文章用于学习记录
文章目录
- 前言
- 一、PDF 文件转换为图片
- 二、OCR 图片文字识别提取
- 三、服务器端下载运行 PaddleOCR
- 四、下载权重文件
- 总结
前言
文字识别(Optical Character Recognition,简称OCR)是指将图片、扫描件或PDF、OFD文档中的打印字符进行检测识别成可编辑的文本格式。
一、PDF 文件转换为图片
import datetime
import os
import fitz #pip install PyMuPDF
def pyMuPDF_fitz(pdfPath, imagePath):
startTime_pdf2img = datetime.datetime.now() # 开始时间
print("imagePath=" + imagePath)
pdfDoc = fitz.open(pdfPath)
for pg in range(pdfDoc.pageCount):
page = pdfDoc[pg]
rotate = int(0)
# 每个尺寸的缩放系数为1.3,这将为我们生成分辨率提高2.6的图像。
# 此处若是不做设置,默认图片大小为:792X612, dpi=96
zoom_x = 1.33333333 # (1.33333333-->1056x816) (2-->1584x1224)
zoom_y = 1.33333333
mat = fitz.Matrix(zoom_x, zoom_y).preRotate(rotate)
pix = page.getPixmap(matrix=mat, alpha=False)
if not os.path.exists(imagePath): # 判断存放图片的文件夹是否存在
