【Python–XML文件读写】XML文件读写详解
文章目录
- 【Python–XML文件读写】XML文件读写详解
- 1. 前言
- 1.1 介绍
- 1.2 用法
- 2. xml文件内容形式
- 3. xml文件读写
- 3.1 项目框架
- 3.1 写入操作(创建)(create_xml.py)
- 3.2 读取操作(解析)(read_xml.py)
- 4. 参考
1. 前言
1.1 介绍
XML 指可扩展标记语言XML ,常被设计用来传输和存储数据。
XML 是一种固有的分层数据格式,最自然的表示方式是使用树。 ET为此有两个类 – ElementTree将整个 XML 文档表示为一棵树,并 Element表示该树中的单个节点。与整个文档的交互(从文件读取和写入/从文件写入)通常在ElementTree级别上完成。与单个 XML 元素及其子元素的交互是在Element级别上完成的。
其内元素称作子节点通过 parse() 解析xml文本,返回根元素 tree。(一级节点Annotation) 通过对 tree 进行findall操作,可到到带有指定标签的节点(二级节点eg:filename,object)。
1.2 用法
xml.etree.ElementTree模块实现了用于解析和创建 XML 数据的简单高效的 API。 Element对象有以下常用属性:
- tag: 标签
- findall() : 只找到带有标签的 所有节点
- append() : 增加新节点
- set():增加或者修改属性
- text: 去除标签,获得标签中的内容。
- attrib: 获取标签中的属性和属性值。
- remove():删除节点
- 保存xml文件: ElementTree.write()
2. xml文件内容形式
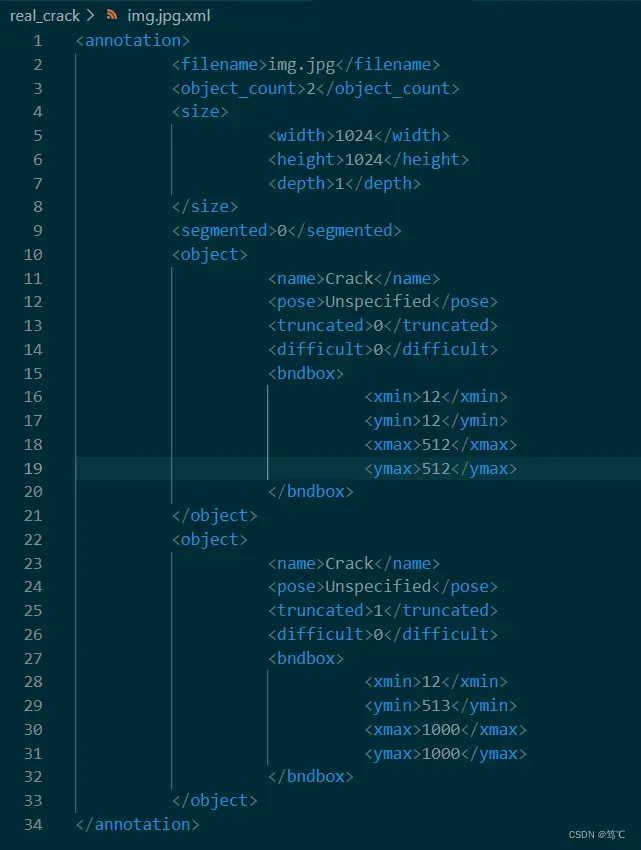
3. xml文件读写
3.1 项目框架
3.1 写入操作(创建)(create_xml.py)
from xml.etree.ElementTree import Element
from xml.etree.ElementTree import SubElement
from xml.etree.ElementTree import ElementTree
from xml.dom import minidom
'''
生成对应的label, 也就是xml文件
'''
# 该函数使xml文件更加美观,也就是换行和缩进
def prettyXml(element, indent, newline, level = 0):
'''
参数:
elemnt为传进来的Elment类;
indent用于缩进;
newline用于换行;
'''
# 判断element是否有子元素
if element:
# 如果element的text没有内容
if element.text == None or element.text.isspace():
element.text = newline + indent * (level + 1)
else:
element.text = newline + indent * (level + 1) + element.text.strip() + newline + indent * (level + 1)
# 此处两行如果把注释去掉,Element的text也会另起一行
#else:
#element.text = newline + indent * (level + 1) + element.text.strip() + newline + indent * level
temp = list(element) # 将elemnt转成list
for subelement in temp:
# 如果不是list的最后一个元素,说明下一个行是同级别元素的起始,缩进应一致
if temp.index(subelement) < (len(temp) - 1):
subelement.tail = newline + indent * (level + 1)
else: # 如果是list的最后一个元素, 说明下一行是母元素的结束,缩进应该少一个
subelement.tail = newline + indent * level
# 对子元素进行递归操作
prettyXml(subelement, indent, newline, level = level + 1)
