1.问题描述
在处理数据时,会遇到\xa0、\u3000、\u2800、\t等Unicode字符串。需要对其进行处理。
2.空格类型说明
空格可以分为两类,一类为普通文本空格,另一类为html实体空格。普通文本空格介绍普通半角空格和普通全角空格。html实体空格介绍三种,分别为html实体不间断空格( )、html实体半角空格( )和html实体全角空格( )。
1.普通半角空格:英文空格键。这是最常见的空格,如我们写代码时,按下空格键产生的就是这种空格键。正则里直接使用空格或者\s就能匹配,在python中对应的unicode码为\u0020;
2.普通全角空格:中文空格键。中文网页上常会出现,直接使用正则的\s匹配不到,unicode码为\u3000;
3.html实体不间断空格:html中的常用空格,出现在html中为 。网页上看不到,打开浏览器开发工具可以看到,unicode码为\u00A0,对应的十六进制为\xa0;
4.html实体半角空格:&ensp,unicode码为\u2002;
5.html实体全角空格:&emsp,unicode码为\u2003;
3.解决方法
3-1.使用re.sub
re.sub方法对普通文本空格和html实体空格两类全部有效,均可完成替换。
import re
#普通半角空格
String = "百度 百科"
#用unicode匹配
new_string = re.sub(r'\u0020',"*", String)
print(new_string)
#用\s匹配
new_string = re.sub(r'\s',"*", String)
print(new_string)
#用空格匹配
new_string = re.sub(r' ',"*", String)
print(new_string)
#普通全角空格
String = "百度\u3000百科"
#使用unicode匹配
new_string = re.sub(r'\u3000',"*", String)
print('使用unicode匹配结果:',new_string)
new_string = re.sub(r'\s',"*", String)
print('使用\s匹配结果:',new_string)
#用空格匹配
new_string = re.sub(r' ',"*", String)
print('使用空格匹配结果:',new_string)
#html实体不间断空格
String = "百度\xa0百科"
new_string = re.sub(r'\xa0',"*", String)
print(new_string)
String = "百度\u00A0百科"
new_string = re.sub(r'\u00A0',"*", String)
print(new_string)
#html实体半角空格
String = "百度\u2002百科"
#使用unicode匹配
new_string = re.sub(r'\u2002',"*", String)
print('使用unicode匹配结果:',new_string)
#html实体全角空格
String = "百度\u2003百科"
#使用unicode匹配
new_string = re.sub(r'\u2003',"*", String)