os.makedirs(imagePath) # 若图片文件夹不存在就创建
pix.writePNG(imagePath + '/' + 'images_%s.png' % pg) # 将图片写入指定的文件夹内
endTime_pdf2img = datetime.datetime.now() # 结束时间
print('pdf2img时间=', (endTime_pdf2img - startTime_pdf2img).seconds)
if __name__ == "__main__":
# 1、PDF地址
pdfPath = './pdf/note.pdf'
# 2、需要储存图片的目录
imagePath = 'pdf'
pyMuPDF_fitz(pdfPath, imagePath)
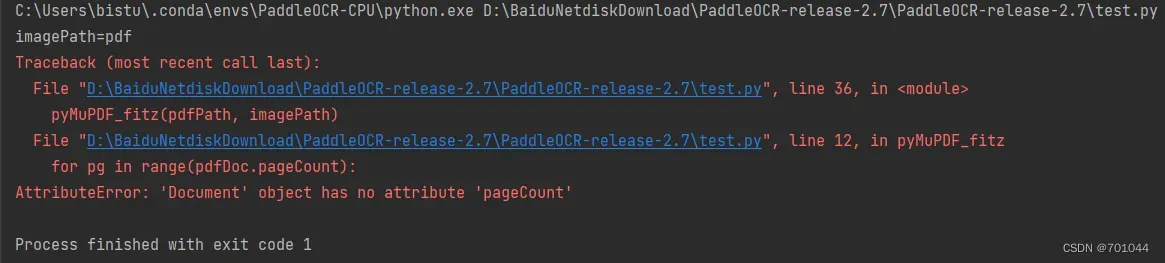
- AttributeError: ‘Document‘ object has no attribute ‘pageCount‘ PyMuPDF库
- 由于 PyMuPDF 库更新导致的,里面的一些函数名发生了变化
- 将 pageCount 改为 page_count
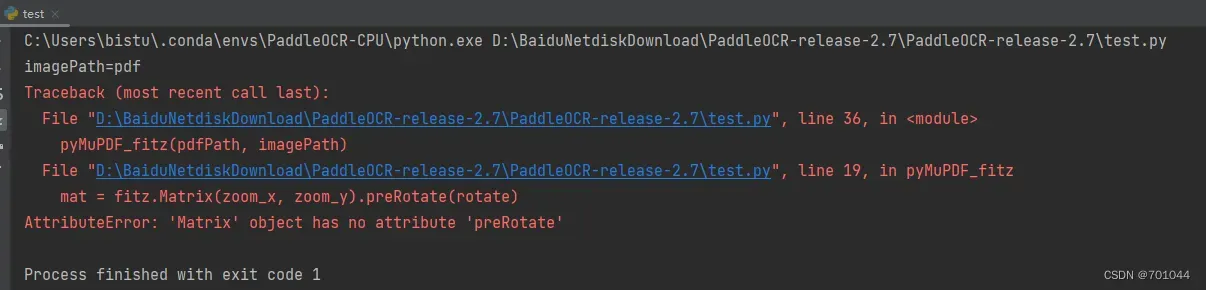
- 将 preRotate 改为 prerotate
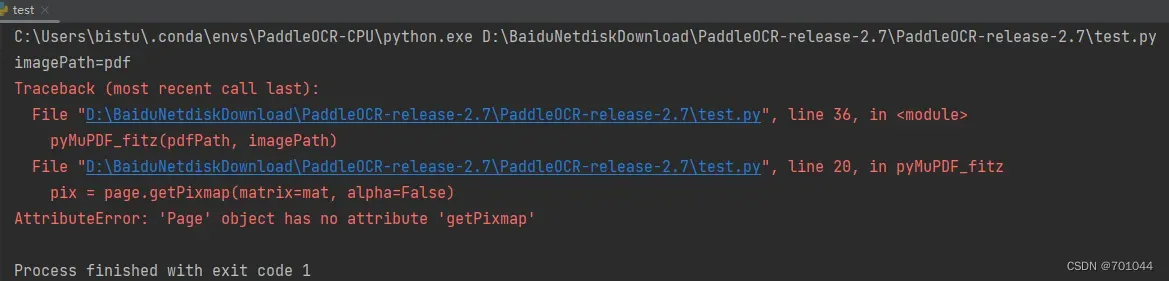
- 将 getPixmap 改为 get_pixmap
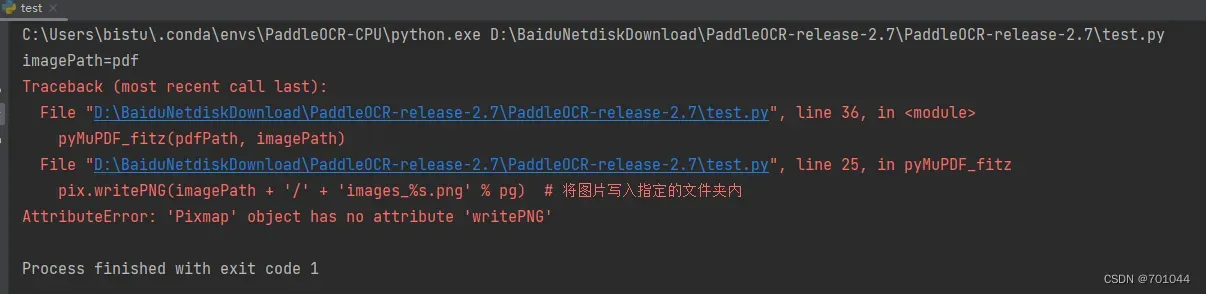
- 将 writePNG 改为 save
- 这是要转换的 PDF 文件
