文章目录
- 专栏导读
- 1. OCR技术介绍
- 2. 模块介绍
- 3. 模块安装
- 4. 代码实战
-
- 4.1 英文图片测试
- 4.2 数字图片测试
- 4.3 中文图片识别
- 书籍分享
专栏导读
🔥🔥本文已收录于《100天精通Python从入门到就业》:本专栏专门针对零基础和需要进阶提升的同学所准备的一套完整教学,从0到100的不断进阶深入,后续还有实战项目,轻松应对面试,专栏订阅地址:https://blog.csdn.net/yuan2019035055/category_11466020.html
- 优点:订阅限时9.9付费专栏进入千人全栈VIP答疑群,作者优先解答机会(代码指导、远程服务),群里大佬众多可以抱团取暖(大厂内推机会)
- 专栏福利:简历指导、招聘内推、每周送实体书、80G全栈学习视频、300本IT电子书:Python、Java、前端、大数据、数据库、算法、爬虫、数据分析、机器学习、面试题库等等
1. OCR技术介绍
OCR,即光学字符识别(Optical Character Recognition),是一种将印刷体字符转化为计算机可读文字的技术。OCR技术可以将纸质文档、扫描文档、照片等转化为可编辑的电子文件,方便用户进行编辑、存储和共享。
OCR技术的应用范围非常广泛。例如,银行和保险公司可以使用OCR技术来处理各种表格和文件,包括支票、发票、合同等,从而提高办公效率。医院可以使用OCR技术来处理病历、处方和医学报告,从而提高医疗质量和效率。政府机构可以使用OCR技术来处理各种表格和文件,例如税务申报表、选民登记表等,从而提高政府服务的效率和质量。
OCR技术的原理是利用光学扫描仪将纸质文档转化为数字图像,然后通过图像处理算法将图像中的字符识别出来,并转化为计算机可读的文字。OCR技术的核心是字符识别算法,这个算法需要考虑到各种字体、字号、字距、倾斜度、噪声等因素。
OCR技术的发展历史可以追溯到20世纪50年代,当时的OCR技术只能处理单一字体、字号、字距的文本。随着计算机技术的不断发展,OCR技术也不断进步,现在的OCR技术能够处理各种字体、字号、字距、倾斜度、噪声等复杂条件下的文本,并且具备高精度和高速度的特点。
总之,OCR技术是一种非常实用的技术,可以帮助用户将纸质文档转化为电子文件,从而提高办公效率和工作质量。随着计算机技术的不断进步,OCR技术也将不断发展,为用户提供更加高效和便捷的服务。
2. 模块介绍
Tesseract OCR(Optical Character Recognition)是一个免费的开源OCR引擎,由Google开发和维护。它能够识别图像中的文本,并将其转换为可编辑和可搜索的文本格式。Tesseract支持超过100种语言的文本识别,并且具有高度的准确性和可扩展性。
3. 模块安装
1、安装Tesseract、Tesseract、Pillow模块,可以使用以下命令:
pip install pytesseract
pip install pillow