def create(root_dir, img_name, bg_size, count, tg_loca):
'''
root_dir: 要写到得文件夹下
img_name: 对应样本的文件名
bg_size: 图片的大小 (w, h)
count: 目标的个数
tg_loca: 裂缝目标的位置 list[(x_tl, y_tl, x_br, y_br)]
'''
# 1 annotation
annotation = Element('annotation')
# 1-1 filename
filename = SubElement(annotation, 'filename')
filename.text = img_name
# 1-2 object_count
object_count = SubElement(annotation, 'object_count')
object_count.text = str(count)
# 1-3 size
# -------------------size start--------------------------
size = SubElement(annotation, 'size')
# 1-3-1 width
width = SubElement(size, 'width')
width.text = str(bg_size[0])
# 1-3-2 height
height = SubElement(size, 'height')
height.text = str(bg_size[1])
# 1-3-3 depth
depth = SubElement(size, 'depth')
depth.text = '1'
# -------------------size end--------------------------
# 1-4 segmented
segmented = SubElement(annotation, 'segmented')
segmented.text = '0'
# 1-(5 : 5 + count) object
for i in range(0, count):
object = SubElement(annotation, 'object')
# 1-(:)-1 name
name = SubElement(object, 'name')
name.text = 'Crack'
# 1-(:)-2 pose
pose = SubElement(object, 'pose')
pose.text = 'Unspecified'
# 1-(:)-3 truncated
truncated = SubElement(object, 'truncated')
truncated.text = str(i)
# 1-(:)-4 difficult
difficult = SubElement(object, 'difficult')
difficult.text = '0'
# 1-(:)-5 bndbox
# ---------------------bndbox start------------------------------
bndbox = SubElement(object, 'bndbox')
# xmin
xmin = SubElement(bndbox, 'xmin')
xmin.text = str(tg_loca[i][0])
# ymin
ymin = SubElement(bndbox, 'ymin')
ymin.text = str(tg_loca[i][1])
# xmax
xmax = SubElement(bndbox, 'xmax')
xmax.text = str(tg_loca[i][2])
# ymax
ymax = SubElement(bndbox, 'ymax')
ymax.text = str(tg_loca[i][3])
# ---------------------bndbox end------------------------------
tree = ElementTree(annotation)
root = tree.getroot()
prettyXml(root, '\t', '\n')
# write out xml data
tree.write(root_dir + img_name + '.xml', encoding = 'utf-8')