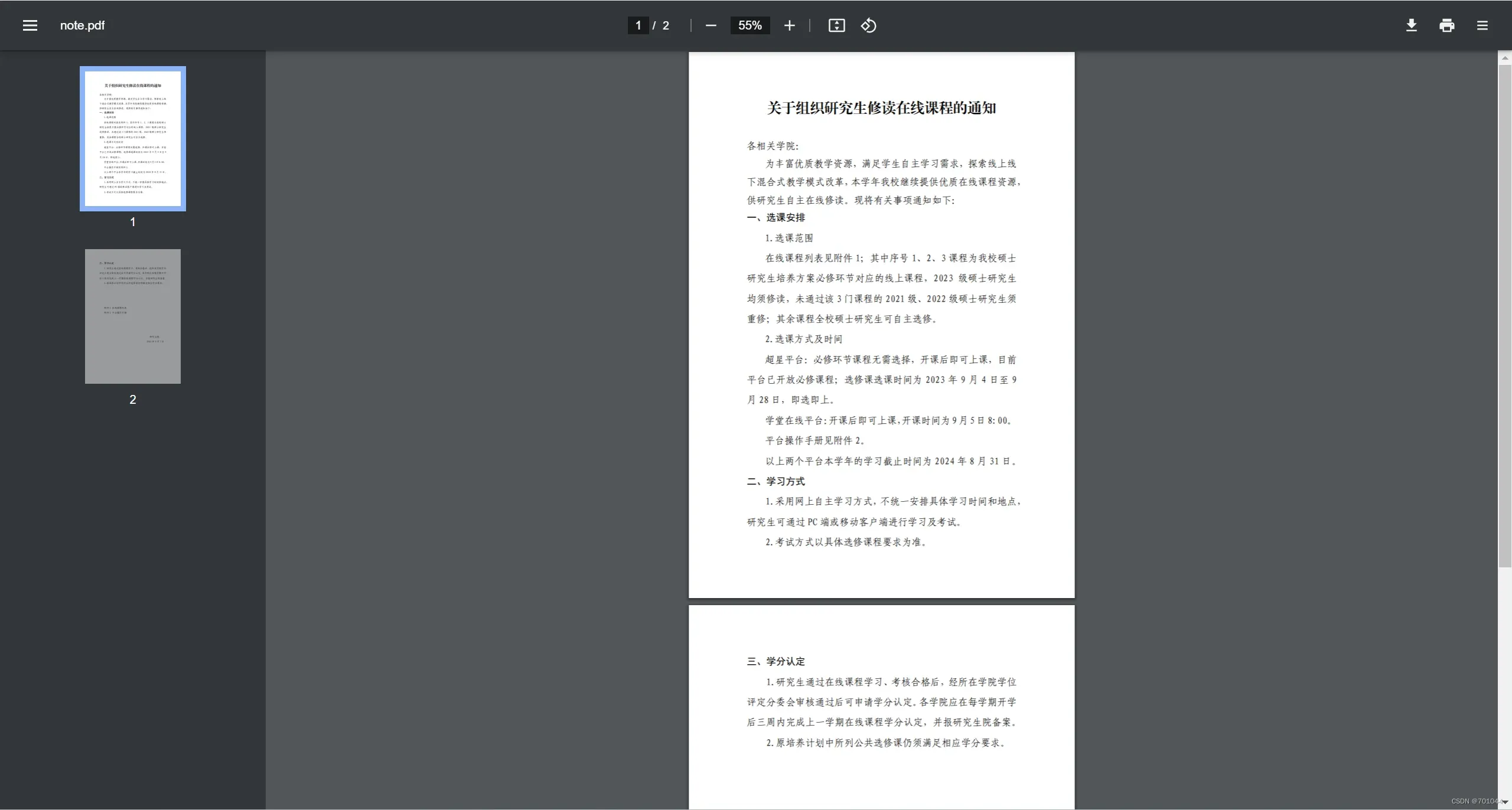
- 修改后
import datetime
import os
import fitz # fitz就是pip install PyMuPDF
def pyMuPDF_fitz(pdfPath, imagePath):
startTime_pdf2img = datetime.datetime.now() # 开始时间
print("imagePath=" + imagePath)
pdfDoc = fitz.open(pdfPath)
for pg in range(pdfDoc.page_count):
page = pdfDoc[pg]
rotate = int(0)
# 每个尺寸的缩放系数为1.3,这将为我们生成分辨率提高2.6的图像。
# 此处若是不做设置,默认图片大小为:792X612, dpi=96
zoom_x = 1.33333333 # (1.33333333-->1056x816) (2-->1584x1224)
zoom_y = 1.33333333
mat = fitz.Matrix(zoom_x, zoom_y).prerotate(rotate)
pix = page.get_pixmap(matrix=mat, alpha=False)
if not os.path.exists(imagePath): # 判断存放图片的文件夹是否存在
os.makedirs(imagePath) # 若图片文件夹不存在就创建
pix.save(imagePath + '/' + 'images_%s.png' % pg) # 将图片写入指定的文件夹内
endTime_pdf2img = datetime.datetime.now() # 结束时间