pip install tesseract-ocr # 如果这个安装报错就用下面的手动安装方法
2、从网上找到相应的‘Tesseract-OCR’下载安装(自行寻找对应版本):https://digi.bib.uni-mannheim.de/tesseract/
3、无脑默认安装即可,
4、安装后的默认文件路径为(这里使用的是Windows版本):C:\Program Files\Tesseract-OCR\
4. 代码实战
4.1 英文图片测试
1. 测试图片准备:

2、修改下面的Tesseract-OCR的安装路径和图片路径:
import cv2
import pytesseract
# 1. 找到Tesseract-OCR的安装路径
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# 2. 图片的路径(注意:图片路径不能有中文
img = cv2.imread(r'English.png')
# 3. 对图片进行灰度处理
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 4. 提取字符串
text = pytesseract.image_to_string(gray)
# 5. 打印字符串
print(text)
3、运行结果,识别成功:
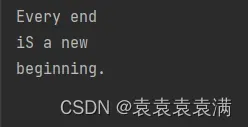
4.2 数字图片测试
- 测试图片准备:

2、修改下面的Tesseract-OCR的安装路径和图片路径:
import cv2
import pytesseract
# 1. 找到Tesseract-OCR的安装路径
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# 2. 图片的路径(注意:图片路径不能有中文
img = cv2.imread(r'number.png')
# 3. 对图片进行灰度处理
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 4. 提取字符串
text = pytesseract.image_to_string(gray)
# 5. 打印字符串
print(text)
3、运行结果,识别成功:
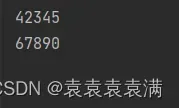
4.3 中文图片识别
注意:上面的代码不能直接识别中文,我们需要下载中文语言包
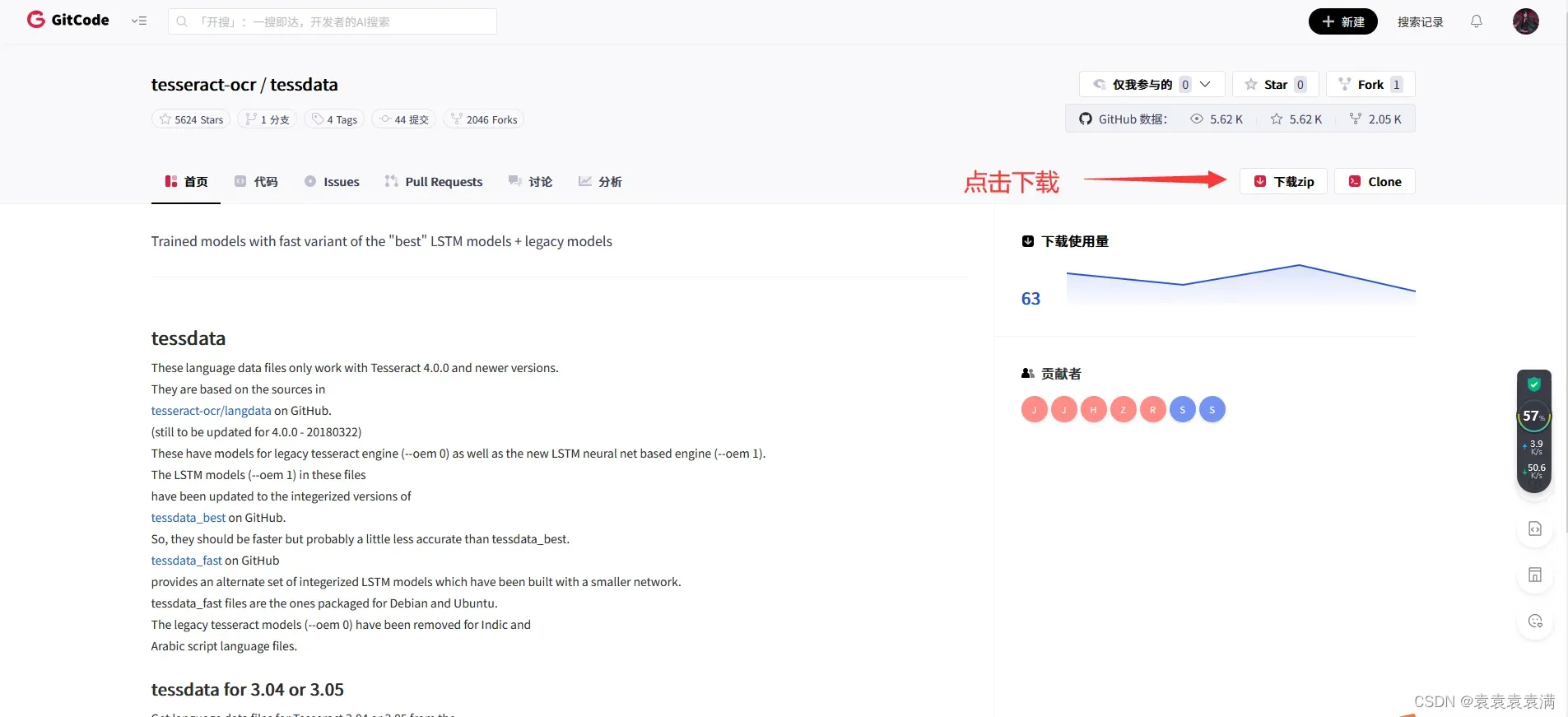
1、下载下面的4个中文语言包文件,复制到Tesseract-OCR安装目录tessdata文件夹里:https://gitcode.com/tesseract-ocr/tessdata/overview
chi_sim.traineddata
chi_sim_vert.traineddata
chi_tra.traineddata
