4 means that the model
will see up to 4 days back in time to predict today
test_size: float
size of the test dataset after train/test split as percentage of dataset
target_encoding: boolean
if True - add target averages to the dataset
"""
# copy of the initial dataset
data = pd.DataFrame(series.copy()).loc[:, ['OT']]
data.columns = ["y"]
# lags of series
for i in range(lag_start, lag_end):
data["lag_{}".format(i)] = data.y.shift(i)
#
# datetime features
data.index = pd.to_datetime(data.index)
data["hour"] = data.index.hour
data["weekday"] = data.index.weekday
data['is_weekend'] = data.weekday.isin([5, 6]) * 1
if target_encoding:
# calculate averages on train set only
test_index = int(len(data.dropna()) * (1 - test_size))
data['weekday_average'] = list(map(
code_mean(data[:test_index], 'weekday', "y").get, data.weekday))
# frop encoded variables
data.drop(["weekday"], axis=1, inplace=True)
# train-test split
y = data.dropna().y
X = data.dropna().drop(['y'], axis=1)
X = pd.get_dummies(X)
X_train, X_test, y_train, y_test = \
timeseries_train_test_split(X, y, test_size=test_size)
return X_train, X_test, y_train, y_test
if __name__ == '__main__':
"""
"XGBoost(机器学习)",
"""
df = pd.read_csv('ETTh1.csv')
df['OT'].fillna(0, inplace=True)
df.set_index('date', inplace=True)
hp_raw = df[['OT']]
tscv = TimeSeriesSplit(n_splits=5)
# reserve 30% of data for testing
X_train, X_test, y_train, y_test = \
prepareData(hp_raw, lag_start=1, lag_end=28, test_size=0.1, target_encoding=True)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
xgb = XGBRegressor()
xgb.fit(X_train_scaled, y_train)
plotModelResults(xgb,
X_train=X_train_scaled,
X_test=X_test_scaled,
plot_intervals=True, plot_anomalies=True)Xgboost分类任务及代码
import pickle
import pandas as pd
import xgboost as xgb
from sklearn.metrics import accuracy_score
import numpy as np
np.random.seed(0)
df = pd.read_csv('ETTh1.csv')
df = df.fillna(method='ffill') # 处理Nan值
# 给ETTh1.csv文件的OT列打上标签
# 将其中的值进行分组,作为其标签划分为四个组-10-10, 10-20, 20-30, 30-50,
thresholds = [-10, 0, 10, 20, 30, 40, 50]
df['truegroup'] = pd.cut(df['OT'], bins=thresholds, labels=['0', '1', '2', '3', '4', '5'])
# 参数定义
data_cycle_day = 24 # 我的数据当中一天有五十个数据,这里代表你一天当中数据有多少个
numbers = list(range(data_cycle_day)) # 我的数据当中一天有五十个数据,这里代表你一天当中数据有多少个
df['shift'] = [i % data_cycle_day for i in range(len(df))]
# 特征工程
averages = []
# 生成过去同一时间段的平均值
for num in numbers:
average = df[df['shift'] == num]['OT'].mean()
averages.append(average)
df['OTmean'] = [averages[i % data_cycle_day] for i in range(len(df))]
# 生成当天过去两天同一时间段的值
df['cycle_index'] = (df.index % data_cycle_day) + 1
df['prev_day_value'] = df.groupby('cycle_index')['OT'].shift(1)
df['prev_two_days_value'] = df.groupby('cycle_index')['OT'].shift(2)
df['prev_three_days_value'] = df.groupby('cycle_index')['OT'].shift(3)
df = df.dropna() # 丢弃没有前三天值的行不进行分类
train_data = df[['OTmean', 'prev_day_value', 'prev_two_days_value','prev_three_days_value','LULL','LUFL',
'MULL', 'MUFL', 'HUFL', 'HULL', 'OT']] # s
label = df['truegroup']
train_size = int(len(df) * 0.75) # 划分测试集和训练集分割比例
# 准备训练数据集和测试数据集
train_features, test_features = train_data[:train_size], train_data[train_size:]
train_labels, test_labels = label[:train_size], label[train_size:]
# 构建 DMatrix xgboost需要的数据格式
dtrain = xgb.DMatrix(data=train_features, label=train_labels)
dtest = xgb.DMatrix(data=test_features)
# 定义参数
params = {
'objective': 'multi:softmax',
'num_class': 6,
'max_depth': 10,
'eta': 0.05,
'eval_metric': 'merror'
}
train = True
if train:
# 训练模型
num_rounds = 25
model = xgb.train(params, dtrain, num_rounds)
with open('Xgboostmodels.pkl', 'wb') as file:
pickle.dump(model, file)
with open('Xgboostmodels.pkl', 'rb') as f: # 加载模型
model = pickle.load(f)
# 预测结果
pred_labels = model.predict(dtest)
# 模型评估
accuracy = accuracy_score(test_labels.astype('float'), pred_labels)
print("Accuracy:", accuracy)
results = test_labels.astype('float') == pred_labels
print(results.sum()) # 打印统计正确总数Xgboost运行资源下载地址
我在CSDN上传了Xgboost的运行文件大家可以下载运行试试,如果想要按照自己的数据集更改进行试验,我在代码上面进行了标注大家可以尝试一下。
Xgboost一键运行代码下载链接
全文总结
总之,XGBoost 是一种功能强大的机器学习算法,已经存在很多年了,但至今依然在很多工程项目上都在使用,其可用于分类和回归问题。
到此为止关于Xgboost分析就结束了,
后期我也会讲一些最新的预测模型包括Informer,TPA-LSTM,ARIMA,Attention-LSTM,LSTM-Xgboost,移动平均法,加权移动平均,指数平滑等等一系列关于时间序列预测的模型,包括深度学习和机器学习方向的模型我都会讲,你可以根据需求选取适合你自己的模型进行预测,如果有需要可以+个关注,包括本次模型我自己的代码大家有需要我也会放出百度网盘下载链接!!
其它时间序列预测模型的讲解!
——————————————————-LSTM-深度学习—————————————————–时间序列预测模型实战案例(三)(LSTM)(Python)(深度学习)时间序列预测(包括运行代码以及代码讲解)
——————————————————–MTS-Mixers———————————————————
【全网首发】(MTS-Mixers)(Python)(Pytorch)最新由华为发布的时间序列预测模型实战案例(一)(包括代码讲解)实现企业级预测精度包括官方代码BUG修复Transform模型
——————————————————–Holt-Winters——————————————————–
时间序列预测模型实战案例(二)(Holt-Winter)(Python)结合K-折交叉验证进行时间序列预测实现企业级预测精度(包括运行代码以及代码讲解)
如果大家有不懂的也可以评论区留言一些报错什么的大家可以讨论讨论看到我也会给大家解答如何解决!
文章出处登录后可见!