print('pdf2img时间=', (endTime_pdf2img - startTime_pdf2img).seconds)
if __name__ == "__main__":
# 1、PDF地址
pdfPath = r'D:\BaiduNetdiskDownload\PaddleOCR-release-2.7\PaddleOCR-release-2.7\pdf\note.pdf'
# 2、需要储存图片的目录
imagePath = r'D:\BaiduNetdiskDownload\PaddleOCR-release-2.7\PaddleOCR-release-2.7\pdf'
pyMuPDF_fitz(pdfPath, imagePath)
- 这是转换后的两张图片

二、OCR 图片文字识别提取
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = './pdf/images_0.png'
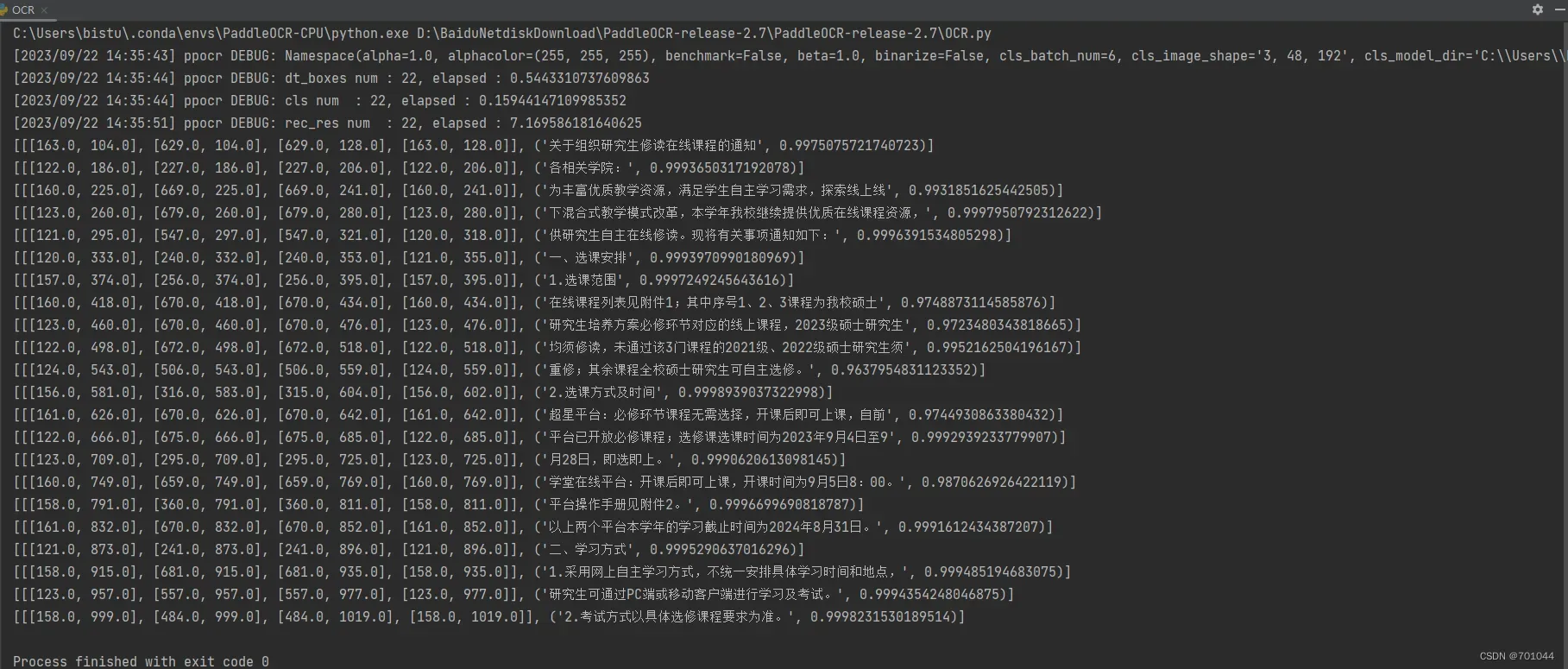
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# 显示结果
# 如果本地没有simfang.ttf,可以在doc/fonts目录下下载
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')

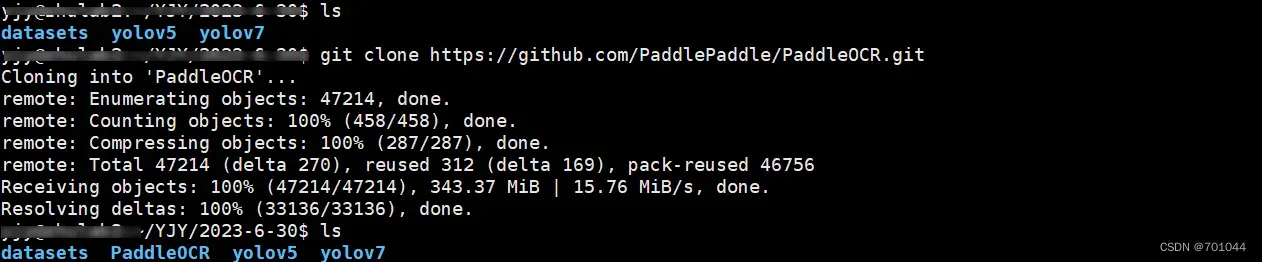
三、服务器端下载运行 PaddleOCR
git clone https://github.com/PaddlePaddle/PaddleOCR.git
