目录
词频统计是自然语言处理的基本任务,针对一段句子、一篇文章或一组文章,统计文章中每个单词出现的次数,在此基础上发现文章的主题词、热词。
1. 单句的词频统计
思路:首先定义一个空字典my_dict,然后遍历文章(或句子),针对每个单词判断是否在字典my_dict的key中,不存在就将该单词当作my_dict的key,并设置对应的value值为1;若已存在,则将对应的value值+1。
#统计单句中每个单词出现的次数
news = "Xi, also general secretary of the Communist Party of China (CPC) Central Committee and chairman of the Central Military Commission, made the remarks while attending a voluntary tree-planting activity in the Chinese capital's southern district of Daxing."
def couWord(news_list):
##定义计数函数 输入:句子的单词列表 输出:单词-次数 的字典
my_dict = {} #空字典 来保存单词出现的次数
for v in news_list:
if my_dict.get(v):
my_dict[v] += 1
else:
my_dict[v] = 1
return my_dict
print(couWord(news.split ()))
输出
{‘Xi,’: 1, ‘also’: 1, ‘general’: 1, ‘secretary’: 1, ‘of’: 4, ‘the’: 4, ‘Communist’: 1, ‘Party’: 1, ‘China’: 1, ‘(CPC)’: 1, ‘Central’: 2, ‘Committee’: 1, ‘and’: 1, ‘chairman’: 1, ‘Military’: 1, ‘Commission,’: 1, ‘made’: 1, ‘remarks’: 1, ‘while’: 1, ‘attending’: 1, ‘a’: 1, ‘voluntary’: 1, ‘tree-planting’: 1, ‘activity’: 1, ‘in’: 1, ‘Chinese’: 1, “capital’s”: 1, ‘southern’: 1, ‘district’: 1, ‘Daxing.’: 1}以上通过couWord方法实现了词频的统计,但是存在以下两个问题。
(1)未去除stopword
输出结果中保护’also’、‘and’、’in’等stopword(停止词),停止词语与文章主题关系不大,需要在词频统计等各类处理中将其过滤掉。
(2)未根据出现次数进行排序
根据每个单词出现次数进行排序后,可以直观而有效的发现文章主题词或热词。
改进后的couWord函数如下:
def couWord(news_list,word_list,N):
#输入 文章单词的列表 停止词列表 输出:Top N的单词
my_dict = {} #空字典 来保存单词出现的次数
for v in news_list:
if (v not in word_list): # 判断是否在停止词列表中
if my_dict.get(v):
my_dict[v] += 1
else:
my_dict[v] = 1
topWord = sorted(zip(my_dict.values(),my_dict.keys()),reverse=True)[:N]
return topWord
加载英文停止词列表:
stopPath = r'Data/stopword.txt'
with open(stopPath,encoding = 'utf-8') as file:
word_list = file.read().split() #通过read()返回一个字符串函数,再将其转换成列表
print(couWord(news.split(),word_list,5)) 输出
[(2, ‘Central’), (1, ‘voluntary’), (1, ‘tree-planting’), (1, ‘southern’), (1, ‘secretary’)]
2. 文章的词频统计
(1)单篇文章词频统计
通过定义读取文章的函数,对其进行大小写转换等处理,形成输入文章的单词列表。
https://python123.io/resources/pye/hamlet.txt
以上为hamlet英文版文本的获取路径,下载完成后保存到工程路径下。
使用open()函数打开hamlet.txt文件,并使用read()方法读取文件内容,将文本保存在txt变量中。
def readFile(filePath):
#输入: 文件路径 输出:字符串列表
with open(filePath,encoding = 'utf-8') as file:
txt = file.read().lower() #返回一个字符串,都是小写
words = txt.split() #转换成列表
return words
filePath = r'Data/news/hamlet.txt'
new_list = readFile(filePath) #读取文件
print(couWord(new_list,word_list,5))
接下来,我们需要对文本进行预处理,去除标点符号、分割成单词等。我们可以使用正则表达式来实现这一步骤。
import re
# 去除标点符号
text = re.sub(r'[^\w\s]', '', text)
# 分割成单词
words = text.split()我们使用re.sub()函数和正则表达式[^\w\s]来去除标点符号,然后使用split()方法将文本分割成单词,并将结果保存在words列表中。
或者:
我们的文本中含有标点和字符的噪声数据,所以要进行数据的清洗,将文档全部处理为只有我们需要的字母类型(为方便操作,用空格替换噪声数据,将文档全部转化为小写字母)
打开文件,进行读取,清洗数据,数据归档。
def getText():
txt = open("Hmlet.txt","r").read()
txt = txt.lower()
for ch in '!@#$%^&*()_/*-~':
txt = txt.replace(ch," ")
return txt
hamlet = getText()
words = hamlet.split()
counts = {}
for word in words:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key= lambda x:x[1],reverse=True)
for i in range(10):
word, count = items[i]
print("{0:<10}{1:>5}".format(word,count))现在,我们已经得到了分割后的单词列表words,接下来我们需要统计每个单词出现的次数。我们可以使用Python的字典数据结构来实现词频统计。
word_counts = {}
for word in words:
if word in word_counts:
word_counts[word] += 1
else:
word_counts[word] = 1这段代码中,我们首先创建一个空字典word_counts,然后遍历words列表中的每个单词。对于每个单词,如果它已经在word_counts字典中存在,则将对应的计数值加1;否则,在字典中新增一个键值对,键为单词,值为1。
在统计完词频后,我们需要按照词频降序排序,以便后续输出结果。我们可以使用Python的内置函数sorted()来实现排序。
sorted_word_counts = sorted(word_counts.items(), key=lambda x: x[1], reverse=True)
我们使用word_counts.items()方法获取word_counts字典中的所有键值对,并使用key=lambda x: x[1]指定按照键值对中的值进行排序,reverse=True表示降序排列。排序结果将保存在sorted_word_counts列表中。
最后,我们将词频统计结果输出到控制台或文件中。
for word, count in sorted_word_counts:
print(f'{word}: {count}')这段代码中,我们使用for循环遍历sorted_word_counts列表中的每个元素(每个元素是一个键值对),并使用print()函数输出单词和对应的词频。
(2)多篇文章词频统计
需要使用os.listdir方法读取文件夹下的文件列表,然后对文件逐一进行处理。
import os
folderPath = r'Data/news' #文件夹路径
tmpFile = os.listdir(folderPath)
allNews = []
for file in tmpFile: #读取文件
newsfile = folderPath + '//' + file #拼接完整的文件路径 \\ 转义字符
allNews += readFile(newsfile) #把所有的字符串列表拼接到allText中
print(couWord(allNews,word_list,5))
输出
[(465, ‘china’), (323, ‘chinese’), (227, ‘xi’), (196, “china’s”), (134, ‘global’)]
(3)中文文章的处理
对于中文文章的词频统计,首先要使用jieba等分词器对文章进行分词,并且加载中文的停止词列表,再进行词频统计。
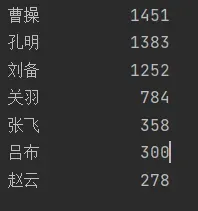
3.三国演义人物出场频数
利用jieba库,进行中文分词,将其存入列表words中,遍历,将词组和词频作为键值对存入列表counts中,利用列表的有序性,进行排序,然后输出
https://python123.io/resources/pye/threekingdoms.txt
以上为三国演义中文版文本获取链接,下载后保存到工程路径下
import jieba
txt = open("threekingdoms.txt","r",encoding="utf-8").read()
counts = {}
words = jieba.lcut(txt)
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key = lambda x:x[1] , reverse=True)
for i in range(15):
word , count = items[i]
print("{0:<10}{1:>5}".format(word,count))该方法比英文哈姆雷特词频简单,不用去处理字符类噪声数据,这也得益于jieba库的简易操作。
但随之带来的是词频的模糊,因为jieba库的特性,导致不是人名的词组也被统计了进来。
如结果中的“二人”、”孔明曰“,这些都是冗余和词组问题的错误。
所以我们应该还需要进行进一步的处理,让词频统计人物的名字次数
经过前几步的操作,我们输出了出现频率最高的15给词组,可我们如果想要人物的出场频率呢? 这就需要对原文件进行过滤,把我们不需要的输出删除。
因为之前的输出可以简单的获取到出现频率高但不是人名的词组,所以我们这里把它们储存到一个集合中,遍历并删除原文件中存在的这些词组。
excludes = {"将军","却说","二人","不可","荆州","不能","如此","商议","如何","主公","军士","左右","军马"}for i in excludes:
del counts[i]冗余处理:把出现频率高的相同人物别名进行统一
elif word == "诸葛亮" or word == "孔明曰":
rword = "孔明"
elif word == "关公" or word == "云长":
rword = "关羽"
elif word == "玄德" or word == "玄德曰":
rword = "刘备"
elif word == "孟德" or word == "丞相":
rword = "曹操"反复的经过这些处理,我们可以得到我们想要的输出
import jieba
txt = open("threekingdoms.txt","r",encoding="utf-8").read()
counts = {}
excludes = {"将军","却说","二人","不可","荆州","不能","如此","商议","如何","主公","军士","左右","军马"}
words = jieba.lcut(txt)
for word in words:
if len(word) == 1:
continue
elif word == "诸葛亮" or word == "孔明曰":
rword = "孔明"
elif word == "关公" or word == "云长":
rword = "关羽"
elif word == "玄德" or word == "玄德曰":
rword = "刘备"
elif word == "孟德" or word == "丞相":
rword = "曹操"
else:
rword = word
counts[rword] = counts.get(rword,0) + 1
for i in excludes:
del counts[i]
items = list(counts.items())
items.sort(key = lambda x:x[1] , reverse=True)
for i in range(7):
word,count = items[i]
print("{0:<10}{1:>5}".format(word,count))
方法一:运用集合去重方法
| 1 2 3 4 5 6 7 8 9 |
|
说明:运用集合对文本字符串列表去重,这样统计词汇不会重复,运用列表的counts方法统计频数,将每个词汇和其出现的次数打包成一个列表加入到word_list中,运用列表的sort方法排序,大功告成。
方法二:运用字典统计
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
方法三:使用计数器
| 1 2 3 4 5 6 7 |
|
文章出处登录后可见!