chi_tra_vert.traineddata
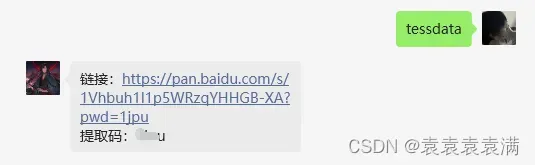
网速慢的小伙伴们,博主这里为大家下载好了,搜索公众号:袁袁袁袁满,回复:tessdata,即可:
2、将下载好的中文语言包复制在Tesseract-ocr安装路径的tessdata文件夹里:
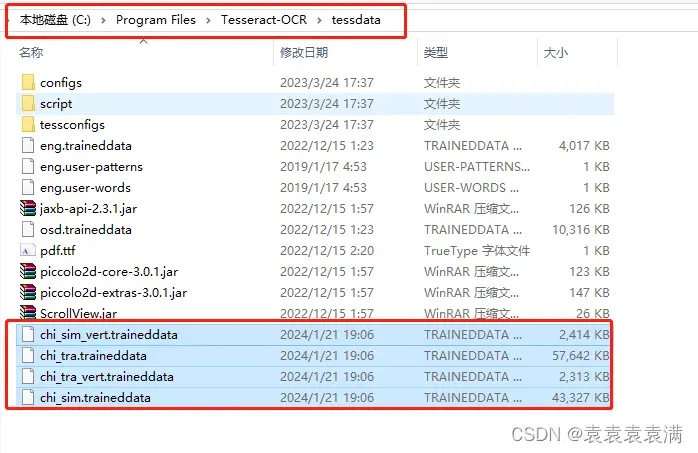
3、准备图片:

4、与之前代码区别在于设置了中文语言包:
import cv2
import pytesseract
# 1. 找到Tesseract-OCR的安装路径
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# 2. 图片的路径(注意:图片路径不能有中文
img = cv2.imread(r'Chinese.png')
# 3. 对图片进行灰度处理
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 4. 提取字符串,并设置为中文
lang = 'chi_sim'
text = pytesseract.image_to_string(gray,lang)
# 5. 打印字符串
print(text)
5、运行结果,提取成功:
书籍分享
《Web前端开发全程实战》

《Web前端开发全程实战——HTML5+CSS3+JavaScript+jQuery+Bootstrap》从初学者角度出发,结合大量实例讲解了如何使用HTML5、CSS3、JavaScript、jQuery、Ajax、Boostrap、Vue、PHP 等基本技术搭建Web 前端,力求向读者提供一套极简的Web 前端一站式高效学习方案。全书共28 章,内容包括HTML5基础、设计HTML5 文档结构、设计HTML5 文本、设计HTML5 图像和多媒体、设计列表和超链接、设计表格和表单、CSS3 基础、设计文本样式、设计特效和动画样式、CSS 页面布局、JavaScript 基础、处理字符串、使用数组、使用函数、使用对象、jQuery 基础、文档操作、事件处理、使用Ajax、CSS 样式操作、jQuery 动画、Bootstrap基础、CSS 组件、JavaScript 插件、使用Vue、PHP 基础、使用PHP 与网页交互、使用PDO 操作数据库、项目实战。书中所有知识点均结合具体实例展开讲解,代码注释详尽,可使读者轻松掌握前端技术精髓,提升实际开发能力。
本书特色:30万+读者体验,畅销丛书新增精品;10年开发教学经验,一线讲师半生心血。
京东地址:https://item.jd.com/13512401.html
版权声明:本文为博主作者:袁袁袁袁满原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/yuan2019035055/article/details/135732360