# 进入 pytorch 虚拟环境
conda activate pytorch
# 命令行进入 PaddleOCR 文件夹下
cd PaddleOCR
# 识别单张图片
python tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True --use_gpu=False
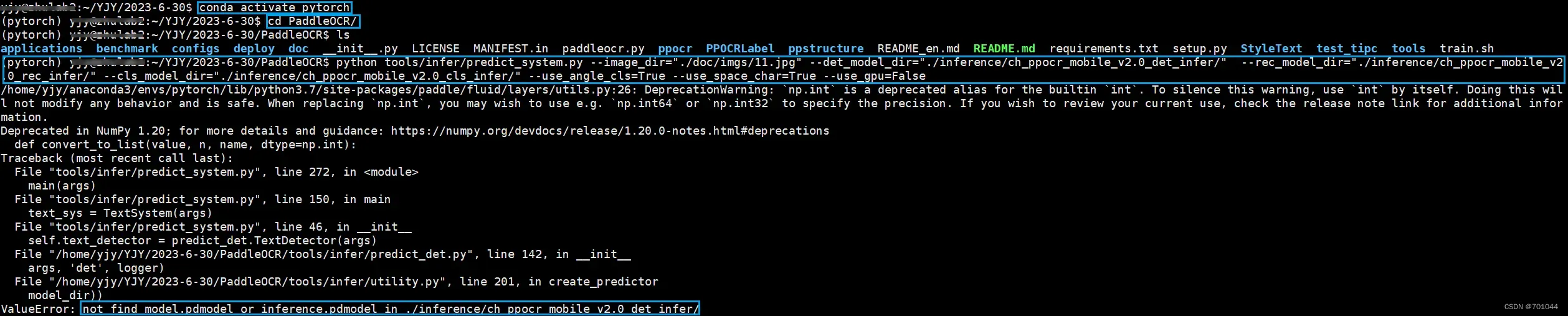
报错 not find model.pdmodel or inference.pdmodel in ./inference/ch_ppocr_mobile_v2.0_det_infer/
四、下载权重文件
- 权重链接地址
# 检测权重
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar
# 方向分类权重
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
# 识别权重
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar
- 创建一个 inference 文件夹,把前面解压后的三个文件夹放入 inference 中,
- 再把 inference 文件夹放入 PaddleOCR 中,最终树形目录结构效果如下:

- 再次检测,报错问题解决


总结
以上就是 Python 实现 PDF 文件转换为图片以及快速使用 PaddleOCR 过程。
版权声明:本文为博主作者:701044原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_41258131/article/details/133163718