print('使用unicode匹配结果:',new_string)



3-2.使用repalce
replace方法可以对‘普通半角空格’、‘普通全角空格’ 的unicode的字符完成替换。对html实体空格无效。
#普通半角空格
String = "百度 百科"
#用unicode匹配
new_string = String.replace('\u0020','*')
print('String',String)
print('用unicode匹配的new_string:',new_string)
#用\s匹配
new_string = String.replace(r'\s',"*")
print('用\s匹配的new_string:',new_string)
#用空格匹配
new_string = String.replace(r' ',"*")
print('用空格匹配的new_string:',new_string)
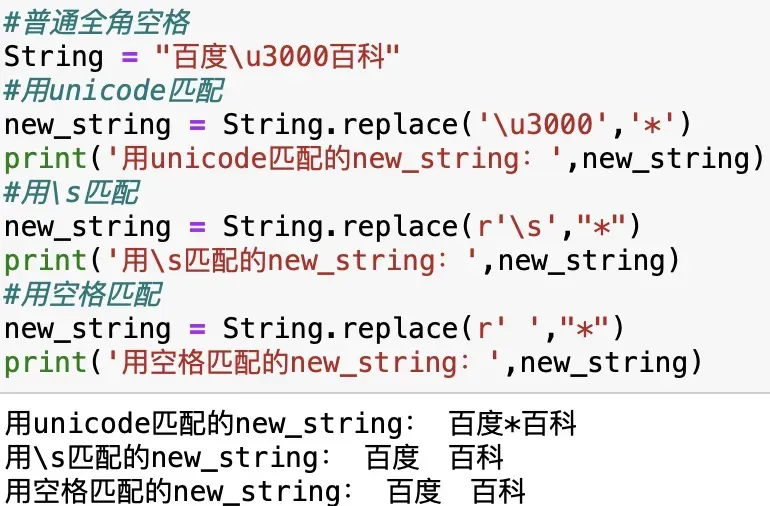
#普通半角空格
String = "百度\u3000百科"
#用unicode匹配
new_string = String.replace('\u3000','*')
print('用unicode匹配的new_string:',new_string)
#用\s匹配
new_string = String.replace(r'\s',"*")
print('用\s匹配的new_string:',new_string)
#用空格匹配
new_string = String.replace(r' ',"*")
print('用空格匹配的new_string:',new_string)
#html实体不间断空格
String = "百度\xa0百科"
new_string = String.replace(r'\xa0',"*")
print('new_string',new_string)
String = "百度\u00A0百科"
new_string = String.replace(r'\u00A0',"*")
print('new_string',new_string)
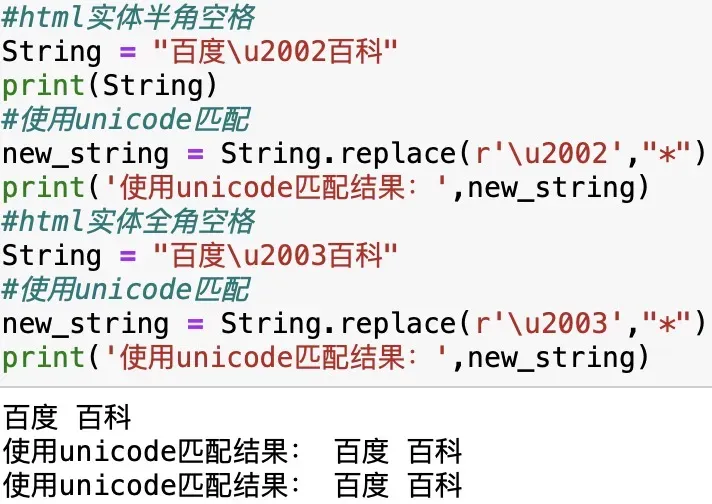
#html实体半角空格
String = "百度\u2002百科"
#使用unicode匹配
new_string = String.replace(r'\u2002',"*")
print('使用unicode匹配结果:',new_string)
#html实体全角空格
String = "百度\u2003百科"
#使用unicode匹配
new_string = String.replace(r'\u2003',"*")
print(String)
print('使用unicode匹配结果:',new_string)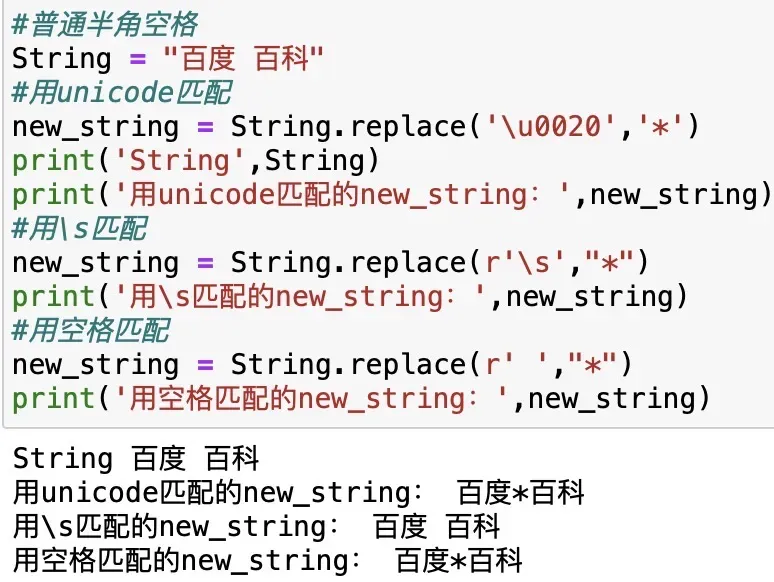

Reference
1.Python爬虫处理\xa0、\u3000、\u2002、\u2003等空格_liqiang94的博客-CSDN博客_python \u3000
文章出处登录后可见!
已经登录?立即刷新