root_dir = "./"
img_name = 'img.jpg'
bg_size = (1024, 1024)
count = 2
tg_loca = [(12, 12, 512, 512), (12, 513, 1000, 1000)]
create(root_dir, img_name, bg_size, count, tg_loca)
- 得到的xml文件如下:
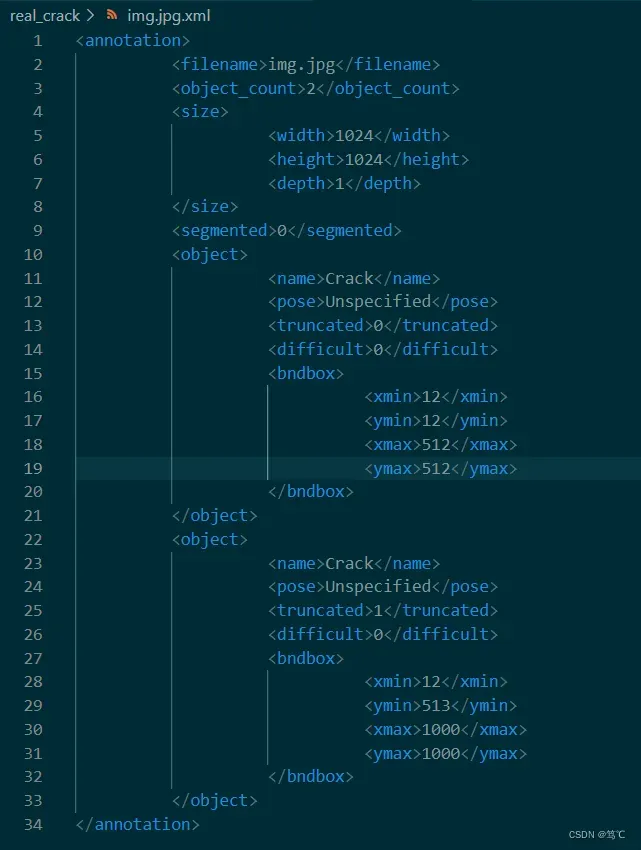
3.2 读取操作(解析)(read_xml.py)
import xml.etree.ElementTree as ET
import os
from PIL import Image, ImageDraw, ImageFont
def parse_rec(pic_path, filename):
"""解析xml"""
tree = ET.parse(filename) # 解析读取xml函数
objects = []
coordinate = []
for xml_name in tree.findall('filename'):
img_path = os.path.join(pic_path, xml_name.text)
for obj in tree.findall('object'):
obj_struct = {'name': obj.find('name').text, 'pose': obj.find('pose').text,
'truncated': int(obj.find('truncated').text), 'difficult': int(obj.find('difficult').text)}
bbox = obj.find('bndbox')
obj_struct['bbox'] = [int(bbox.find('xmin').text),
int(bbox.find('ymin').text),
int(bbox.find('xmax').text),
int(bbox.find('ymax').text)]
objects.append(obj_struct)
for obj_one in objects:
xmin = int(obj_one['bbox'][0])
ymin = int(obj_one['bbox'][1])
xmax = int(obj_one['bbox'][2])
ymax = int(obj_one['bbox'][3])
label = obj_one['name']
coordinate.append([xmin,ymin,xmax,ymax,label])
return coordinate, img_path
def visualise_gt(objects, img_path, now_path):
img = Image.open(img_path)
draw = ImageDraw.ImageDraw(img)
for obj in objects:
xmin = obj[0]
ymin = obj[1]
xmax = obj[2]
ymax = obj[3]
label = obj[4]
draw.rectangle(((xmin, ymin), (xmax, ymax)), fill=None, outline="white")
draw.text((xmin + 10, ymin), label, "blue")
img.save(now_path)
if __name__ == "__main__":
# 图片路径
pic_path = "."
# xml文件路径
xml_path = "./img.jpg.xml"
# 解析后存放地址
now_path = "./img_now.jpg"
# obj_context:返回一个含有所有标注的信息,img_dir:原始图片路径
obj_context, img_path = parse_rec(pic_path, xml_path)
visualise_gt(obj_context, img_path, now_path)
-
原图:(img.jpg)

-
解析后的图:(img_now.jpg)

4. 参考
【1】https://blog.csdn.net/qq_48764574/article/details/122052510
文章出处登录后可见!
已经登录?立即刷新